개요
- 풀이 시간 : 40분
- 시간 제한 : -
- 메모리 제한 : -
- 기출 : 2019 KAKAO BLIND RECRUITMENT
- 링크 : https://programmers.co.kr/learn/courses/30/lessons/42893
문제
프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다. 평소에 관심있어하던 검색에 마침 결원이 발생하여, 검색개발팀에 편입될 수 있었고, 대망의 첫 프로젝트를 맡게 되었다.
그 프로젝트는 검색어에 가장 잘 맞는 웹페이지를 보여주기 위해 아래와 같은 규칙으로 검색어에 대한 웹페이지의 매칭점수를 계산 하는 것이었다.
- 한 웹페이지에 대해서 기본점수, 외부 링크 수, 링크점수, 그리고 매칭점수를 구할 수 있다.
- 한 웹페이지의 기본점수는 해당 웹페이지의 텍스트 중, 검색어가 등장하는 횟수이다. (대소문자 무시)
- 한 웹페이지의 외부 링크 수는 해당 웹페이지에서 다른 외부 페이지로 연결된 링크의 개수이다.
- 한 웹페이지의 링크점수는 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합이다.
- 한 웹페이지의 매칭점수는 기본점수와 링크점수의 합으로 계산한다.
예를 들어, 다음과 같이 A, B, C 세 개의 웹페이지가 있고, 검색어가 hi라고 하자.
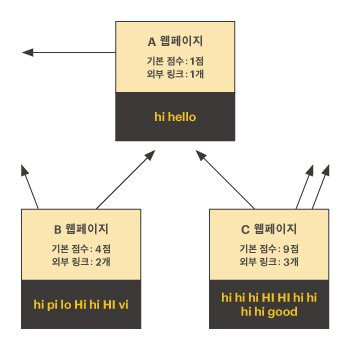
이때 A 웹페이지의 매칭점수는 다음과 같이 계산할 수 있다.
- 기본 점수는 각 웹페이지에서 hi가 등장한 횟수이다.
- A,B,C 웹페이지의 기본점수는 각각 1점, 4점, 9점이다.
- 외부 링크수는 다른 웹페이지로 링크가 걸린 개수이다.
- A,B,C 웹페이지의 외부 링크 수는 각각 1점, 2점, 3점이다.
- A 웹페이지로 링크가 걸린 페이지는 B와 C가 있다.
- A 웹페이지의 링크점수는 B의 링크점수 2점(4 ÷ 2)과 C의 링크점수 3점(9 ÷ 3)을 더한 5점이 된다.
- 그러므로, A 웹페이지의 매칭점수는 기본점수 1점 + 링크점수 5점 = 6점이 된다.
검색어 word와 웹페이지의 HTML 목록인 pages가 주어졌을 때, 매칭점수가 가장 높은 웹페이지의 index를 구하라. 만약 그런 웹페이지가 여러 개라면 그중 번호가 가장 작은 것을 구하라.
입력 형식
- pages는 HTML 형식의 웹페이지가 문자열 형태로 들어있는 배열이고, 길이는 1 이상 20 이하이다.
- 한 웹페이지 문자열의 길이는 1 이상 1,500 이하이다.
- 웹페이지의 index는 pages 배열의 index와 같으며 0부터 시작한다.
- 한 웹페이지의 url은 HTML의
<head>태그 내에<meta>태그의 값으로 주어진다- 예를들어, 아래와 같은 meta tag가 있으면 이 웹페이지의 url은
https://careers.kakao.com/index이다. <meta property="og:url" content="https://careers.kakao.com/index" />
- 예를들어, 아래와 같은 meta tag가 있으면 이 웹페이지의 url은
- 한 웹페이지에서 모든 외부 링크는
<a href="https://careers.kakao.com/index"\>의 형태를 가진다.<a>내에 다른 attribute가 주어지는 경우는 없으며 항상 href로 연결할 사이트의 url만 포함된다.- 모든 url은 https:// 로만 시작한다.
- 검색어 word는 하나의 영어 단어로만 주어지며 알파벳 소문자와 대문자로만 이루어져 있다.
- word의 길이는 1 이상 12 이하이다.
- 검색어를 찾을 때, 대소문자 구분은 무시하고 찾는다.
- 검색어는 단어 단위로 비교하며, 단어와 완전히 일치하는 경우에만 기본 점수에 반영한다.
- 단어는 알파벳을 제외한 다른 모든 문자로 구분한다.
- 예를들어 검색어가 "aba" 일 때, "abab abababa"는 단어 단위로 일치하는게 없으니, 기본 점수는 0점이 된다.
- 만약 검색어가 "aba" 라면, "aba@aba aba"는 단어 단위로 세개가 일치하므로, 기본 점수는 3점이다.
- 결과를 돌려줄때, 동일한 매칭점수를 가진 웹페이지가 여러 개라면 그중 index 번호가 가장 작은 것를 리턴한다
- 즉, 웹페이지가 세개이고, 각각 매칭점수가 3,1,3 이라면 제일 적은 index 번호인 0을 리턴하면 된다.
해결방법
문제 이해하기
어휴... 문제 길이부터 거부감이 몰려온다. 카카오는 은근 이런 문제를 자주 내는 편인듯하다. 문제는 길지만 잘 살펴보면 핵심은 3가지라고 볼 수 있다.
- 페이지 내에서 웹페이지의 url 찾기
- 페이지 내에서 모든 외부 링크 찾기
- 페이지 내에서 모든 검색어 찾기
알고리즘 - 정규표현식
결국에는 문자열 내에서 특정 형태를 찾아내야 하는 문제이다. 따라서 얼마나 정규표현식을 잘 사용하느냐 못하느냐에 따라서 이 문제를 빠르게 풀 수 있느냐 없느냐 판가름 날 것이다.
1. 페이지 내에서 웹페이지의 url 찾기
일단 하나씩 살펴보자. 먼저 페이지 내에서 웹페이지의 url 찾기이다. 언뜻보면 쉬워보이지만 함정이 존재한다. 처음에 나는 단순히 아래와 같이 작성해주었다.
url = re.search('content="(.+)"', page).group(1)하지만 이런식으로 작성하면 테스트케이스 9번을 통과하지 못하는거 같다. 찾아보니 meta 태크의 property 옵션이 og:url 것 중에 content 의 내용이 https:// 으로 시작하는 url을 찾아야 된다고 한다. 따라서 아래와 같은 경우에는 올바른 형식이 아니기 때문에 틀렸다고 볼 수 있다.
<meta content="https://careers.kakao.com/index" />
<meta property="og:url" content="careers.kakao.com/index" />그러면 어떻게 수정하면 되느냐? 아래와 같이 작성하는 것이 좋다. 여기서 \S는 공백문자가 아닌 모든 문자를 말한다. (공백문자란 스페이스, 탭, 줄바꿈 등을 말함)
url = re.search('<meta property="og:url" content="(\S+)"', page).group(1)2. 페이지 내에서 모든 외부 링크 찾기
여기서도 함정이 존재한다. 나는 처음에 아래와 같이 작성해서 모든 외부 링크를 찾을 수 있었다고 생각했다.
exiosLink = re.findall('<a href="(.+)">', page)하지만 이런식으로 작성하면 테스트케이스 4, 6, 8, 10, 17을 통과하지 못했다. 이런 이유에 대해서도 찾아보니까 아래와 같은 상황에서 제대로 동작하지 않는 것을 알 수 있었다. (은근 정규식을 제대로 사용하지 못하고 있었구나... 반성 😂)
exiosLink = re.findall('<a href="(.+)">', '<a href="https://rerfdb"> test="dfdqom">')
print(exiosLink) # ['https://rerfdb"> test="dfdqom']위 경우에는 단순히 "(.+)"라고 했으며 .가 모든 문자를 의미하고 +가 1이상을 의미하므로 ">가 뒤에 있는 경우라면 무조건 골라낸다. 앞에 "> 가 아니라 맨 뒤에 ">를 찾아서 위와 같은 출력이 나오게 된다. 음... 이를 어떻게 해결하면 좋을까?
exiosLink = re.findall('<a href="(https://[\S]*)"', page)위와 같이 해결할 수 있다. 여기서 중요한 점은 공백문자가 아니라는 점...이다. 🤔
3. 페이지 내에서 모든 검색어 찾기
마지막으로 해결해야할 주제는 페이지 내에서 모든 검색어 찾기이다. 이것도 상당히 까다로웠다. 결국 아래와 같이 해결하는 방법을 찾기는 했지만...
basicScore = 0
for f in re.findall(r'[a-zA-Z]+', page.lower()):
if f == word.lower():
basicScore += 1정규식 한줄로 찾으려고 별짓을 다해봤는데 너무 어렵더라고... 이게 왜그러냐면 만약 Muzi를 찾는다고 했을때 아래와 같은 예시가 있다면..
- #!MuziMuzi! => 이거는 안 되는거임(Muzi랑 MuziMuzi은 다름)
- muzI92apeach&2 => 이거는 되는거임(Muzi랑 muzI는 같음)
문제에서 단어 단위를 알파벳을 제외한 다른 모든 문자로 구분한다고 했었으니까... 92앞에 muzI는 한 단어가 되는 셈이다. (와... 어렵다)
cnt = re.sub('[^a-zA-Z]', ' ', k).lower().split().count(word.lower())혹은 sub를 통해 알파벳 대소문자가 아닌걸 다 치환시켜서 찾는 방법도 있었다.
Python
정답 코드
import re
def solution(word, pages):
webpage = []
webpageName = []
webpageGraph = dict() # 나를 가리키는 외부 링크
for page in pages:
url = re.search('<meta property="og:url" content="(\S+)"', page).group(1)
basicScore = 0
for f in re.findall(r'[a-zA-Z]+', page.lower()):
if f == word.lower():
basicScore += 1
exiosLink = re.findall('<a href="(https://[\S]*)"', page)
for link in exiosLink:
if link not in webpageGraph.keys():
webpageGraph[link] = [url]
else:
webpageGraph[link].append(url)
webpageName.append(url)
webpage.append([url, basicScore, len(exiosLink)]) # 내가 가진 외부 링크 (개수)
# 링크점수 = 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합
# 매칭점수 = 기본점수 + 링크점수
maxValue = 0
result = 0
for i in range(len(webpage)):
url = webpage[i][0]
score = webpage[i][1]
if url in webpageGraph.keys():
# 나를 가리키는 다른 링크의 기본점수 ÷ 외부 링크 수의 총합을 구하기 위해
for link in webpageGraph[url]:
a, b, c = webpage[webpageName.index(link)]
score += (b / c)
if maxValue < score:
maxValue = score
result = i
return result
✍️ 어렵다. 어려워... 역시 정규표현식은 내가 아는게 아는게 아니야~~
