Launch에 대해
Launch에 대해 어떻게 설명하고 있는지 부터 알아보자.
현재 쓰레드를 차단하지 않고 새 코루틴을 실행하고 job을 반환한다.
job을 이용해 코루틴을 참조할 수 있다.
코루틴 스코프는 코루틴 콘텍스트를 상속받고 있으며 추가적인 콘텍스트를 추가할 수 있다.
- ContinuationInterceptor
- dispatcher
등등.. 디스패쳐의 기본 값은 Dispatchers.Default이다.
코루틴의 생성은 DEFAULT, LAZY, ATOMIC, UNDISPATCHED의 옵션을 가질 수 있으며 이는 각각
- DEFAULT - 코루틴을 즉시 예약
- LAZY - 필요할 때 코루틴을 시작
- ATOMIC - 원자적인(취소 불가능한 방식) 실행을 위한 루틴을 예약
- UNDISPATCHED - 현재 스레드의 첫 번째 중지 point까지 코루틴을 실행
기본값은 DEFAULT이다.
코루틴에서의 예외는 기본적으로 parent job을 취소한다. (ExceptionHandler가 명시적으로 지정하지 않는 경우)
이는 다른 코루틴의 컨텍스트와 함께 코루틴을 사용할 경우 예외가 부모 코루틴의 취소로 이어지는 것을 의미한다.
매개 변수
- context - Coroutine의 CoroutineScope.coroutineContext
- start - 코루틴 시작 옵션. 기본값은 CoroutineStart
- block - 제공된 스코프의 컨텍스트에서 호출될 코루틴 코드
지정할 수 있는 컨텍스트는 다음과 같다.
어떤 스레드에서 코루틴을 돌릴지를 정의하는 것
- Dispatcher.Main - 메인 스레드에서 동작(UI쓰레드)
- Dispatcher.IO - 네트워크 / 디스크(파일) 작업에 사용하는 방식
- Dispatcher.Default - CPU사용량이 많은 작업에 수행
IO,Default는 같은 쓰레드 풀을 활용합니다. 스케줄링 방식이 다를 뿐입니다.
코루틴이 중단되면(에러가 나거나, Thread.interrupt) job은 캔슬되고 코루틴은 InterruptedException을 발생시킨다.
Job: 코루틴의 상태를 가지고 있으며 제어한다.
Job은 하나의CoroutineContext.Element이고,CoroutineScope.coroutineContext에는 반드시Job이 포함되어 있어야만 한다.
간단하게 메인함수에서 코루틴을 생성해보자.
fun main() {
runBlocking{
println("Start")
launch {
task1("task1")
}
launch(Dispatchers.Unconfined) {
task1("task2")
}
val job = launch(
context = EmptyCoroutineContext,
start = CoroutineStart.LAZY
) {
task1("task3")
}
delay(4000L)
job.join()
println("End")
}
}
suspend fun task1(task: String) {
println("$task Working Thread Started : ${Thread.currentThread().name}")
delay(1000L)
println("$task Working Thread Ended : ${Thread.currentThread().name}")
}출력결과
Start
task2 Working Thread Started : main
task1 Working Thread Started : main
task1 Working Thread Ended : main
task2 Working Thread Ended : kotlinx.coroutines.DefaultExecutor
task3 Working Thread Started : main
task3 Working Thread Ended : main
End유의할점은 다음과 같다.
task1는 start =CoroutineStart.DEFAULT로 코루틴을 "예약"task2는 context =CoroutineStart.Unconfined를 통해task2 Started를 먼저 출력하고 첫 번째 중지 포인트인delay(1000L)에서 중지CoroutineStart.Unconfined는 어떤 쓰레드이든 일단 코루틴을 즉시 실행하고 중지된 후에는 코루틴이 무엇이든 재게된다. (continuation.resume()을 통해 어디서든 실행되고 재개됨) 따라서
Task2의Ended는kotlinx.coroutines.DefaultExecutor가 찍힘을 볼 수 있다.task3은start=CoroutineStart.LAZY임으로 delay(4000L)이후 실행되는 것을 볼 수 있다.
내부 소스를 톺아보자
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}위에서 설명한것과 같이 context, start를 매개변수로 코루틴을 생성하고 이는 Job을 반환한다.
val newContext = newCoroutineContext(context)
@ExperimentalCoroutinesApi
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = foldCopies(coroutineContext, context, true)
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug
}코루틴스코프의 코루틴콘텍스트와 매개변수로 입력된 새로운 context를 복사하여 새로운 콘텍스트를 만들어 낸다.
runBlocking{
launch {
task1("task1")
}
}위의 launch는 RunBlocking의 코루틴 스코프의 GlobalScope.coroutineContext와 Default context인 EmptyContext를 활용하여 새로운 콘텍스트를 만들어 낼 것 이다.
val coroutine = if (start.isLazy) LazyStandaloneCoroutine(newContext, block) else StandaloneCoroutine(newContext, active = true)
레이지 코틀린생성자는 다음과 같다.
private class LazyStandaloneCoroutine(
parentContext: CoroutineContext,
block: suspend CoroutineScope.() -> Unit
) : StandaloneCoroutine(parentContext, active = false) {
private val continuation = block.createCoroutineUnintercepted(this, this)
override fun onStart() {
continuation.startCoroutineCancellable(this)
}
}이는 코루틴 인터셉터인 continuation를 선언하고 코루틴의 시작이 감지되면 코루틴을 시작한다.
레이지가 아닌 형태의 기본 코루틴은 다음과 같이 만들어진다.
private open class StandaloneCoroutine(
parentContext: CoroutineContext,
active: Boolean
) : AbstractCoroutine<Unit>(parentContext, initParentJob = true, active = active) {
override fun handleJobException(exception: Throwable): Boolean {
handleCoroutineException(context, exception)
return true
}
}@InternalCoroutinesApi
public abstract class AbstractCoroutine<in T>(
parentContext: CoroutineContext,
initParentJob: Boolean,
active: Boolean
) : JobSupport(active), Job, Continuation<T>, CoroutineScope {
init {
if (initParentJob) initParentJob(parentContext[Job])
}
public final override val context: CoroutineContext = parentContext + this
public override val coroutineContext: CoroutineContext get() = context
// ...
}위에서 생성한 newContext를 parentContext라는 인자로 전달하여 AbsractCoroutine을 반환한다.
또한 handleJobException 오버라이드 받아 exception이 일어났을 때 context와 exception을 가지고 에러를 처리하는데
context는 다음과 같이 정의되어 있다.
public final override val context: CoroutineContext = parentContext + this즉 부모의 context와 자신을 더한것을 context로 정의하고 있다. 여기서 자신은 Job으로의 this이다.
context에
Job을 어떻게 더할 수 있나?
Job : CoroutineContext.ElementJob은 코루틴 콘텍스트의 요소로 정의되어 있으며
public operator fun plus(context: CoroutineContext): CoroutineContext
Job내에서 해당 연산자를 구현해 주고 있다.
다시 강조하자면
CoroutineScope.coroutineContext에는 coroutine의 실행을 위한 여러가지 정보가 담기지만, 가장 중요한 것은 coroutine의 Job을 저장하는 것이다. Job은 하나의 CoroutineContext.Element이고, CoroutineScope.coroutineContext에는 반드시 Job이 포함되어 있어야만 한다
생성된 새로운
newContext즉parentContext에 대한 잡을 생성하기위해AbstractCoroutine의 생성자에서는 부모의 Job에 자식의 Job을 더해주고있다.
initParentJob(parentContext[Job])
Job은 부모-자식의 트리형태의 예는 다음과 같다.
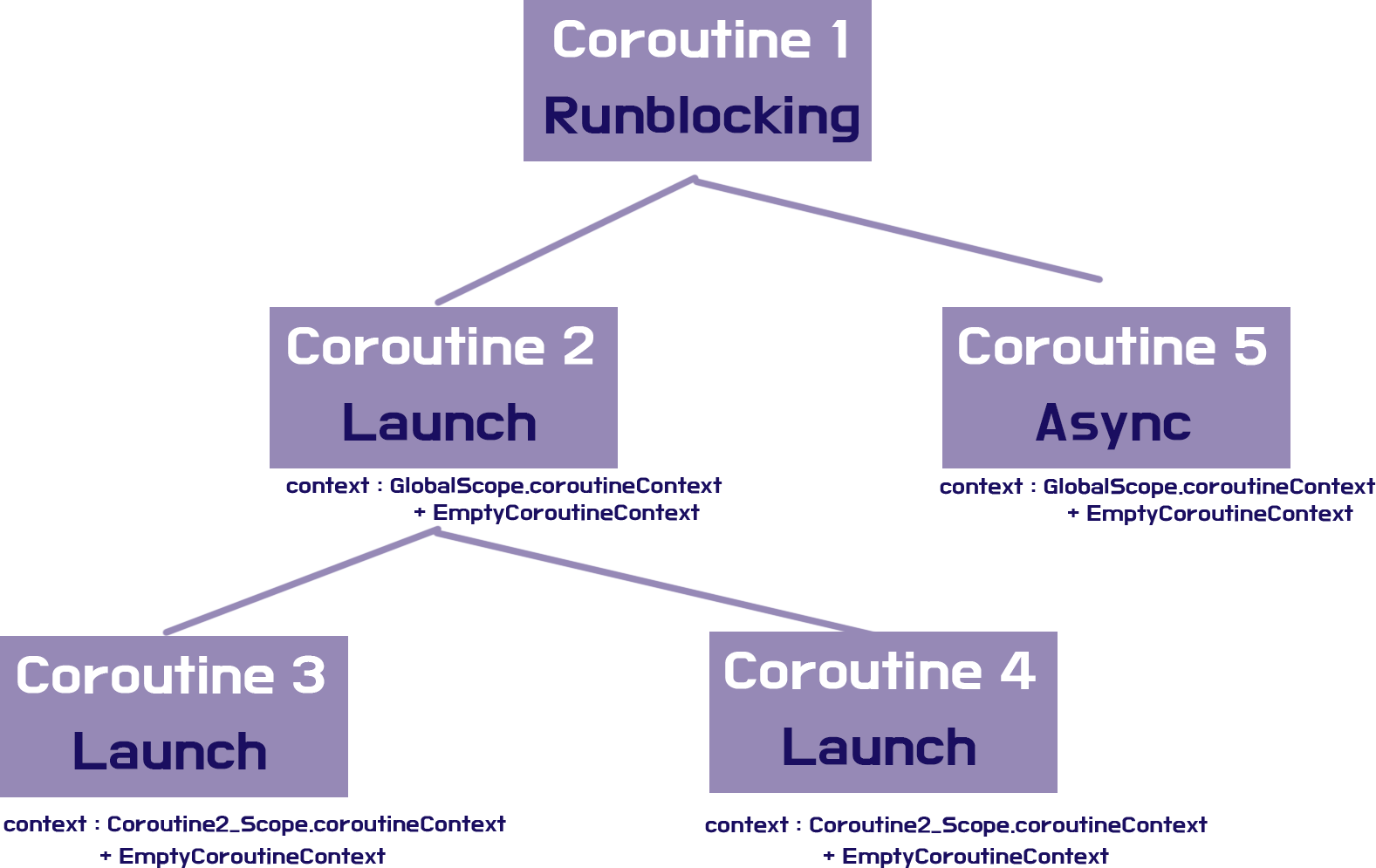
fun main() = runBlocking {
// coroutine 1
launch {
// coroutine 2
launch {
// coroutine 3
}
launch {
// coroutine 4
}
}
asyce {
// coroutine 5
}
}
coroutine.start(start, coroutine, block)
/* AbstractCoroutine.start()의 구현 */
public fun <R> start(start: CoroutineStart, receiver: R, block: suspend R.() -> T) {
start(block, receiver, this)
}start: launch {} 를 실행할 때 아규먼트로 넣은start를 의미 (활동할 쓰레드를 정의)receiver:newContext를 사용해 만든 coroutine을 의미한다.block: launch {} 안의 내용
을 이용해 새로운 코루틴을 시작한다.
return coroutine
코루틴을 반환하되 Job의 형태로 반환한다.
Job을 사용해 코루틴을 제어할 수 있기 때문이다.
Async에 대해
제공하는 설명
코루틴을 만들고 이후 결과를 Deffered로 반환한다.
결과(Deffered)가 취소되면 코루틴도 취소된다.
deffered값은 await()함수를 이용해 기다릴 수 있다.
fun main() {
runBlocking(context = EmptyCoroutineContext){
println("Start")
launch {
task1("task1")
}
val deffered = async {
// TODO task4의 결과 값 계산 로직
"task4결과 값"
}
delay(4000L)
println(deffered.await())
println("End")
}
}
// 출력
Start
task1 Working Thread Started : main
task1 Working Thread Ended : main
task4결과 값
End결과 코루틴은 각각의 키를 가지고 있으며 부모의 Job이 실패할시 작업을 취소한다.
async {
throw Exception("task1실패")
}
launch {
task1("task2") // 실행되지 않는다.
}
// 출력
Start
Exception in thread "main" java.lang.Exception: task1실패이러한 작업을 방지하기 위해 이러한 (Supervisor Job 또는 Supervisor Scope)를 사용할 수 있다.
runBlocking(context = EmptyCoroutineContext){
println("Start")
val supervisor = SupervisorJob()
launch(Dispatchers.IO + supervisor) {
throw AssertionError("task1실패")
launch {
task1("task2")
}
}
val deffered = async(Dispatchers.IO + supervisor) {
// TODO task4의 결과 값 계산 로직
"task4결과 값"
}
delay(4000L)
println(deffered.await())
println("End")
}
// 실행결과
Start
Exception in thread "DefaultDispatcher-worker-1" java.lang.AssertionError: task1실패
task4결과 값
EndSupervisor Job을 활용하여 코루틴에서 에러가 발생할 때 이를 부모에 전파하지 않을 수 있다. 형제 코루틴은 잘 실행되는 것을 볼 수 있다.
start 파라미터를 LAZY로 설정하여 지연되게 시작할 수 있으며 Join, wait 또는 waitAll을 처음 호출할 때 코루틴이 시작된다.
(Lazy로 하지 않으면 해당 함수가 호출되어 에러가 바로 발생할 수 있음)
내부 생성자
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
launch와 동일하되 coroutine을 생성할 때 DeferredCoroutine()를 사용하여 생성한다.
@Suppress("UNCHECKED_CAST")
private open class DeferredCoroutine<T>(
parentContext: CoroutineContext,
active: Boolean
) : AbstractCoroutine<T>(parentContext, true, active = active), Deferred<T>, SelectClause1<T> {
override fun getCompleted(): T = getCompletedInternal() as T
override suspend fun await(): T = awaitInternal() as T
override val onAwait: SelectClause1<T> get() = this
override fun <R> registerSelectClause1(select: SelectInstance<R>, block: suspend (T) -> R) =
registerSelectClause1Internal(select, block)
}DeferredCoroutine()생성자는 AbstractCoroutine을 상속받되, Deffered도 상속받는다.
이는 차단 불가능한 결과가 있는 Job이다.
그렇다면 의문이 생길 수 있다. 코루틴은 쓰레드위에서 돌아가고 쓰레드위에서 돌아가는 async {}의 결과 값은 멀티쓰레드로부터 원자성을 지니고 있는가?
All functions on this interface and on all interfaces derived from it are thread-safe and can be safely invoked from concurrent coroutines without external synchronization.
Deffered를 상속받는 인터페이스의 모든 기능은 쓰레드로부터 안전하며 외부 동기화 없이 동시 코루틴에서 안전하게 호출될 수 있다고 한다.
하지만 파생된 모든 인터페이스에 어떤 메소드가 추가될지 모르기 때문에 모든 서드파티 라이브러리에서 모두 안전하지는 않는다.
async {}에서는 Job을 state라는 프로퍼티로 관리하며 이는 완료되면 Incomplete상태가 되며 unboxState를 활용해 유저 코드에 대한 값을 얻을 수 있다.
internal fun getCompletedInternal(): Any? {
val state = this.state
check(state !is Incomplete) { "This job has not completed yet" }
if (state is CompletedExceptionally) throw state.cause
return state.unboxState()
}- state 내부 소스
internal val state: Any? get() {
_state.loop { state -> // helper loop on state (complete in-progress atomic operations)
if (state !is OpDescriptor) return state
state.perform(this)
}
}Job을 관리하는 프로퍼티를 구현하고 있기 때문에 await(), getCompleted()등의 함수를 구현 가능하다.
이후 AbstractCorotine()을 만드는 과정은 동일하다.
RunBlocking에 대해
제공하는 설명
새 코루틴을 실행하고 완료될 때까지 현재 스레드를 중단 없이 차단한다.
이 기능은 코루틴에서 사용해서는 안된다고 권장하고 있으며 suspend함수의 도메인 로직 테스트용으로만 쓰이도록 설계되었다.
사용되는 CoroutineDispatcher에서 해당 코루틴이 완료될 때 까지 block()내의 코드를 실행한다.
실제 runBlocking 함수를 뜯어보자.
@Throws(InterruptedException::class)
public actual fun <T> runBlocking(context: CoroutineContext, block: suspend CoroutineScope.() -> T): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
val currentThread = Thread.currentThread()
val contextInterceptor = context[ContinuationInterceptor]
val eventLoop: EventLoop?
val newContext: CoroutineContext
if (contextInterceptor == null) {
// create or use private event loop if no dispatcher is specified
eventLoop = ThreadLocalEventLoop.eventLoop
newContext = GlobalScope.newCoroutineContext(context + eventLoop)
} else {
// See if context's interceptor is an event loop that we shall use (to support TestContext)
// or take an existing thread-local event loop if present to avoid blocking it (but don't create one)
eventLoop = (contextInterceptor as? EventLoop)?.takeIf { it.shouldBeProcessedFromContext() }
?: ThreadLocalEventLoop.currentOrNull()
newContext = GlobalScope.newCoroutineContext(context)
}
val coroutine = BlockingCoroutine<T>(newContext, currentThread, eventLoop)
coroutine.start(CoroutineStart.DEFAULT, coroutine, block)
return coroutine.joinBlocking()
}위의 함수가 실행되며 어떤 일이 일어나는가?
contract를 통한 컴파일러에게 실행횟수 전달
Specifies that the function parameter lambda is invoked in place.
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}callsInPlace는 람다 함수를 사용할 때, 그 함수의 호출 횟수를 명시적으로 컴파일러에게 이해시켜주기 위해 사용
해당 block을 1번만 실행시킨다는 것을 컴파일러에게 전달
왜 전달해야 하는가?
fun main(){
val str: String
invokeLambda {
str = "TEMP" // ERROR! 재할당 가능성으로 인해 캡처된 값 초기화가 금지되었습니다.
}
}
fun invokeLambda(lambda: ()-> Unit){
lambda()
}블록으로 전달된 람다식을 1번만 실행할거라는 보장이 없기 때문에 setter을 한번밖에 할 수 없는 str은 오류를 발생하게 된다.
fun invokeLambda(lambda: ()-> Unit){
// 해결!!
contract {
callsInPlace(lambda, InvocationKind.EXACTLY_ONCE)
}
lambda()
}현재 쓰레드 가져와서 park 및 unpark 수행
val currentThread = Thread.currentThread()
// ...
val coroutine = BlockingCoroutine<T>(newContext, currentThread, eventLoop)
}
coroutine.start(CoroutineStart.DEFAULT, coroutine, block)
return coroutine.joinBlocking()현재 쓰레드 상태를 가져온 후 해당 상태와 함께 coroutine을 생성하고 시작한다.
해당 코루틴은 BlockingCoroutine이며 생성자는 다음과 같다.
private class BlockingCoroutine<T>(
parentContext: CoroutineContext,
private val blockedThread: Thread,
private val eventLoop: EventLoop?
) : AbstractCoroutine<T>(parentContext, true, true) {
// ...
override fun afterCompletion(state: Any?) {
// wake up blocked thread
if (Thread.currentThread() != blockedThread)
unpark(blockedThread)
}
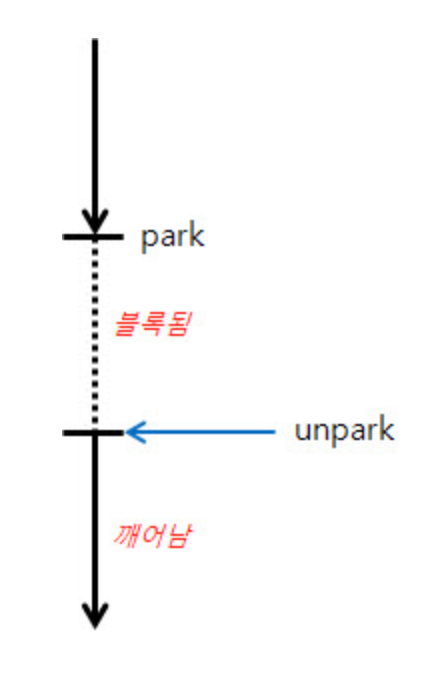
}코루틴의 joinBlocking() 함수가 Java의 LockSupport를 사용하여 현재 스레드를 파킹(차단)한다.
이후
afterCompletion()함수 내에서 파킹한 쓰레드에 대한 unpark를 진행하고 있다.
- park : 쓰레드를 잠구는 것 (남이 사용하지 못하게 재우는 것을 의미)
- unpark : 쓰레드를 깨우는 것 쓰레드를 사용할 수 있게 풀어줌
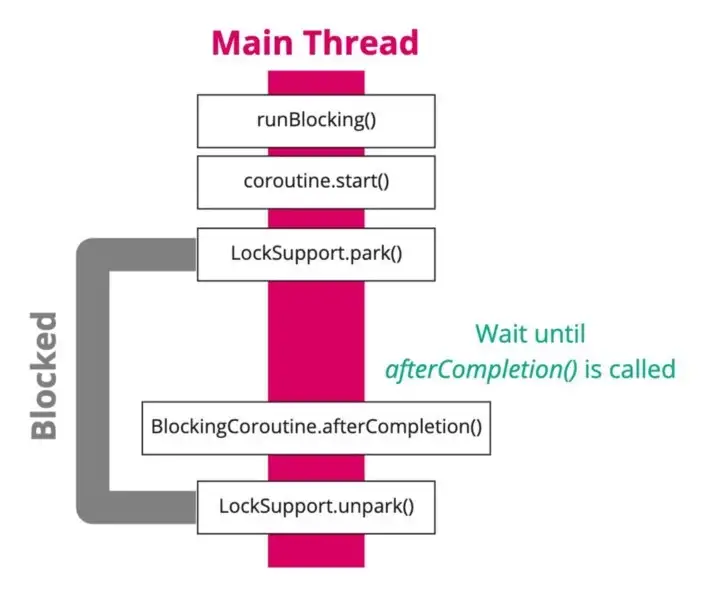
이와 같이 runblocking을 실행할 때 현재 스레드를 중단 없이 차단한 것을 볼 수 있다.
runBlocking은 다음과 같은 기능을 하기 때문이다.
새 코루틴을 실행하고 완료될 때까지 현재 스레드를 중단 없이 차단한다.
Launch와 Aysnc에서는 부모의 Job에 자식의 Job을 합친다
AbstractCoroutine는 다음과 같이 정의된다.
@InternalCoroutinesApi
public abstract class AbstractCoroutine<in T>(
parentContext: CoroutineContext,
initParentJob: Boolean,
active: Boolean
) : JobSupport(active), Job, Continuation<T>, CoroutineScope {
init {
if (initParentJob) initParentJob(parentContext[Job])
}
// ...
}- coroutine이 생성될 때,
parentContext를 인자로 받아온다.
// dipatcher 파라미터를 정의하지 않았을 때
eventLoop = ThreadLocalEventLoop.eventLoop
newContext = GlobalScope.newCoroutineContext(context + eventLoop)
// dispatcher 파라미터를 정의했을 때
newContext = GlobalScope.newCoroutineContext(context)- parentContext에서 부모의 Job을 빼온다
initParentJob(parentContext[Job])- 자신의 job(자기 자신)을 부모의 child로 붙인다
val handle = parent.attachChild(this).코루틴내에서 또 코루틴이 생성되면 이 job은 트리의 형태가 이루어지게 된다.
여기서 AbastractCoroutine 즉 Coroutine은 자기 자신이 CoroutineScope이며 Job이다.
- CoroutineScope - coroutine은 자기 자신이 scope가 되어 자신의 code block 안에서 자식 coroutine을 실행할 수 있다.
또한, 자신의 coroutine context를 자식 coroutine에게 전달할 수 있다(e.g. 위에서 본 parentContext 주입 등).
runBlocking에서도 그렇게 돌아갈까?
public actual fun <T> runBlocking(context: CoroutineContext, block: suspend CoroutineScope.() -> T): T {
val eventLoop: EventLoop?
val newContext: CoroutineContext
if (contextInterceptor == null) {
// 디스패처가 지정되지 않은 경우 개인 이벤트 루프 생성 또는 사용
eventLoop = ThreadLocalEventLoop.eventLoop
newContext = GlobalScope.newCoroutineContext(context + eventLoop)
} else {
newContext = GlobalScope.newCoroutineContext(context)
}
val coroutine = BlockingCoroutine<T>(newContext, currentThread, eventLoop)
coroutine.start(CoroutineStart.DEFAULT, coroutine, block)
return coroutine.joinBlocking()
}runBlocking의 디스패쳐로 받아온 context를 활용해 GlobalScope.newCoroutineContext을 실행시켜 새로운 context를 사용하는 코루틴을 시작하고있다.
newCoroutineContext는 다음과 같이 실행된다.
@ExperimentalCoroutinesApi
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = foldCopies(coroutineContext, context, true)
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug
}val combined는 현재 CoroutineScope의 Context와 context param을 더해 반환하고 있다.
- coroutineContext는 GlobalScope의 context
- context에는 eventLoop라는 element밖에 없음을 볼 수 있다.
// dipatcher 파라미터를 정의하지 않았을 때
eventLoop = ThreadLocalEventLoop.eventLoop
newContext = GlobalScope.newCoroutineContext(context + eventLoop)
// dispatcher 파라미터를 정의했을 때
newContext = GlobalScope.newCoroutineContext(context)이는 BlockingCoroutine은 Job 대신 eventLoop를 사용하는 것을 알 수 있다.
그 이유는 BlockingCoroutine의 joinBlocking()함수에서 볼 수있다.
@Suppress("UNCHECKED_CAST")
fun joinBlocking(): T {
registerTimeLoopThread()
try {
eventLoop?.incrementUseCount()
try {
while (true) {
@Suppress("DEPRECATION")
if (Thread.interrupted()) throw InterruptedException().also { cancelCoroutine(it) }
val parkNanos = eventLoop?.processNextEvent() ?: Long.MAX_VALUE
/* note: process next even may loose unpark flag, so check if completed before parking */
if (isCompleted) break
parkNanos(this, parkNanos)
}
} finally { /* paranoia */
eventLoop?.decrementUseCount()
}
} finally { /* paranoia */
unregisterTimeLoopThread()
}
/* now return result */
val state = this.state.unboxState()
(state as? CompletedExceptionally)?.let { throw it.cause }
return state as T
}while문 안 쪽을 잘 보면 isCompleted가 true일 때, 즉 event loop의 queue가 비었을 때 종료됨을 알 수 있다.
즉, runBlocking 으로 실행된 coroutine은 부모 coroutine 없이(따라서 부모 Job 없이) 실행된다.
추가 : isCompleted는 Atomic Type은으로 한 번에 단 하나의 스레드만 변수의 값을 변경할 수 있도록 제공하고 있다
lock 없이 동기화 처리 수행
private val _isCompleted = atomic(false)
private var isCompleted
get() = _isCompleted.value
set(value) { _isCompleted.value = value }parkNanos란?
LockSupport()에서 쓰레드를 제어하기위해 제공하는 함수로
대기 시간까지 스레드 스케줄링을 위해 현재 스레드를 비활성화한다.
while문 안에서 parkNanos의 setter는 다음과 같다.
- 다음 이벤트가 있으면 해당 이벤트를 실행하고
0을 반환 - 이벤트가 없으면
Long.MAX_VALUE를 반환
public open fun processNextEvent(): Long {
if (!processUnconfinedEvent()) return Long.MAX_VALUE
return 0
}
public fun processUnconfinedEvent(): Boolean {
val queue = unconfinedQueue ?: return false
val task = queue.removeFirstOrNull() ?: return false
task.run()
return true
}이벤트가 있으면 parkNanos() 를 실행한다.
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
U.park(false, nanos);
setBlocker(t, null);
}
}다음 실행할 이벤트가 없어서 nanos가 Long.MAX_VALUE이면 해당쓰레드를 park하고
TIMED_WAITING 상태로 진입한다.
다음 이벤트가 들어와 unpark가 되기 전까지 대기한다.
RunBlocking 정리
runBlocking : 새 코루틴을 실행하고 완료될 때까지 현재 스레드를 중단 없이 차단한다.
-
runbocking이
joinBlocking()되면서 현재 쓰레드를 중단 없이 차단한다. -
eventLoop라는 아규먼트를 사용해 newContext를 생성한다.
-
runBlocking의 경우는 eventLoop를 활용하여 task들을 큐로 관리한다.
-
각각의 task들을 실행하며 실행할 때 마다 parkNanos를 활용하여 해당 쓰레드를 unpark, park를 수행한다.
-
runblocking의 모든 task가 끝나면 현재 쓰레드를 unpark한다.
구조화된 동시성(Structured Concurrency)의 근거
코루틴은 생성될 때 부모의 CorocutineScope.coroutineContext 및 생성되는 코루틴의 context를 더하여 새로운 newContext를 생성한다. 코루틴이 생성될 때는 해당 newContext의 코루틴이 생성되는 것이다.
또한 생성된 newContext를 기반으로 부모의 Job에 자식의 Job을 더한다
그렇다면 왜 에러가 부모 코루틴으로 전파될까?
AbstractCoroutine이 상속받는 JobSupport 클래스의 finalizeFinishingState()함수를 살펴보자.
private fun finalizeFinishingState(state: Finishing, proposedUpdate: Any?): Any? {
// ...
if (finalException != null) { // 예외로 인한 종료 시 진입
val handled = cancelParent(finalException) || handleJobException(finalException)
if (handled) (finalState as CompletedExceptionally).makeHandled()
}
// ...
}cancelParent는 현재 코루틴에서 발생한 예외를 부모 코루틴으로 전달함으로써 예외 처리를 요청하는 함수이다. true를 반환한다면 예외가 부모에 의해 처리된다는 것이고, false를 반환한다면 예외는 부모에 의해 처리될 수 없으니 현재 코루틴이 처리해야 한다는 것이다.
handleJobException은 전달되는 예외를 가능한 예외 처리 방식으로 처리를 한다. 예외를 처리하는 경우에는 true, 그렇지 않은 경우는 false로 반환된다.
cancleParent와handleJobException은Or연산자로cancelParent가 true일 경우handleJobException은 실행되지 않는다.
최상위에 위치하는 루트 코루틴을 제외한 나머지 자식 코루틴들은 일반적으로는 cancelParent()에서 true를 반환받고 handleJobException() 함수를 실행하지 않는다.
오류를 전파 받은 루트 코루틴만이 cancelParent() 함수에서 false를 반환받고, handleJobException() 을 실행한다.
CancelParent()
private fun cancelParent(cause: Throwable): Boolean {
if (isScopedCoroutine) return true
val isCancellation = cause is CancellationException
val parent = parentHandle
if (parent === null || parent === NonDisposableHandle) {
return isCancellation
}
return parent.childCancelled(cause) || isCancellation
}ScopedCoroutine일 경우에는
부모 코루틴에 예외 전파 없이 곧바로 true를 반환하여 현재 코루틴이 예외를 처리하지 않게 한다.
대표적인 ScopedCoroutine으로는 coroutinScope, supervisorScope, runBlocking 등의 코루틴 빌더들로부터 생성되는 코루틴들을 그 예로 들 수 있다.
이러한 ScopedCoroutine 들은 코루틴들의 실행 범위를 제한하기 위한 목적의 코루틴들로 스코프 내에서 실행 된 코루틴들에서 발생한 예외를 스코프 외부로 그대로 전달하는 동작만 수행하기 때문
새로운 Job을 새로 생성한 코루틴이라 생각하면 됨
부모 코루틴이 없는 경우 (parent === null || parent === NonDisposableHandle)
cause is CancellationException예외가 취소로 인한 예외인지 확인하고 취소이면 true를 반환한다. (취소 예외는 코루틴의 전체 스코프를 취소하기 위해 사용되며 정상적인 상황으로 간주되기 때문)
코루틴은 Scoped Coroutine도 아니며 Root Coroutine도 아닐 때
부모 코루틴의 핸들인 parent 객체에 childCancelled(cause) 함수를 호출하여 예외를 전파한다.
parent.childCancelled(cause)
internal class ChildHandleNode(
@JvmField val childJob: ChildJob
) : JobCancellingNode(), ChildHandle {
override val parent: Job get() = job
override fun invoke(cause: Throwable?) = childJob.parentCancelled(job)
override fun childCancelled(cause: Throwable): Boolean = job.childCancelled(cause)
}childCancelled()를 보면 트리 구조로 생성된 부모 코루틴의 job을 이용하여 예외를 전달하고 있다. 자식은 Throwable에 의해 취소되며, 예외가 처리되면 true를 반환하며, 그렇지 않으면 false를 반환한다.
SupervisorJob인 경우는 부모 코루틴의 취소 동작 없이 바로 false를 반환한다. 따라서 부모 코루틴으로 예외를 전파하려던 코루틴은 아래에서 살펴볼handleJobException()함수를 통해 직접 예외를 처리해야 함
handleJobException()
handleJobException은 예외를 처리하는 경우에는 true, 그렇지 않은 경우는 false로 반환된다.
cancelParent()가 false를 반환할 경우 현재 코루틴에서 예외처리를 위해서 호출되는 handleJobException() 코드를 살펴보자.
// Standalone Coroutine
override fun handleJobException(exception: Throwable): Boolean {
handleCoroutineException(context, exception)
return true
}
// Deferred Coroutine
protected open fun handleJobException(exception: Throwable): Boolean = false
public fun handleCoroutineException(context: CoroutineContext, exception: Throwable) {
try {
context[CoroutineExceptionHandler]?.let {
it.handleException(context, exception)
return
}
} catch (t: Throwable) {
handleCoroutineExceptionImpl(context, handlerException(exception, t))
return
}
handleCoroutineExceptionImpl(context, exception)
}launch와 async는 서로 에러를 처리하는 방법이 다르다.
- launch : StandaloneCoroutine
launch로 생성된 코루틴은 handleJobException를 오버라이드하여 Job에 대한 예외처리를 context와 함께 정의하고 있다.
public final override val context: CoroutineContext = parentContext + this이는 부모의 context를 의미하며 부모 코루틴에 에러를 전파하여 그에 따른 예외처리를 수행한다. 따라서 예외를 처리한 후 true를 반환하는 것을 볼 수 있다.
- async 빌더 : DeferredCoroutine
async로 생성된 코루틴은 따로 예외 핸들링을 구현하지 않기 때문에 기본 구현인 false를 반환하고 다른 방식으로 예외처리를 한다.
protected open fun handleJobException(exception: Throwable): Boolean = falseDeferredCoroutine의 경우 코루틴 실행 후 반환받은 핸들인 Deferred<T>에 await() 함수를 호출하면 코루틴이 예외로 인해 종료되었을 경우 발생했던 예외가 다시 발생하게 된다. 때문에 따로 오버라이드하지 않고 false를 반환하는 것을 볼 수 있다.
기본적으로 코루틴은 Job트리(코투린트리)를 구성함으로써 해당 부모의 Job까지 트리 구조를 통해 연결할 수 있기 때문에 오류가 전파되는 것이다.
예외는 자식부터 부모까지 방향으로 전파되고 cancelParent()==false인 부모에서 최종적으로 처리된다.
코루틴이 async같은 빌더를 통해 생성된 DeferredCoroutine인 경우는 await()를 실행할 때 오류가 전파되며 부모 코루틴의 Job이 SupervisorJob인 경우에는 오류가 더이상 위로 전파되지 않는다.
정리
-
코루틴은 중첩되면서 코투린트리(Job 트리)를 생성한다.
-
에러가 발생하면
cancelParent를 실행하여 부모의 코루틴을 종료시킨다.
부모 코루틴이 스코프 코루틴이 아니거나, 부모 코루틴이 없거나, SupervisorJob이면true를 반환하고, 그렇지 않으면false를 반환한다. -
handleJobException를 실행하여 예외를 처리하며 처리되면true, 그렇지 않은 경우false를 반환한다.
- Launch와 Async는 에러를 처리하는 방식이 다르다.
launch는
handleCoroutineException를 오버라이드하여 부모의 context에서 에러를 처리한 후 true를 반환한다.
async는 false를 기본적으로 반환하며 await()가 수행될 때 해당 에러를 처리한다.
cancelParentOrhandleJobException이 true이면 Job을 종료한다.
참고 자료
https://suhwan.dev/2022/01/21/Kotlin-coroutine-structured-concurrency/
https://suhwan.dev/2022/01/21/Kotlin-coroutine-structured-concurrency/
https://applefarm.tistory.com/124
https://velog.io/@l2hyunwoo/Kotlin-Coroutine-Basics
https://velog.io/@l2hyunwoo/Kotlin-Coroutine-Create-a-basic-coroutine
