
목차
4.1 DB 엑세스를 위한 자동 설정 프라이밍
스프링 부트는 개발자가 계속해서 반복적으로 수행하는 코드와 사용 패턴의 80~90%를 최대한 단순화하는 것을 목표로 합니다.
사용 패턴을 식별하면, 적절한 기본 구성을 사용해 필요한 빈(Bean)을 자동으로 초기화합니다. 간단한 사용자 맞춤 기능으로는 사용 패턴에 따라 여러 속성값을 제공하거나 하나 이상의 맞춤형 빈을 제공하는 기능 등이 있습니다.
4.2 앞으로 얻게 될 것
이전 챕터에서는 MutableList로 서버가 꺼지면 없어지는 커피 리스트를 관리하였습니다. 이런 구조는
-
회복 탄력성이 떨어집니다. 어플리케이션 또는 어플리케이션이 실행 중인 프랫폼에 장애가 발생하면 어플리케이션이 실행되는 동안 수행된 변경 내용이 모두 사라집니다.
-
어플리케이션 규모를 확장하기 어렵습니다. 사용자가 많아져서 어플리케이션을 확장하기 위해 추가로 인스턴트를 만들어 사용하면, 새로 생긴 인스턴스는 해당 인스턴스만의 고유한 커피 목록을 가지게 됩니다.
이런 방식으로는 어플리케이션을 운영할 수 없습니다.
4.2.1 DB 의존성 추가하기
스프링 부트 어플리케이션에서 DB에 엑세스하기 위해서는 다음 사항이 필요합니다.
- 실행 중인 DB - 접속 가능한 DB이거나 개발하는 어플리케이션의 내장 DB
- 프로그램상에서 DB엑세스를 가능하게 해주는 DB 드라이버 - 보통은 DB 공급/관리 업체가 제공
- 원하는 DB에 엑세스하기 위한
스프링 데이터모듈
스프링 데이터모듈에는 단일 의존성을 가진 DB 드라이버가 포함되는데, 이는 스프링 이니셜라이저에서 선택하면 됩니다. 스프링이 JPA-호환 데이터 스토어엑세스를 위해 JPA를 활용하는 경우, 스프링 데이터 JPA의존성과 사용하는 DB드라이버 의존성을 선택해야 합니다.
용어 정리
JPA(Java Persistent API)란?
JPA는 자바 ORM(Object Relational Mapping) 기술에 대한 API 표준 명세를 뜻합니다.
즉 다시말한다면 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스라고 할 수 있습니다.
인터페이스 이기 때문에 Hibernate, OpenJPA 등이 JPA의 구현체입니다.
그렇다면
ORM(Object Relational Mapping) 기술이란?
ORM 기술은 말 그대로 객체와 관계형 데이터 베이스를 매핑해 주는 기술을 의미합니다.
객체는 객체대로, 관계형 데이터베이스는 관계형 데이터베이스대로 설계하고, ORM 프레임워크가 중간에서 매핑을 하는 역할을 수행합니다.
Hibernate, EclipseLink, DataNucleus 등이 JPA의 구현체 중 일부이며 주로 사용됩니다.
Spring Data JPA란??
Spring Data JPA는 JPA를 사용하기 편하도록 만들어놓은 모듈입니다.
Spring Data JPA는 JPA를 한 단계 더 추상화시킨 Repository 인터페이스를 제공하며,이러한 Spring Data JPA는 Hibernate와 같은 JPA구현체를 사용해서 JPA를 사용하게 됩니다.
이는 다음과 같은 구조로 이루어져 있다고 보면 됩니다.
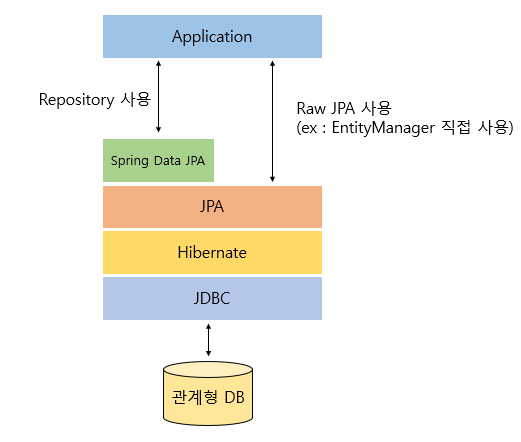
마이크로소프트 SQL, MySQL, Oracle, PostgreSQL 등이 JPA 사용할 수 있는 데이터베이스 입니다.
H2 Dependency 추가
본 책에서는 H2라는 데이터베이스를 활용할 예정입니다.
JPA와 H2를 사용하기 위해 다음과 같이 선언합니다.
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
implementation("com.h2database:h2:2.2.220")엔티티 만들기
그리고 JPA 어노테이션을 추가해 커피를 엔티티로 만듭니다.
@Entity
class Coffee(
@Id
val id: Int = 0,
name: String,
) {
var name: String = name
protected set
}Entity 를 구성할 땐 public 혹은 protected no arg constructor 가 필요합니다.
여기서 Kotlin 은 No-arg compiler-plugin 을 통해 no arg constructor를 자동으로 추가합니다.
id("org.jetbrains.kotlin.plugin.jpa") version "1.9.0"+) Entity 의 equals(), hashCode() 메서드는 양방향 연관관계 매핑시 무한순환참조를 발생시킨다고 하니 data class로 만드는 것을 지양해야 합니다.
저장소 만들기
Coffee가 저장, 조회할 수 있는 유효한 JPA로 정의되었으니, DB에 연결해야 합니다.
스프링에서는 이 과정을 간단하게 제공하기 위해 저장소(Repository) 개념을 도입합니다. Repository는 스프링 데이터에 정의됐으며, 다양한 DB를 위한 추상화 인터페이스입니다.
실제 사용해 봅시다.
interface CoffeeRepository : CrudRepository<Coffee, Int> { }여기서 <Coffee, Int>는 저장할 타입, 키의 타입 입니다.
스프링부트의 자동 설정은
- 클래스 경로(이 경우 H2)의 DB드라이버
- 어플리케이션에 정의된 저장소 인터페이스
JPA엔티티인Coffee클래스
등을 고려해 사용자를 대신해서 DB 프록시 빈을(Proxy bean) 생성합니다. 이는 보일러플레이트 코드를 줄여주기에 개발자가 비즈니스 로직에 집중하게 됩니다.
JPA 프록시와 지연로딩에 대하여에 알아보기
다음 예제에서는 컨트롤러에서 해당 레포지토리를 주입받아 로컬 변수인 coffee말고 h2 데이터베이스를 활용해 CRUD를 구현했습니다.
@RestController
@RequestMapping("/coffees")
class CoffeController {
@Autowired
private lateinit var coffeeRepository: CoffeeRepository
// private val coffees = mutableListOf<Coffee>(
// Coffee(1, "아메리카노"),
// Coffee(2, "카페 라떼"),
// Coffee(3, "모카"),
// )
@GetMapping
fun getCoffees(): MutableIterable<Coffee> {
return coffeeRepository.findAll()
}
@GetMapping("/{id}")
fun getCoffeById(@PathVariable id: Int): Optional<Coffee> {
return coffeeRepository.findById(id)
}
@PostMapping
fun insertCoffee(@RequestBody coffee: Coffee): ResponseEntity<Coffee> {
coffeeRepository.save(coffee)
return ResponseEntity(coffee, HttpStatus.CREATED)
}
@PutMapping("/{id}")
fun putCoffee(@PathVariable id: Int, @RequestBody coffee: Coffee): ResponseEntity<Coffee> {
return if (coffeeRepository.existsById(id)) {
ResponseEntity(coffeeRepository.save(coffee), HttpStatus.CREATED)
} else {
ResponseEntity(coffeeRepository.save(coffee), HttpStatus.OK)
}
}
@DeleteMapping("/{id}")
fun deleteCoffee(@PathVariable id: Int) {
coffeeRepository.deleteById(id)
}
}CrudRepository에서는 findAll(), findById(), save(), deleteById()등의 크루드를 자동으로 지원하여 이를 활용하면 됩니다.
무사히 추가 및 조회가 되는 것을 확인할 수 있습니다.
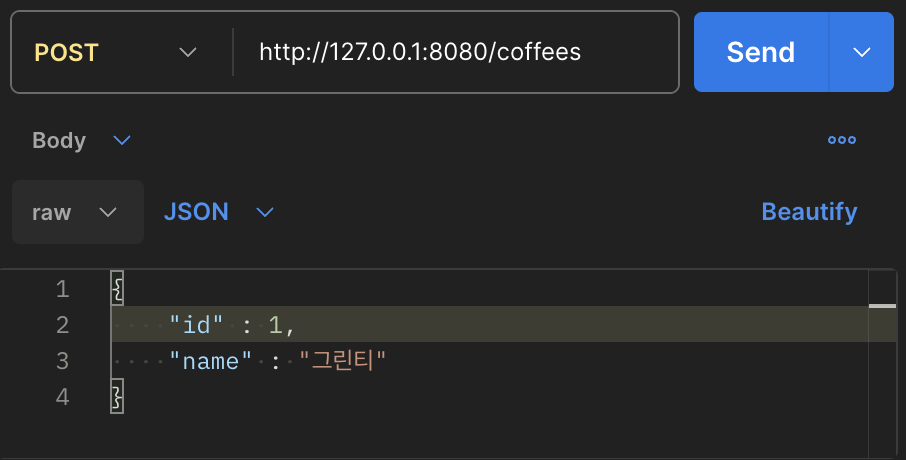
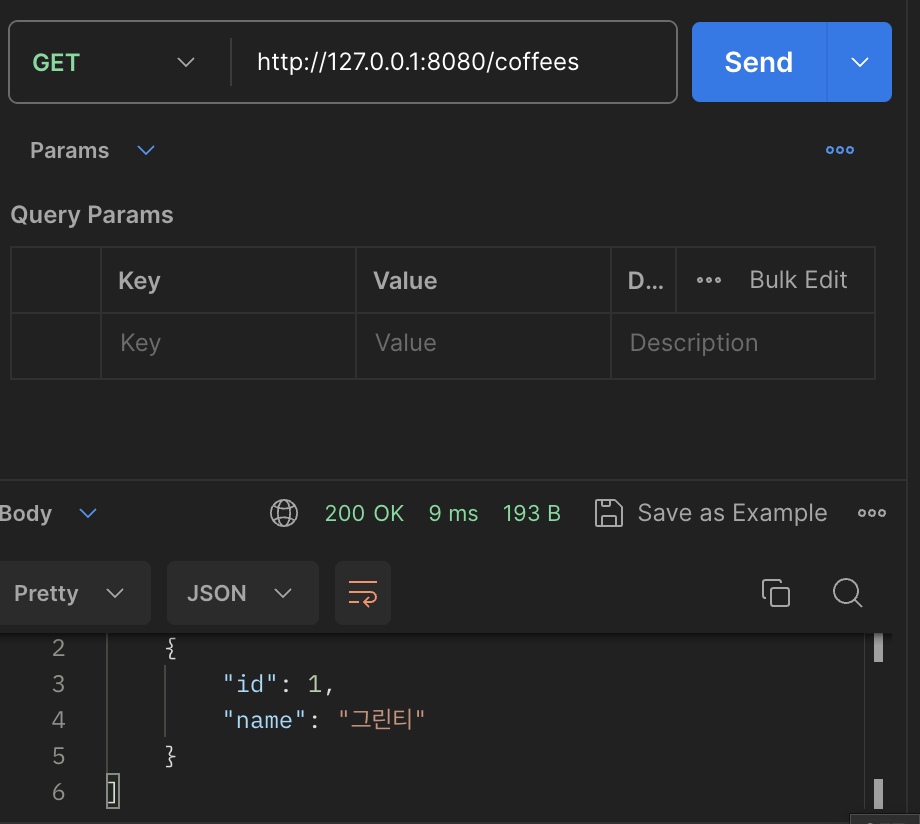
어플리케이션이 시작될 떄 초기 샘플 데이터 구성하기
어플리케이션 실행 시 자동 코드 실행은 CommandLineRunner와 ApplicationRunner를 사용하거나 람다를 사용하는 등 여러 가지 방법을 사용할 수 있습니다.
주의!
@Autowired
private lateinit var coffeeRepository: CoffeeRepository
init {
coffeeRepository.saveAll(
listOf(
Coffee(1, "아메리카노"),
Coffee(2, "카페 라떼"),
Coffee(3, "모카"),
)
)
}위의 소스는 kotlin.UninitializedPropertyAccessException: lateinit property coffeeRepository has not been initialized를 발생시키며 다른 방식이 필요합니다.
책에서는 @Component 클래스와 @PostConstruct 메서드를 사용하는 방식을 설명하고 있습니다.
그 이유로는 다음과 같습니다.
-
CommandLineRunner와ApplicationRunner가repository를autowire하면,repository빈을 목 객체로 대체하기가 어려우므로 일부 단위 테스트가 제대로 동작하지 않습니다. -
만약 테스트 내에서
repository빈을 목 객체로 대체해 사용하거나 샘플 데이터를 생성하지 않고 애플리케이션을 실행하면,@Component어노테이션을 주석 처리해 데이터를 추가하는 빈을 손쉽게 비활성화할 수 있습니다.
실제로 사용해 봅시다.
@Component
class DataLoader {
@Autowired
private lateinit var coffeeRepository: CoffeeRepository
@PostConstruct
private fun loadData() {
coffeeRepository.saveAll(
listOf(
Coffee(1, "아메리카노"),
Coffee(2, "카페 라떼"),
Coffee(3, "모카"),
)
)
}
}실제로 해당 컴포넌트를 작성만하면 손쉽게 초기 데이터를 로드할 수 있습니다.
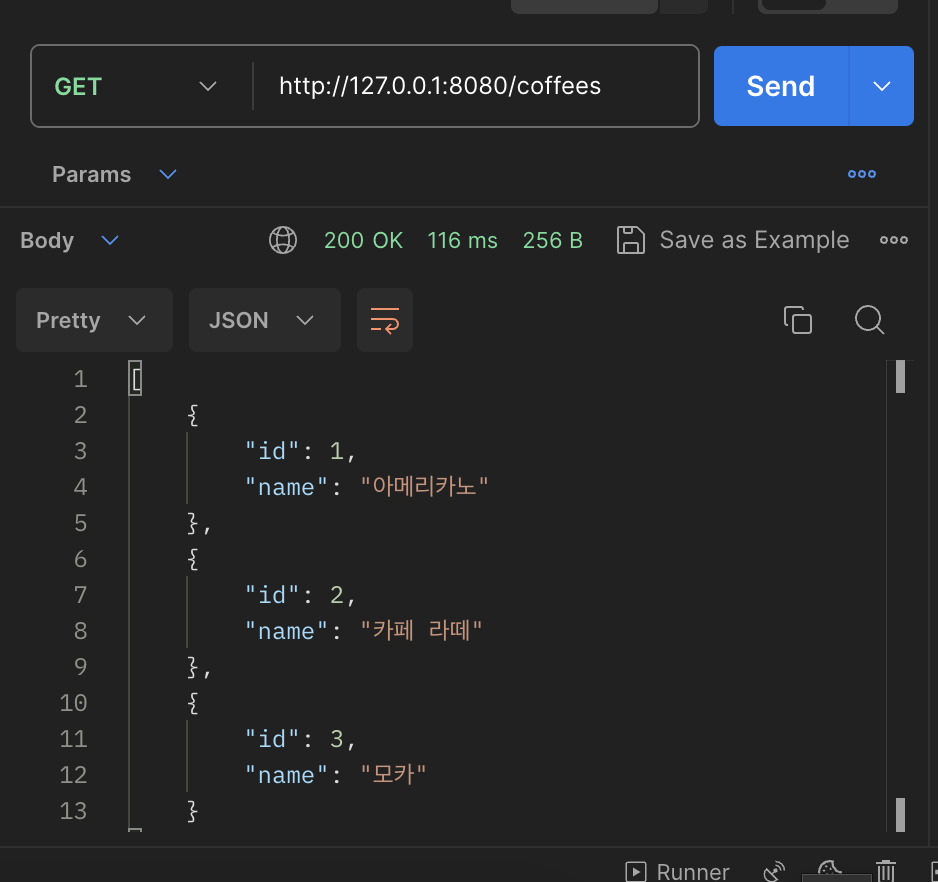
아니 아무것도 안넣고 해당 클래스만 추가해도 @AutoWired로 객체를 자동 주입하고 @PreConstruct로 알아서 초기데이터까지 넣어주는데 이게 스프링인가..?
공부해야할 것
@Component,@Preconstruct어노테이션에 대해- JPA란 무엇이고, repository(저장소)는 무엇인가?
- JPA 프록시와 지연로딩이 무엇인가?
@Autowired의 동작과정에 대해
참고 자료
