개요
- 풀이 시간 : 30분
- 시간 제한 : 12초
- 메모리 제한 : 1024MB
- 기출 : 백준 7453번 문제
- 링크 : https://www.acmicpc.net/problem/7453
문제
정수로 이루어진 크기가 같은 배열 A, B, C, D가 있다.
A[a], B[b], C[c], D[d]의 합이 0인 (a, b, c, d) 쌍의 개수를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 배열의 크기 n (1 ≤ n ≤ 4000)이 주어진다. 다음 n개 줄에는 A, B, C, D에 포함되는 정수가 공백으로 구분되어져서 주어진다. 배열에 들어있는 정수의 절댓값은 최대 이다.
출력
합이 0이 되는 쌍의 개수를 출력한다.
해결방법
난 처음에 문제를 잘못이해해서 한줄씩 계산해서 0이되는 경우에만 1 증가시켜서 결과를 리턴해주면 되는거 아닌가? 생각했다.
문제풀이
사실 한줄씩 계산하는거는 아니며 세로 한줄씩 A, B, C, D 배열이고 각 원소마다 순서쌍을 정해서 0이 되는 쌍의 개수를 구하는 문제이다. 단순히 생각해보면 순열이라고 볼 수 있겠다. 조합은 (a, b, c, d)랑 (b, a, c, d)랑 같은거고 순열은 이 둘을 다른 경우로 보기 때문이다.
하지만 모든 순열을 따져가면서 연산을 하다보면 경우의 수가 너무 많아져 아래에 있는 내 코드와 같이 시간 초과가 난다.
결국 다른 방법을 생각해서 풀어야 정답을 맞출 수 있는 문제이다...
알고리즘
음... 정답을 말하자면 다음과 같이 풀면 된다.
- A[a]와 B[b]로 만들 수 있는 딕셔너리를 구현한다. 딕셔너리의 key와 value는 만들 수 있는 숫자와 해당 숫자의 개수이다.
- C[c]와 D[d]로 만들 수 있는 값에 -를 붙인 값이 해당 딕셔너리에 존재하는지 확인한 후 존재한다면 해당 key의 value 값을 result 값에 더해준다.
- 마지막으로 result를 출력해주면 끝
생각해보면 정말 쉬운 문제다. 사실 A-B, C-D 따로 계산하는거 까지는 생각했었는데... dict을 이용해서 푸는 것 까지는 생각하지 못했다. 아쉽네... dict을 이용해 풀면 내부적으로 해시를 이용하기 때문에 찾는 속도가 빠르다는 점을 이용했다.
Python
내 코드(21.1.18)
n = int(input())
result = 0
A, B, C, D = [], [], [], []
for _ in range(n):
a, b, c, d = map(int, input().split())
A.append(a)
B.append(b)
C.append(c)
D.append(d)
for a in A:
for b in B:
for c in C:
for d in D:
if a + b + c + d == 0:
print("fewf", a, b, c, d)
result += 1
print(result)경우의 수를 생각해보면 4000 x 4000 x 4000 x 4000 ... 절대 시간내에 못푼다. (ㄹㅇ 이걸 왜 구현했냐? ㅋㅋ)
2차 시도(21.3.3)
한달 반만에 다시 도전해봤다. 아... 그래도 방법은 잘 기억해냈는데 구현에서 약간 실수하는바람에..ㅠㅠ
import sys
from collections import defaultdict
if __name__ == "__main__":
n = int(input())
left = []
right = []
for i in range(n):
a, b, c, d = map(int, sys.stdin.readline().split())
left.append((a, b))
right.append((c, d))
# print(left, right)
left_dict = defaultdict(int)
right_dict = defaultdict(int)
for i in range(n):
for j in range(n):
left_dict[left[i][0] + left[j][1]] += 1
right_dict[right[i][0] + right[j][1]] += 1
# print(left_dict, right_dict)
result = 0
for ld, lc in left_dict.items():
if -1 * ld in right_dict.keys():
result += lc
print(result)굳이 right_dict를 구현할 필요가 없었다. 왜냐면 right[i][0] + right[j][1] 를 left_dict 저장이 끝난다음 바로 찾아서 검색하면 되기 때문. 즉 아래처럼 구현하는게 메모리 측면에서 더 효과적이다. (아무래도 처음 시도는 시간 초과가 아니라 메모리 초과일 수도 있겠다는 생각이 든다)
...
left_dict = defaultdict(int)
for i in range(n):
for j in range(n):
left_dict[left[i][0] + left[j][1]] += 1
# print(left_dict, right_dict)
result = 0
for i in range(n):
for j in range(n):
temp = (right[i][0] + right[j][1]) * -1
if temp in left_dict.keys():
result += left_dict[temp]
print(result)
✍️ 에잇. 맞출 수 있었는데 아쉽게 됐다.
정답 코드
n = int(input())
result = 0
A, B, C, D = [], [], [], []
for _ in range(n):
a, b, c, d = map(int, input().split())
A.append(a)
B.append(b)
C.append(c)
D.append(d)
ab = dict()
for a in A:
for b in B:
v = a + b
if v not in ab.keys():
ab[v] = 1
else:
ab[v] += 1
for c in C:
for d in D:
v = -1 * (c + d)
if v in ab.keys():
result += ab[v]
print(result)
생각해보면 별거 아닌문제네...😂😂
좀 더 효율적인 정답 코드
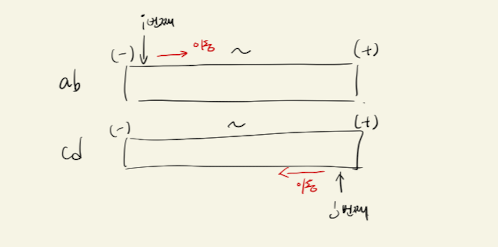
사실 백준에서는 이 알고리즘을 투 포인터, 정렬, 이분탐색으로 명시해놓고 있었다. 여기서는 정렬 + 투 포인터 방식을 이용해서 문제를 풀어보는 방법을 적어보겠다.
import sys
input = sys.stdin.readline
if __name__ == "__main__":
n = int(input())
arr = [list(map(int, input().split())) for _ in range(n)]
ab, cd = [], []
for i in range(n):
for j in range(n):
ab.append(arr[i][0] + arr[j][1])
cd.append(arr[i][2] + arr[j][3])
ab.sort()
cd.sort()
# print(ab, cd)
i, j = 0, len(cd) - 1 # i는 ab의 시작점, j는 cd의 끝점(투포인터)
result = 0
while i < len(ab) and j >= 0:
if ab[i] + cd[j] == 0: # 합이 0이 되는 경우
nexti, nextj = i + 1, j - 1
# ab가 같은게 여러개인경우
while nexti < len(ab) and ab[i] == ab[nexti]:
nexti += 1
# cd가 같은게 여러개인경우
while nextj >= 0 and cd[j] == cd[nextj]:
nextj -= 1
result += (nexti - i) * (j - nextj) # 이야... 지리네
i, j = nexti, nextj
elif ab[i] + cd[j] > 0: # cd가 ab보다 더 절댓값이 큰경우
j -= 1
else: # ab가 cd보다 더 절댓값이 큰 경우
i += 1
print(result)
# 코드 참고 : https://www.acmicpc.net/source/26772324그림을 그려보면 해당 코드를 왜 이렇게 작성했는지 쉽게 알 수 있을 것이다. 오키도키?

이런 방식으로 풀었을때 메모리와 시간이 꽤 많이 단축되는 것을 볼 수 있었다.






