데이터 파이프라인이란?
다양한 데이터 소스에서 원시 데이터를 수집한 다음 분석을 위해 데이터 레이크 또는 데이터 웨어하우스와 같은 데이터 저장소로 이전하는 방법.
데이터는 저장소로 이동전 데이터 처리 과정을 거쳐 저장을 하여 탐색형 데이터 분석, 데이터 시각화, 머신 러닝 작업에 활용 할 수 있도록 하는것.
데이터 파이프라인 유형
데이터 파이프라인에는 일괄 처리(batch processing)와 스트리밍 데이터(streaming data)의 두 가지 주요 유형이 있습니다.
일괄 처리 (batch Processing)
batch는 미리 설정된 시간에 일괄적으로 로드하여, 대용량 데이터를 처리 할 수 있겠끔 하는 일괄 처리 방식
장점으로는 안정성이 높음.
스트리밍 데이터(streaming data)
일괄 처리와 달리, 데이터를 지속적으로 업데이트 할 때 활용됨. 예로 POS(point of Sale) 시스템은 제품의 실시간 재고 여부가 필요하기 때문에 실시간 데이터가 필요함. 필요에 따라 선택 가능
장점으로는 지연시간 짧음.
데이터 분석 파이프라인 5단계
CAPTURE -> PROCESS -> STORE -> ANALYZE -> USE
1. CAPTURE (데이터 수집)
- 데이터 마이그레이션 도구를 활용하여 한 클라우드에서 다른 클라우드로 마이그레이션 (google cloud 스토리지 전송 서비스)
- BigQuery를 이용하여 타사 SaaS(Youtube, Google Ads, Amazon S3, Res Shift 등)데이터 수집가능
- Pub/Sub 서비스를 사용하여 애플리케이션 실시간 데이터를 스트리밍 받을 수 있음
2. PROCESS (데이터 처리)
- Dataproc : 기본적으로 Hadoop, Spark의 클러스터를 함께 이용할 수 있고, 일괄 처리, 쿼리, 스트리밍, 머신 러닝을 위한 오픈 소스 데이터 도구를 활용할 수 있음
관리에 소요되는 시간과 비용을 줄여 데이터처리에 집중가능 - Dataprep : 데이터 분석가가 코드를 작성할 필요 없이 데이터를 처리할 수 있도록 도와주는 지능형 그래픽 사용자 인터페이스 도구
- Dataflow : 스트리밍 및 batch 데이터를 위한 서버리스 데이터 처리 서비스
Apache Beam 오픈 소스 SDK를 기반으로 한 파이프 라인을 이식가능 특징으로는 스토리지를 컴퓨팅과 분리하여 원활하게 확장가능
Hadoop 이란?
대용량의 데이터를 적은 비용으로 빠르게 분석할 수 있도록 하는 플랫폼
빅데이터 처리와 분석을 위해 사실상 표준으로 사용되는 영향력 있는 플랫폼
3. STORE (저장)
- GCS : 용도에 맞는 Standard, Nearline, Coldline, Archive로 맞게 선택 할 수 있고 이미지, 동영상, 파일 등을 위한 객체 저장소
- BigQuery : 서버리스 데이터 웨어하우스 페타바이트 규모의 데이터까지 원활하게 확장 가능.
4. Analyze (분석)
- BigQuery : BigQuery를 사용하는 경우 SQL을 사용하여 BigQuery에서 데이터를 직접 분석가능
- Cloud Stoge를 사용하는 경우에도 BigQuery로 쉽게 이동이 가능함.
5. USE (데이터 사용 및 시각화)
1) 데이터 사용
데이터 웨어하우스에 데이터가 있으면 Tesorflow, AI Platform을 통해 활용 가능.
- Tesorflow : 도구, 라이브러리, 커뮤니티 리소스가 포함된 엔드 투 엔드 오픈소스 머신 러닝 플랫폼
- AI Platform : 개발자, 데이터 과학자, 데이터 엔지니어가 ML 워크플로를 간소화 할때 이용
2) 데이터 시각화
- Data Studio : 손쉬운 데이터 시각화를 위해 사용
- Looker : 데이터 시각화, 임베디드 분석기능 제공
https://www.freecodecamp.org/news/scalable-data-analytics-pipeline/
Cloud Data Fusion이란?
데이터 파이프라인을 신속하게 빌드 및 관리하기 위한 완전 관리형 클라우드 기반의 기업 데이터 통합 서비스
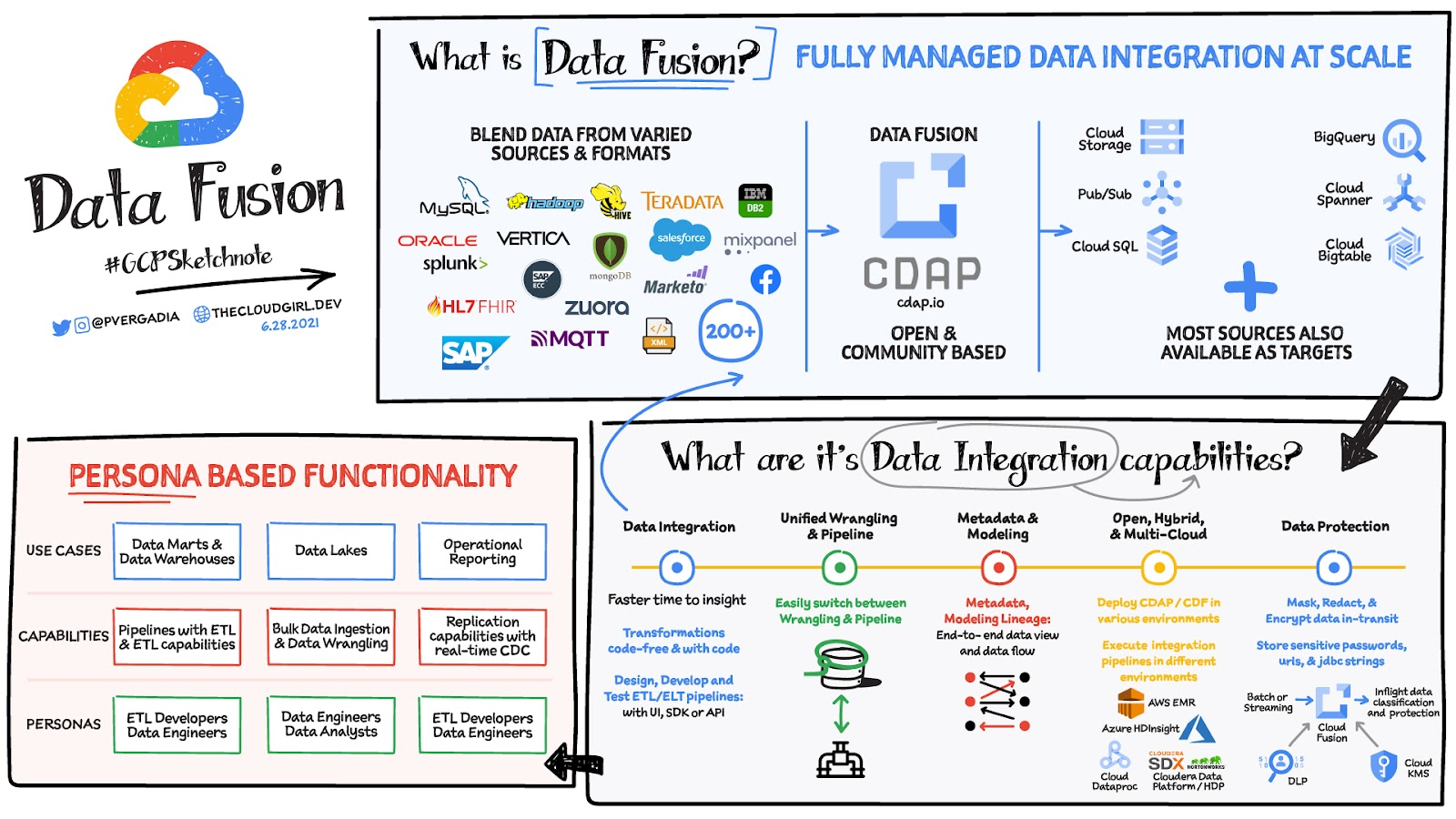
대표기능
데이터 통합기능
- 데이터를 추출하고 혼합 할 수 있는 200개 이상의 커넥터를 지원하기 때문에
데이터 일관성
메타데이터 모델링
Managed Service
How to Build a Scalable Data Analytics Pipeline: https://www.freecodecamp.org/news/scalable-data-analytics-pipeline/
All the products mentioned in this section are described here:
Pub/Sub https://www.youtube.com/watch?v=JrKEErlWvzA&list=PLTWE_lmu2InBzuPmOcgAYP7U80a87cpJd
BigQuery Data Transfer Service https://cloud.google.com/bigquery-transfer/docs/introduction
Storage Transfer Service https://cloud.google.com/storage-transfer-service
Cloud IoT Core https://cloud.google.com/blog/topics/developers-practitioners/what-cloud-iot-core
Cloud Dataflow https://cloud.google.com/blog/topics/developers-practitioners/dataflow-backbone-data-analytics
Dataproc https://medium.com/google-cloud/all-you-need-to-know-about-google-cloud-dataproc-23fe91369678
Dataprep https://cloud.google.com/blog/topics/developers-practitioners/google-cloud-dataprep-trifacta-cheat-sheet
Bigquery https://cloud.google.com/blog/topics/developers-practitioners/query-big-bigquery-cheat-sheet
Data analytics design patterns https://cloud.google.com/architecture/reference-patterns/overview
