상태를 정의할 떄는 변수와 프로퍼티의 스코프를 최소화 하는 것이 좋다.
- 프로퍼티보다는 지역 변수를 사용하자.
- 최대한 좁은 스코프를 갖게 변수를 사용하자.
다음과 같은 예제를 보자
// 나쁜 예
var user: User
for(i in users.indices) {
user = users[i]
print("user at $i is $user")
}
// 조금 더 좋은 예
for(i in users.indices) {
val user = users[i]
print("User at $i is $user")
}
// 제일 좋은 예
for((i, user) in users.withIndex()){
print("User at $i is $user")
}
왜 변수의 스코프를 좁게 만들어야하냐?
-
스코프 내부에 스코프가 있을 수도 있기때문에 (람다내부의 람다 표현식 등) 최대한 변수는 스코프를 좁게 설정하는 것이 좋다.
-
프로그램을 추적하고 관리하기 쉽게 만들기 위해서이다. 코드를 분석할 때 어떤 시점에 어던 요소가 있는지 확인해야 하는데 변수의 스코프가 넓어지면 프로그램을 이해하기 어려워진다.
-
변수의 스코프가 너무 넓으면 다른 개발자에 의해서 변수가 잘못 사용될 수도 있다.
변수의 스코프를 좁게 사용하는 방법에는 무엇이 있을까?
- if, when, try-catch, Elvis 표현식을 활용하여 변수를 정의할 때 초기화하자.
// 변수 정의할 때 if-else 사용하기
val user: User = if(hasValue){
getValue()
} else {
User()
}
// elvis 표현식
val str: String? = "1234"
val nullStr: String? = null
var len: Int = str?.length ?: -1
println("str.length: $len") // 4
len = nullStr?.length ?: -1
println("nullStr.length: $len") // -1str?.length ?: -1는 엘비스 연산자 왼쪽의 str?.length 객체가 null이 아니면 그 값을 리턴하고, null이면 -1을 리턴한다.
- 구조분해 선언을 활용하자
val (description, color) = when {
degrees < 5 -> "cold" to Color.BLUE
degrees < 23 -> "mild" to Color.YELLOW
else -> "hot" to Color.RED
}다음은 degrees에 따라 description, color를 다르게 선언하는 것 볼수있다.
이와 비슷한 기능으로는 코틀린 표준 라이브러리에 미리 정의된 Pair 나 Triple 클래스를 사용할 수 있다.
val (manufacturer, modelGroup, model) = Triple("현대", "그랜저", "그랜저 IG")+) Kotlin의 시퀀스(Sequences)란??
시퀀스는 Iterable과 동일한 기능을 제공하지만 연상방식에서 Collection, List, Map 등과는 다른 접근 방식을 구현한다.
Map, Collectino, List 와 같은 Collection은 Eagerly evalution으로 동작한다.
Sequences는 Lazy evaluation으로 동작한다.
Lazy evaluation이란 지금 하지 않아도 되는 연산은 최대한 뒤로 미루고, 어쩔 수 없이 연산이 필요한 순간에 연산을 수행하는 방식을 의미한다.
다음과 같은 예제를 보자.
val sequence = sequence {
val start = 0
// 단일 값 생성
yield(start)
// 이터 러블 생성
yieldAll(1..5 step 2)
// 무한 시퀀스 생성
yieldAll(generateSequence(8) { it * 3 })
}
println(sequence.take(7).toList()) // [0, 1, 3, 5, 8, 24, 72]위에서 무한 시퀀스를 생성했음에도 불구하고 Lazy evaluation으로 동작하기 때문에 take(7), 즉 7개의 sequence 요소만 연산이 수행됨을 볼 수 있다.
시퀀스는 모든 단일 요소에 대해 하나씩 모든 처리 단계를 수행하는 반에, Iterable은 전체 컬렉션에 대한 각 단계를 완료한 다음 다음 단계로 진행한다.
시퀀스를 생성하는 방법은 다음과 같다.
// sequenceOf로 생성
val numbersSequence = sequenceOf("four", "three", "two", "one")
// collection 을 asSequence()로 변경
val numbers = listOf("one", "two", "three", "four")
val numbersSequence = numbers.asSequence()
// generateSequence(초기값) { it +2 }
// 만약 끝을 내고싶으면 null을 return하기
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count())
Sequence내에서 yield(), yieldAll() 함수를 활용하여 소비자에게 sequence를 반환할 수 있다.
시퀀스 소비자에게 요소를 반환하고 다음 요소가 소비자애 의해 요청될 때까지 sequence()의 실행을 일시 중단한다.
yield()은 단일 요소를 인수로 사용하며, yieldAll()은 반복 가능한 개체, 반복기 또는 다른 시퀀스를 사용할 수 있다. yieldAll()의 시퀀스 인수는 무한할 수 있지만, 이후 모든 후속 호출은 실행되지 않는다.
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5)) // kotlin.sequences.TakeSequence@4b9af9a9
println(oddNumbers.take(5).toList()) // [1, 3, 5, 7, 9]
Iterable 과 Sequence의 예제를 살펴보자
- Iterable
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)
// 출력 값
filter: The
filter: quick
filter: brown
filter: fox
filter: jumps
filter: over
filter: the
filter: lazy
filter: dog
length: 5
length: 5
length: 5
length: 4
length: 4
Lengths of first 4 words longer than 3 chars:
[5, 5, 5, 4]Iterable의 예제를 보면 filter() 및 map()이 코드에 쓰인 순서대로 실행됨을 볼 수 있다. 즉 filter()로 모든 요소를 필터링하고, 그 다음 map()으로 it.length로 변환하고 output을 뽑는다.

- Sequence
val words = "The quick brown fox jumps over the lazy dog".split(" ")
// Sequence로 벼노한
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars")
println(lengthsSequence.toList())
// 출력 값
Lengths of first 4 words longer than 3 chars
filter: The
filter: quick
length: 5
filter: brown
length: 5
filter: fox
filter: jumps
length: 5
filter: over
length: 4
[5, 5, 5, 4]
Sequence의 경우 출력값이 “Lengths of..” 이후 출력됨을 볼 수 있다. 이는 filter() 및 map() 함수가 lengthsSequence를 요청할 때 실행됨을 알 수 있다. 또한 한꺼번에 실행되는 것이 아니라 .take(4)임으로 4개의 원소를 배출할 때 까지 filter 및 map이 동시에 돌아간다.
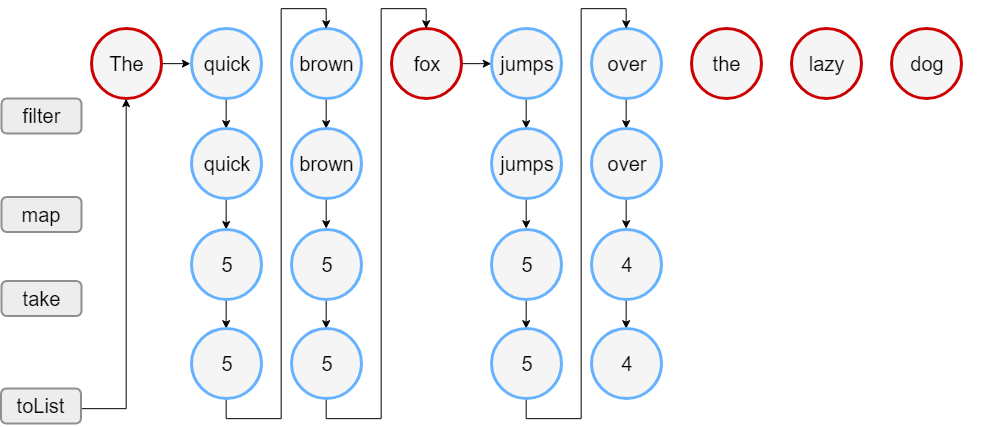
즉 filter()연산을 모두 수행할 필요가 없음으로 Collection 코드보다 연산이 빨리 끝날 수 있다.
캡처링
람다 본문 블럭 내에서 외부 함수의 로컬 변수나 글로벌 변수등을 사용할
수 있는데, 이것을 lamda capturing(포획)이라고 한다.
에라토스테네스의 체를 sequence를 사용하여 구현해보자.
val result = sequence {
var numbers = generateSequence(2) {
println("generated ${it+1}")
it + 1
}
while (true) {
val prime = numbers.first()
yield(prime)
numbers = numbers.drop(1).filter{
println("filtered ${it}")
it % prime != 0
}
}
}
print(result.take(4).toList())
// 출력 값
generated 3
filtered 3 -> yield(3)
generated 3
filtered 3
generated 4
filtered 4
generated 5
filtered 5
filtered 5 -> yield(5)
generated 3
filtered 3
generated 4
filtered 4
generated 5
filtered 5
filtered 5
generated 6
filtered 6
generated 7
filtered 7 -> yield(7)
filtered 7
filtered 7
[2, 3, 5, 7]이 소스를 다음과 같이 바꾸어보자.
val result = sequence {
var numbers = generateSequence(2) {
it + 1
}
var prime : Int
while (true) {
prime = numbers.first()
yield(prime)
numbers = numbers.drop(1).filter{
it % prime != 0
}
}
}
print(result.take(4).toList()) // [2,3,5,6]제대로 동작하지 않음을 볼 수 있다.
그 이유는
반복문 내부에서 filter을 활용해서 prime으로 나눌 수 있는 숫자를 필터링하지만, 시퀀스를 사용함으로 필터링이 지연된다.
즉 filter()가 지연된 연산을 수행하여 람다안의 코드가 수행될때 while문을 돌며 변한 prime값을 참조하게 된다.
따라 최종적인 prime 값으로만 필터링 되어 prime이 2로 설정되어 있을 때 필터링된 4를 제외하면, drop만 동작하여 연속된 숫자가 나온다.
가변성을 피하고 스코프 범위를 좁게 만들자.
참고 자료
https://lovia98.github.io/blog/kotlin-lamda.html
https://kotlinlang.org/docs/sequences.html
https://codechacha.com/ko/kotlin-elvis-operation/
