
오디오 실험실 두 번째 글입니다. 저번 시간에는 스피커 + 앰프를 이용해 간단한 소리를 출력해봤는데요. (참고)
이번에는 오디오 입력을 받아서 데이터가 제대로 잘 넘어오는 지 확인하고 분석 해보려고 합니다. 이를 위해 INMP441 디지털 MEMS 마이크 모듈을 사용해 봅니다.
INMP441
INMP441은 TDK InvenSense에서 제조하는 고성능, 저전력, 디지털 출력, 전방향성 MEMS 마이크로폰입니다.
이 마이크는 마이크로폰 센서, 신호 컨디셔닝 회로, 아날로그-디지털 변환기(ADC), 안티앨리어싱 필터, 전력 관리 기능을 모두 통합하고 있으며, 특히 24비트 I²S(Inter-IC Sound) 인터페이스를 통해 디지털 오디오 데이터를 출력하는 것이 특징입니다.
참고로, MEMS에 대한 설명은 "가속도계 센서 알아보기"에서 다뤘습니다.
"MEMS(Micro-Electro-Mechanical Systems, 미세 전자기계 시스템)는 초소형 기계 부품과 전자 회로를 하나의 실리콘 칩 위에 집적하는 반도체 제조 기술입니다. 마이크로미터(μm, 100만 분의 1미터) 크기의 초소형 정밀 기계 및 전자 부품을 만들 수 있습니다."
주요 특징 및 사양
INMP441의 주요 특징은 다음과 같습니다:
- 출력 인터페이스: 디지털 I²S 인터페이스를 사용하여 오디오 코덱 없이 DSP나 마이크로컨트롤러와 직접 연결이 가능합니다. (24비트 고정밀 데이터)
- 지향성: 전방향성(Omnidirectional)으로, 모든 방향에서 들어오는 소리를 균일하게 감지합니다.
- 전력 소비: 1.4 mA의 낮은 전류 소비를 가집니다.
- 패키지: 소형 4.72 mm × 3.76 mm × 1 mm 표면 실장 패키지로 제공됩니다.
성능과 관련한 특징은 다음과 같습니다.
- 높은 SNR(Signal-to-Noise Ratio, 신호 대 잡음비): 일반적으로 61 dBA로, 깨끗한 오디오 캡처에 유리합니다.
- 높은 감도: 일반적으로 -26 dBFS입니다.
- 평탄한 주파수 응답: 60 Hz에서 15 kHz 범위에서 안정적인 주파수 응답을 제공하여 자연스럽고 명료한 사운드를 구현합니다.
- 높은 PSR(Power Supply Rejection, 전원 공급 거부율): 일반적으로 -75 dBFS입니다.
주요 용도
INMP441은 높은 성능과 디지털 I²S 인터페이스 덕분에 다음과 같은 다양한 오디오 및 음성 인식 애플리케이션에 적합합니다:
- 화상 회의 시스템 (Teleconferencing Systems)
- 게이밍 콘솔 (Gaming Consoles)
- 모바일 기기 (Mobile Devices), 노트북, 태블릿
- 원격 제어 (Remote Controls)
- 보안 시스템 (Security Systems)
- 음성 비서 및 IoT 장치 (Voice assistants and IoT devices)
구매처
알리 익스프레스: https://ko.aliexpress.com/item/1005007889064664.html (2,700원 정도)

판매 페이지에 나와있는 INMP441 디지털 MEMS 마이크 모듈에 대한 설명은 동일합니다.
- 고성능 MEMS 마이크: 저전력 소비, 전방향성(무지향성) 특성으로 모든 방향의 소리를 균일하게 수신
- 24비트 I²S 디지털 출력: 아날로그-디지털 변환, 앤티앨리어싱 필터 내장으로 별도 오디오 코덱 없이 MCU/DSP 직접 연결 가능
- 높은 SNR과 광대역 주파수 응답: 평탄한 주파수 특성으로 선명하고 자연스러운 음질, 근거리 녹음에 최적
- 초소형 SMD 패키지: 4.72×3.76×1mm 크기로 리플로우 솔더링 가능, 성능 저하 없이 소형화 가능
- 환경 친화적: RoHS 준수, 할로겐 프리로 환경 규제 만족
주 용도: 아두이노/라즈베리파이 음성 인식, 녹음 프로젝트, IoT 스마트 기기, 음향 센싱
성능 지표
SNR (신호 대 잡음비)
SNR (Signal-to-Noise Ratio, 신호 대 잡음비)은 원하는 신호(Signal)의 세기와 원하지 않는 잡음(Noise)의 세기를 비교하여 시스템의 성능이나 데이터의 품질을 정량적으로 나타내는 지표입니다. 통신 시스템, 음향, 이미지 처리 등 다양한 분야에서 신호의 품질을 평가하는 데 사용됩니다.
높은 SNR 값은 신호의 세기가 잡음의 세기보다 훨씬 강하다는 것을 의미하며, 이는 곧 더 선명하고 깨끗하며 신뢰할 수 있는 데이터 또는 오디오 품질을 나타냅니다. (신호 품질이 좋다는 뜻)
SNR은 기본적으로 신호 전력 ()을 잡읍 전력()으로 나눈 비율로 정의합니다.
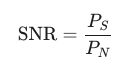
실제 통신 및 측정 분야에서는 비율 자체보다 이 비율을 로그 스케일로 변환한 데시벨 (dB) 단위를 주로 사용합니다. 이는 매우 크거나 작은 전력 비율을 다루기 쉽고, 시스템 구성 요소별 이득/손실을 덧셈/뺄셈으로 처리할 수 있게 하기 때문입니다.
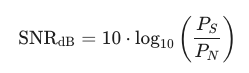
참고로, 신호가 전압(V) 또는 전류(I)로 측정되는 경우, P ∝ V^2 또는 P ∝ I^2 이므로 공식은 다음과 같이 20을 곱하게 됩니다.
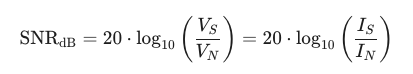
SNR 값의 의미 (예시)
| 비율(SNR = Ps/Pn) | 데시벨(SNR_dB) | 의미 |
|---|---|---|
| 1 | 0 dB | 신호 전력과 잡음 전력이 같음 (Ps = Pn) |
| 10 | 10 dB | 신호 전력이 잡음 전력의 10배 |
| 100 | 20 dB | 신호 전력이 잡음 전력의 100배 |
| 0.1 | -10 dB | 잡음 전력이 신호 전력보다 10배 크다 |
dBA 단위 설명: 일반적인 dB는 물리적인 전력 또는 진폭 비율을 나타내지만, dBA에서 A는 A-가중치(A-weighting)가 적용되었음을 의미합니다.
- 사람의 귀는 주파수(Frequency)에 따라 민감도가 다릅니다. 특히 낮은 주파수와 아주 높은 주파수에는 덜 민감하고, 중간 주파수(약 1kHz ~ 6kHz)에서 가장 민감하게 반응합니다.
- A-가중치는 인간의 청각 특성을 반영하여 측정된 소리 레벨에 주파수별로 보정값(더하거나 빼기)을 적용한 것입니다.
따라서 dBA로 표현된 SNR 값은 인간의 청각 관점에서 마이크의 성능을 평가하는 데 더 유용합니다.
🤔 INMP441의 SNR 61 dBA 는 어느 정도 수준일까요?
INMP441 마이크의 61 dBA SNR은 마이크로폰으로서 매우 우수한 성능을 나타냅니다. 주변 소음이 심하지 않은 환경에서 사람의 목소리나 원하는 소리를 매우 명확하게 녹음할 수 있습니다. 이는 신호와 잡음의 전력 차이가 크기 때문이며, 녹음된 오디오에서 히스 노이즈가 상대적으로 매우 낮게 들립니다.
보급형 또는 저가형 아날로그 마이크의 SNR은 보통 50~55 dBA 수준입니다. 고급형 또는 스튜디오급 콘덴서 마이크는 70 dBA 이상을 자랑하기도 하지만, 일반적인 컨슈머 전자제품에 내장되는 디지털 마이크로폰 중 61 dBA는 고성능 축에 속합니다.
dBFS
dBFS (decibels relative to Full Scale) - 디지털 신호의 최대값 대비 상대적 크기
디지털 시스템에서 가능한 가장 큰 소리 레벨을 0 dBFS 로 정의하고, 이보다 작은 소리는 음수 값으로 나타냅니다. 소리가 이 기준 (0 dBFS)를 넘어서면 신호가 왜곡되는 클리핑이 발생할 수 있으므로, 녹음 및 편집 시 소리 크기를 조절하는 데 사용됩니다.
- 0에 가까울수록 감도 높음: 작은 소리도 큰 디지털 신호로 변환되어 잘 잡히지만, 큰 소리에서 클리핑 위험이 있습니다.
- 0에서 멀수록 헤드룸 큼: 감도가 낮아 작은 소리가 약하게 녹음되지만, 큰 소리까지 왜곡 없이 처리할 여유(헤드룸)가 많습니다.
용도별 선택: 조용한 환경에서 미세한 소리 녹음은 높은 감도(-26 dBFS)가 좋고, 시끄러운 환경이나 음악 녹음은 낮은 감도(-38 dBFS)로 헤드룸을 확보하는 게 유리합니다.
🤔 INMP441의 "-26 dBFS" 감도는 어느 정도 수준일까요?
"-26 dBFS" 감도라는 뜻은 표준 음압(94 dB SPL, 보통 대화 소리) 입력 시 디지털 출력이 최대치보다 26dB 낮다는 뜻입니다. 마이크 출력이 최대값의 약 5% 수준이며, 매우 우수한 감도에 속합니다 (일반 MEMS 마이크는 -38~-42 dBFS).
작은 소리도 잘 잡고, 큰 소리에도 클리핑 여유가 있어 음성 인식, 녹음 품질이 좋다는 뜻입니다.
PSR
PSR (Power Supply Rejection) - 전원 공급 거부율
PSR은 전원 공급 장치의 잡음이나 변동이 최종 출력 신호에 미치는 영향을 얼마나 잘 억제하는지를 나타내는 지표입니다. 이 값이 높을수록 전원 공급 변동의 영향을 덜 받는다는 뜻입니다.
"-75 dBFS"와 같이 dBFS가 붙는 경우, 이는 전원 공급 장치에서 발생하는 잡음이 마이크의 출력 신호에 최대치 (0 dBFS)보다 75 dB 낮은 레벨로 영향을 미친다는 것을 뜻하며, 매우 미미한 수준임을 나타냅니다.
INMP441 작동 원리
INMP441은 MEMS 센서와 통합 신호 처리 회로(ASIC)가 결합되어 소리를 디지털 I²S 신호로 변환하여 출력하는 방식으로 작동합니다.
이 보드들에 있는 실제 마이크는 작은 표면 실장 장치(SMD)로 패키징되어 있으며, 소리가 들어갈 수 있도록 위나 아래에 구멍이 있습니다. 작동 원리는 공기압에 따라 값이 변하는 커패시터를 사용하는 일렉트릿 콘덴서 마이크(ECM)와 유사합니다.
💻 이미지 출처: ESP32 Audio Input Showdown: INMP441 vs SPH0645 MEMS I2S Microphones! - atomic14
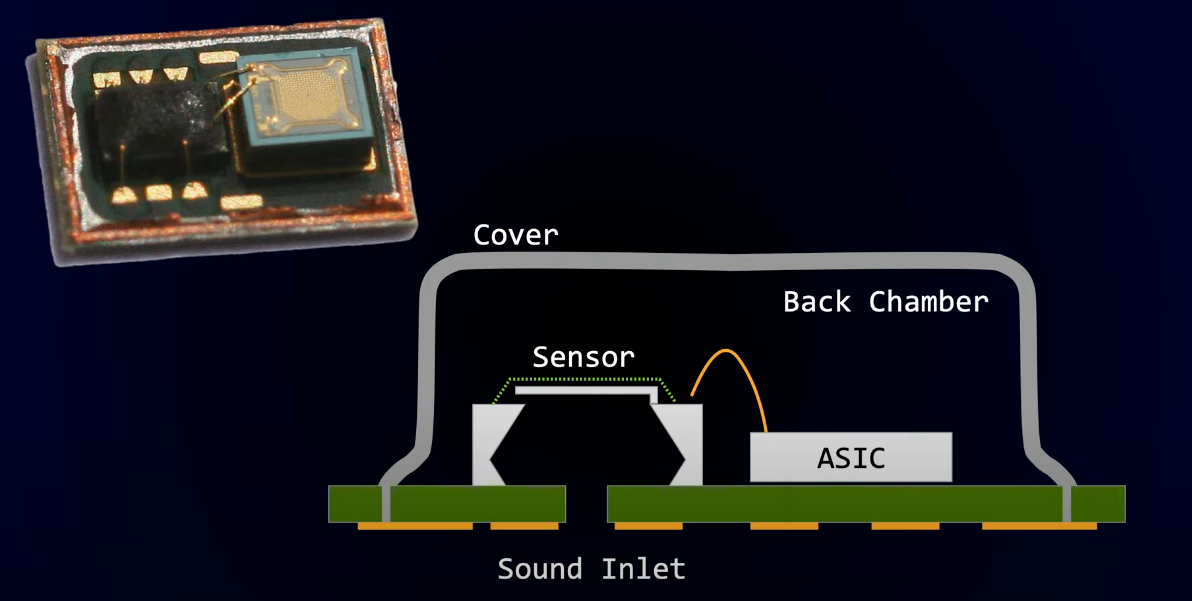
작동 원리는 크게 음향-전기 변환 (MEMS 센서), 신호 컨디셔닝 및 필터링, 그리고 아날로그-디지털 변환 및 I²S 출력의 3단계로 나눌 수 있습니다.
#1. 음향-전기 변환 (MEMS 센서)
INMP441 작동의 핵심은 MEMS(Micro-Electro-Mechanical Systems) 마이크로폰 센서입니다.
MEMS 마이크로폰은 일반적으로 진동판(Diaphragm)과 후판부(Back Plate)가 서로 마주 보고 있는 가변 콘덴서(Capacitor) 구조를 가집니다. 이 두 전극 사이에는 전압이 걸려 있습니다.
💻 이미지 출처: HOLLYLAND > How Does a Condenser Microphone Work?
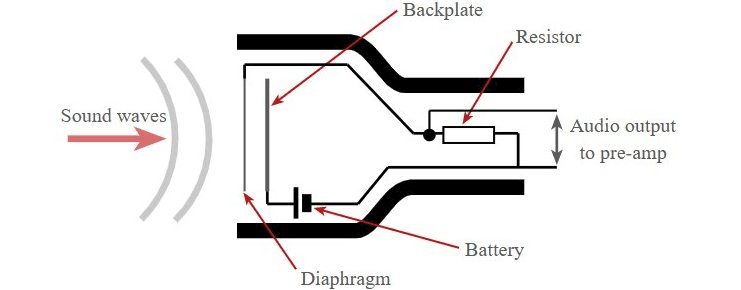
- 외부에서 소리(음파)가 유입되면, 소리의 압력 변화에 따라 진동판이 미세하게 진동합니다.
- 진동판이 진동하면서 고정된 후판부 전극과의 거리가 변화하게 됩니다.
- 두 전극 사이의 거리가 변하면 정전용량(Capacitance, C)이 변화합니다.
- 이 정전용량의 변화는 소리의 진동 패턴을 그대로 반영하는 아날로그 전기 신호로 변환됩니다.
#2. 신호 컨디셔닝 및 필터링 (ASIC)
MEMS 센서에서 생성된 미세한 아날로그 전기 신호는 INMP441 칩 내부의 ASIC(Application-Specific Integrated Circuit)으로 입력됩니다.
ASIC은 입력된 약한 아날로그 신호를 잡음 없이 증폭하는 프리앰프(Pre-Amplifier) 및 신호 구성 조정 회로를 포함합니다. 이후 신호가 ADC로 들어가기 전에 안티앨리어싱 필터를 거쳐 고주파 잡음을 제거하고 샘플링 시 발생할 수 있는 앨리어싱(Aliasing) 현상을 방지합니다.
#3. ADC 및 디지털 I²S 출력
신호 처리의 마지막 단계는 아날로그 신호를 마이크로컨트롤러나 DSP가 이해할 수 있는 디지털 신호로 변환하는 것입니다. 컨디셔닝된 아날로그 신호는 높은 정밀도(High-Precision)의 ADC를 통해 연속적인 디지털 데이터로 변환됩니다. INMP441은 높은 SNR(61 dBA)을 제공하는 것이 특징입니다.
INMP441은 변환된 디지털 데이터를 24비트 I²S(Inter-IC Sound) 형식으로 출력합니다. 이 디지털 데이터는 SCK (Serial Clock), WS (Word Select), SD (Serial Data) 세 개의 핀을 통해 호스트 프로세서(예: ESP32)로 전송됩니다. I²S 인터페이스를 사용하면 시스템에서 별도의 오디오 코덱이 필요 없이 마이크로컨트롤러와 직접 연결하여 고품질 디지털 오디오를 얻을 수 있습니다.
✍️ 요약하자면, INMP441은 소리를 MEMS 센서로 감지하여 정전용량 변화를 만들고, 이 아날로그 신호를 내부 ASIC에서 증폭 및 필터링한 후, ADC를 통해 디지털 I²S 신호로 변환하여 출력하는 일체형 디지털 마이크로폰 입니다.
ECM (Electret Condenser Microphone) 비교
💻 참고: Digikey > MEMS와 ECM: 마이크 기술 비교
마이크 구성에 가장 널리 사용되는 기술 중 두 가지는 초소형 전자 기계 시스템(MEMS) 마이크와 일렉트릿 콘덴서 마이크(ECM) 입니다. Electret Condenser 마이크(ECM)와 INMP441 Digital MEMS 마이크는 소리를 캡처하는 방식은 유사하지만, 출력 방식과 신호 품질 측면에서 근본적인 차이가 있습니다.
| 특징 | Electret Condenser 마이크 (ECM) | INMP441 Digital MEMS 마이크 |
|---|---|---|
| 출력 방식 | 아날로그 (Analog) 전압 신호 | 디지털 (Digital) I²S 신호 |
| 내부 회로 | 마이크 캡슐 + FET(임피던스 변환용) | MEMS 캡슐 + ADC, DSP (집적 회로) |
| 필요한 외부 회로 | ADC (디지털 변환 시) | 없음 (디지털 신호이므로) |
| 잡음 민감도 | 높음 (아날로그 신호는 노이즈에 취약) | 낮음 (디지털 신호는 노이즈에 강함) |
| SNR (신호 대 잡음비) | 상대적으로 낮음 (보통 50 ~ 60 dB) | 높음 (INMP441은 61 dBA) |
ECM은 정전용량(Capacitance)의 변화를 이용해 소리를 전기 신호로 바꾸는 방식은 콘덴서 마이크와 동일합니다.
- 원리: 진동판과 고정 전극 사이에 영구적으로 전하가 저장된 엘렉트릿 재료를 사용합니다. 소리가 진동판을 움직이면 이 간격이 변하고, 정전용량 변화가 전압 변화로 이어집니다.
- FET의 역할: ECM의 출력 임피던스는 매우 높기 때문에, 내부에 FET(Field-Effect Transistor)이 필수적으로 내장됩니다. 이 FET은 높은 임피던스 신호를 낮은 임피던스의 사용 가능한 아날로그 전압 신호로 변환(버퍼링)해주는 역할만 합니다.
- 단점: 최종적으로 나오는 신호가 아날로그 전압이기 때문에 ESP32나 아두이노에 연결하려면 마이크로컨트롤러의 ADC를 사용하거나 별도의 고성능 ADC 칩을 거쳐야 합니다. 이 과정에서 전원 노이즈나 긴 배선 노이즈가 쉽게 유입되어 신호 품질이 떨어집니다.
💻 이미지 출처: ESP32 Audio Input Showdown: INMP441 vs SPH0645 MEMS I2S Microphones! - atomic14
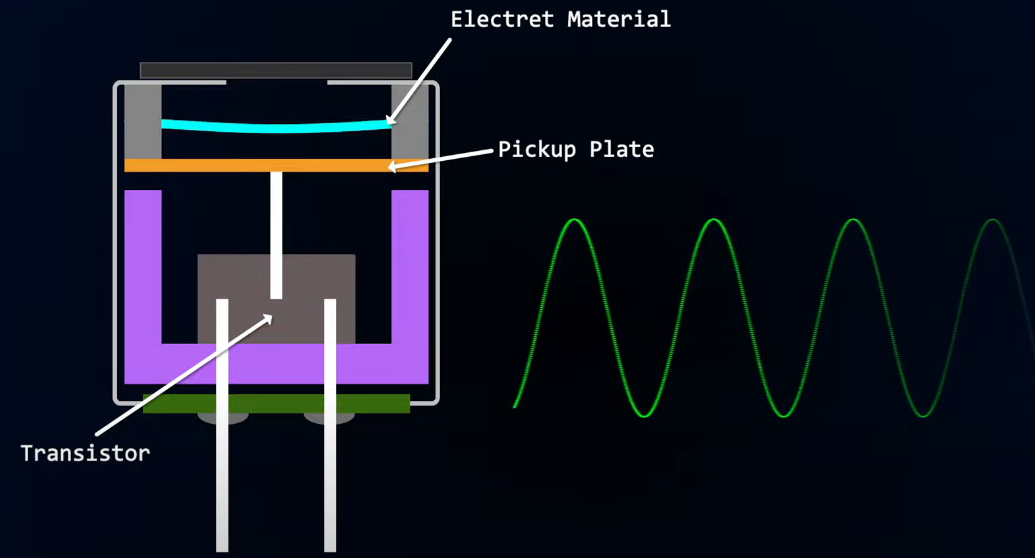
MAX4466와 MAX9814는 모두 일렉트릿 콘덴서(Electret Condenser) 마이크를 사용합니다. 이 보드들은 아날로그 신호를 출력하며, 이 신호는 ESP32의 아날로그-디지털 변환기(ADC)로 입력되어야 합니다.
ECM 이랑 MEMS 마이크는 기본 원리는 유사합니다. 둘 다 진동판과 고정판 사이의 정전용량 변화로 소리를 감지하는 콘덴서 마이크 원리 입니다. 다만 제조 방식이 핵심 차이인 거죠.
다양한 마이크로폰 제품
INMP441 외에도 다양한 종류의 마이크로폰 모듈 및 센서가 있으며, 특히 마이크로컨트롤러(ESP32, Arduino 등)와 연결하여 사용하는 용도에서는 INMP441과 유사하거나 더 최신인 디지털 MEMS 마이크로폰과 아날로그 마이크로폰이 주로 사용됩니다.
디지털 마이크로폰
디지털 마이크로폰은 아날로그 마이크에 비해 SNR이 훨씬 높습니다. (60 dBA 이상). 또한, 마이크 센서 내부에 ADC(아날로그-디지털 변환기)가 통합되어 있어, 마이크로컨트롤러의 ADC를 사용할 필요 없이 I²S 포트에 직접 연결하여 노이즈에 강한 디지털 데이터를 얻을 수 있습니다.
참고로 INMP441은 구형 모델이고, ICS-43434는 후속 모델입니다. I2S 인터페이스, 65dB SNR로 INMP441보다 성능 향상, 더 낮은 소비 전력이 특징입니다. 다른 제품군으로는 SPH0645 이 있습니다.
PDM 디지털 마이크
PDM (Pulse Density Modulation) 디지털 마이크는 I²S와 유사하게 디지털 출력을 제공하지만, 데이터는 단일 핀(DATA)으로 출력되고 CLK 핀으로 동기화됩니다. I²S보다 핀 수가 하나 적어 배선이 간단합니다.
시그마-델타 ADC를 사용하여 펄스 밀도 변조된 신호를 출력하며, 호스트 컨트롤러(ESP32 등)가 이를 소프트웨어적으로 복조해야 합니다.
I²S와 PDM은 모두 고품질 디지털 오디오를 제공하지만, I²S는 전용 핀이 많아 복잡하지만 호스트에서 처리가 단순하고, PDM은 핀이 적지만 호스트에 복조 부하가 걸립니다.
아날로그 MEMS / ECM
센서 자체에서 아날로그 신호(전압)가 출력됩니다. 이 아날로그 신호를 마이크로컨트롤러의 ADC 핀에 연결하여 디지털로 변환해야 합니다. 대표적으로 MAX4466, MAX9814가 있습니다.
마이크로컨트롤러의 내장 ADC 품질이 낮아 오디오 품질(SNR)이 떨어질 수 있습니다. 아날로그 신호이므로 전원 노이즈나 긴 배선으로 인한 잡음에 매우 취약합니다. 음성 감지(Detection)나 대략적인 소리 레벨 측정 등 높은 음질이 필요 없는 간단한 프로젝트에서 사용됩니다.
실습 해보기
하드웨어 연결
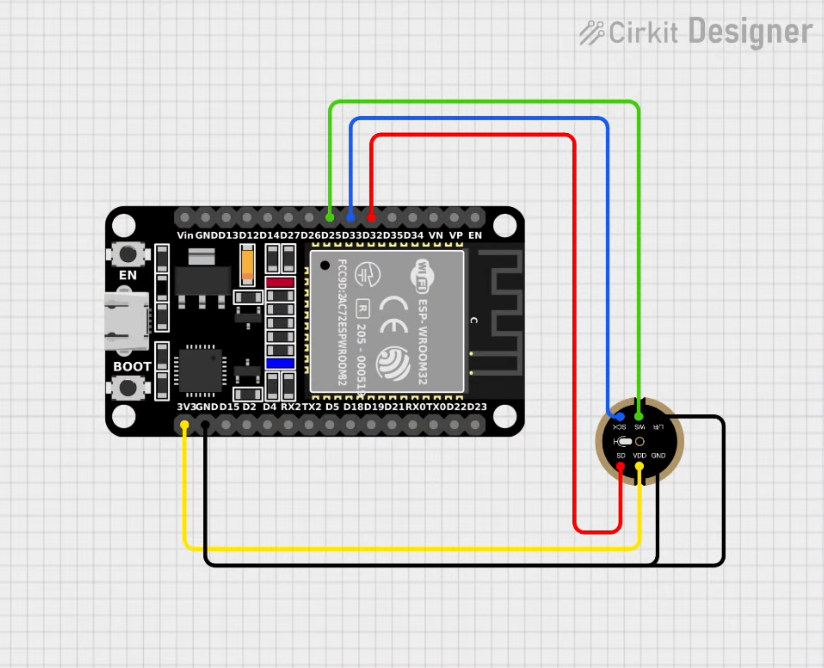
ESP32 보드와 INMP441 디지털 MEMS 마이크로폰 모듈을 연결하는 방법은 비교적 간단합니다. 두 장치 모두 I²S(Inter-IC Sound) 통신 프로토콜을 사용하기 때문에, 해당하는 핀들을 서로 연결해 주기만 하면 됩니다.
INMP441 모듈에는 총 6개의 핀이 있으며, 이들을 ESP32의 특정 GPIO 핀에 연결해야 합니다.
| INMP441 핀 이름 | 기능 | ESP32 핀 번호 (예시) |
|---|---|---|
| VDD | 전원 입력 | 3.3V |
| GND | 접지 | GND |
| SCK/BCLK | 비트 클록 (Bit Clock) - I2S SCK | GPIO 14 |
| WS | 워드 선택 (Word Select) - I2S WS | GPIO 15 |
| SD | 직렬 데이터 출력 (Data) - I2S DATA_IN | GPIO 32 |
| L/R | 채널 선택 - GND(Left) or VDD(Right) | GND (Mono/Left 채널 설정) |
I2S 에 대해서는 Audio 실험실 #1 을 참고해 주시면 될 거 같습니다.
INMP441은 스테레오(좌우 채널) 기능을 지원하지만, ESP32로 하나의 마이크를 사용할 때는 일반적으로 모노 채널로 설정하면 됩니다.
- L/R 핀을 GND에 연결: 마이크를 Left Channel (왼쪽 채널)로 설정하여 데이터를 출력합니다. (가장 일반적인 설정)
- L/R 핀을 VDD에 연결하거나 플로팅 (Floating): 마이크를 Right Channel (오른쪽 채널)로 설정하여 데이터를 출력합니다.
테스트 코드 작성 (ESP-IDF)
ESP32 IDF(IoT Development Framework) 환경에서 INMP441 마이크로폰 모듈을 테스트하기 위한 기본 예제 코드입니다. 이 코드는 I²S 드라이버를 초기화하고, 마이크로부터 24비트 디지털 오디오 데이터를 읽어 들여 시리얼 모니터로 출력하는 기능을 수행합니다.
#1. 기본 정의
#include <stdio.h>
#include <string.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "driver/i2s.h"
#include "driver/gpio.h"
#include "esp_log.h"
// --- INMP441 핀 설정 (하드웨어 연결에 맞게 수정하세요) ---
#define I2S_WS_PIN GPIO_NUM_15 // Word Select (WS)
#define I2S_SCK_PIN GPIO_NUM_14 // Serial Clock (SCK / BCLK)
#define I2S_SD_PIN GPIO_NUM_32 // Serial Data (SD / DATA_IN)
#define I2S_PORT I2S_NUM_0 // 사용할 I2S 포트 (일반적으로 0)
// --- I2S 설정 ---
#define SAMPLE_RATE 16000
#define SAMPLE_BITS I2S_BITS_PER_SAMPLE_32BIT
#define DMA_BUFFER_COUNT 4
#define DMA_BUFFER_SIZE 1024
static const char *TAG = "INMP441_TEST":📌 샘플 레이트(샘플링 속도)는 아날로그 소리를 디지털 신호로 변환할 때 초당 몇 번의 '샘플'(표본, 데이터 조각)을 추출하는지를 나타내는 수치입니다. 샘플레이트가 높을수록 더 많은 정보를 캡처하여 오디오 품질이 향상되지만, 데이터 용량도 커집니다.
CD 음질에 해당하는 44.1kHz는 일반적으로 고품질 오디오를 재생하는 데 사용되지만 여기서는 16kHz (16000)으로 낮췄습니다. 너무 빠르면 보기 힘들어...
📌 샘플 비트 수는 하나의 오디오 샘플을 표현하는 데 사용되는 비트 수를 결정합니다. 이 값이 높을수록 각 샘플이 더 많은 단계의 진폭 값을 표현할 수 있어, 소리의 미세한 변화를 더 정확하게 기록하여 음질을 향상시키고 원본 아날로그 신호의 정밀도를 높입니다.
INMP441는 24bit 를 내보내지만 ESP32는 내부적으로 24bit를 32bit(4 byte) 슬롯에 채워서 처리합니다. ESP32의 I²S 드라이버가 32bit 형태로 메모리(DMA)에 저장한다는 뜻.
INMP441의 24비트 데이터는 32비트 정수 내에서 상위 24비트에 정렬됩니다 (I²S 표준). 따라서 하위 8비트는 사용되지 않거나 '0'으로 채워집니다.
I2S SAMPLE_BITS를 24bit로 해야하나 32bit로 해야하나... 사실 별로 상관은 없을거 같긴 합니다. 어차피 DMA 버퍼에 저장되는 건 32bit로 똑같을 거 같습니다.
📌 DMA 버퍼는 여기서는 "1024 샘플 x 4 버퍼" 로 처리하도록 합니다. 샘플 하나당 4btye니까 1024 샘플 × 4 버퍼 × 4 바이트 = 16,384 바이트 = 16 KB 를 사용하겠네요.
16kHz, 32bit 오디오 데이터 기준으로 하면 16,384 바이트 ÷ (16,000 샘플/초 × 4 바이트) = 0.256초 = 약 256ms (1/4초) 저장 가능하겠네요.
버퍼 4개를 사용하니까 원형 버퍼(Circular Buffer) 방식으로 버퍼 1 → 버퍼 2 → 버퍼 3 → 버퍼 4 순으로 DMA가 자동으로 채운 후 다시 버퍼 1로 돌아가 반복됩니다. 각 버퍼가 가득 차면 인터럽트가 발생하여 CPU는 이전 버퍼의 데이터를 처리하는 동안 DMA는 다음 버퍼를 채웁니다.
이렇게 여러 버퍼를 사용하면 CPU가 한 버퍼를 처리하는 시간 동안 DMA가 다른 버퍼를 채울 수 있어 데이터 손실을 방지할 수 있습니다.
#2. I2S 드라이버 초기화 함수
/**
* @brief I2S 드라이버 초기화 함수
*/
static void i2s_init() {
i2s_config_t i2s_config = {
.mode = I2S_MODE_MASTER | I2S_MODE_RX, // ESP32는 마스터, 마이크는 슬레이브로 설정, 수신 모드
.sample_rate = SAMPLE_RATE,
.bits_per_sample = SAMPLE_BITS,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT, // 모노 (왼쪽 채널만)
.communication_format = I2S_COMM_FORMAT_STAND_I2S,
.intr_alloc_flags = 0, // 기본 인터럽트 플래그
.dma_buf_count = DMA_BUFFER_COUNT,
.dma_buf_len = DMA_BUFFER_SIZE,
.use_apll = false, // APLL 사용 안 함
.tx_desc_auto_clear = false,
.fixed_mclk = 0
};
i2s_pin_config_t pin_config = {
.bclk = I2S_SCK_PIN,
.ws = I2S_WS_PIN,
.data_in = I2S_SD_PIN,
.data_out = I2S_PIN_NO_CHANGE // TX(출력) 사용 안 함
};
// I2S 드라이버 설치
ESP_ERROR_CHECK(i2s_driver_install(I2S_PORT, &i2s_config, 0, NULL));
// I2S 핀 설정
ESP_ERROR_CHECK(i2s_set_pin(I2S_PORT, &pin_config));
ESP_LOGI(TAG, "I2S 초기화 완료");
}- mode: 마스터(Master) 모드로 설정하여 ESP32가 클록 신호(SCK, WS)를 생성하고, 수신(RX) 모드로 설정하여 데이터를 INMP441로부터 받도록 합니다.
- bits_per_sample: 마이크 출력이 32비트임을 명시합니다.
- channel_format: INMP441의 L/R 핀이 GND에 연결되어 왼쪽 채널로 데이터가 들어온다고 가정하고 설정합니다.
- communication_format: 표준 I²S 프로토콜을 사용하도록 설정합니다.
- dma_buf_count, dma_buf_len: DMA(Direct Memory Access) 버퍼 설정입니다. CPU 개입 없이 효율적으로 데이터를 전송하기 위한 메모리 공간을 설정합니다.
- i2s_driver_install: I²S 드라이버를 메모리에 설치하고 초기화합니다.
- i2s_set_pin: 위에 정의한 BCLK, WS, DATA_IN 핀을 I²S 포트에 할당합니다.
#3. I2S 데이터 읽기 및 출력 태스크
static void i2s_read_task(void *arg) {
// 데이터 버퍼
// 버퍼 크기(바이트) = DMA_BUFFER_SIZE * 4 (24비트는 3바이트지만, ESP32는 32비트 단위로 전송)
const int buffer_size = DMA_BUFFER_SIZE;
int32_t *i2s_read_buffer = (int32_t *)malloc(buffer_size * sizeof(int32_t));
size_t bytes_read = 0;
ESP_LOGI(TAG, "오디오 녹음 시작...");
while (1) {
// I2S 포트에서 데이터 읽기 - 버퍼 1개를 통으로 읽는 거
esp_err_t err = i2s_read(I2S_PORT, i2s_read_buffer, buffer_size * sizeof(int32_t),
&bytes_read, portMAX_DELAY);
if (err != ESP_OK) {
ESP_LOGI(TAG, "I2S 읽기 실패: %s", esp_erro_to_name(err));
continue;
}
if (bytes_read > 0) {
// 읽은 바이트 수를 32비트 샘플 수로 변환 (4바이트 = 1 샘플)
int num_samples = bytes_read / sizeof(int32_t);
// --- 데이터 처리 및 출력 ---
// 여기서는 첫 10개의 32비트 샘플만 출력하여 데이터 수신을 확인합니다.
// 실제 오디오 처리를 위해서는 FFT, RMS 계산 등을 수행해야 합니다.
printf("Read %d bytes (%d samples).\n", bytes_read, num_samples);
for (int i = 0; i < 10; i++) {
// INMP441의 24비트 데이터는 32비트 정수의 상위 24비트에 정렬됩니다.
int32_t sample = i2s_read_buffer[i] >> 8;
printf("Sample %d: %ld\n", i, sample);
}
printf("...\n");
} else {
printf("I2S Read Timeout or Error.\n");
}
vTaskDelay(pdMS_TO_TICKS(1000)); // 1초 간격으로 출력
}
}- i2s_read(...): I²S 드라이버 함수를 호출하여 버퍼 크기만큼의 오디오 데이터를 읽습니다. 데이터가 도착할 때까지 대기(portMAX_DELAY)합니다.
- if (bytes_read > 0): 데이터를 성공적으로 읽었는지 확인합니다.
- int num_samples = bytes_read / sizeof(int32_t); : 읽은 바이트 수를 32비트(4바이트)로 나누어 실제 샘플 수를 계산합니다.
- for (int i = 0; i < 10; i++): 디버깅 목적으로, 수신된 32비트 샘플 중 처음 10개를 정수형(%ld)으로 출력합니다. 이 값이 크게 변할수록 소리가 크다는 것을 의미합니다.
#4. 메인 애플리케이션 함수
FreeRTOS 태스크로 실행되며, I²S 포트를 통해 마이크 데이터를 연속적으로 읽어와 처리하는 핵심 루틴입니다.
void app_main(void) {
// 1. I2S 초기화
i2s_init();
// 2. I2S 읽기 태스크 생성
xTaskCreate(i2s_read_task, "i2s_read_task", 4096, NULL, 5, NULL);
}ESP32 애플리케이션의 시작점입니다. i2s_init()을 호출하여 하드웨어를 준비하고, xTaskCreate()를 통해 데이터를 읽는 i2s_read_task를 시작합니다.
실행 결과 분석
DMA 1개 = 1024 × 4 bytes = 4096 bytes 이고, 샘플은 처음 10개만 출력되고 있습니다.
Read 4096 bytes (1024 samples).
Sample 0: 639
Sample 1: 116
Sample 2: 47
Sample 3: 195
Sample 4: 395
Sample 5: 50
Sample 6: -681
Sample 7: 199
Sample 8: 846
Sample 9: 1046
...
Read 4096 bytes (1024 samples).
Sample 0: -5529
Sample 1: -4798
Sample 2: -4698
Sample 3: -4660
Sample 4: -5663
Sample 5: -6286
Sample 6: -5707
Sample 7: -6057
Sample 8: -6145
Sample 9: -6062
...만약에 입력된 소리가 1초인 경우를 보겠습니다. 마이크에서 출력되는 데이터의 개수는 샘플링 속도(Sample Rate)와 채널 수에 의해 결정됩니다. 만약에 44.1kHz, 1 (모노) 인 경우를 볼까요?

1초당 샘플 개수는 44,100개 입니다. 그리고 데이터 크기 (비트레이트)가 24bit 라면... 1초당 전송되는 총 데이터량 (Bitrate)은 다음과 같이 계산됩니다.

DMA 버퍼, DMA_BUFFER_SIZE는 1024 샘플이었습니다. 32비트 정수(int32_t)의 형태로 메모리에 저장하여 처리합니다. 이러한 DMA 버퍼를 약 44100 / 1024 = 대략 43.07회/초 를 읽으면 1초간의 오디오 데이터를 읽어오게 되겠네요. (오우...)
저 값의 의미를 좀 보겠습니다. 32bit 이지만 실제로는 24bit 일 것이고요. 이 정수 값 자체는 소리의 진폭(amplitude)을 나타냅니다. 이론적으로는 최댓값: +8,388,607, 최솟값: −8,388,608 (= ±2²³ − 1) 이겠네요.
정상적인 환경에서 마이크는 주변 소리 세기에 따라 값이 변합니다.
- 조용한 방: 약 -5000 ~ +5000
- 외부 말소리(보통 말하기 음량, 20~30cm 거리): 약 -200k ~ +200k
- 크게 말함 / 손뼉 / 책상 두드림: -500k ~ +500k
- 아주 큰 소리(바로 옆에서 큰 박수/소음): 최대 ±1M 정도
🤔 음. 근데 왜 마이너스 값이 나오는걸까요?
INMP441은 I2S로 24비트 부호 있는(signed) PCM 데이터를 출력하므로, 소리의 양의 압력과 음의 압력을 각각 양수/음수로 표현합니다. 아날로그 마이크와 달리 디지털 마이크는 중심값이 0이며, 소리의 진동은 0을 중심으로 +/-로 진동합니다. 무음 상태일 때 0 근처의 작은 양수/음수가 나옵니다.
마이너스 값이 나오는 것은 정상이며, 진폭(절댓값)을 보거나 RMS, FFT 등으로 분석해야 실제 소리 크기를 알 수 있습니다. 부호는 파형의 위상 정보입니다.
파이썬 실시간 그래프 분석
위와 같이 값은 제대로 확인이 되는데, 일단 1초마다 10개씩 출력하기 때문에 실시간 느낌은 없고요. 출력 데이터로 확인하니까 시각적으로 보기 어렵다는 단점이 있습니다. 그래서 그래프로 확인하고 싶은데 Python을 이용하면 가능합니다.
Python (Matplotlib 또는 PyQtGraph): Python은 데이터 시각화에 가장 강력하고 유연한 도구를 제공합니다.
- ESP32가 I2S로 PCM 샘플을 읽음
- UART로 PC에 샘플을 전송
- PC에서 파이썬으로 받아서 matplotlib로 그래프 그리기
i2s_read_task 함수를 다음과 같이 수정합니다:
static void i2s_read_task(void *arg) {
// 데이터 버퍼
// 버퍼 크기(바이트) = DMA_BUFFER_SIZE * 4 (24비트는 3바이트지만, ESP32는 32비트 단위로 전송)
const int buffer_size = DMA_BUFFER_SIZE;
int32_t *i2s_read_buffer = (int32_t *)malloc(buffer_size * sizeof(int32_t));
size_t bytes_read = 0;
ESP_LOGI(TAG, "오디오 녹음 시작...");
while (1) {
// I2S 포트에서 데이터 읽기 - 버퍼 1개를 통으로 읽는 거
esp_err_t err = i2s_read(I2S_PORT, i2s_read_buffer, buffer_size * sizeof(int32_t),
&bytes_read, portMAX_DELAY);
if (err != ESP_OK) {
ESP_LOGI(TAG, "I2S 읽기 실패: %s", esp_erro_to_name(err));
continue;
}
if (bytes_read > 0) {
// 읽은 바이트 수를 32비트 샘플 수로 변환 (4바이트 = 1 샘플)
int num_samples = bytes_read / sizeof(int32_t);
int64_t sum = 0;
for (int i = 0; i < num_samples; i++) {
// INMP441의 24비트 데이터는 32비트 정수의 상위 24비트에 정렬됩니다.
int32_t sample = i2s_read_buffer[i] >> 8;
sum += abs(sample);
}
int32_t average_amplitude = sum / num_samples;
printf("%ld\n", average_amplitude);
} else {
printf("I2S Read Timeout or Error.\n");
}
vTaskDelay(pdMS_TO_TICKS(1));
}
}참고로, 처음에는 모든 샘플 데이터를 출력하려고 했더니 파이썬 matplotlib 가 따라가질 못하더라고요. 그래서 버퍼 1개 (1024 샘플)을 평균으로 내서 출력하는 방식으로 바꿨습니다.
파이썬 코드 참고 - PC에 pyserial과 matplotlib 라이브러리가 설치되어 있어야 합니다.
import serial
import matplotlib.pyplot as plt
import numpy as np
import time
# --- 설정 (ESP32 환경에 맞게 수정) ---
# 1. ESP32가 연결된 시리얼 포트 이름 (Windows: 'COMx', Linux/Mac: '/dev/ttyUSBx' 등)
SERIAL_PORT = 'COM4'
# 2. ESP32에서 설정한 시리얼 통신 속도 (보통 115200)
BAUD_RATE = 115200
# 3. 그래프에 표시할 샘플 개수 (윈도우 크기)
WINDOW_SIZE = 512
# 시리얼 포트 초기화
try:
ser = serial.Serial(SERIAL_PORT, BAUD_RATE)
print(f"Connected to {SERIAL_PORT} at {BAUD_RATE} band.")
except serial.SerialException as e:
print(f"Error connecting to serial port: {e}")
exit()
# 그래프 설정
plt.ion() # 대화형 모드 켜기 ??
fig, ax = plt.subplots()
# 초기 데이터 버퍼 (모두 0으로 초기화)
data = np.zeros(WINDOW_SIZE, dtype=np.int32)
line, = ax.plot(data)
ax.set_ylim(0, 100000) # y축 범위 설정 (INMP441 24비트 데이터 값에 맞게 조정)
ax.set_xlabel("Sample Index")
ax.set_ylabel("Amplitude")
print("Visualization started. Speak into the microphone!")
def update_plot(new_sample):
"""새로운 샘플을 버퍼에 추가하고 그래프를 업데이트 함"""
global data
# 기존 데이터를 한 칸씩 왼쪽으로 밀고, 가장 오른쪽에 새 데이터를 추가
data = np.roll(data, -1)
data[-1] = new_sample
line.set_ydata(data)
ax.relim()
ax.autoscale_view()
fig.canvas.draw()
fig.canvas.flush_events()
try:
while True:
if ser.in_waiting > 0:
# 시리얼 버퍼에서 한 줄(샘플 값)을 읽음
s_line = ser.readline().decode('utf-8').strip()
try:
# 읽은 문자열을 정수(샘플 값)로 변환함
sample_value = int(s_line)
# 그래프 업데이트 함수 호출
update_plot(sample_value)
except ValueError:
# 숫자가 아닌 데이터가 들어온 경우 무시
pass
# CPU 사용량을 줄이기 위해 잠시 대기
# time.sleep(0.001)
except KeyboardInterrupt:
print("\nStopping visualization...")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 종료 시 시리얼 포트를 닫고 그래프 창을 닫음
if 'ser' in locals() and ser.is_open:
ser.close()
plt.close()결과는 다음과 같습니다. 실제로 잘 반응합니다.
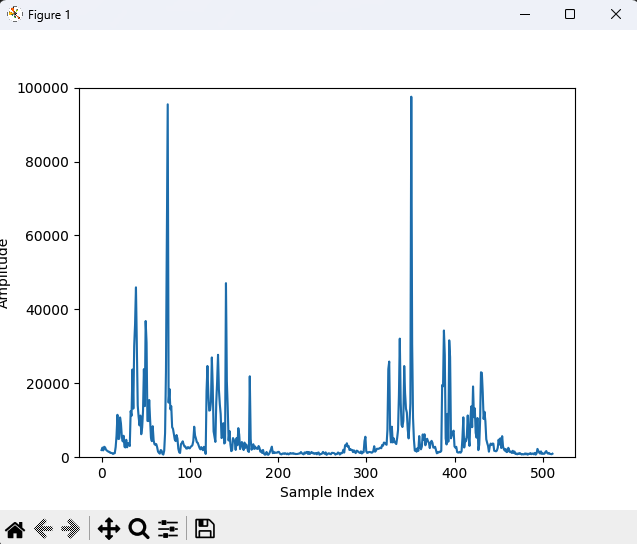
지금은 시간에 따라 신호의 파형 자체가 어떻게 변하는지를 간단하게 보여준 것이고요. 실제로 오디오 데이터 분석을 위해서는 주파수 영역 분석이 필요합니다. 이에 대해서는 나중에 다뤄보도록 하겠습니다.
참고 자료
