개요
- 풀이 시간 : 30분
- 시간 제한 : 2초
- 메모리 제한 : 128 MB
- 기출 : ICPC > Regionals > Europe > Southeastern European Regional Contest > SEERC 2003 D번
- 난이도 : 골드 4
- 링크 : https://www.acmicpc.net/problem/2109
문제
한 저명한 학자에게 n(0 ≤ n ≤ 10,000)개의 대학에서 강연 요청을 해 왔다. 각 대학에서는 d(1 ≤ d ≤ 10,000)일 안에 와서 강연을 해 주면 p(1 ≤ p ≤ 10,000)만큼의 강연료를 지불하겠다고 알려왔다. 각 대학에서 제시하는 d와 p값은 서로 다를 수도 있다. 이 학자는 이를 바탕으로, 가장 많은 돈을 벌 수 있도록 순회강연을 하려 한다. 강연의 특성상, 이 학자는 하루에 최대 한 곳에서만 강연을 할 수 있다.
예를 들어 네 대학에서 제시한 p값이 각각 50, 10, 20, 30이고, d값이 차례로 2, 1, 2, 1 이라고 하자. 이럴 때에는 첫째 날에 4번 대학에서 강연을 하고, 둘째 날에 1번 대학에서 강연을 하면 80만큼의 돈을 벌 수 있다.
입력
첫째 줄에 정수 n이 주어진다. 다음 n개의 줄에는 각 대학에서 제시한 p값과 d값이 주어진다.
출력
첫째 줄에 최대로 벌 수 있는 돈을 출력한다.
해결방법
문제 이해하기
해당 문제를 딱 보자마자 백준 1781번 - 컵라면 이 문제가 생각이 났다. 하지만 어떻게 풀었는지는 좀처럼 생각나지 않았다...ㅠㅠ 진짜 이제는 문제만 봐도 '어 내가 풀었던 문제네' 이거는 생각나는데 자꾸 어떻게 풀었는지는 까먹는 현상이 나타난다.
알고리즘
가정 1. 가장 강의료가 쎈 순서로 구하면 될까?
45 1
45 1
80 2만약 위와 같이 입력이 주어진다면 어떨까? 가장 강의료가 쎈 순서로 구하면 80 밖에 못 얻는다. 하지만 실제로는 45 + 80 = 125를 얻을 수 있다.
가정 2. 날짜 순서에서 가장 강의료가 쎈 순서로 구하면 될까?
20 1
45 1
50 2
60 3
60 3해당 가정대로 문제를 풀어보면 45 + 50 + 60 = 155가 된다. 하지만 정답은 50 + 60 + 60 = 170이 된다. 따라서 이 가정도 정답이 될 수 없다.
그래서 어떻게 풀어야 하는데...!!
컵라면 문제 풀이와 진짜 똑같이 풀면 된다. 나도 결국 생각이 안나서 이전에 푼 거를 봤는데 하... 이쯤되면 제발 기억좀 하자.
- 먼저 d(데드라인) 순서로 정렬한다.
- 힙을 만든다. 그리고 데드라인 순서로 강연료를 힙에다가 넣는다(heappush).
- 그리고 힙의 개수가 데드라인보다 크다면 heappop을 해준다. 그러면 강연료가 제일 작은 녀석이 나갈 것이다.
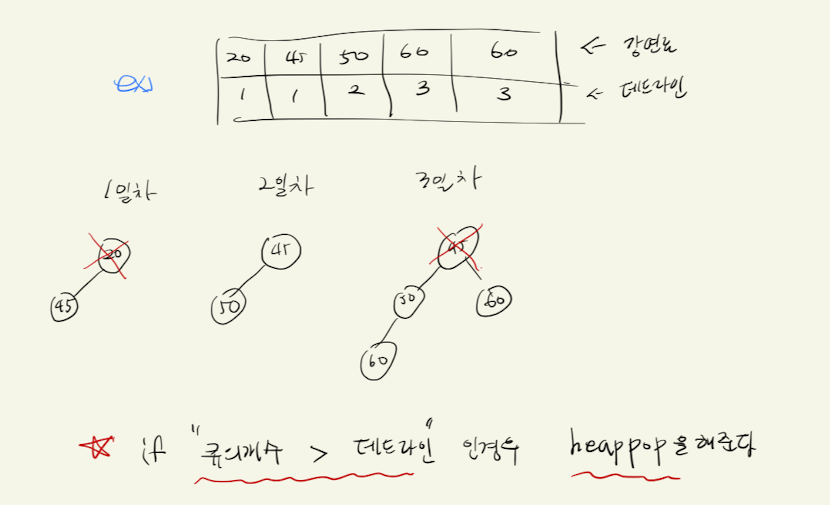
그니까 날짜 순서대로 힙에다가 넣긴하는데 데드라인이 힙의 개수가 되도록 균형을 잡아주는 구나...
✍️ 다시봐도 이런 생각은 어떻게 했는지 신기하기만 하다...
Python
내 코드
import sys
import heapq
input = sys.stdin.readline
if __name__ == "__main__":
n = int(input())
if n == 0:
print(0)
exit()
data = []
for _ in range(n):
amount, deadline = map(int, input().split())
data.append((deadline, amount))
data.sort()
q = []
for deadline, amount in data:
heapq.heappush(q, amount)
if len(q) > deadline:
heapq.heappop(q)
print(sum(q))
이외로 정답률이 낮은편이 었는데 아마 문제에서 n이 0이 되는 뜬끔없는 경우 때문에 그렇듯하다. (진짜 뜬금없기는 하다...ㅋㅋ n이 왜 0이 있는건지)
