
Overview
한글 문서... HWP... 별로 좋아하지 않습니다만... 이번에 분석해야할 일이 있었습니다. 그렇다고 처음부터 맨땅에 헤딩을 할 수 없으니 적당한 라이브러리를 찾다가 hwp.js 라는 것을 보게 됩니다. 생각보다 잘 만든 라이브러리이지만 관리를 더 이상 하지 않는듯한 아쉬움을 보여줍니다.
이번시간에는 제가 어떻게 HWP 문서 및 hwp.js 라이브러리 분석했는지 그 과정을 적어보도록 하겠습니다.
hwp.js 라이브러리
라이브러리 소개
hwp.js는 사용자가 한글 문서를 올리면 웹에서 쉽게 볼 수 있게 하는 라이브러리 입니다. 잘 보면 요소마다 HTML로 되어있는 걸 알 수 있습니다. 라이브러리를 분석하면 아시겠지만 이게 전부 한글 문서를 분석해서 구조화한 다음 HTML로 변환한 것입니다. (대단합니다)
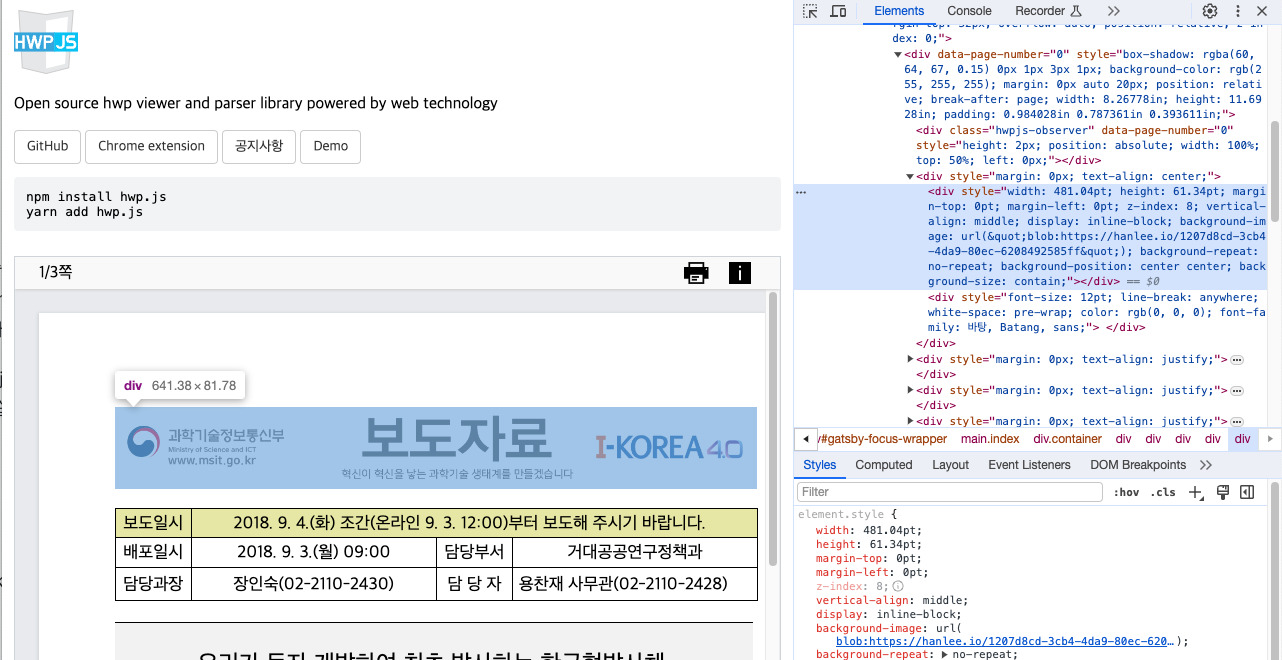
이처럼 컴퓨터에 한글이 설치가 안된 사용자도 웹에서 쉽게 볼 수 있도록 지원하기 위해 만든 라이브러리인 것을 알 수 있습니다.
다만 아쉬운 점이 있다면 이미 말씀드린것처럼 관리가 전혀 되고 있지 않습니다. 마지막 업데이트가 2년전입니다. 그리고 수식에 대한 부분은 아예 보이지도 않습니다. 이에 대해 코드를 살펴보니 수식에 대해 변환하는 부분은 구현되어있지 않았습니다.
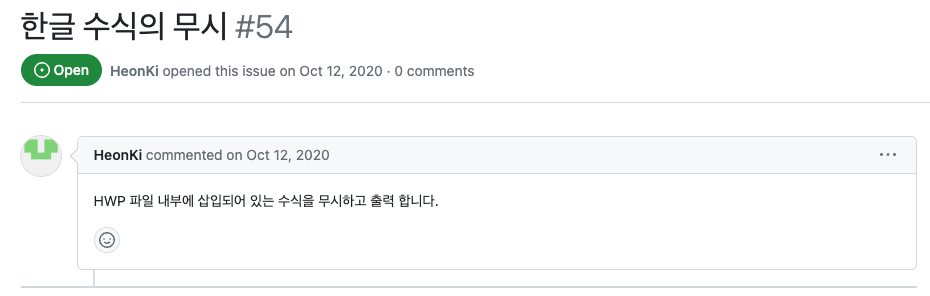
이미 이슈도 있는데... 아무런 답변도, 소식도 없네요. (이것 때문에 내가... 구현했지...)
프로젝트 구조
해당 라이브러리를 살펴보면 yarn workspaces 를 사용할 것을 알 수 있습니다. 그리고 yarn은 3버전을 사용했군요. yarn berry를 사용하기 위함인듯합니다.
"workspaces": [
"packages/*",
"website"
],
...
"packageManager": "yarn@3.2.2"packages 폴더 안을 보니 extension, parser, viewer 로 나눠져있습니다. 우리가 중요하게 볼 부분은 parser, viewer 입니다.
그리고 packages 폴더 밖에는 website 라는 폴더가 있습니다. Gatsby로 되어있는 걸 알 수 있고, 이게 바로 위에서 본 hwp.js 데모 사이트 입니다.
hwp.js 라이브러리 분석하기
파일 읽어오기
가장 먼저 사용자가 올린 hwp를 FileReader로 읽어들입니다. (코드 참고)
// website/src/pages/Demo.tsx
import HWPViewer from '@hwp.js/viewer'
const reader = new FileReader()
reader.onloadend = (result) => {
const bstr = result.target?.result
if (bstr) {
try {
new HWPViewer(ref.current, bstr as Uint8Array) // ✅
} catch (e) {
setErrorMessage(e.message)
}
}
}
reader.readAsBinaryString(file)그리고 나서 HWPViewer 를 사용하는 걸 알 수 있습니다. HWPViewer가 핵심이겠네요.
HWPViewer
HWPViewer 코드 입니다. packages > viewer 폴더에 있습니다. (코드 참고)
// packages/viewer/src/viewer.ts
import parse, {
...
} from '@hwp.js/parser'
class HWPViewer {
private hwpDocument: HWPDocument
private container: HTMLElement
private viewer: HTMLElement = window.document.createElement('div')
private pages: HTMLElement[] = []
private header: Header | null = null
constructor(container: HTMLElement, data: Uint8Array, option: CFB$ParsingOptions = { type: 'binary' }) {
this.container = container
this.hwpDocument = parsePage(parse(data, option)) // ✅
this.draw()
}여기서 parse 를 호출하고 있습니다. parse는 parser 에 있는 걸 알 수 있군요.
parser - parse 함수
사실상 여기서부터 핵심이라고 보면 될 거 같습니다. (코드 참고)
function parse(input: CFB$Blob, options?: CFB$ParsingOptions): HWPDocument {
const container: CFB$Container = read(input, options)
const header = parseFileHeader(container)
const docInfo = parseDocInfo(container, header)
const sections: Section[] = []
for (let i = 0; i < docInfo.sectionSize; i += 1) {
sections.push(parseSection(container, i))
}
return new HWPDocument(header, docInfo, sections)
}container에 들어가는 내용입니다. options는 binary 형태입니다. cfb 라는 라이브러리에서 read 메서드를 사용하고 있습니다. 아마 최초의 한글문서를 바이너리 형태로 읽어서 아래와 같은 형식으로 반환하는거 같습니다.

참고 : https://cdn.hancom.com/link/docs/한글문서파일형식_5.0_revision1.3.pdf
한글문서파일형식 문서를 살펴보면 크게 FileHeader, DocInfo, BodyText(Section포함), BinData… 로 구성되어있다고 합니다. 그래서 hwp.js에서도 header랑 docInfo, section를 따로 parse 하는게 아닐까 생각됩니다.
parseFileHeader
파일헤더에 저장되는 정보는 파일버전, 속성 등이 저장된다고 합니다. FileHeader는 256 bytes 고정 길이를 가집니다.

const { content } = fileHeader
// 256 bytes 가 아니라면 잘못된 형식임
if (content.length !== FILE_HEADER_BYTES) {
throw new Error(`FileHeader must be ${FILE_HEADER_BYTES} bytes, Received: ${content.length}`)
}
// 아. 원래 signature는 32 bytes이지만 내용자체는 0~17까지 밖에 없네. 그 뒤에는 0으로 되어있군
const signature = String.fromCharCode(...Array.from(content.slice(0, 17))) // "HWP Document File"
if (SIGNATURE !== signature) {
throw new Error(`hwp file's signature should be ${SIGNATURE}. Received version: ${signature}`)
}보면 아스키코드로 되어있는걸 알 수 있습니다. 이를 번역하면 "HWP Document File" 이라는 뜻입니다.

33, 34, 35, 36 번째 인덱스는 파일 버전을 담고 있습니다. 여기서는 아마 한글 5버전만 지원하게 해놓은거 같습니다.
const [major, minor, build, revision] = Array.from(content.slice(32, 36)).reverse()
const version = new HWPVersion(major, minor, build, revision)
//major: 5
//minor: 0
//build: 5
//revision: 0음… 갑자기 Uint8Array를 사용합니다. 8bit 부호 없는 형태라고 하네요. 그리고 이를 buffer로 바꾸고 있습니다.
const reader = new ByteReader(Uint8Array.from(content).buffer)
// signature bytes + version bytes
reader.skipByte(32 + 4)그랬더니 아래와 같이 나왔습니다. 72가 갑자기 48이 되었는데 이는 72를 비트 형태로 바꿔보면 0100_1000인데 그래서 48이 되는 모양입니다.

ByteReader는 parser의 utils에 있는 클래스인데… offsetByte 및 readUInt___ 함수가 있어서 어디까지 읽었는지, 얼마나 읽을 것인지를 잘 관리해준다고 볼 수 있습니다. 결국 reader.skipByte(32 + 4)는 36만큼 offsetByte를 이동한다고 볼 수 있겠죠?
class ByteReader {
private view: DataView
private offsetByte: number = 0
constructor(buffer: ArrayBuffer) {
this.view = new DataView(buffer)
}
readUInt32(): number {
const result = this.view.getUint32(this.offsetByte, true)
this.offsetByte += 4
return result
}
...
read(byte: number): ArrayBuffer {
const result = this.view.buffer.slice(this.offsetByte, this.offsetByte + byte)
this.offsetByte += byte
return result
}
skipByte(offset: number) {
this.offsetByte += offset
}
}
export default ByteReader그렇게 옮긴 다음에는 bit 단위로 데이터를 읽고 있는 걸 볼 수 있습니다. 공식문서를 보면 이부분은 속성입니다. (압축 여부, 암호 설정 여부.. 등)
return new HWPHeader(version, signature, {
compressed: Boolean(getBitValue(data, 0)),
encrypted: Boolean(getBitValue(data, 1)),
distribution: Boolean(getBitValue(data, 2)),
script: Boolean(getBitValue(data, 3)),
drm: Boolean(getBitValue(data, 4)),
hasXmlTemplateStorage: Boolean(getBitValue(data, 5)),
vcs: Boolean(getBitValue(data, 6)),
hasElectronicSignatureInfomation: Boolean(getBitValue(data, 7)),
certificateEncryption: Boolean(getBitValue(data, 8)),
prepareSignature: Boolean(getBitValue(data, 9)),
certificateDRM: Boolean(getBitValue(data, 10)),
ccl: Boolean(getBitValue(data, 11)),
mobile: Boolean(getBitValue(data, 12)),
isPrivacySecurityDocument: Boolean(getBitValue(data, 13)),
trackChanges: Boolean(getBitValue(data, 14)),
kogl: Boolean(getBitValue(data, 15)),
hasVideoControl: Boolean(getBitValue(data, 16)),
hasOrderFieldControl: Boolean(getBitValue(data, 17)),
})참고로 getBitValue는 이런식으로 되어있습니다. 어렵군… 어렵네… 뭐 비트 마스킹 그런거 하는거 같아보입니다.
export function getBitValue(mask: number, start: number, end: number = start): number {
const target: number = mask >> start
let temp = 0
for (let index = 0; index <= (end - start); index += 1) {
temp <<= 1
temp += 1
}
return target & temp
}따라서 헤더는 최종적으로 이와 같은 형식이 됩니다. 이런 일련의 과정을 살펴보니 코드를 잘 작성한거 같다 라는 느낌을 받았습니다. HWPHeader는 클래스입니다. 모델(models)를 위해 사용됩니다.
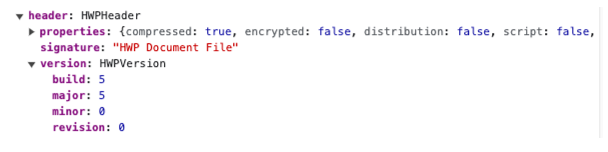
parseDocInfo
헤더 다음으로는 문서 정보입니다. 본문에 사용 중인 글꼴, 글자 속성, 문단 속성, 탭, 스타일 등에 문서 내 공통으로 사용되는 세부 정보를 담고 있다고 합니다.

import { inflate } from 'pako'
function parseDocInfo(container: CFB$Container, header: HWPHeader): DocInfo {
const docInfoEntry = find(container, 'DocInfo')
if (!docInfoEntry) {
throw new Error('DocInfo not exist')
}
const content: Uint8Array = docInfoEntry.content as Uint8Array
const decodedContent: Uint8Array = inflate(content, { windowBits: -15 })
return new DocInfoParser(header, decodedContent, container).parse()
}흠… inflate(content, { windowBits: -15 }) 이 부분이 이해가 잘 안되긴 하는데... inflate가 부풀게 하다… 뭔가 압축을 해제한다는 동작인거 같습니다.
windowBits 매개변수는 창 크기(히스토리 버퍼 크기)의 기본 2 로그입니다. 이 버전의 라이브러리에서는 8..15 범위에 있어야 합니다. 이 매개변수의 값이 클수록 메모리 사용량을 희생하면서 압축 성능이 향상됩니다. 대신 deflateInit를 사용하는 경우 기본값은 15입니다.
음… 기본적으로 docInfo는 압축이 어느정도 되어있는건가… 그렇게 이해해야 될 거 같은데.. 네. 확인해보니 맞는거 같습니다.
- content: (1719)
- decodedContent: Uint8Array(11773)
DocInfoParser 가 메인 부분이라고 볼 수 있겠네요. DocInfo에 보면 무엇을 저장할지 내용이 다 정의되어있습니다.
class DocInfoParser {
...
private result = new DocInfo()
constructor(header: HWPHeader, data: Uint8Array, container: CFB$Container) {
this.header = header
this.record = parseRecordTree(data) ✅
this.container = container
}
...
parse() {
this.record.children.forEach(this.visit)
return this.result
}
}parseRecordTree는 한번 살펴보겠습니다.
function parseRecordTree(data: Uint8Array): HWPRecord {
const reader = new ByteReader(data.buffer)
const root = new HWPRecord(0, 0, 0)
while (!reader.isEOF()) {
const [tagID, level, size] = reader.readRecord() ✅
let parent: HWPRecord = root
const payload = reader.read(size) ✅
for (let i = 0; i < level; i += 1) {
parent = parent.children.slice(-1).pop()!
}
parent.children.push(new HWPRecord(tagID, size, parent.tagID, payload))
}
return root
}readRecord 를 보니 테그아이디, 길이, 레벨 값을 뽑아내는 걸 알 수 있습니다.
readRecord(): [number, number, number] {
const value = this.readUInt32()
const tagID = value & 0x3FF
const level = (value >> 10) & 0x3FF
const size = (value >> 20) & 0xFFF
if (size === 0xFFF) {
return [tagID, level, this.readUInt32()]
}
return [tagID, level, size]
}한글형식 문서 21쪽을 보면(PDF기준) 데이터 레코드라는 부분이 나옵니다.
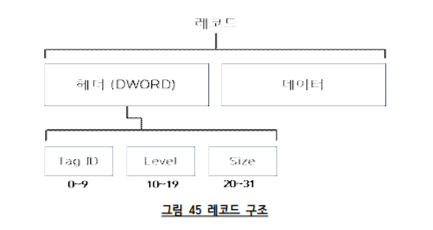
레코드 헤더의 크기는 32bits이고 TagID(10bits), Level(10bits), Size(12bits)로 구성된다.
- Tag ID에는 10 비트가 사용되므로 0x000 - 0x3FF까지 가능하다.
- Level : 대부분 하나의 오브젝트는 여러 개의 레코드로 구성되는 것이 일반적이기 때문에 하나의
레코드가 아닌 "논리적으로 연관된 연속된 레코드"라는 개념이 필요하다. 레벨은 이와 같이 연관된
레코드의 논리적인 묶음을 표현하기 위한 정보이다. 스트림을 구성하는 모든 레코드는 계층 구조로
표현할 수 있는데, 레벨은 바로 이 계층 구조에서의 depth를 나타낸다. - Size : 데이터 영역의 길이를 바이트 단위로 나타낸다. 12개의 비트가 모두 1일 때는 데이터 영역의
길이가 4095 바이트 이상인 경우로, 이때는 레코드 헤더에 연이어 길이를 나타내는 DWORD가
추가된다.
음. 그래서 tagID = value & 0x3FF, level = (value >> 10) & 0x3FF 이런식으로 해준 것이네요.
size === 0xFFF 이면 this.readUInt32() 하도록 하고요.
parseRecordTree 로 다시 돌아가서 const payload = reader.read(size) 해당 사이즈만큼 데이터를 이제 읽으면 됩니다. 아. 근데 level 0 다음에 level 1이 있으면 level 0을 부모로 삼고, 그 밑에 children으로 저장되는 모양입니다.

아무튼 그렇게 children 을 만든 다음 visit로 개별 태그마다 함수 처리를 해주는군요.
private visit = (record: HWPRecord) => {
switch (record.tagID) {
case DocInfoTagID.HWPTAG_DOCUMENT_PROPERTIES: {
this.visitDocumentPropertes(record)
break
}
case DocInfoTagID.HWPTAG_CHAR_SHAPE: {
this.visitCharShape(record)
break
}
case DocInfoTagID.HWPTAG_FACE_NAME: {
this.visitFaceName(record)
break
}
case DocInfoTagID.HWPTAG_BIN_DATA: {
this.visitBinData(record)
break
}
case DocInfoTagID.HWPTAG_BORDER_FILL: {
this.visitBorderFill(record)
break
}
case DocInfoTagID.HWPTAG_PARA_SHAPE: {
this.visitParagraphShape(record)
break
}
case DocInfoTagID.HWPTAG_COMPATIBLE_DOCUMENT: {
this.visitCompatibleDocument(record)
break
}
case DocInfoTagID.HWPTAG_LAYOUT_COMPATIBILITY: {
this.visitLayoutCompatibility(record)
break
}
default:
break
}
record.children.forEach(this.visit) // 아. children안에 또 children이 있으면 재귀...
}
parse() {
this.record.children.forEach(this.visit)
return this.result
}예를 들어 tagId가 16은 HWPTAG_DOCUMENT_PROPERTIES 입니다. 따라서 visitDocumentPropertes가 실행된다. 여기에 들어있는 내용은 다음과 같습니다.
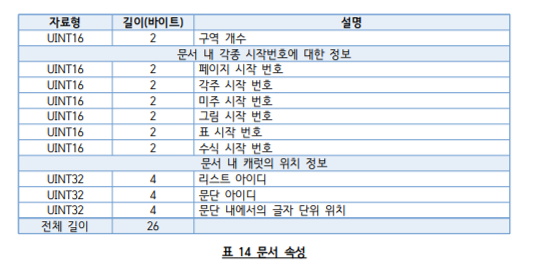
그래서 readUInt16로 2바이트씩 읽는 것이군요.
visitDocumentPropertes(record: HWPRecord) {
const reader = new ByteReader(record.payload)
this.result.sectionSize = reader.readUInt16()
this.result.startingIndex.page = reader.readUInt16()
this.result.startingIndex.footnote = reader.readUInt16()
this.result.startingIndex.endnote = reader.readUInt16()
this.result.startingIndex.picture = reader.readUInt16()
this.result.startingIndex.table = reader.readUInt16()
this.result.startingIndex.equation = reader.readUInt16()
this.result.caratLocation.listId = reader.readUInt32()
this.result.caratLocation.paragraphId = reader.readUInt32()
this.result.caratLocation.charIndex = reader.readUInt32()
}아무튼 이러한 과정을 반복하면 다음과 같은 데이터를 뽑아볼 수 있습니다.

parseSection
마지막 section 부분입니다. 문서의 본문에 해당되는 문단, 표, 그리기 개체 등의 내용이 저장됩니다.
BodyText 스토리지는 본문의 구역에 따라 Section%d 스트림(%d는 구역의 번호)으로 구분됩니다. 구역의 개수는 문서 정보의 문서 속성에 저장됩니다. (docInfo.sectionSize)
Section 스트림에 저장되는 데이터는 문단들(문단 리스트)이며, 다음과 같은 문단 정보들이 반복됩니다.
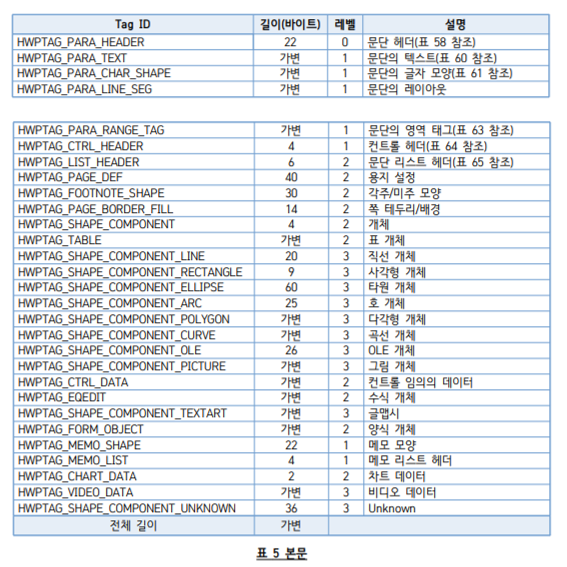
여기서보면 수식 개체가 있는 것을 볼 수 있습니다. (EQEDIT)
제어 문자(컨트롤)
표, 그림 등 일반 문자로 표현할 수 없는 요소를 표현하기 위해서 문자 코드 중 일부분을 특수 용도로 사용하고 있다.
문단 내용 중에 문자 코드가 0-31인 문자들은 특수 용도로 사용된다. 이미 13번 문자는 문단 내용의 끝 식별 기호로 사용된다는 것은 설명한 바 있다. 이외의 특수 문자들은 표나 그림 등, 일반 문자로 표현할 수 없는 문서 장식 요소를 표현하기 위해서 제어문자(컨트롤)로 사용된다.
제어 문자는 다음 세 가지 형식이 존재한다.
- 문자 컨트롤 [char] = 하나의 문자로 취급되는 문자 컨트롤 / size = 1
- 인라인 컨트롤 [inline] = 별도의 오브젝트 포인터를 가리키지 않는 단순한 인라인 컨트롤 / size = 8
- 확장 컨트롤 [extended] = 별도의 오브젝트가 데이터를 표현하는 확장 컨트롤 / size = 8
특히 확장컨트롤 같은 경우는 포인터가 있고… 따로 실제 데이터를 가리키는 부분이 있는거 같다.

const sections: Section[] = []
for (let i = 0; i < docInfo.sectionSize; i += 1) {
sections.push(parseSection(container, i))
}
return new HWPDocument(header, docInfo, sections)extended type의 컨트롤은 종류를 나타내는 식별 기호로 32 비트 ID가 사용된다. 컨트롤 코드가 큰 범주를 나타내는 식별 기호라고 한다면, 컨트롤 ID는 세부 분류를 나타내는 식별 기호인 셈이다.
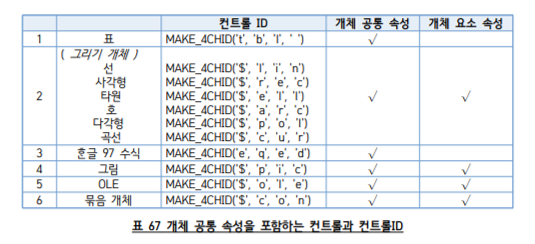
class SectionParser {
private record: HWPRecord
private result: Section
private content: Paragraph[] = []
constructor(data: Uint8Array) {
this.record = parseRecord(data)
this.result = new Section()
}parseRecord 를 통해 record 구조를 만든다. children안에 또 children이 있는구조를 볼수 있다.

근데 왜 … 처음에 children이 6개가 있는데 전부 tagId가 66인걸까. tagId가 66이라는 것은 HWPTAG_PARA_HEADER라는 뜻인데...
제가 테스트 중인 한글 문서를 보니 엔터까지 포함해서 총 6개의 문장으로 되어있었기 때문입니다. 즉, 각 문장? 단락? 마다 헤더가 있다는 것을 알 수 있군요.
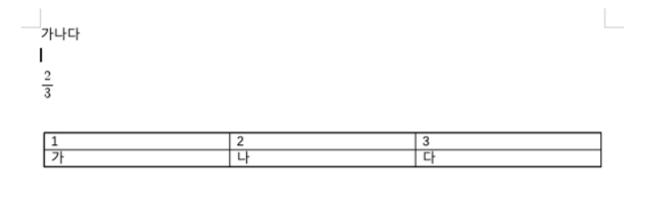
HWPTAG_PARA_TEXT 67에 있는 payload에서 00 AC ⇒ '가', 98 B0 ⇒ '나', E4 B2 ⇒ '다' 인것을 알 수 있다. 리틀 엔디안… 적용 (거꾸로 AC 00 이렇게 읽어야 됨)


신기하죠? 바이트를 읽으면서 한글 문자를 볼 수 있습니다.
다음으로 3번째 PARA_HEADER를 보면 이게 수식부분인데… 여기서 HWPTAG_CTRL_HEADER 를 확인하고, 또 여기서 tagID: 88 이 있는데 이 녀석이 바로 수식인 것을 알 수 있음.

보면 {2} over {3} 인 것을 알 수 있습니다. 뒤에 있는 내용은... 쓰잘대기 없는거 같군요.
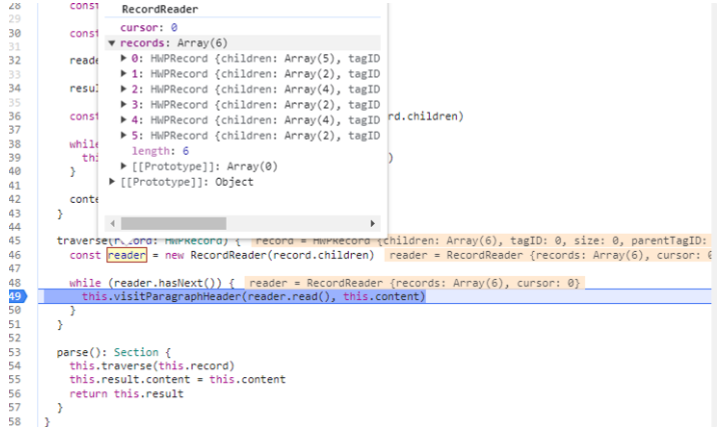
traverse(record: HWPRecord) {
const reader = new RecordReader(record.children)
while (reader.hasNext()) {
this.visitParagraphHeader(reader.read(), this.content)
}
}
parse(): Section {
this.traverse(this.record)
this.result.content = this.content
return this.result
}가장 최초 children 마다 반복문을 돌리는 과정을 거치고 있습니다.
이하 내용 생략...
마치면서
작업 중간에 몸도 안좋고... 몸이 안좋은 와중에도 자꾸 생각나서 '아... 좀만 더 하면 한글 수식 부분 구현 가능할 거 같은데...' 싶었습니다.
한글 문서랑 hwp.js를 완벽하게 분석하고 이해하진 못했지만 대략적인 구조나 로직에 대해 알 수 있었던 거 같습니다. 결국 한글 문서도 잘 만들어진 바이너리 데이터라는 사실도 알 수 있었고요.
그리고 분석을 위해 크롬 개발자 도구 디버깅이 많은 도움이 되었습니다. 덕분에 디버깅 실력이 좀 올라간거 같습니다. ㅎㅎ
아. 마지막으로 hwp.js 를 만들기 위한 개발자 님의 많은 노력이 엿보였습니다. hwp.js 코드 자체도 구성이 잘 되어있는거 같고 볼만 했습니다. 남이 잘 작성한 코드를 보면서 저 또한 개인적으로 도움이 되었던거 같습니다.
참고 자료
