
인공지능(AI)
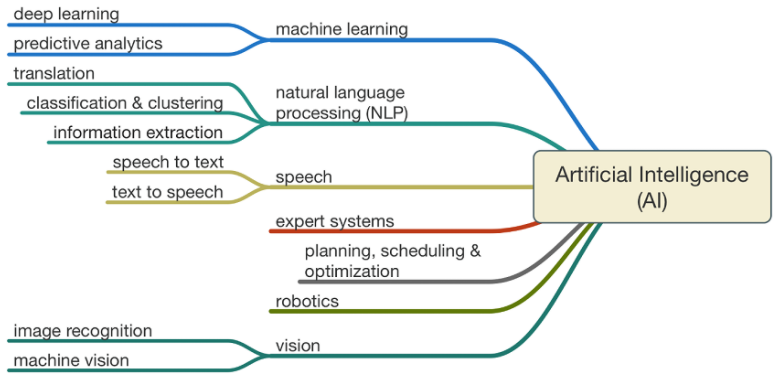
👉 이미지 출처 : https://futurearchitectureplatform.org/news/28/ai-architecture-intelligence/
개념
그림을 보면 알겠지만 인공지능은 머신러닝, 딥러닝 등을 포함하는 가장 큰 개념이다. 인공지능(artificial Intelligence)은 인간의 학습능력, 추론능력, 지각능력, 자연언어의 이해능력 등을 컴퓨터 프로그램으로 실현한 기술이라고 위키피디아에서는 정의하고 있다.
역사
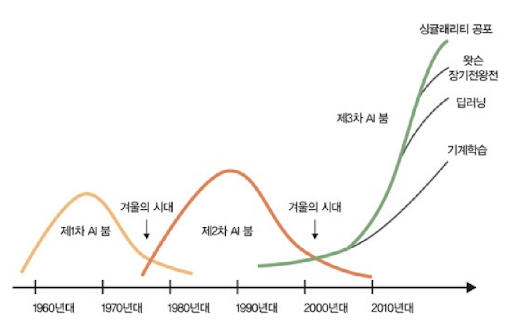
인공지능의 탄생(1943-1956)
1940년대 후반과 1950년대 초반에 이르러서 수학, 철학, 공학, 경제등 다양한 영역의 과학자들에게서 인공적인 두뇌의 가능성이 논의되었다. 1956년에 이르러서, 인공지능이 학문 분야로 들어서게 된다.
대표적인 사건으로는 최초의 인공신경망 모델 탄생, 튜링 테스트, 다트머스 컨퍼런스가 있다.
-
최초의 인공신경망 모델(1943) : 논리학자인 월터 피츠(Walter Pitts)와 신경외과의 워렌 맥컬럭은 한 논문을 발표하면서 여기서 뉴런의 작용을 0과 1로 이루어지는 2진법 논리 모델로 설명했고 이는 인간 두뇌에 관한 최초의 논리적 모델이 되었다.
-
튜링 테스트(1950) : 앨런 튜링은 생각하는 기계의 구현 가능성에 대한 분석이 담긴, 인공지능 역사에서 혁혁한 논문을 발표했다. 튜링 테스트는 인공 지능에 대한 최초의 심도 깊은 철학적 제안이다.
-
다트머스 컨퍼런스(1956) : 이 학회에서 존 매카시가 인공지능(AI, Artificial Intelligence)이라는 용어를 처음 사용했다. 넓은 의미의 AI의 탄생을 포함하는 순간이다.
첫번째 황금기(1956~1974년)
AI라는 새로운 영역은 발전의 땅을 질주하기 시작했다. 이 기간에 만들어진 프로그램은 많은 사람들을 놀랍게 만들었는데, 프로그램은 대수학 문제를 풀었고 기하학의 정리를 증명했으며 영어를 학습했다. 몇 사람들은 이와같은 기계의 "지능적" 행동을 보고 AI로 모든 것이 가능할 것이라 믿었다.
연구가들은 개인의 의견 또는 출판물들을 통해 낙관론을 펼쳤고, 완전한 지능을 갖춘 기계가 20년 안에 탄생할 것이라고 예측했다. 그리고 정부기관은 이 새로운 분야에 돈을 쏟아붓는다.
이 당시 인공지능 연구는 크게 두가지 분야로 나눠지게 되는데 바로 기호주의와 연결주의입니다.
-
기호주의 : 계산을 수행하려면 계산 과정을 정의하는 기호(Symbol)과 기호 간 연산에 대한 규칙(Rule)을 정의해야 하기 때문에 초창기 인공지능은 규칙기반 인공지능으로 발전하게된다. 하지만, 1980년대 이르러 성능부족과 범용성 부족, 그리고 근본적으로 실세계의 형상을 모두 기호화 할 수 있는가에 대한 의문이 제기되면서 쇠락하게 된다.
-
연결주의(Connectionism) : 기호화나 기호 조작만으로 지능을 충분히 설명할 수 없다고 보며 사람의 지능이 두뇌를 이루고 있는 신경들 사이의 연결에서부터 출발한다고 가정하고, 뇌 구조를 낮은 수준에서 모델링한 후 학습데이터를 통해 인공두뇌의 구조와 가중치 값을 변형시키는 방식으로 학습을 시도한다. 1958년 퍼셉트론이 최초로 개발되며 이렇게 세상 밖으로 나온 퍼셉트론은 사람들의 사진을 대상으로 남자와 여자를 구별해내고 뉴욕 타임즈에 실리게 된다. 인공지능 연구의 트렌드가 기호주의에서 연결주의로 넘어오게 되는 계기가 되었죠. 그리고 이 퍼셉트론은 오늘날 딥러닝으로 발전하게 된다.
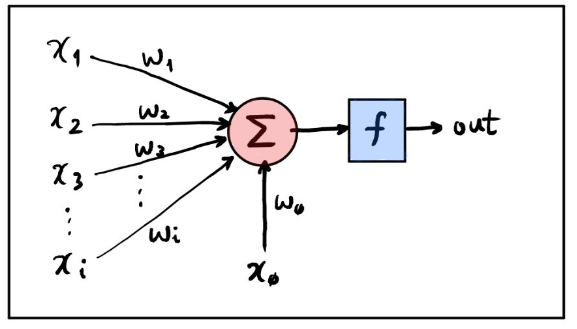
👉 출처 : https://brunch.co.kr/@hvnpoet/80
추가적으로, 기호주의와 연결주의를 더 알고 싶다면 여기를 참고하자.
첫번째 암흑기(1974-1980)
70년대에 이르자, AI는 비판의 대상이 되었고 재정적 위기가 닥치게 된다. AI 연구가들은 그들의 눈앞에 있는 복잡한 문제를 해결하는데 실패했다. 연구가들의 엄청난 낙관론은 연구에 대한 기대를 매우 높여놓았고, 그들이 약속했던 결과를 보여주지 못하자, AI에 대한 자금 투자는 사라져버렸다.
동시에, Connectionism 또는 뉴럴망은 지난 10년동안 마빈 민스키의 퍼셉트론(시각과 뇌의 기능을 모델화한 학습 기계)에 대한 파괴적인 비판에 의해 완전히 중지되었다.
퍼셉트론은 그 당시 두가지 문제를 가지고 있었는데...
-
XOR 문제 : 로젠 블랫의 퍼셉트론으로 AND, OR, NAND 같은 선형문제는 풀 수 있지만, XOR 같은 비선형 문제는 해결할 수 없었고, 대부분 데이터는 선형보다 비선형 형식으로 데이터가 분포되어 있었습니다.
-
당시의 정보처리 능력의 한계와 정보량의 부족
두번째 황금기(1980-1987)
1980년대에 존 홉필드와 데이비드 루멜하트의 신경망 이론의 복원이 이루어집니다.
-
역전파 알고리즘 제시(1974)
-
다층 신경회로망, 다층 퍼셉트론(Multi-Layer Perceptrons, MLP) 제시(1980)
1982년, 물리학자 John Hopfield는 (현재 ‘Hopfield net’이라고 불리는) 완벽한 새로운 길에서 정보를 프로세스하고 배울 수 있는 신경망의 형태를 증명해냈다. 이 시기에, David Rumelhart는 (Paul Werbos에 의해 발견된) “역전파”라고 불리는 신경망을 개선하기 위한 새로운 방법을 알리고 있었다. 이러한 두 가지 발견은 1970년 이후 버려진 신경망 이론이라는 분야를 복구시켰다.
신경망은 1990년대에 광학 문자 인식(OCR) 및 음성 인식과 같은 프로그램의 구동 엔진으로 사용되며 상업적으로 성공하게 된다.
두번째 암흑기(1987-1993)
물론 문자인식이나 음성인식등의 가시적인 성과가 있는 분야도 있었지만 대화 인공지능등의 개발 실패 등, 눈앞의 목표를 달성하지 못하는 경우도 많았기 때문인데 다시 주춤해지게 된다.
또한 역전파와 다층퍼셉트론을 실험적으로 증명해서 XOR문제가 해결되었지만 Vanishing Gradient와 Overfitting 문제가 새로 등장하기도 했다.
21세기
컴퓨팅 속도와 초고속 인터넷, 많은양의 데이터가 모이면서 인공지능 분야가 다시 성장하게 됩니다. 그 중심에 있던 것이 바로 제프리 힌튼입니다. 😲
모두가 인공신경망을 외면하던 암흑기 시절에도 제프리 힌튼은 꿋꿋하게 인공신경망을 연구해왔다. 제프리 힌튼은 “A fast learning algorithm for deep belief nets” 논문을 통해 가중치(weight)의 초깃값을 제대로 설정한다면 깊은 신경망을 통한 학습이 가능하다는 것을 밝혀내는데 성공한다.
기존 인공신경망과 크게 달라진 점은 없었지만, 인공지능의 두 번째 겨울을 거치면서 인공신경망이라는 단어가 들어간 논문은 제목만 보고 거절당하거나 사람들의 관심을 끌지 못해 deep을 붙인 DNN(Deep Neural Network)이라는 용어를 사용하면서 본격적으로 딥 러닝(Deep Learning) 용어가 사용되기 시작한다.
그리고 최종적으로 딥러닝의 성능을 알리는 몇가지 사건이 일어나게됩니다.
- 음성인식 정확도 향상
- 이미지넷 정확도 향상
- 비지도학습을 통한 이미지 인식 성공
이후에는 아시다시피 페이스북, 구글 같은 거대기업은 물론이고 네이버나 카카오같은 국내 기업도 딥러닝에 대해 적극적으로 연구중이니 말 다했다. (물론 또다시 겨울이 찾아올 수도 있습니다만 그건 아무도 모르는 거임)
인공지능, 머신러닝, 딥러닝
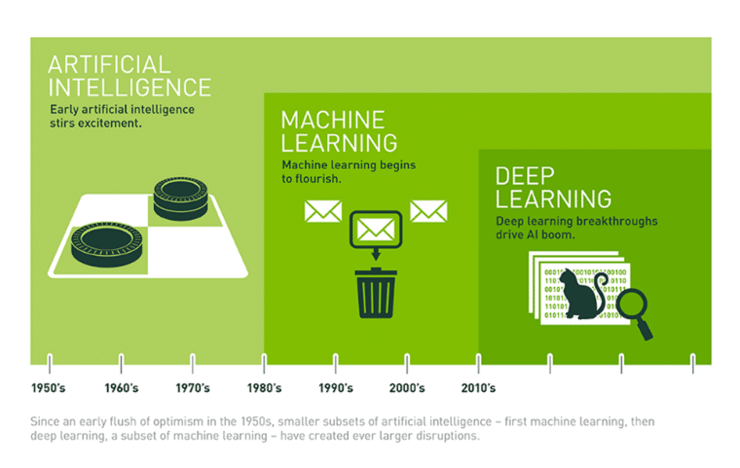
인공지능이 가장 넓은 개념이고, 인공지능을 구현하는 방법 중 중요한 방법이 기계학습 또는 머신러닝(Machine Learning)이다. 딥러닝(Deep Learning)은 머신러닝의 여러 방법 중 중요한 방법론이며 인공신경망(Artificial Neural Network)의 한 종류이다.
즉, 인공지능 ⊃ 머신러닝 ⊃ 인공신경망 ⊃ 딥러닝 관계가 성립한다.
인공지능에 대해서는 앞서 설명했기 때문에 머신러닝과 딥러닝이 뭔지 가볍게 살펴보고 마치도록 하겠다.
머신러닝
기계학습의 가장 그럴듯한 정의는 다음과 같다. 이는 "Machine Learning" 책을 지은 CMU의 교수 Tom M. Mitchell이 제시한 것이다.
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E." (해석하면, 어떠한 작업 T에 대해 꾸준한 경험 E를 통하여 그 T에 대한 성능 P를 높이는 것, 이것이 기계학습이라고 할 수 있다)
정의에서 알 수 있듯이, 기계학습에서 가장 중요한 것은 E에 해당하는 데이터이다. 좋은 품질의 데이터를 많이 가지고 있다면 보다 높은 성능을 끌어낼 수 있다. 그래서 오늘날에는 데이터가 중요한 자산 중 하나가 되는 계기가 된다.
학습 종류에 따른 분류로는 지도학습, 비지도학습, 강화학습이 존재하는데 구체적인 내용은 나중에 알아보도록 하겠다.
딥러닝
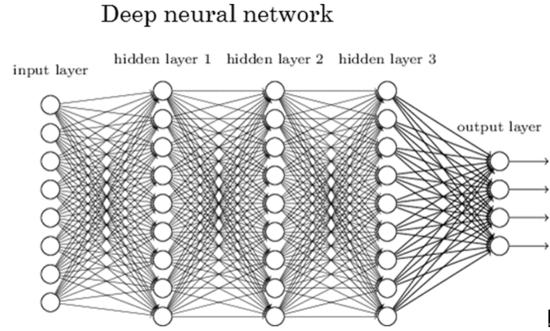
딥러닝은 입력과 출력 사이에 있는 인공 뉴런들을 여러개 층층이 쌓고 연결한 인공신경망 기법을 주로 다루는 연구이다. 인공신경망을 여러 개 쌓으면 Deep learning. RNN을 여러 계층으로 쌓으면 Deep RNN 같은 식이다.
본격적으로 딥 러닝이란 용어를 사용한 것은 2000년대 딥 러닝의 중흥기를 이끌어간다고 평가할 수 있는 제프리 힌튼과 Ruslan Salakhutdinov에 의해서이며 "인공신경망"이란 단어가 논문에 들어가면 퇴짜맞는다는 소문이 있었을 정도로 학계가 무관심을 넘어서 혐오했던 그당시 상황때문에 딥러닝이란 용어를 사용한게 결과적으로 성공한 셈이 된 것이다.
딥 러닝이 부활하게 된 이유는 크게 세 가지로 꼽힌다.
- 첫 번째는 앞서 딥 러닝의 역사에서 언급한 바 있는 기존 인공신경망 모델의 단점이 극복되었다는 점이다. (과적합)
- 두 번째 이유로, 여기에는 하드웨어의 발전이라는 또다른 요인이 존재 한다. 특히 강력한 GPU는 딥 러닝에서 복잡한 행렬 연산에 소요되는 시간을 크게 단축시켰다.
- 가장 중요한 세 번째 이유로 빅 데이터를 들 수 있다. 대량으로 쏟아져 나오는 데이터들, 그리고 그것들을 수집하기 위한 노력 특히 SNS 사용자들에 의해 생산되는 다량의 자료와 태그정보들 모두가 종합되고 분석 되어 학습에 이용될 수 있다.
마침
References
- https://futurearchitectureplatform.org/news/28/ai-architecture-intelligence/
- 위키피디아 인공지능 : https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
- 딥러닝의 기원을 열다 월터 피츠 : https://brunch.co.kr/@hvnpoet/80
- 인공지능의 역사 : https://insilicogen.com/blog/340
- 인공지능의 개념 : https://brunch.co.kr/@gdhan/1
- 딥러닝의 개념 : https://brunch.co.kr/@gdhan/7
- 나무위키 인공지능 : https://namu.wiki/w/%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
- 인공지능, 머신러닝, 딥러닝 개념 : https://brunch.co.kr/@gdhan/10
- 나무위키 심층학습 : https://namu.wiki/w/%EC%8B%AC%EC%B8%B5%ED%95%99%EC%8A%B5
- 나무위키 기계학습 : https://namu.wiki/w/%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5
참고 영상
