데이터를 한꺼번에 전달해야할 때가 있다. 일반적으로 이러한 상황에 클래스를 사용한다.
data class Player (
val id: Int,
var name: String,
var points: Int
)
val player = Player(0, "Gecko", 9999)data한정자는 무엇이고 왜붙어야할까?
data한정자를 붙이면 몇가지 함수가 자동으로 생성된다.
- toString
- equals와 hashCode
- copy
- componentN(component1, component2)
첫 번째로 toString함수는 모든 프로퍼티와 값을 출력해준다.
로그나 디버그할 때 유용하게 활용할 수 있다.
print(player.toString()) // Player(id=0, name=Gecko, points=9999)equals는 기본 생성자의 프로퍼티가 같은지 확인해 준다. equals, hashCode둘다 같은 결과를 낸다.
println(player.hashCode()) // 21290109180
println(Player(0, "Gecko", 9999).hashCode()) // 2129010918
println(Player(0, "Gecko", 9999) == player) // true객체가 다르더라도 데이터 클래스내의 프로퍼티가 같으면 같은 해쉬코드값을 반환한다.
player.name = "Hello"
println(player.hashCode()) // -2137058147
player.name = "Gecko"
println(player.hashCode()) // 2129010918
println(Player(0, "Gecko", 9999).hashCode()) // 2129010918
// 만약 data한정자가 붙지 않는다면
val player = Player(0, "Gecko", 9999)
val player2 = Player(0, "Gecko", 9999)
println(player.hashCode()) // 2061475679
println(player2.hashCode()) // 140435067copy는 기본 생성자 프로퍼티가 같은 새로운 객체를 반환한다. 새로 만들어진 객체의 값은 이름있는 아규먼트를 활용해 효율적으로 생성할 수 있다.
val player2 = player.copy(
id = 1,
name = "HaeChan"
)copy는 객체를 얕은 복사하지만, 이것은 객체가 immutable 이라면 상관이 없다. immutable한 객체는 깊은 복사한 객체가 필요 없기 때문이다.
componentN 함수는 위치를 기반으로 객체를 해제할 수 있게 해준다.
val (id, name, pts) = player
print("$id $name $pts") // 0 Gecko 9999 이는 JS에서의 비구조할당과 매우 유사하게 작동하며 코틀린 내에서는 해당 코드를 다음과 같은 코드로 변환한다.
val id: Int = player.component1()
val name: String = player.component2()
val pts: Int = player.component3()이렇게 위치를 기반으로 객체를 해제하면 변수의 이름을 원하는 대로 가져올 수 있다.
또한 List, Map.Enty등의 원하는 형태로도 객체를 해제할 수 있다.
val trip = mapOf(
"China" to "Tianjin",
"Russia" to "Petersburg",
"India" to "Rishikesh",
)
for ((country, city) in trip) {
println("$country And $city")
// China And Tianjin
// Russia And Petersburg
// India And Rishikesh
}하지만 위치를 잘못 지정하면 혼동이 일어날 수 있음으로 데이터 클래스의 이름과 동일한 이름을 사용하는 것이 좋다.
그렇게 하면 IDE에서도 관련된 경고를 내보내 주기 때문이다.
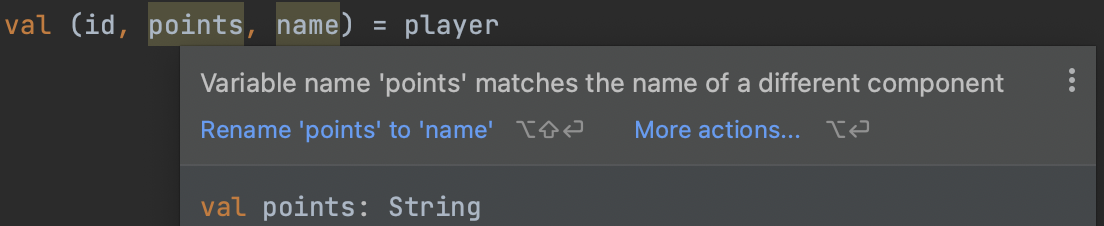
데이터를 하나만 갖는 데이터 클래스는 해제하지 말자
data calss User(val name: String)
val (name) = User("John")이러한 코드는 람다 표현식과 함께 활용될 때 혼동될 수 있다.
user = User("John")
user.let {
a -> print(a) // User(name=John)
}
user.let {
(a) -> print(a) // John
}튜플 대신 데이터 클래스를 활용하자.
데이터 클래스는 튜플보다 많은 것을 제공한다.
코틀린의 튜플은 Serializable을 기반으로 만들어지며, toString()을 사용할 수 있는 제너릭 데이터 클래스이다.
+) Serializable이란?
직렬화란 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 시스템에서도 사용할 수 있도록 바이트(byte) 형태로 데이터 변환하는 기술과 바이트로 변환된 데이터를 다시 객체로 변환하는 기술(역직렬화)을 아울러서 이야기한다.
안드로이드에서는 해당 직렬화를 더 효율적으로 활용하는 인터페이스인 Parcelable을 사용한다.
public data class Pair<out A, out B>(
public val first: A,
public val second: B
) : Serializable {
public override fun toString(): String = "($first, $second)"
}Pair과 Triple이 코틀린에 남아 있는 마지막 튜플이다.
과거에는 튜풀을 (Int, String, String, Long)처럼 괄호와 타입 지정을 통해 원하는 형태의 튜플을 정의할 수 있었다. 이는 데이터 클래스와 같은 역할을 하지만 가독성이 나빴다.
Pair과 Triple같은 경우 특별한 상황을 제외하면 무조건 데이터 클래스를 사용하는 것이 좋다.
fun String.parseName(): Pair<String, String>? {
val indexOfLastSpace = this.trim().lastIndexOf(' ')
if (indexOfLastSpace < 0) return null
val firstName = this.take(indexOfLastSpace)
val lastName = this.drop(indexOfLastSpace)
return Pair(firstName, lastName)
}
fun main() {
val fullname = "모스칸 지브스키"
val (firstName, lastName) = fullname.parseName() ?: return
println("$firstName, $lastName") // 모스칸, 지브스키
}해당 소스에서 리턴값 Pair<String, String>쌍에서 무엇이 성인지 무엇이 이름인지 예측하기 어렵고 혼돈을 야기할 뿐이다.
data class FullName(
val firstName: String,
val lastName: String
)
fun String.parseName(): FullName? {
val indexOfLastSpace = this.trim().lastIndexOf(' ')
if (indexOfLastSpace < 0) return null
val firstName = this.take(indexOfLastSpace)
val lastName = this.drop(indexOfLastSpace)
return FullName(firstName, lastName)
}
fun main() {
val fullname = "모스칸 지브스키"
val (firstName, lastName) = fullname.parseName() ?: return
println("$firstName, $lastName") // 모스칸, 지브스키
}데이터 클래스를 추가하여 다음과 같이 반환하면 분해할 때 IDE의 도움도 받을 수 있고, 무엇보다 명확하다.
또한 이러한 작업을 수행해도 추가 비용은 거의 들지 않는다.
정리
데이터 클래스를 활용하면 튜플을 활용할 때 보다 더 많은 장점이 있다. 코틀린에서 클래스는 큰 비용없이 사용할 수 있는 좋은 도구이며, 따라서 클래스를 활용하는 데 두려움을 갖지 말고, 적극적으로 활용하자.
