
배열
어떤 언어이든 배열은 기본이 되며 참 중요한 자료구조 중 하나이다.
의미
- 데이터를 나열하고, 각 데이터를 인덱스에 대응하도록 구성한 데이터 구조
- 파이썬에서는 리스트 타입이 배열 기능을 제공하고 있음
사용이유
- 같은 종류의 데이터를 효율적으로 관리하기 위해 사용
- 같은 종류의 데이터를 순차적으로 저장
- 장점 : 빠른 접근 가능 // 단점 : 추가 및 삭제가 쉽지 않음
파이썬 실습
파이썬에서 배열 생성 방법, 슬라이싱, 인덱싱, 사용가능한 메소드에 대해 알아보겠다.
1. 생성방법
파이썬은 배열을 리스트형으로 생성할 수 있다.
# 1차원 배열 리스트 구현
data = [1, 2, 3, 4, 5]
print(data) # [1, 2, 3, 4, 5]
# 2차원 배열 리스트 구현
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(data) # [[1, 2, 3], [4, 5, 6], [7, 8, 9]]또한 리스트형은 여러 종류의 자료형을 넣어줘도 상관없다.
# 1차원 배열 리스트 구현
data = [1, "문자열", 2, True]
print(data) # [1, '문자열', 2, True]2. 인덱싱/슬라이싱
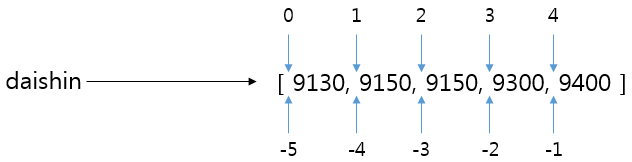
인덱싱은 그냥 보통 언어처럼 0은 첫번째, 1은 두번째를 가리킨다고 보면 된다. 하지만 파이썬은 추가적으로 -1, -2와 같은 음수도 가능한데 그 의미는 -1은 가장 뒤에 번호, -2는 가장 뒤에서 2번째 번호를 의미한다. (꽤나 자주 쓰이므로 잘 알아두어야 한다)
data = [1, 2, 3, 4, 5]
print(data[0]) # 1
print(data[1]) # 2
print(data[-1]) # 5
print(data[-2]) # 4이제 슬라이싱에 대해 알아보자. 슬라이싱은 범위를 지정해서 데이터를 가져올 수 있다. 하지만 여기서 주의할게 있는데 보통의 언어라면 [0:2]는 0~2 인덱스를 가리키는 반면, 파이썬은 0~1까지 범위를 갖는다. 왜 그럴까?
위 그림을 보면 알 수 있는데, 2가 가리키는게 9150과 9150사이이다. 이 의미는 9130, 9150까지만 포함되며 그 뒤에 9150까지는 포함되지 않는다는 것을 의미한다.
data = [1, 2, 3, 4, 5]
print(data[0:2]) # [1, 2]처음 파이썬을 접하는 사람에게는 꽤나 혼란스러운 방식이긴 하다.
그 외에도 특이한 예를 살펴보자. 왜 이런 결과가 나오는지 한번 추론해보길 바란다.
print(data[2:]) # [3, 4, 5]
print(data[-3:-1]) # [3, 4]
print(a[:]) # [1, 2, 3, 4, 5] , 주로 원본 배열 복사할때... 사용
print(data[::2]) # [1, 3, 5]이를 조금만 응용하면 리스트 뒤집기도 손쉽게 가능하다. 자주 쓰이는 구문이니 참고 바람.
data = [1, 2, 3, 4, 5]
print(data[::-1]) # [5, 4, 3, 2, 1]3. 지원하는 메소드
자바스크립트도 배열과 관련해서 여러 메소드가 있지만, 파이썬도 마찬가지다. 꽤나 중요하고 잘 알아두어야 한다.
data = [1, 2, 3, 4, 5]로 통일해서 실습하겠다.
3.1 len()
print(len(data)) # 5len()은 배열의 개수를 계산해서 알려준다.
3.2 append()
data.append(6)
print(data) # [1, 2, 3, 4, 5, 6]
data.append([1, 2])
print(data) # [1, 2, 3, 4, 5, [1, 2]]apppend()는 뒤에다가 요소를 추가하는 함수이다. (파이썬에서는 append 구나... 자바에서는 add, 자바스크립트에서는 push... 라서 매번 헷갈린다)
3.3 extend()
data.extend([1, 2])
print(data) # [1, 2, 3, 4, 5, 1, 2]append만큼은 아니지만 가끔씩 쓰이는 함수이다. 한번에 여러 요소를 추가하고 싶을때 extend를 사용하면 원래 리스트 뒤에 새로운 리스트의 요소를 모두 추가해준다.
print(data + [1, 2]) # [1, 2, 3, 4, 5, 1, 2]물론 +연산을 사용해서도 같은 결과를 낼 수 있습니다만 extend는 data 변수를 바꾸며, +는 data를 그대로 유지한다.
3.4 insert(index, object)
data.insert(2, 2.5)
print(data) # [1, 2, 2.5, 3, 4, 5]이것도 뭐... 자주는 아니지만 알아두면 좋은 함수이다. 원하는 위치에 데이터를 추가할 수 있다.
3.5 del
값을 추가하는 법을 공부했으니 이제는 삭제하는 법에 대해 알아보자.
del data[0]
print(data) # [2, 3, 4, 5]여러개를 삭제하려면 슬라이싱을 해주면 된다.
3.6 pop(index?)
print(data.pop()) # 5
print(data) # [1, 2, 3, 4]
print(data.pop(0)) # 1
print(data) # [2, 3, 4, 5]pop은 append 반대개념이라고 할 수 있다. 어찌보면 insert 반대라고도 볼 수 있다. index를 생략하면 가장 뒤에 요소를 추출한다.
index를 써주면 원하는 위치에 요소를 추출할 수도 있다. 여러모로 자주쓰이는 함수이다.
3.7 remove(값)
data.remove(2)
print(data) # [1, 3, 4, 5]리스트 내부에 있는 특정 값을 찾아서 제거하는 함수가 remove이다. 만약 data가 [1, 2, 2, 3, 4, 5]라고 해도 가장 앞에 있는 첫번째 2만 제거 시키게 된다.
3.8 clear()
리스트 내부의 요소를 모두 제거할 때는 clear를 사용하면 된다.
3.9 sort()
data를 이번에는 좀 바꿔야겠다. data = [1, 5, 2, 3, 4]로 지정해주자.
data.sort()
print(data) # [1, 2, 3, 4, 5]sort를 사용하면 오름차순으로 바로 정렬이 가능하다. 고급정렬알고리즘을 사용하기 때문에 정렬문제는 웬만하면 sort를 사용하면 한번에 풀린다.
data.sort(reverse=True)
print(data) # [5, 4, 3, 2, 1]sort에는 reverse 옵션이 존재한다. reverse를 True로 설정하면 내림차순 정렬 또한 가능하다. sort + lambda 라던가, 여러가지가 sort 응용이 있는데 이것은 정렬문제를 풀 때 따로 설명하도록 하겠다.
참고로, reverse 라는 함수도 별도로 존재한다. data.reverse() 사용가능.
3.10 count()
data = [1, 5, 2, 3, 4, 2]
print(data.count(2)) # 2count는 문자열에서도 사용가능하며 가끔가다 유용하게 쓰이는, 하지만 이거모른다고 문제를 못푸는건 아니고, 이걸 알면 좀더 간략하게 코드를 작성할 수 있는 함수이다.
리스트에 포함된 요소 x의 개수를 계산해준다.
3.11 copy()
파이썬에서 중요하고 그만큼 실수하기 좋은게 바로 리스트 복사이다.
data = [1, 2, 3, 4, 5]
a = data
a[0] = 2
print(a) # [2, 2, 3, 4, 5]
print(data) # [2, 2, 3, 4, 5]왜 a에서 0번째 인덱스 요소를 2로 지정했는데 data도 바뀐거지 의아할 수도 있겠다. a = data가 그 핵심인데 이렇게 실행하면 data가 가진 주소와 a가 가진 주소가 같아져버리기 때문이다.
이는 mutable(변하기 쉬운)한 객체의 변수간 대입에서 공통적으로 나타나는 현상으로 list, set, dict가 그에 해당한다. immutable(불변)한 string에 대해서는 그런 현상이 나타나지 않는다. 불변하기 때문에 아예 값이 재할당되면서 메모리 주소가 변경되기 때문이다.
어쨌든 어려운 얘기를 해버렸는데... 이를 해결하기 위해서는 얕은 복사와 깊은복사가 있다. 얕은 복사는 list의 슬라이싱을 통해 가능하다. 혹은 data.copy()를 사용한다.
data = [1, 2, 3, 4, 5]
a = data[:]
a[0] = 2
print(a) # [2, 2, 3, 4, 5]
print(data) # [1, 2, 3, 4, 5]다만 이는 얕은 복사이기 때문에 리스트안에 리스트가 있는 경우는 또 문제가 된다.
data = [[1, 2], [3, 4]]
a = data[:]
a[0][0] = 2
print(a) # [[2, 2], [3, 4]]
print(data) # [[2, 2], [3, 4]]이를 해결하기 위해 깊은 복사라는 방법이 있다. 바로 copy라는 라이브러리를 이용해서 copy.deepcopy메소드를 사용하는 방법.
import copy
data = [[1, 2], [3, 4]]
a = copy.deepcopy(data)
a[0][0] = 2
print(a) # [[2, 2], [3, 4]]
print(data) # [[1, 2], [3, 4]]가끔가다 쓰이기 때문에 알아둘 필요가 있다.
4. 기타
4.1 in과 not in
data = [1, 2, 3, 4, 5]
print(2 in data) # True
print(6 not in data) # Truein과 not in은 리스트 내부에 내가 원하는 값이 존재하는지 판단할때 유용하게 쓰인다.
4.2 반복문
data = [1, 2, 3, 4, 5]
for d in data:
print(d)
for index, value in enumerate(data):
print(index, value)References
- 패스트캠퍼스 알고리즘 / 기술면접 완전 정복 올인원 패키지 Online : https://fastcampus.co.kr/dev_online_algo
- 위키독스 점프 투 파이썬 리스트자료형 : https://wikidocs.net/14
- 위키독스 파이썬 기본을 갈고 닦자! "얕은복사와 깊은복사" : https://wikidocs.net/16038
