
연구개발 일지: 박찬
- 2021.07.01
리눅스 명령어 및 기본 사용법 공부
- 현재 디렉터리를 알려주는: pwd
- 디렉터리 구조의 이해와 디렉터리 이동하기(cd)
- 현재 디렉터리 표현법, 절대 경로와 상대경로 이해하기
- 상위 디렉터리, 홈 디렉터리, 임시 디렉터리 /tmp
- 디렉터리의 정보 파악: ls
- 파일, 디렉터리 조작을 위한 기본 명령어들
개발환경 셋팅 1번째
- pytorch 설치

- CUDA Toolkit 설치

- 명령어 입력
$ wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
$ sudo sh cuda_11.2.0_460.27.04_linux.run
- Anaconda3 설치
- 다음으로 설치에서 생긴 환경 변수의 변경을 적용하기 위해 bashrc를 실행시킨다.
source ~/.bashrc환경 변수 적용이 완료되고 설치가 정상적으로 완료 되면 (base) 표시가 생성된다.
- 다음으로 conda 명령어를 사용해서 설치를 확인한다.
conda --version
conda search python # 사용 가능한 python 버전 출력하는 명령어소셜그룹 이미지 데이터셋 구축 방법 구상
-
각 그룹별 나눠서 데이터를 구축해야할 것 같다고 생각해 먼저 그룹을 나눴다.
가족 , 친구 , 연인 , 직장동료 , 기타 등등
-
나눈 그룹별 이미지를 캐글을 통해 데이터를 수집했다.
- 2021.07.02
-
개발환경 셋팅 2번째
- cuDNN 8.1.0 설치
-
다운로드 받은 파일을 압축풀어서 파일 복사합니다.
$ cd 다운로드
$ tar xvzf cudnn-11.2-linux-x64-v8.1.0.77.tgz
$ sudo cp cuda/include/cudnn* /usr/local/cuda/include
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
- Tensorflow 설치
- pip 명령을 사용하여 tensorflow를 설치합니다.
$ pip3 install tensorflow
- python에서 tensorflow 모듈을 불러와서 설치가 제대로 되었는지 확인합니다.
$ python3 >> import tensorflow as tf (모듈 로드) >> tf.__version__ (버전 확인) >> tf.config.list_physical_devices('GPU') (GPU 체크)
- Pycharm 설치
- 커뮤니티 버전 다운
- Docker 설치
- 강력하게 독립 환경을 구성하기 위해 Docker 활용
PISC (People in Social Context)
- 사회적 관계에 초점을 맞춘 Dataset
- 9가지 유형의 사회적 관계에 대한 22,670개의 이미지 다운
- 한 이미지에 하나 이상의 그룹이 있는 이미지를 판단하여 제거
1. PISC 라는 가상환경 만들고 pytorch 설치
실행 후 cuda, cudnn 설치 확인
$ python >> import torch >> torch.cuda.is_available() True >> torch.backends.cudnn.enabled True
2. 가상환경과 pycharm 연동
인터프리터 세팅
3. Test
코드 작성 중

- 2021.07.05
모델 학습

- Pytorch
- python Version : 3.9
- 전체 데이터 개수 : 약 26000장
문제점
- 모든 이미지가 다 섞여 있어서 새로 모델링을 하기 위해 클래스별 분류 과정 필요
- 한 이미지에 하나 이상의 클래스가 들어있는 경우
1차 Goals
- 데이터 전처리를 통해 이미지를 5가지 클래스로 분류 (friends / couple / family / professional / no relation)
- 5개 Label Classify 정확도를 50% 이상 만들기
- Model 성능을 개선하여 Detecting에 대한 성능 향상
CNN 모델 학습
모델을 훈련하려면 이미지와 레이블이 첨부 된 데이터 세트가 필요합니다. 그러나 일반적으로 이미지 분류에 사용할 수있는 데이터 세트는 해당 폴더에 저장된 이미지로 구성됩니다. 데이터 세트는 5가지 유형의 이미지로 구성되며 해당 폴더에 저장됩니다.
이러한 구조에서 데이터 세트를 준비하기 위해 PyTorch는 데이터 세트를 쉽게 준비 할 수있는 ImageFolder 클래스를 제공합니다 . 데이터 디렉토리를 전달하기 만하면 모델 학습에 사용할 수있는 데이터 세트가 제공됩니다

아직 데이터 전처리가 완벽하지 않아 폴더 내 이미지가 없으므로 다음 단계 미진행!
- 2021.07.06
1차 모델 테스트 (정확도 약 45&)
- 데이터 개수 : 5개 Class Label x 3~4000 = 약 20,000 Image
- 기초적인 CNN 구성
- Optimizer : adam
1차 모델 구성
1차 테스트 결과

1차 모델 테스트 결과 분석
- class별 데이터 개수 차이가 크다 (no relation-30개 미만 / family-1000개)
- traing accuracy와 test accuracy의 차이가 크다 (데이터가 training set에 overfitting이 일어났을 가능성 고려)
- 모델 성능 개선을 위해 train, test, validation 비율 조정 필요
- 2021.07.07
PISC dataset 분류
약 24000개의 이미지 (구분하기 쉬운 확실한 이미지만 분류)
1. friends : 약3300장 -> train:2000 , test:660 , validation:660
2. family : 약1500장 -> train:950 , test:300 , validation:300
3. couple : 약1400장 -> train:900 , test:250 , validation:250
4. professional : 약5000장 -> train:3000 , test:1000 , validation:1000
5. no relation : 약400장 -> train:250 , test:70 , validation:70- 전처리 결과 약 12000장 남았지만 여전히 데이터 불균형 및 더 확실한 분류 필요
2차 모델 테스트를 위해 추가적인 데이터셋을 구하여 부족한 클래스 부분에 채우는 과정 진행중
- PISC보다 명확하나 클래스별 추가적인 분류작업 필요
- 분류작업 완료시 PISC 데이터셋에서 걸러낸 데이터와 합칠 예정

- 2021.07.08
데이터 전처리
약 12000장 개의 이미지 선별 및 검토
1. friends : couple클래스와 비슷하거나 사람이 보기에도 부적절한 이미지 제외
2. family : 누가봐도 가족임을 판별가능한 이미지로만 선별
3. couple : 스킨십,친밀도가 강하거나 웨딩사진이 포함된 이미지 위주
4. professional : 옷차림, 물건, 장소 등을 고려하여 이미지 선별
5. no relation : 시선, 거리감, 길거리 등을 고려하여 이미지 선별논문 분석
PISC 관련
1. 표정, 포즈, 감성 등의 핵심적 속성 및 행동 분석
2. 특정 개인 쌍에 대한 관계 예측을 먼저 하고 주변 지역을 사용하여 예측을 구체화 (두 단계를 거쳐 예측)
3. 그래프 뉴럴 네트워크(GGNN) , 그래프 추론 모델(GRM) 등 그래프 Attention 메커니즘을 도입하여 내부 정보를 탐색
4. 이미지 인식 - PPRN으로 추론 모드로 구성 후 RNN을 통해 관계 메시지를 전파
5. 연결된 노드의 가중치 계수를 계산하기 위해 소셜 그래프와 메시지를 집계하여 두 개의 대규모 벤치마크에 대한 실험진행 방향 계획
GNN 구조 사용
* GNN 관련 논문 분석 - 그래프는 점들과 그 점들을 잇는 선으로 이루어진 데이터 구조이기에 관계, 상호작용과 같은 추상적인 개념을 다루기에 적합
* Scene graph generation by iterative message passing : CNN으로 탐지된 물체들을 scene graph를 만들어서 관계를 파악
* 이미지에서 소셜 관계 그래프를 생성 한 다음, 그래프 노드 간의 일관성을 강화하여 새로운 이미지를 수신하여도 예측에 성공하고 그래프를 계속
개선할 수 있도록 작업 예정- 2021.07.09
GNN 구조 Study
- 논문과 기본 개념 내용을 바탕으로 이해
- Tutorial을 참고하여 예제 학습
박사님과의 토의 및 진행과정 발표
- 전반적인 확실한 데이터 선별을 위해 특징을 검출하여 훈련 시키는 방안
- 맥락은 제외하고 이미지 1장으로 사회적 관계를 결정
- 전체 이미지보다는 얼굴, 사물 등 한 특정 영역의 이미지에서 특징을 검출하여 분류하는것이 나을 수 있다
-> CNN 모델들을 비교하여 성능 테스트 해볼 것
- ResNet
- AlexNet
- DenseNEt
- Inception
- MobileNet-v3-large(small)
+) Confusion matrix 그리기 - GNN 스터디 (쉬운 난이도의 예제를 돌려보며 공부하고 CNN과 비교해볼 것 )
- 2021.07.12
cnn 모델 이해 & 관련 논문 리뷰
- ResNet : Skip connection적용하여 기울기소실문제 해결하면서, 매우 깊은 네트워크(152Layer) 학습하여 성능 상승
- AlexNet : GPU, ReLU함수를 사용하면서, 깊은 네트워크(8Layer) 학습하여 성능 상승
- DenseNEt : 진화된 Skip connection과 bottleneck layers를 적용하면서, 알짜배기 Feature만 가진 매우 깊은 네트워크를 학습하여 성능 상승
1. Resnet 1차 모델 테스트
- 지금까지 전처리가 진행된 데이터를 가지고 먼저 테스트를 돌려보며 비교한 뒤, 결과를 기반으로 특징을 추출하여 다시 전처리를 할 예정
- 모델 구성

- 테스트 결과 (약 62%)

- 2021.07.13
수집한 데이터 전처리 마무리
1. friends : 남녀 친구인경우 couple 클래스와 비슷하거나, 사람 눈으로도 판별하기 힘든 친구 이미지 제외 (1872 / 693)
2. family : 누가봐도 가족임을 판별가능한 이미지로만 선별 / 아기가 있다면 family, 부부만 있다면 couple (929 / 288)
3. couple : 스킨십,친밀도가 강하거나 웨딩사진이 포함된 이미지 선정 (898 / 294)
4. professional : 옷차림, 스포츠, 장소, 물건 등을 고려하여 이미지 선정 (2811 / 918)
5. no relation : 시장, 이발소 등 손님과의 관계가 있는 사진 / 시선, 거리감, 길거리 등을 고려하여 이미지 선정 (235 / 77)Resnet 2차 모델 테스트 (약 70%)
- 단순히 클래스별 데이터를 전처리 마무리 후 2차 테스트 진행


- 6개를 뽑아서 예측한 데이터를 확인한 결과, 전부 다 성공한 것을 알 수 있다.
테스트 결과 분석
- 성능을 개선하기 위해 여러가지 방법 구성할 필요있음
- 데이터증폭, 컬러 데이터셋 적용, layer수정
- 다른 모델도 적용해보고 추후 결과 비교해보기
- 2021.07.14
2. AlexNet 모델 테스트
- 모델 구성

구성한 모델을 통해 초기화를 한다. 즉 모델 내의 모든 모듈과 하위 모듈에 대해 지정된 기능이 호출됩니다.

- 테스트 결과 (약 43%)

테스트 결과 분석
- Resnet보다 현저히 정확도가 떨어지며, 학습정확도보다 test 정확도가 더 높은 현상 발생
- 모델이 일반화 되었으며 전체적인 데이터 불균형
- train data 보충 필요하다고 생각
- Dropout을 사용하면서 훈련 손실이 높기 때문에 훈련 정확도가 떨어질 수 있음
- 2021.07.15
3. DenseNet 모델 테스트
- 모델 구성
class DenseNet(nn.Module):
def __init__(self, nblocks, growth_rate=12, reduction=0.5, num_classes=5, init_weights=True):
super().__init__()
self.growth_rate = growth_rate
inner_channels = 2 * growth_rate # output channels of conv1 before entering Dense Block
self.conv1 = nn.Sequential(
nn.Conv2d(3, inner_channels, 7, stride=2, padding=3),
nn.MaxPool2d(3, 2, padding=1)
)
self.features = nn.Sequential()
for i in range(len(nblocks)-1):
self.features.add_module('dense_block_{}'.format(i), self._make_dense_block(nblocks[i], inner_channels))
inner_channels += growth_rate * nblocks[i]
out_channels = int(reduction * inner_channels)
self.features.add_module('transition_layer_{}'.format(i), Transition(inner_channels, out_channels))
inner_channels = out_channels
self.features.add_module('dense_block_{}'.format(len(nblocks)-1), self._make_dense_block(nblocks[len(nblocks)-1], inner_channels))
inner_channels += growth_rate * nblocks[len(nblocks)-1]
self.features.add_module('bn', nn.BatchNorm2d(inner_channels))
self.features.add_module('relu', nn.ReLU())
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.linear = nn.Linear(inner_channels, num_classes)
# weight initialization
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv1(x)
x = self.features(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
def _make_dense_block(self, nblock, inner_channels):
dense_block = nn.Sequential()
for i in range(nblock):
dense_block.add_module('bottle_neck_layer_{}'.format(i), BottleNeck(inner_channels, self.growth_rate))
inner_channels += self.growth_rate
return dense_block
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def DenseNet_121():
return DenseNet([6, 12, 24, 6])- 테스트 결과 (약 67%)


- 2021.07.16
Coufusion Matrix
원하던 행렬이 아닌데 ,, 문제해결을 위해 원인 찾는중 ,,

모델간의 비교 & 결과 분석
1. ResNet : layer들의 feature map을 계속해서 다음 layer의 입력과 연결하는 방식이며, feature map끼리 더하기를 해주는 방식 / Residual Block를 이해하면 전체적인 구조 쉽게 이해 가능
2. DenseNet : layer들의 feature map을 계속해서 다음 layer의 입력과 연결하는 방식이며, feature map끼리 Concatenation 을 시키는 것
3. AlexNet : nn.Sequential and nn.Dropout이 핵심!
Sequential은 여러 계층을 제공하며, Sequential 모듈이 호출되면 각 계층을 순서대로 입력에 적용
Dropout는 정규화의 한 형태다. 모델이 커질수록 많은 데이터셋에서 보다 정확하게 수행하기 위해 훨씬 더 많은 수의 매개 변수를 갖게 된다.
즉, 이미지 분류 학습 동안 일반적인 이미지 기능을 학습하지 않고 암기만 한다. 이는 검증에서 불량한 성능은 보이게 된다. 이 과적합 문제를 해결하기 위해 정규화를 사용!결과 : Dataset이 충분하지 않고 클래스 수가 5개 밖에 없으므로 cnn구조는 정확도가 가장 좋은 ResNet을 사용하며,
LSTM과 연결지어 2단계를 거처 분류한다면 더 좋은 성능 가능한지 연구
박사님과의 토의 및 진행과정 발표
- MobileNet으로 학습 진행 후 ResNet과 비교하기
- { friends, couple, family, etc } 4가지 클래스로 분류하여 MobileNet 과 ResNet으로 테스트
- Yolo v5를 사용하여 사람 영역을 검출 후 crop하여 MobileNet 과 ResNet으로 테스트
- 위 내용들 결과분석 및 비교
- 추가적으로, Webcam으로 직접 확인할 수 있도록 온라인 테스트 구성
- 2021.07.19
1. ResNet 3차 테스트(71%)
- 단순히 class 개수만 4개로 줄여서 테스트
- 1,2차와 동일한 모델로 테스트


결과분석
- 1,2차 테스트 결과보다 약 1% 상승하였으나 etc클래스에 일치하지 않는 그림 많이 보임
- { friends, couple, family } 를 중심으로 기준을 명확히 정한 후, 전체적인 전처리 진행 필요성 보임2. MobileNet 테스트
- 모델 구성
class MobileNet(nn.Module):
def __init__(self, input_channel, num_classes=4):
super(MobileNet, self).__init__()
self.network = nn.Sequential(
nn.Conv2d(input_channel, 32, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(True),
dw_block(32, kernel_size=3),
one_by_one_block(32, 64),
dw_block(64, kernel_size=3, stride=2),
one_by_one_block(64, 128),
dw_block(128, kernel_size=3),
one_by_one_block(128, 128),
dw_block(128, kernel_size=3, stride=2),
one_by_one_block(128, 256),
dw_block(256, kernel_size=3),
one_by_one_block(256, 256),
dw_block(256, kernel_size=3, stride=2),
one_by_one_block(256, 512),
# 5 times
dw_block(512, kernel_size=3),
one_by_one_block(512, 512),
dw_block(512, kernel_size=3),
one_by_one_block(512, 512),
dw_block(512, kernel_size=3),
one_by_one_block(512, 512),
dw_block(512, kernel_size=3),
one_by_one_block(512, 512),
dw_block(512, kernel_size=3),
one_by_one_block(512, 512),
dw_block(512, kernel_size=3, stride=2),
one_by_one_block(512, 1024),
dw_block(1024, kernel_size=3, stride=2),
one_by_one_block(1024, 1024),
)
self.linear = nn.Linear(1024, num_classes)
def forward(self, x):
body_output = self.network(x)
avg_pool_output = F.adaptive_avg_pool2d(body_output, (1, 1))
avg_pool_flat = avg_pool_output.view(avg_pool_output.size(0), -1)
output = self.linear(avg_pool_flat)
return output- 테스트 결과 (약 35%)

진행 방향
- 4개의 class로 데이터 전처리를 다시 마무리
- ResNet18 모델로 선정
- Yolo v5를 사용하여 사람 영역을 검출 후 crop하여 ResNet으로 테스트
- 사람 영역 검출 후의 결과와 전체적인 이미지로 테스트한 결과 비교 및 분석
- 2021.07.20
- yolo v5 환경셋팅 및 학습
- 추론코드로 couple 클래스 데이터 실험

결과 : 커플 이외의 많은 물체 판별
- 임계치를 설정하여 물체 판별 정확도 올리기
- 추론이 아닌 훈련으로 모델을 사용 고려
- 사람 영역 검출만을 가지고 판별하기위해 사람 이외 주변 물체 판별하지 않도록 조절 필요
- 데이터 전처리 필요- 2021.07.21
- glob 사용하여 이미지 리스트 불러오기
- 학습데이터와 테스트 데이터로 나누기
import torch
from glob import glob
from sklearn.model_selection import train_test_split
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5x') # or s yolov5m, yolov5x, custom
train_img_list = glob('/home/parkchan/anaconda3/envs/PISC/social group/image/train/*/*.jpg')
test_img_list = glob('/home/parkchan/anaconda3/envs/PISC/social group/image/test/*/*.jpg')
# Images
# img = '/home/parkchan/anaconda3/envs/PISC/social group/image/train/couple/06438.jpg' # or file, PIL, OpenCV, numpy, multiple
with open("/home/parkchan/anaconda3/envs/PISC/social group/image/train.txt", "w") as f:
f.write('\n'.join(train_img_list) + '\n')
with open("/home/parkchan/anaconda3/envs/PISC/social group/image/test.txt", "w") as f:
f.write('\n'.join(test_img_list) + '\n')- data.yaml안의 경로 수정
import yaml
with open('./image/data.yaml', 'r') as f:
data = yaml.load(f)
print(data)
data['train'] = './image/'
data['test'] = './image/'
with open('./image/data.yaml', 'w') as f:
yaml.dump(data, f)
print(data)- 데이터 학습 후 exp에 저장된 이미지들을 가지고 ResNet 테스트 예정
- 2021.07.22
- 테스트 결과
- 전처리된 데이터셋으로 resnet모델을 통해 webcam으로 테스트한 결과, 정확하지 않은 결과들 확인
- 사람이 없이 빈화면인 경우에도 아무 관계나 출력

-> 이미지내의 bbox 특정 영역을 추출해 그 안에서 관계를 유츄하기로 함.
- 결과 분석
-
yolo를 통해 사람이 검출되는 경우에만 예측 진행
-
이미지 내의 여러 클래스가 존재하고, 두 사람간의 관계를 전부 나타냄
-> 한 이미지의 특정 두사람을 검출하여, 두사람간의 관계를 유추, 즉 이미지내 사람들의 모든 관계 유추 -
Test_set 설정

- 2021.07.23
-
아키텍쳐

-
구성
- bounding box의 영역을 오브젝트로 받아서 특징추출을 위한 학습을 하기 위해 진행중
- 두사람의 관계를 Graph Reasoning Model로 해결하기 위해 구성중
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from person_pair import person_pair
from ggnn import GGNN
from torch.distributions import Bernoulli
from vgg_v1 import vgg16_rois_v1
import math
class GRM(nn.Module):
def __init__(self, num_class = 3,
ggnn_hidden_channel = 4098,
ggnn_output_channel = 512, time_step = 3,
attr_num = 80, adjacency_matrix=''):
super(GRM, self).__init__()
self._num_class = num_class
self._ggnn_hidden_channel = ggnn_hidden_channel
self._ggnn_output_channel = ggnn_output_channel
self._time_step = time_step
self._adjacency_matrix = adjacency_matrix
self._attr_num = attr_num
self._graph_num = attr_num + num_class
self.fg = person_pair(num_class)
self.full_im_net = vgg16_rois_v1(pretrained=False)
self.ggnn = GGNN( hidden_state_channel = self._ggnn_hidden_channel,
output_channel = self._ggnn_output_channel,
time_step = self._time_step,
adjacency_matrix=self._adjacency_matrix,
num_classes = self._num_class)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(self._ggnn_output_channel * (self._attr_num + 1) , 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 1)
)
self.ReLU = nn.ReLU(True)
self._initialize_weights()
def forward(self, union, b1, b2, b_geometric, full_im, rois, categories):
batch_size = union.size()[0]
# full image
rois_feature = self.full_im_net(full_im, rois, categories)
contextual = Variable(torch.zeros(batch_size, self._graph_num, self._ggnn_hidden_channel), requires_grad=False).cuda()
contextual[:, 0:self._num_class, 0] = 1.
contextual[:, self._num_class:, 1] = 1.
start_idx = 0
end_idx = 0
for b in range(batch_size):
cur_rois_num = categories[b, 0].data[0]
end_idx += cur_rois_num
idxs = categories[b, 1:(cur_rois_num+1)].data.tolist()
for i in range(cur_rois_num):
contextual[b, int(idxs[i])+self._num_class, 2:] = rois_feature[start_idx+i, :]
start_idx = end_idx
# first glance scores
scores, fc7_feature = self.fg(union, b1, b2, b_geometric)
# ggnn input
fc7_feature_norm_enlarge = fc7_feature.view(batch_size, 1, -1).repeat(1, self._num_class, 1)
contextual[:, 0: self._num_class, 2:] = fc7_feature_norm_enlarge
ggnn_input = contextual.view(batch_size, -1)
#ggnn forward
ggnn_feature = self.ggnn(ggnn_input)
ggnn_feature_norm = ggnn_feature.view(batch_size * self._num_class, -1)
#classifier
final_scores = self.classifier(ggnn_feature_norm).view(batch_size, -1)
return final_scores
def _initialize_weights(self):
for m in self.classifier.modules():
cnt = 0
if isinstance(m, nn.Linear):
if cnt == 0:
m.weight.data.normal_(0, 0.001)
else :
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
cnt += 1- person_pair에서 네트워크 load를 위해 adjacency_matrix numpy 파일 생성
- 2021.07.26
- GNN은 구성된 장면-관계 그래프에 포함된 글로벌 컨텍스트 정보와 사회적 관계 간의 상호 작용을 통해 추론하는 데 사용합니다
- GRM은 인물의 특징과 장면의 컨텍스트 객체를 노드로 취급하는 그래프를 구성합니다. 구성된 그래프를 통해 GGNN을 추론하고 Attention 메커니즘을 사용하여 두 가지 유형의 노드에 대한 가중치를 계산합니다. 마지막으로, 사람 노드의 벡터 표현은 Social Relation에 대한 객체 노드의 가중치를 연결합니다.
- GRM은 Faster RCN을 사용합니다. (resnet101 / vgg16)
backbone = torchvision.models.vgg16(pretrained=True).features[:-1]
backbone_out = 512
backbone.out_channels = backbone_out
anchor_generator = torchvision.models.detection.rpn.AnchorGenerator(sizes=((128, 256, 512),),aspect_ratios=((0.5, 1.0, 2.0),))
resolution = 7
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], output_size=resolution, sampling_ratio=2)
box_head = torchvision.models.detection.faster_rcnn.TwoMLPHead(in_channels= backbone_out*(resolution**2),representation_size=4096)
box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(4096,21) #21개 class
model = torchvision.models.detection.FasterRCNN(backbone, num_classes=None,
min_size = 600, max_size = 1000,
rpn_anchor_generator=anchor_generator,
rpn_pre_nms_top_n_train = 6000, rpn_pre_nms_top_n_test = 6000,
rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=300,
rpn_nms_thresh=0.7,rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3,
rpn_batch_size_per_image=256, rpn_positive_fraction=0.5,
box_roi_pool=roi_pooler, box_head = box_head, box_predictor = box_predictor,
box_score_thresh=0.05, box_nms_thresh=0.7,box_detections_per_img=300,
box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5,
box_batch_size_per_image=128, box_positive_fraction=0.25
)
for param in model.rpn.parameters():
torch.nn.init.normal_(param,mean = 0.0, std=0.01)
for name, param in model.roi_heads.named_parameters():
if "bbox_pred" in name:
torch.nn.init.normal_(param,mean = 0.0, std=0.001)
elif "weight" in name:
torch.nn.init.normal_(param,mean = 0.0, std=0.01)
if "bias" in name:
torch.nn.init.zeros_(param)backbone으로 VGG16을 사용하며 마지막 max pooling층은 제거해 줍니다. Faster RCNN을 사용하기 위해서는 fully connected layer를 만들기 위해 최종 backbone output채널이 512임을 알려주어야 합니다. 이후 anchor generator, roi pooler, box head, box predictor를 각각 만들어 줍니다.
모델은 torchvision.models.detection에 있는 FasterRCNN을 사용합니다. 마지막으로 weight와 bias를 초기화합니다.
이후 training을 통해 학습하여 object boxes 로 사용하려 했으나 다시 ... GNN접고 토의 결과대로
- 2021.07.29
- 프로젝트 구성 메카니즘
1) 데이터 전처리(사람 영역별 자르기)
2) fine tuning
3) feature extraction(vector)
4) concatenate
5) classfication(6가지 클래스)-
(2,3과정) 영역에 대한 특징벡터 추출
특징 벡터는 단순히 신경망 계층의 출력에서 가져온 숫자 목록입니다. 이 벡터는 인풋데이터로 다시 사용되며 향후 클래스를 분류하는 작업에 사용할 예정
-
사전 훈련된 모델(ResNet18)을 통해 특징벡터 추출
def get_vector(image_name):
img = Image.open(image_name)
t_img = Variable(normalize(to_tensor(scaler(img))).unsqueeze(0))
my_embedding = torch.zeros(512)
def copy_data(m, i, o):
my_embedding.copy_(o.data)
h = layer.register_forward_hook(copy_data)
model(t_img)
h.remove()
return my_embedding
pic_one_vector = get_vector(pic_one)
pic_two_vector = get_vector(pic_two)- 두 벡터간의 유사도 확인
cos = nn.CosineSimilarity(dim=1, eps=1e-6)
cos_sim = cos(pic_one_vector.unsqueeze(0),
pic_two_vector.unsqueeze(0))
print('\nCosine similarity: {0}\n'.format(cos_sim))- 추출한 두 특징벡터의 Concatenate
class resnet(nn.Module):
def __init__(self):
super().__init__()
self.model = models.resnet18(pretrained=True)
self.features = nn.Sequential(*list(self.model.children())[:-1])
# class : friends, family, couple, professional, commercial, no_relation
self.num_classes = 6
self.fc1 = nn.Linear(2000, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, self.num_classes)
def forward(self, x1, x2):
x1 = self.model(x1)
x2 = self.model(x2)
x = torch.cat((x1, x2), dim=1)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x이후 분류하기위한 Network 구성에 있어서 고려해야 할 요소가 많아 어려움을 겪으며 여러 논문과 자료 검토중
- 2021.07.30
- 4주차 회의 결과
1) self.fc1 = nn.Linear(2000, 1024) -> 2000의 부분을 직접 < chanel_num height width > 의 계산을 통해 구해야한다. (대부분 2000으로 딱 떨어지는 경우는 없고 2001만 돼도 에러발생)
2) 계산을 하지 않는다면 avg pooling을 통해 적용
3) 차주 이러한 발생하는 에러 등을 수정하여 프로젝트 마저 진행
+) 추가적으로 먹방 데이터 수집(URL
대상 : 1~2인상 + 식사하는사람 / 음식+음료 5가지 이상 // 촬영방향:<정면,측면> <45도,10도> // 수집은 4가지 경우를 5개씩 !
고려사항 : 양으로 승부하거나 음식이 다양하지 않은 먹방 제외 / 화면전환이 자주 일어나는 먹방 제외
- 2021.08.02
- 1차 데이터 수집


- 예시
1) 측면


2) 정면

- 새로운 에러 직면
TypeError: object of type 'NoneType' has no len()
데이터로드 부분에서 문제발생! 해결하기 위해 수정 및 검색중

- 2021.08.03
- 에러 발생 (1)
valueerror: decompressed data too large- 해결
from PIL import Image, ImageFile
PIL.ImageFile.LOAD_TRUNCATED_IMAGES = True - 에러 발생 (2)
IndexError: list index out of range- 해결
리스트 범위 수정하여 해결
이후 강보경님이 데이터셋 관련 에러를 해결하며 다음 epoch로 넘어갈 수 있었다!- 결과

사람영역만을 가지고 관계를 유추하는 것은 이미지 전체 영역에서 특징을 추출하는 것보다 성능이 좋지 못하다.
이미지 전체 및 주변 영향을 받는 것을 알 수 있다. 또한 데이터를 재구성한 것이 성능 측면에서 긍정적인 영향을 미쳤다고 생각한다. - 1차 데이터수집 마무리
1) 1차 데이터 수집에서 모아놓은 링크들 재점검하며 각도, 구도별 분류
2) 45도 정면 - 5개 (완료) / 15도 정면 -5개 (완료) / 45도 측면 - 5개 (완료) / 15도 측면 - 5개 (완료)
+) 측면 피드백 필요, 추후 다음 데이터 수집부터 고려하여 다시 재수집 예정
- 2021.08.05
- 2차 데이터수집 마무리
1) < 정면,45 > - 13개 / < 측면,45 > - 13개 / < 정면,10 > - 13개 / < 측면,10 > - 13개
2) 빈번한 화면전환, 다양하지 않은 음식 제외
3) 한식, 중식, 양식, 분식 등 분류별로 수집 및 검토
< 정면,45 >

< 정면,10 >

< 측면,45 >

< 측면,10 >

- 지금까지 진행한 < Social Relation > 프로젝트 정리
1) PISC 데이터셋을 대상으로 재구성한 데이터셋을 정리해서 구글 드라이브에 저장하고 공유
2) 아래 두 코드를 포함하는 Github 리퍼지토리를 만들어서 공유
- 재구성한 데이터셋으로 70% 내외의 성능을 얻었던 인식기 코드
- 사람 영역을 잘라서 두 사람 간 관계를 유추한 인식기 코드 - 2021.08.06
< Social Relation > 프로젝트 정리 마무리
- Model : 모델별 학습했던 내용 정리
- data preprocessed : 이미지마다 두사람의 영역을 잘라서 분류했던 코드 정리
- data load, model, data.py 업로드
- 이외 재구성한 dataset, json파일 구글 드라이브 공유
- 성능 개선을 위해 모델 학습 부분 재검토 중
신규 작업 준비
- Group Activity Recognition SW 검증 (단체 행동인식)
- SW가 정상 동작하는지, 성능은 어느 정도인지를 검증
1) 그룹 활동 인식 모델학습
python main.py --dataset 'volleyball' --num_frame 3 --enc_layers 1 --lr_scheduler 'cyclic' --lr 1e-6 --max_lr 1e-4 --lr_step 5 --drop_rate 0.12) 에러발생
ImportError: cannot import name '_new_empty_tensor' from 'torchvision.ops' - 검색 결과, 버전 문제일 가능성 고려하여 3.7.7의 버전을 다운받아 변경 후 다시 실행
- 2021.08.09
1) 에러 해결
ImportError: cannot import name '_new_empty_tensor' from 'torchvision.ops' Python 3.7.7
Pytorch 1.6.0
Torchvision 0.7.0
- 모두 다운그레이드를 통해 문제 해결
2) wandb 계정 생성 및 API key 복사
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 2
wandb: Paste an API key from your profile and hit enter: 3) 에러 발생
NotADirectoryError: [Errno 20] Not a directory: '/home/parkchan/Downloads/aai4r-Group-Activity-Recognition-main/wandb/run-20210809_165008-kd6602ue'
wandb: ERROR Abnormal program exit
six.raise_from(Exception("problem"), error_seen)
File "<string>", line 3, in raise_from
Exception: problem- wandb를 run하는 과정에서 에러가 생겼다고 추측 중
- 코드를 하나씩 살펴보며 원인을 해결중에 있으며 일단 이슈에 문제를 올려놓을 예정
- 2021.08.10
-
wandb 에러 해결
프로젝트 경로 수정 및 wandb api 등록 후 계정 재접속으로 해결 -
dataload를 위해 데이터셋 다운중 (용량이 커서 오래걸림)
1) volleyball
2) NBA (중국 개발자에게 메일을 보내 답변을 받아 패스워드 입력 후 데이터셋 접근)
다운을 위해 바이두 사이트 회원가입 필요

- 관련된 논문 분석
Social Adaptive Module은 비디오에서 감독되는 그룹 행동 인식에 대한 차별적 제안과 프레임을 선택할 수 있습니다.
약하게 훈련된 사람들을 돕는데 있어 주요 인스턴스(사용자/프레임)는 서로 매우 관련이 깊습니다.
구체적으로, 먼저 가능한 모든 입력 기능에 대한 고밀도 관계 그래프를 구성합니다.
서로 간의 관계를 측정한 후, 선택한 피쳐를 기반으로 관계 그래프가 작성됩니다.
(a) 배구 데이터셋은 비디오 레벨 레이블만 제공하는 약하게 감독된 설정이 그룹 행동 인식에 도입되었습니다.
(b) 보다 까다로운 NBA는 저렴한 비용으로 웹에서 수집됩니다.
(c) 취약하게 감독되는 훈련을 완화하기 위해 Social Adaptive Module 제안.
주요 인스턴스(instance)가 일반적으로 서로 밀접하게 연관되어 있다는 가정.NBA는 배구 경기에서의 활동에 비해 더 장기적인 시간을 가지고 있다.
구조 및 빠른 이동 속도로 인해 그룹 활동 분석에 새로운 과제가 제기됩니다. 우선, 선수 수는 서로 다를 수 있다.
반면에, 액티비티는 너무 빨라서 싱글 프레임은 이러한 플레이어를 추적하는 데 사용자 수준의 주석이 무용지물이다.
그러므로 배구 경기와 다른 비디오의 모든 사람들에게 라벨을 붙이기는 어렵다.
우리는 약하게 조정된 환경에서 이 벤치마크에 주석을 달았다. 때문에 이 데이터 집합을 사용할 수 있다.
동영상이 주어진 경우 주석의 목표는 그룹을 할당하는 것입니다.
해당 부문에 대한 활동. 수동으로 레이블을 지정하는 데 시간이 오래 걸립니다.
기존 주석 툴을 사용하여 대규모 데이터셋을 구성할 수 있으며, 주석의 효율성을 높이기 위해, NBA의 임원이 제공한 로그를 최대한 활용할 수 있다.- 2021.08.11
Volleyball dataset 그룹 활동 인식 모델 학습
-
에러발생

-
해결
Dataset 폴더를 만들어서 경로를 설정해도 같은 에러가 발생해 dataloader.py와 volleyball.py 코드를 참고하여 "data_path"를 수정했다.
if args.dataset == 'volleyball':
data_path = args.dataset
image_path = data_path + "/videos"- 학습 결과

1) test_group_acc

2) train_group_acc

3) test_mean_acc

4) train_loss

Nba dataset 그룹 활동 인식 모델 학습
- 바이두 회원가입 측면에서 자꾸 에러가 나서 핫스팟 및 핸드폰 어플을 활용해 데이터셋 다운 활용중
- 2021.08.12
Nba dataset 다운실패
-
개인 핫스팟 연결을 통해 웹에 접근할 수는 있으나 웹에서 다운 받을 수는 없고 바이두 클라우드를 통해 받을 수 있다.
-
바이두 클라우드 계정 회원가입 완료
-
rpm 패키지 설치완료 " sudo alien -i baidunetdisk_3.5.0_amd64.rpm "
-
deb 패키지 설치완료 " sudo dpkg -i baidunetdisk_3.5.0_amd64.deb "
그러나 접속에러 ..!

-
중국측에 구글드라이브 공유 문의했으나 속도측면과 사이즈 크기상 불가능하다는 답변 받음
-
핸드폰 어플을 통해 다운을 받아 컴퓨터와 연결 후 다시 공유하려했으나 데이터 크기상 핸드폰 다운 실패
그래도 중국 바이두에 대해 처음으로 알아갈 수 있는 시간이였고 .. 용량을 2TB까지 다운가능하나 속도가 정말 느리다는 사실도 알게 되었다. 앞으로 두번다시는 쓸 일 없을 것 같다..
Volleyball dataset 그룹 활동 인식
-
결과 분석 및 코드 확인
-
학습된 모델을 가지고 하나의 새로운 이미지로 테스트 (도쿄올림픽 여자배구 사진)

-
에러발생
model.eval()
AttributeError: 'dict' object has no attribute 'eval'로드하는 도중 문제가 생겨서 수정 예정
- 2021.08.13
Volleyball dataset 그룹 활동 인식 분석 마무리
- 총 8개의 활동 :
> 'r_set' , 'r_spike' , 'r-pass' , 'r_winpoint' , 'l_set' , 'l-spike' , 'l-pass' , 'l_winpoint' - 6개의 클래스로 분류
> 'r_set / r-pass' , 'r_spike' , 'r_winpoint' , 'l_set' / 'l-pass' , 'l-spike' , 'l_winpoint' - Resnet 모델 기반 구축
- annotation.txt 주석파일을 통해 그룹id를 할당한다.
- 주석의 효율성을 높이기 위해, 데이터셋에 포함된 info.txt를 활용한다.
약 95%의 성능으로 그룹 활동 인식 검증
새로운 단일 이미지로 테스트 해보려했으나 에러를 해결하지 못해 일단 데이터셋 내의 이미지로만 결과 확인
OwithC (SR-PyTorch) 1차 프로젝트 정리 마무리
- 2021.08.18
PISC 데이터셋 모델 성능 개선방안 연구
- batch size, epoch, 모델의 층을 늘려도 큰 변화가 없었다.
- class당 데이터 불균형 및 개수 너무 적음
- 중간 Layer의 개수, Node의 개등 방법고려
- Layer를 깊게만 쌓는다고 성능 향상으로 직결되진 않음
- Input Image Resizing -> 64 x 64 또는 256 x 256 으로 resizing 하여 일어나는 변화를 관측
- Optimizer 와 Learning Rate 조정 (SGD -> Adam -> Nadam)
- 단, resnet모델의 경우 SGD사용!
- Image Augmentation을 통한 데이터 증폭
- 특징들(Feature maps)도 늘리고 convolutional layer와 fully connected layer를 하나 늘려보는 방안도 고려
- 과적합 방지(Dropout)
이처럼 여러 개선 방안을 고려해서 모델을 재구축하는 과정에 있다. 각 과정을 그래프로 나타내 validation loss을 비교하며 성능을 개선 중
- 2021.08.19
Social relation
모델을 직접 구성해 성능을 개선해보려고 했으나 resnet,vgg보다 훨씬 성능이 안나옴
-> 개선방안 고려
- 데이터 불균형(test data, train data 비율 조정)
- Image Augmentation을 통해 데이터 증폭
resize, horizontally flip, vertically flip, shift, brightness, contrast, gamma, scale label- 가중치 초기화 함수 정의 후 모델 적용
Group Activity Recognition SW 검증 에러
models.py 에서 사용한 args를 설정(모델링에 필요한 값)
-> argparse 사용


학습된 이미지를 검증하기 위해 로드하는 과정에서 문제발생 .. 간단하게 접근했는데 해결을 못하고 있다..
- 2021.08.20
Group Activity Recognition Volleyball dataset 학습곡선 분석
- Train acc / Train loss 에 비해 Test acc가 일정하지 않고 Overfitting 된 모습을 확인
-
원인을 분석하던 과정 test loss를 찍어보니 nan값으로 나오는 것을 확인

-
해결 과정
학습 성능이 너무 높아서 나타나는 현상일 수 있음. 성능을 좀 낮추더라도 네트워크를 다시 구성해야 한다는 의견.
또한 , 가중치가 정규화되지 않았거나 가중치 규제가 필요하다.Social relation
- 이미지 내의 두 사람을 crop한 파일 말고 전체 이미지를 통해 모델 구성중
- pretrained된 resnet을 통해 70%이상의 성능을 얻었지만 직접 모델을 구성하면 어느정도 성능이 나오는지 공부하고자 진행
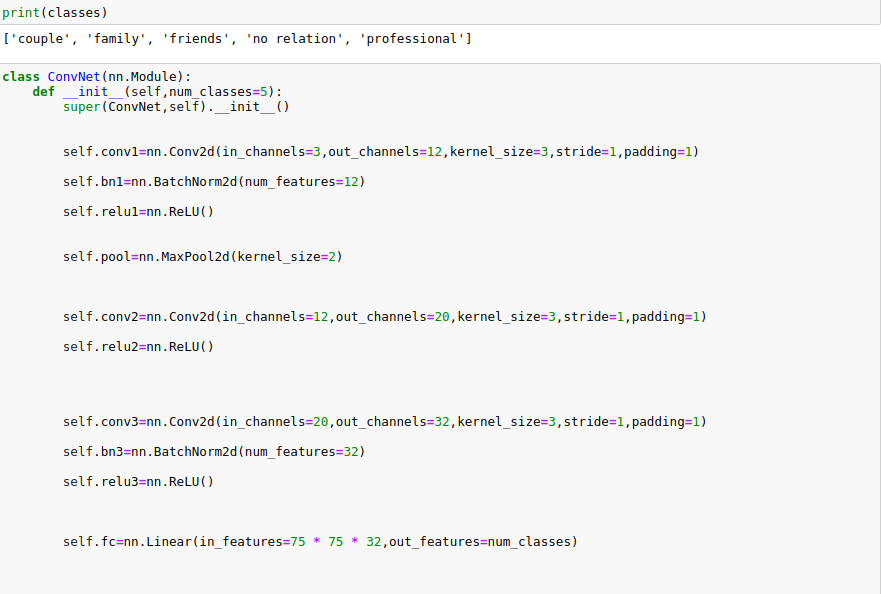
1차 학습모델 (32.5%)
- 데이터 개수 : 4개 Class Label x (1000,1000,3000,5000) = 10,000 Image
- 기초적인 CNN 구성
- Optimizer : adam

- 원인분석
1. Class Label에 대한 데이터 개수가 너무 적음 ( label당 불균형한 이미지 )
2. CNN 모델이 너무 얕아 특징을 분리하기 어려울 수 있음
3. validation set에 대한 loss가 커서 이를 줄이기 위한 방법이 필요- 개선방안
1. 단순하게 클래스 수를 줄여서 3가지 클래스로 분류 (professional(5000장)에 대한 이미지를 친구로 이동하거나 버림)
2. CNN 구조 개선 작업
3. Optimizer 와 Learning Rate 조정- 2021.08.23
Semi-Supervised-Domain-Adaptation
도메인 적응에 대한 의사 레이블 지정 및 일관성 정규화
- DomainNet 데이터셋 다운로드
- Office-home 데이터셋 다운로드
SW 검증을 위해 데이터셋 다운로드중
관련된 논문 분석 및 코드 점검
기본 모델은 기능적인 인코딩 네트워크와 추정된 각 대표 클래스 기능의 유사성을 계산하는 분류 계층으로 구성됩니다.
적응에 대한 검증은 분류자에 대해 레이블이 지정되지 않은 대상, 데이터의 조건부를 교대로 최대화하고 특징 인코더에 대해 최소화함으로써 달성됩니다.- 2021.08.24
Semi-Supervised-Domain-Adaptation
- 데이터셋 다운 마무리 후 훈련 실행
- 에러 발생 1
AttributeError: module 'torchvision.transforms' has no attribute 'GaussianBlur'
GaussianBlurpytorch 1.6에 존재하지 않았고, 1.7에서 추가되었다.
저번 그룹 행동 인식 검증에서 버전 다운 그레이드를 해서 생긴 에러!
다시 pytorch와 torchvision을 최신버전으로 업데이트! - 에러 발생 2



해당 폴더에 파일 경로가 있는데도 불구하고 계속해서 에러가 발생
파일 경로부분 코드를 수정하면 또 다른 곳에서 파일을 못찾는다는 에러가 반복
다른 곳도 해당 폴더에 파일이 있는 것은 확인- 2021.08.25
Semi-Supervised-Domain-Adaptation 검증

dataset.py / return_dataset.py 내 각 클래스별 root 및 base_path 수정 마무리
utils 폴더의 path관련 py파일 경로 수정 마무리
코드에 알맞게 data폴더의 하위폴더 dataset 재구성 마무리
결과

< train , val , test loss 전부 nan 값 >






< val-acc : 0.79365 >

< train-sacc : 0.00417 >

< test-acc : 0.13097 >

< test-acc-at-best-val : 52.22374 >

분석

< 1 >
source domain이 target domain으로 바뀌는 상황을 도메인 이동이라고 하며, 도메인 적응은 높은 성능을 유지하면서 도메인 이동을 달성하는 기법입니다.
데이터셋은 office home / M3SDA이고 라벨이 부착된 데이터와 라벨이 부착되지 않은 데이터를 활용하여 작업을 실행한다.
어떻게든 이전 task(target domain)서 배운 지식을 사용해 새로운 상황에서도 맞출 확률을 올려주는 것이 목표다.
Source domain에서 classification 성능 우수 , Source domain과 target domain을 구별하지 못하게 한다.
< 2 >
학습, 테스트, 검증 loss 값이 전부 nan이 나왔다. 저번과 같은 현상인데 아마 이유가 따로 있을 것 같다.
현 개발자에게 이슈를 남겨놨으니 보고 확인할 예정
정확도 그래프는 심한 편차를 보인다. 저런 현상도 어떠한 것을 나타내는지 자료를 찾아보고있다. 