컬렉션에 공부하기전
컬렉션(Collection)과 배열(Arrays)의 차이란?
Difference between List and Array types in Kotlin - stackoverflow (코틀린에서 리스트와 어레이 타입의 차이점은 무엇인가요??)
Array<T>는 고정 사이즈 메모리를 참조하며 데이터를 저장하는 객체이다.(JVM에서Java array를 나타냄)
List<T>와MutableList<T>는ArrayList<T>와LinkedList<T>가 상속받는 인터페이스 중 하나이다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableArray<T>는mutable하며List<T>는immutable하다. 읽기 전용 콜랙션이며 수정하려면MutableList<T>를 사용해야 한다.
val a = arrayOf(1, 2, 3)
a[0] = a[1] // OK
val l = listOf(1, 2, 3)
l[0] = l[1] // doesn't compile
val m = mutableListOf(1, 2, 3)
m[0] = m[1] // OKArray<T>는 크기가 고정되어 있으므로, 크기를 늘리거나 축소할 수 없다.List<T>의 경우 사이즈를 늘릴 수 있다.
val a = arrayOf(1, 2, 3)
println(a.size) // will always be 3 for this array
val l = mutableListOf(1, 2, 3)
l.add(4)
println(l.size) // 4Array<T>는 T에 대해invariant하다 (Array<Int>는Array<Number>가 될 수 없다.) 그러나List<T>는 T에 대해covariant하다.
val a: Array<Number> = Array<Int>(0) { 0 } // won't compile
val l: List<Number> = listOf(1, 2, 3) // OKArray는IntArray,DoubleArray,CharArray등의 원시타입에 최적화 되어 있다. (각각의 어레이는int[],double[],char[]으로 매핑된다.)
List는 원시 타입에 대해 최적화를 제공하지 않지만, 일부 라이브러리에서 최적화를 제공한다.
라이브러리와 같은 성능이 중요한 파트의 소스가 아니면
List를 사용하는 것이 좋다.
컬렉션은 프로그래밍에서 굉장히 중요한 개념 중 하나이다. 안드로이드의 RecyclerView, LazyRow 등과 같은 뷰에서 컬렉션은 필수불가결한 요소이다. 이러한 컬렉션을 효율적으로 사용하는 방법을 알아보자.
대부분의 현대적인 프로그래밍 언어에는 컬렉션 리터널이 따로 제공된다.
// 파이썬
primes = [2, 3, 5, 7, 13]
// 스위프트
let primes = [2, 3, 5, 7, 13]코틀린 역시 강력한 컬렉션 처리를 제공한다. 대표적인 예로는 map, filter, all, none등과 같은 Collection API와 Sequence를 예로 들 수 있겠다.
이러한 최적화 도구를 잘 활용하지 않으면, 어플리케이션 성능에 문제가 일어날 수 있다. 컬렉션 최적화를 공부하는 것은 그렇게 어렵지는 않다. 몇 가지 규칙을 기억하고, 상황에 맞춰 생각하면 누구나 효과적으로 최적화할 수 있다.
그 규칙과 상황을 지금부터 알아보자.
규칙 1 : 하나 이상의 처리 단계를 가진 경우에는 시퀀스를 사용하라
Iterable과 Sequence의 차이가 무엇일까?
public interface Sequence<out T> {
public operator fun iterator(): Iterator<T>
}
public interface Iterable<out T> {
public operator fun iterator(): Iterator<T>
}Iterable과 Sequence는 완전히 다른 목적으로 설계되어서, 완전히 다른 형태로 동작한다.
무엇보다 Sequnce는 지연(lazy)처리된다. 따라서 시퀀스 처리 함수들을 사용하면, 데코레이터 패턴으로 꾸며진 새로운 시퀀스가 리턴된다. 최종적인 계산은 toList 또는 count등의 최종 연산이 이루어질 때 수행된다.
Iterable은 처리 함수를 사용할 때마다 연산이 이루어져 List가 만들어 진다.
데코레이터 패턴에 대해 간단히 알아보기
데코레이터 패턴(Decorator Pattenr)은 주어진 상황 및 용도에 따라 어떤 객체에 책임(기능)을 동적으로 추가하는 패턴이다.
val result = sequenceOf(1, 2, 3, 4, 5)
.filter { it % 2 == 1 } // 데코레이터를 추가
.map { it + 1 } // 데코레이터 추가
.toList() // 최종 연산 수행
println(result)정리하자면 컬렉션 처리 연산은 호출할 때 연산이 이루어진다. 반면, 시퀀스 처리는 최종 연산이 이루어지기 전까지는 각 단계에서 연산이 이러나지 않는다. 따라서 어떤 연산 처리도 하지 않고, 기존의 시퀀스에 대한 데코레이터의 연산만 설치한다. 최종 필터링 처리는 toList등과 같은 최종 연산을 할 때 이루어진다.
val seq = sequenceOf(1, 2, 3)
val filtered = seq.filter { println("f$it"); it % 2 == 1 }
println(filtered) // kotlin.sequences.FilteringSequence@62043840
val asList = filtered.toList() // f1, f2, f3
println(asList) // [1, 3]
val list = listOf(1, 2, 3)
val listFiltered = list.filter { println("f$it"); it % 2 == 1 } // f1, f2, f3
println(listFiltered) // [1, 3]Seqeunce의 filtered는 시퀀스 객체를 의미하며 리스트를 나타내지 않는다.(최종 연산이 이루어지기 전까지 설치만 함)
Iterable은 각각의 연산을 수행할 때마다 리스트 결과값을 반환한다.
이런 시퀀스의 지연 처리의 장점은 다음과 같다.
- 자연스러운 처리 순서를 유지한다.
- 최소한만 연산한다.
- 무한 시퀀스 형태로 사용할 수 있다.
- 각각의 단계에서 컬렉션을 만들어 내지 않는다.
순서의 중요성
Iterable처리와 Sequnce 처리는 연산의 순서가 달라지면, 다른 결과가 나타난다.
시퀀스는 요소하나하나에 지정한 연산을 한꺼번에 적용한다. 이를 전문적으로 element-by-element order 또는 lazy-order이라고 한다.
이터러블은 요소 전체를 대상으로 설치된 연산을 차근차근 하나씩 적용해 나간다. 이를 전문적으로 step-by-step order또는 eager order이라고 부른다.
sequenceOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// F1, M1, E2, F2, F3, M3, E6
listOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// F1, F2, F3, M1, M3, E2, E6,
Sequnce는 요소 하나하나에 지정한 연산을 한꺼번에 적용한다.
Iterable은 요소 전체를 대상으로 연산을 차근차근 수행한다.
최소 연산
컬렉션에 어떤 처리를 적용하고, 앞의 요소 10개만 필요한 상황은 굉장히 자주 접할 수 있는 상황이다. 이터러블의 처리는 기본적으로 중간 연산이라는 개념이 없으므로, 원하는 처리를 컬렉션 전체에 적용한 뒤, 앞의 요소 10개를 사용해야한다. 하지만 시퀀스는 중간 연산이라는 개념을 갖고 있으므로, 앞의 요소 10개만 원하는 처리를 할 수 있다.
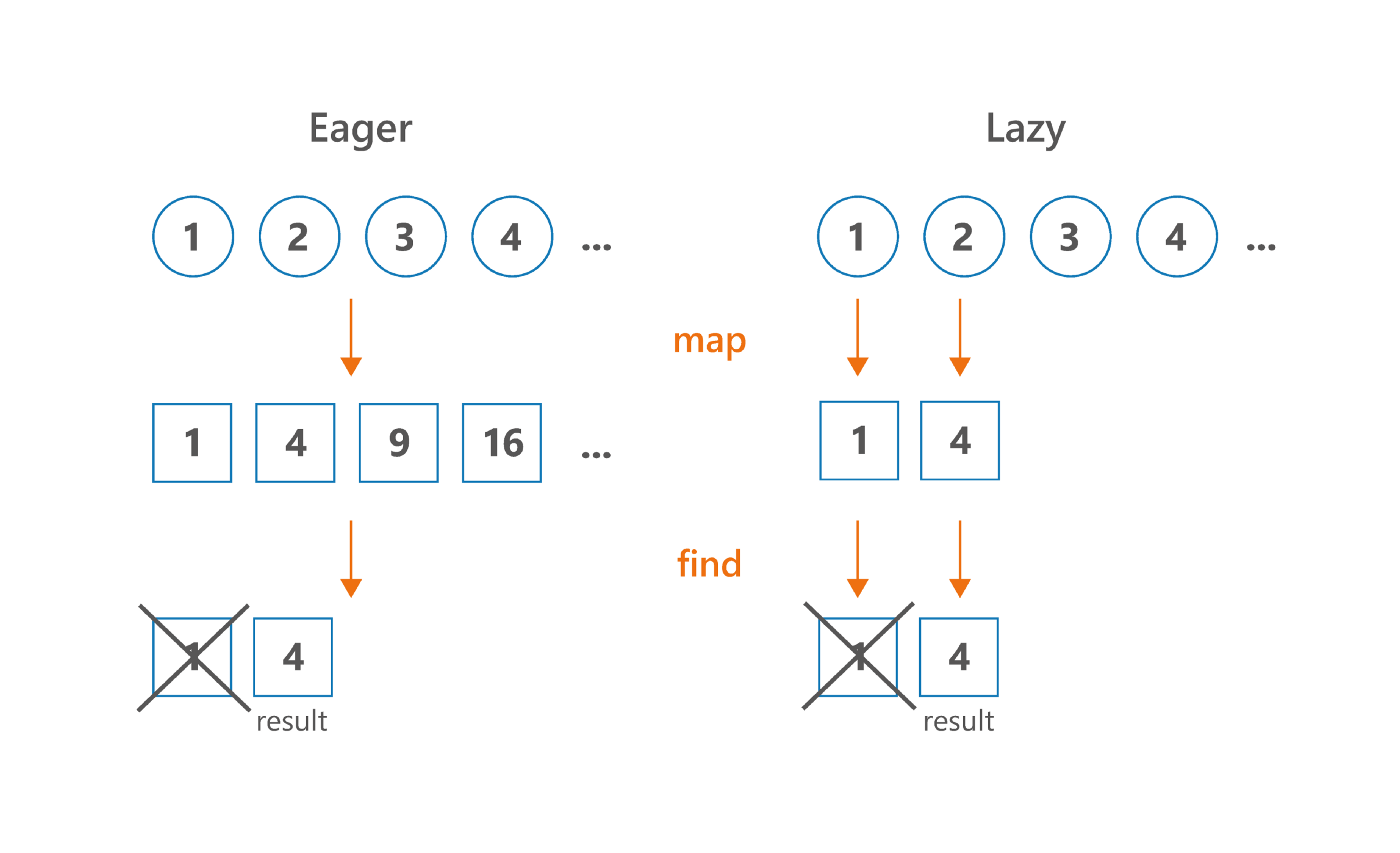
간단한 예를 살펴보자.
(1..10).asSequence()
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.find { it > 5 }
// F1, M1, F2, F3, M3
(1..10)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.find { it > 5 }
// F1, F2, F3, F4, F5, F6, F7, F8, F9, F10, M1, M3, M5, M7, M9, 이러한 이유로 중간 처리 단계를 모든 요소에 적용할 필요가 없는 경우에는 시퀀스를 사용하는 것이 좋다.
현재 코드에서 find처럼 처리를 적용하고 싶은 요소를 선택하는 연산으로는 first, take, any, all, none, indexOf등이 있다.
무한 시퀀스
시퀀스는 실제 최종 연산이 일어나기 전까지는 컬렉션에 어떠한 처리도 하지 않는다. 따라서 무한 시퀀스를 만들고 필요한 값을 추출하는 것도 가능하다.
generateSequence 또는 sequence를 사용해 시퀀스를 만들 수 있다.
generateSequence(1) { it + 1 } // 첫번 째 요소와 그 다음요소의 계산방법을 정의
.map { it * 2 }
.take(10)
.forEach { print("$it, ") } // 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 두 번째로 sequence는 suspend 함수로 요소들을 지정한다. 시퀀스 빌더는 중단 함수내부에서 yield로 값을 하나씩 만들어 낸다.
이때 시퀀셜 코루틴이 생성되며, 쓰레드를 변경하지 않고, 단순하게 함수를 중간에 중단하는 기능만을 제공한다.
val fibonacci = sequence<Int> {
yield(1) // 1 방출
var current = 1
var prev = 1
while (true) {
yield(current) // current 방출
val temp = prev
prev = current
current += temp
}
}
println(fibonacci.take(10).toList()) // [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]find,any,first,all,take와 같은 값의 활용 갯수를 지정하지 않으면 무한하게 반복한다.
fibonaaci.toList() // 무한 반복실제로 무한 반복에 빠지는 경우가 많음으로 종결 연산으로 first, take정도만 사용하는 것이 좋다.
각각의 단계에서 컬렉션을 만들어 내지 않음
표준 컬렉션 처리 함수는 각각의 단계에서 새로운 컬렉션을 만들어 낸다. 일반적으로 대부분 List이다. 각각의 단계에서 만들어진 결과를 활용하거나,
저장할 수 있다는 것은 컬렉션의 장점이지만, 각각의 단계에서 결과가 만들어지면서 공간을 차지하는 비용이 든다는 것은 큰 단점이다.
val numbers = listOf(1, 2, 3, 4, 5, 6)
numbers.filter { it % 3 == 0 } // 여기서 컬렉션 1개
.map { it * 2 } // 여기서 컬렉션 1개
.sum() // 총 2개의 컬렉션이 만들어짐
numbers.asSequence()
.filter { it % 3 == 0 }
.map { it * 2 }
.sum() // 컬렉션이 만들어지지 않음크거나 무거운 컬렉션을 처리할 때는 큰 비용이 들어간다. 만약 크기가 1GB인 컬렉션을 처리한다고 해보자.
File("1GBCollection.csv").readLines() // 1개
.drop(1) // descriptions 컬럼 제거
.mapNotNull { it.split(",").getOrNull(6) } // 1개
.filter { /* */ } // 1개
.count()
.let(::println)컬렉션이 총 3개가 만들어직 있음으로 약 3GB이내의 메모리를 소비할 것이다. 이를 Sequence로 구현한다면 비용, 성능면에서 이득을 볼 수 있을 것이다.
File("1GBCollection.csv").useLines {
.drop(1) // descriptions 컬럼 제거
.mapNotNull { it.split(",").getOrNull(6) }
.filter { /* */ }
.count()
.let(::println)
}useLines는 시퀀스의 형태로 파일을 사용할 수 있게해준다.
컬렉션의 파일이 클 수록, 처리 단계가 많아질수록 시퀀스와 이터러블의 차이가 커진다.
시퀀스가 빠르지 않은 경우도 있다.
컬렉션 전체를 기반으로 처리해야 하는 연산은 시퀀스를 사용해도 빨라지지 않는다.
예를 들면 stdlib의 sorted함수가 있다. 이는 Sequence를 List로 변환한 뒤에, 자바 stdlib의 sort를 사용해 처리한다. 문제는 이러한 변환 처리로 인해서, 시퀀스가 컬렉션처리보다 느려진다는 것이다.
무한 시퀀스에서 sorted를 사용하면 무한 시퀀스에 빠진다.
sorted는 Sequence보다 Collection이 더 빠른 희귀한 예이다. 다른 처리는 모두 Sequence가 빠르므로, 여러 처리가 결합된 경우에는 시퀀스를 사용하자.
자바 스트림의 경우
자바 8부터는 컬렉션 처리를 위해 스트림 기능이 추가되었다. 코틀린의 시퀀스와 비슷한 형태로 동작한다.
products.asSequence()
.filter { it.bought }
.map { it.price }
.average()
products.stream()
.filter { it.bought }
.mapToDouble { it.price }
.average()
.orElse(0.0)자바8의 스트림도 lazy하게 작동하며, 마지막 처리 단계에서 연산이 일어난다. 다만 자바의 스트림과 코틀린의 시퀀스는 다음과 같은 세 가지 큰 차이점이 있다.
-
코틀린의 시퀀스가 더 많은 처리 함수를 가지고 있으며(확장 함수로 정의되어 있기에), 더 사용하기 쉽다.
-
자바 스틀미은 별렬 함수를 사용해서 병렬 모드로 실행할 수 있다. 멀티 코어 환경에서 굉장히 큰 성능 향상을 가져온다.(자바 내에서 쓰레드풀과 관련된 문제가 있음으로 주의)
-
코틀린의 시퀀스는 코틀린/JVM, 코틀린/JS, 코틀린/네이티브 등의 일반적인 모듈에서 모두 사용가능하다. 하지만 자바 스트림은 코틀린/JVM에서만 동작하며, JVM이 8버전 이상일 때만 동작한다.
병렬 모드를 사용하지 않는다면, 자바 스트림과 코틀린 시퀀스 중 어떤 것이 더 효율적이라고 단정하긴 어렵다.
정말 성능적 이득을 볼려고한다면 자바의 스트림을 사용하고, 이외의 일반적인 경우에는 코틀린의 시퀀스를 사용하자.(사용하기 쉽고 가독성이 좋다.)
정리
컬렉션과 시퀀스는 같은 처리 메서드를 지원하며, 사용하는 형태가 거의 비슷하다. 일반적으로 데이터를 컬렉션에 저장하므로, 시퀀스 처리를 하려면 시퀀스로 변환하는 과정이 필요하다.
최종적으로 컬렉션 결과를 원하므로, 시퀀스를 다시 컬렉션으로 변환하는 과정도 필요하다. 이것이 시퀀스 처리의 단점이라고 할 수 있다.
하지만 시퀀스는 lazy하게 처리되므로 다음과 같은 장점이 있다.
- 자연스러운 처리 순서를 유지한다.
- 최소한의 연산만 수행한다.
- 무한 시퀀스 형태로 사용 가능하다.
- 각각의 단계에서 컬렉션을 만들어 내지 않는다.
무거운 객체나 규모가 큰 컬렉션을 여러 단계에 걸쳐서 처리할 때 시퀀스를 사용하자. 상황에 따라서 시퀀스 처리를 활용하면 성능 향상을 기대할 수 있다.
