SQL의 분류
SQL 문은 크게 DML, DDL, DCL로 분류한다.
-
DML(데이터 조작 언어) : 데이터를 조작(선택, 삽입, 수정, 삭제)하는데 사용되는 언어이다. SQL문 중에 SELECT, INSERT, UPDATE, DELETE가 이 구문에 해당된다. 또 트랜젹션이 발생하는 SQL도 이 DML이다.
-
DDL(데이터 정의 언어) : 데이터베이스, 테이블, 뷰, 인덱스 등의 데이터베이스 개체를 생성/삭제/변경하는 역할을 한다. 자주사용하는 DDL은 CREATE, DROP, ALTER 등이다. DDL은 트랜잭션을 발생시키지 않는다. 즉, 실행 즉시 MySQL에 적용되는 특징이 있다.
-
DCL(데이터 제어 언어) : 사용자에게 어떤 권한을 부여하거나 빼앗을때 주로 사용한다. GRANT, REVOKE, DENY 등이 이에 해당한다.
이번 시간에는 DML언어 중에서 SELECT에 대해 배워볼 것이다.
SELECT 구문 형식
SELECT문은 가장 많이 사용하는 구문이다. 처음에는 별거 아닌거 같지만 가면갈수록 어렵게 느껴지는 특징이 있다. SELECT는 데이터베이스 내의 테이블에서 원하는 정보를 추출할때 사용한다.
다음은 MySQL 8.0 Select Statement 공식 문서에 나와있는 전체 구문 형식이다.
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
[into_option]
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}SELECT문은 다양한 옵션으로 인해 전체 구문 형식은 복잡해보이지만 실제적으로 많이 사용되는 형태로 요약해보면 다음과 같다.
SELECT
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}아까보다 훨씬 단순해졌다. 그래도 복잡해보인다면 가장 자주 쓰이는 형식으로 줄여볼 수도 있다.
SELECT 열 이름
FROM 테이블 이름
WHERE 조건USE 구문
SELECT 문을 학습하려면 먼저 사용할 데이터베이스를 지정해야 한다. 이번 실습에서 사용할 데이터베이스는 잠시 후 만들게 될 sqldb 와 employees 이다.
데이터베이스를 지정 또는 변경하는 구문은 다음과 같다.
USE 데이터베이스_이름;한마디로 "지금부터 데이터베이스는 얘로 지정했으니 모든 쿼리는 이 데이터베이스에서 수행하라"는 의미이다.
SELECT와 FROM
본격적으로 SELECT문에 대해 실습을 통해 공부를 해보자. employees 데이터베이스를 선택한 후 다음 SQL문을 실행해보자
실습 1 - 기본 조회 방법
select * from titles;*은 모든 것을 의미한다. 즉 titles라는 테이블에서 모든 열에 대한 데이터를 가져오라는 의미가 된다. 특정 열만을 가져오고 싶다면 그 열의 이름을 적으면 되고, 만약 여러개를 가져오고 싶다면 콤마로 구분하면 된다.
실습 2 - SHOW와 DESC
근데 만약 오랜만에 MySQL에 접속한 경우 어떤 데이터베이스가 있었고 그 데이터베이스에는 어떤 테이블이 있고, 해당 테이블에는 어떤 정보가 있었는지 기억이 나지 않는다면? 물론 해결방법이 있다.
show databases; -- 어떤 데이터베이스가 있는지 조회
show table status; -- 현재 데이터베이스에 있는 테이블 정보 조회
desc employees; -- 특정 테이블에 열이 무엇이 있는지 조회자주쓰이는 명령어는 show와 desc이다.
실습 3 - AS
열 이름은 별도의 별칭(Alias)으로 지정할 수도 있다. 열 이름 뒤에 AS 별칭 형식으로 붙이면 된다. 하지만 별칭의 중간에 공백이 있다면 꼭 작은 따음표로(' ')로 별칭을 감싸줘야 한다. 또, AS는 붙여도 되고 생략해도 된다. 하지만 권장하는 방법은 AS를 쓰고 작은 따음표를 쓰는 것이다.
select first_name as '이름', gender as '성별', hire_date '회사 입사일'
from employees;실습 4 - sqldb 생성
이제는 조건을 지정해서 조회하는 방법에 대해 설명할 차례이다. 그 전에 간단히 인터넷 쇼핑몰 업체에서 운영할법한 데이터베이스를 단순화해서 만들어 본 다음 실습을 진행해보도록 하겠다.
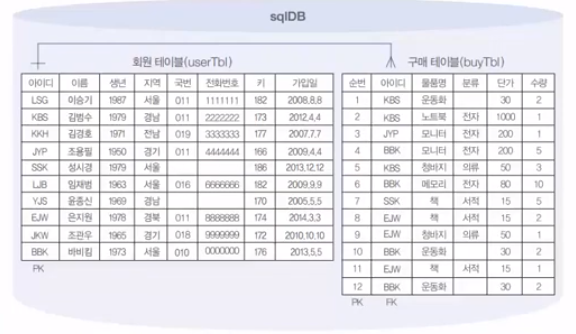
위 그림을 토대로 SQL 문을 작성보았다. 자세한 문법에 대해서는 추후 배우게될테니 그냥 그러려니 하고 넘어가면 된다.
drop database if exists sqldb; -- 만약 sqldb가 존재하면 우선 삭제한다.
create database sqldb;
use sqldb;
-- 회원테이블
create table usertbl (
userID char(8) not null primary key, -- 사용자 아이디(PK)
name varchar(10) not null, -- 이름
birthYear int not null, -- 출생년도
addr char(2) not null, -- 지역(경기, 서울, 경남 식으로 2글자만 입력)
mobile1 char(3), -- 휴대폰 국번(011, 064, 017, 010 등)
mobile2 char(8), -- 휴대폰 나머지 번호 (하이픈 제외)
height smallint, -- 키
mDate date -- 회원가입일
);
-- 회원구매 테이블
create table buytbl (
num int auto_increment not null primary key, -- 순번(PK)
userID char(8) not null, -- 아이디(FK)
prodName char(6) not null, -- 물품명
groupName char(4), -- 분류
price int not null, -- 단가
amount smallint not null, -- 수량
foreign key (userID) references usertbl(userID)
);💻 참고로 MySQL 8.0은 CHAR과 VARCHAR가 모두 UTF-8을 사용하기 때문에 영문/숫자/기호를 입력하면 내부적으로 1byte를 할당하고, 한글/중국어/일본어 등을 입력하면 내부적으로 3byte가 할당되므로 CHAR(10)을 설정하면 영문이든 한글이든 10글자까지 입력할 수 있다. 내부적으로 할당을 자동으로 다르게 해주므로 우리가 신경쓸필요는 없다는 뜻.
💻 두번째 참고로 데이터베이스 개체 이름을 설정할때 Linux에서는 데이터베이스 이름과 테이블 이름은 모두 소문자로 사용해야 하기 때문에 Windows와 Linux에서 동일한 코드를 사용하려면 개체 이름을 모두 소문자로 사용하는 것이 편리하다. 그니까 userTBL(X), usertbl(O), user_tbl(O) 이렇게 쓰라는 소리.
데이터베이스와 테이블을 생성했으므로 데이터를 넣어주도록 하자.
INSERT INTO usertbl VALUES('LSG', '이승기', 1987, '서울', '011', '1111111', 182, '2008-8-8');
INSERT INTO usertbl VALUES('KBS', '김범수', 1979, '경남', '011', '2222222', 173, '2012-4-4');
INSERT INTO usertbl VALUES('KKH', '김경호', 1971, '전남', '019', '3333333', 177, '2007-7-7');
INSERT INTO usertbl VALUES('JYP', '조용필', 1950, '경기', '011', '4444444', 166, '2009-4-4');
INSERT INTO usertbl VALUES('SSK', '성시경', 1979, '서울', NULL , NULL , 186, '2013-12-12');
INSERT INTO usertbl VALUES('LJB', '임재범', 1963, '서울', '016', '6666666', 182, '2009-9-9');
INSERT INTO usertbl VALUES('YJS', '윤종신', 1969, '경남', NULL , NULL , 170, '2005-5-5');
INSERT INTO usertbl VALUES('EJW', '은지원', 1972, '경북', '011', '8888888', 174, '2014-3-3');
INSERT INTO usertbl VALUES('JKW', '조관우', 1965, '경기', '018', '9999999', 172, '2010-10-10');
INSERT INTO usertbl VALUES('BBK', '바비킴', 1973, '서울', '010', '0000000', 176, '2013-5-5');
INSERT INTO buytbl VALUES(NULL, 'KBS', '운동화', NULL , 30, 2);
INSERT INTO buytbl VALUES(NULL, 'KBS', '노트북', '전자', 1000, 1);
INSERT INTO buytbl VALUES(NULL, 'JYP', '모니터', '전자', 200, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '모니터', '전자', 200, 5);
INSERT INTO buytbl VALUES(NULL, 'KBS', '청바지', '의류', 50, 3);
INSERT INTO buytbl VALUES(NULL, 'BBK', '메모리', '전자', 80, 10);
INSERT INTO buytbl VALUES(NULL, 'SSK', '책' , '서적', 15, 5);
INSERT INTO buytbl VALUES(NULL, 'EJW', '책' , '서적', 15, 2);
INSERT INTO buytbl VALUES(NULL, 'EJW', '청바지', '의류', 50, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '운동화', NULL , 30, 2);
INSERT INTO buytbl VALUES(NULL, 'EJW', '책' , '서적', 15, 1);
INSERT INTO buytbl VALUES(NULL, 'BBK', '운동화', NULL , 30, 2);그리고 조회를 해서 제대로 결과가 나오는지 확인하자. 이 책의 많은 부분이 이 sqldb를 사용하게 될 것이므로 혹시 다시 입력할필요 없도록 SQL문을 저장해놓자.
SELECT와 FROM 그리고 WHERE
기본적인 WHERE 절
WHERE절은 조회하는 결과에 특정한 조건을 줘서 원하는 데이터만 보고 싶을 때 사용하는데 다음과 같은 형식을 갖는다.
select * from usertbl where name = '김경호';DISTINCT
중복된 열 데이터가 있으면 중복을 제거해서 출력하고 싶을때도 있을 것이다. 만약 회원 테이블에서 회원의 거주지역을 출력해보면 중복된 지역이 존재하는 것을 알 수 있을 것이다.
select addr from usertbl;이때 사용하는게 DISTINCT이다. 상당히 중요하고 자주사용되므로 기억해두자.
select DISTINCT addr from usertbl;조건/관계 연산자 사용
조건절에는 관계 연산자 사용이 가능하다. 예를 들어 1970년 이후 출생하고 신장이 182이상인 사람의 아이디와 이름을 조회하고 싶다면 다음과 같이 SQL문을 작성하면 된다.
select userID, name from usertbl
where birthYear >= 1970 and height >= 182;결과는 이승기, 성시경 두 고객만 나올 것이다. 이렇듯 조건연산자(=, <, >, <=, >=, <>, != 등)와 관계연산자(NOT, AND, OR 등)을 잘 조합하면 다양한 쿼리를 생성할 수 있다. 참고로 <>와 !=는 같은 같지 않다라는 의미로 동일하다.
BETWEEN ~ AND
이번에는 키가 180~183인 사람을 조회해보자. 물론 조건연산자와 관계연산자를 이용해서 가능하지만 이번엔 BETWEEN ~ AND 연산자를 써보자.
select name, height from usertbl where height between 180 and 183;다만 BETWEEN ~ AND은 숫자로 구성된 연속적인 값을 갖는 경우에만 가능하다. 즉, 지역이 경남이거나 전남인 사람을 BETWEEN ~ AND연산을 통해 찾을 수는 없다.
IN
지역이 경남, 전남, 경북인 사람을 찾는 경우에는 IN을 쓰는게 훨씬 편리하다. 물론 이 역시 조건과 관계연산자로 조회가 가능하다.
select name, addr from usertbl where addr in ('경남', '전남', '경북');LIKE
LIKE는 문자열 중에서 특정 문자열을 검색할때 사용한다. 예를들어 이름이 김씨인 사람을 찾고 싶다면 다음과 같이 해주면 된다.
select name from usertbl where name LIKE '김%';%는 무엇이든 허용한다는 의미이고, 한글자와 매치하기 위해서는 _를 사용한다. 이번에는 이름이 종신인 사람을 조회해보자.
select name from usertbl where name LIKE '_종신';💻 참고로 다만
%나_로 검색할때 문자열 맨 앞에 들어가는 경우는 MySQL 성능에 나쁜 영향을 끼칠 수 있다고 한다. 따라서 대용량 데이터를 처리하는 경우에는 아주 비효율적인 결과를 낳게 된다. 나중에 상세히 다루도록 하겠다.
ANY/ALL/SOME 그리고 서브쿼리
서브 쿼리란 간단히 말하자면 쿼리문 안에 또 쿼리문이 들어있는 것을 말한다. 예를 들어 김경호란 사람의 키보다 같거나 큰 사람의 이름과 키를 출력하고 싶다면? 근데 김경호란 사람의 키를 모르는 경우는?
select name, height from usertbl
where height >= (select height from usertbl where name='김경호');김경호란 사람의 키를 먼저 조회한 다음 그 결과를 이용해 다시 조회할 수 있다. 하지만 이는 하위쿼리 결과가 한개라서 에러가 안나는 것이다. 만약 둘 이상의 값을 반환하는 경우는 어떻게 되는지 보자.
select name, height from usertbl
where height > (select height from usertbl where addr='경남');🚨 Error Code: 1242. Subquery returns more than 1 row 0.000 sec... 왜냐면 하위쿼리가 173과 170이라는 두가지 값을 반환하기 때문이다.
이 문제를 해결할 수 있는게 바로 ANY이다. 다음과 같이 코드를 고쳐서 실행해보자.
select name, height from usertbl
where height > ANY (select height from usertbl where addr='경남');ANY구문은 키가 173 보다 크거나 같은 사람 또는 170보다 크거나 같은 사람을 모두 출력한다. 즉 결국에는 키가 170보다 크거나 같은 사람이 출력되는것이다. 참고로 SOME은 ANY와 동일한 의미로 사용된다.
ANY말고도 ALL로 바꿔서 실행할 수도 있다. ALL은 173보다 크거나 같아야 하고 170보다 크거나 같아야 하므로 결과적으로 173보다 크거나 같은 사람이 출력된다.
테이블 복사 CREATE TABLE ... SELECT
CREATE TABLE ... SELECT는 테이블을 복사해서 사용할때 주로 사용한다. 아래는 buytbl을 buytbl2로 복사하는 구문이다. 필요하다면 지정한 일부열만 복사할 수 있다.
create table buytbl2 (select * from buytbl);하지만 PK나 FK 등의 제약조건은 복사되지 않는다.
