문제 설명
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
세로길이가 n 가로길이가 m인 격자 모양의 땅 속에서 석유가 발견되었습니다. 석유는 여러 덩어리로 나누어 묻혀있습니다. 당신이 시추관을 수직으로 단 하나만 뚫을 수 있을 때, 가장 많은 석유를 뽑을 수 있는 시추관의 위치를 찾으려고 합니다. 시추관은 열 하나를 관통하는 형태여야 하며, 열과 열 사이에 시추관을 뚫을 수 없습니다.
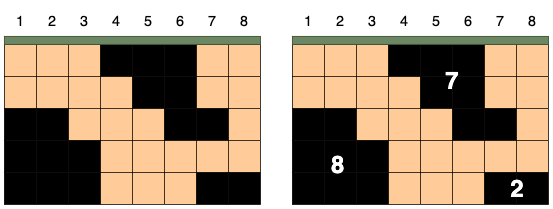
예를 들어 가로가 8, 세로가 5인 격자 모양의 땅 속에 위 그림처럼 석유가 발견되었다고 가정하겠습니다. 상, 하, 좌, 우로 연결된 석유는 하나의 덩어리이며, 석유 덩어리의 크기는 덩어리에 포함된 칸의 수입니다. 그림에서 석유 덩어리의 크기는 왼쪽부터 8, 7, 2입니다.
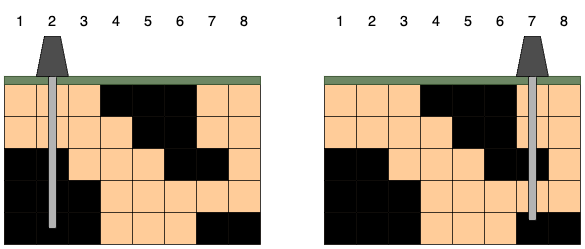
시추관은 위 그림처럼 설치한 위치 아래로 끝까지 뻗어나갑니다. 만약 시추관이 석유 덩어리의 일부를 지나면 해당 덩어리에 속한 모든 석유를 뽑을 수 있습니다. 시추관이 뽑을 수 있는 석유량은 시추관이 지나는 석유 덩어리들의 크기를 모두 합한 값입니다. 시추관을 설치한 위치에 따라 뽑을 수 있는 석유량은 다음과 같습니다.
| 시추관의 위치 | 획득한 덩어리 | 총 석유량 |
|---|---|---|
| 1 | [8] | 8 |
| 2 | [8] | 8 |
| 3 | [8] | 8 |
| 4 | [7] | 7 |
| 5 | [7] | 7 |
| 6 | [7] | 7 |
| 7 | [7, 2] | 9 |
| 8 | [2] | 2 |
오른쪽 그림처럼 7번 열에 시추관을 설치하면 크기가 7, 2인 덩어리의 석유를 얻어 뽑을 수 있는 석유량이 9로 가장 많습니다.
석유가 묻힌 땅과 석유 덩어리를 나타내는 2차원 정수 배열 land가 매개변수로 주어집니다. 이때 시추관 하나를 설치해 뽑을 수 있는 가장 많은 석유량을 return 하도록 solution 함수를 완성해 주세요.
제한사항
- 1 ≤ land의 길이 = 땅의 세로길이 = n ≤ 500
- 1 ≤ land[i]의 길이 = 땅의 가로길이 = m ≤ 500
- land[i][j]는 i+1행 j+1열 땅의 정보를 나타냅니다.
- land[i][j]는 0 또는 1입니다.
- land[i][j]가 0이면 빈 땅을, 1이면 석유가 있는 땅을 의미합니다.
정확성 테스트 케이스 제한사항
- 1 ≤ land의 길이 = 땅의 세로길이 = n ≤ 100
- 1 ≤ land[i]의 길이 = 땅의 가로길이 = m ≤ 100
효율성 테스트 케이스 제한사항
- 주어진 조건 외 추가 제한사항 없습니다.
입출력 예
| land | result |
|---|---|
| [[0, 0, 0, 1, 1, 1, 0, 0], [0, 0, 0, 0, 1, 1, 0, 0], [1, 1, 0, 0, 0, 1, 1, 0], [1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 0, 0, 0, 1, 1]] | 9 |
| [[1, 0, 1, 0, 1, 1], [1, 0, 1, 0, 0, 0], [1, 0, 1, 0, 0, 1], [1, 0, 0, 1, 0, 0], [1, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1]] | 16 |
입출력 예 설명
입출력 예 #1
문제의 예시와 같습니다.
입출력 예 #2
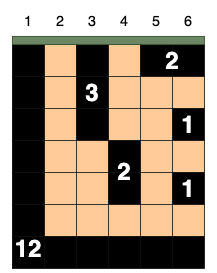
시추관을 설치한 위치에 따라 뽑을 수 있는 석유는 다음과 같습니다.
| 시추관의 위치 | 획득한 덩어리 | 총 석유량 |
|---|---|---|
| 1 | [12] | 12 |
| 2 | [12] | 12 |
| 3 | [3, 12] | 15 |
| 4 | [2, 12] | 14 |
| 5 | [2, 12] | 14 |
| 6 | [2, 1, 1, 12] | 16 |
6번 열에 시추관을 설치하면 크기가 2, 1, 1, 12인 덩어리의 석유를 얻어 뽑을 수 있는 석유량이 16으로 가장 많습니다. 따라서 16을 return 해야 합니다.
제한시간 안내
정확성 테스트 : 10초
효율성 테스트 : 언어별로 작성된 정답 코드의 실행 시간의 적정 배수
풀이 방법
초기에는 이중 for를 돌며 매번 land를 원본 상태로 초기화해주면서 석유가 있는 곳마다 BFS를 수행했으나 시간초과가 발생해 다른 방법을 찾았다
- BFS를 통해 석유덩어리의 개수와 각 덩어리를 이루는 석유들의 위치를 저장.
- 석유 덩어리를 각 2, 3, 4 ... 와 같은 수로 이름을 정하고 dict에 각 덩어리 별 크기를 저장. 크기는 덩어리를 이루는 석유들의 위치들을 저장한 리스트의 길이가 됨
- 석유 덩어리를 구성하는 각 위치들에 석유덩어리의 이름 값을 저장
- 열 별로 마주하는 석유 덩어리들의 번호를 key로 하는 dict의 value값을 합산
코드 최적화가 더 가능한 부분이 많이 있을 것이라 생각한다. 그래도 실행 속도가 매우매우 빨라졌다
다른 사람들의 코드 중 인상적인 것이 있었는데 먼저, 각 열별로 채취할 수 있는 석유량을 저장하는 1차원 리스트 하나를 선언해둔다.
이후 이중 for를 돌며 각 위치에서 BFS를 돈다 그러나 한 번 방문한 곳은 다시 방문하지 않는다 대신, 석유 덩어리를 구성하는 각 위치들의 열 정보를 덩어리마다 집합 형태로 저장한다
덩어리를 발견할 때마다 덩어리를 이루는 열 정보를 기반으로 열별 석유량에 덩어리 크기만큼 값을 더해줌
그러면 BFS를 전체 한 번만 돌고도 각 열별로 채취할 수 있는 석유량을 구할 수 있다
코드
from collections import deque
import copy
def solution(land):
col_num = len(land[0])
row_num = len(land)
dxs = [1,-1,0,0]
dys = [0,0,1,-1]
# bfs로 석유 위치와 석유 덩어리 크기 구하기
pos_list = []
cnt = 2
for i in range(row_num):
for j in range(col_num):
tmp = []
if land[i][j] == 1:
q = deque([(i,j)])
tmp.append((i,j))
land[i][j] = cnt
while q:
x, y = q.popleft()
for dx, dy in zip(dxs, dys):
nx, ny = dx+x, dy+y
if -1<nx<row_num and -1<ny<col_num and land[nx][ny] == 1:
q.append((nx, ny))
tmp.append((nx, ny))
land[nx][ny] = cnt
if len(tmp):
pos_list.append(tmp)
cnt += 1
# 석유 덩어리 크기를 저장하기
size = dict()
for i in range(2, cnt):
size[i] = len(pos_list[i-2])
# 열 별로 순회하며 얻을 수 있는 석유 덩어리들의 크기를 더하기
# transpose and summation
max_amount = 0
for elem in zip(*land):
tmp = 0
for num in set(elem):
if num != 0:
tmp += size[num]
max_amount = max(tmp, max_amount)
return max_amount더 효율적인 코드
from collections import deque
import copy
def solution(land):
col_num = len(land[0])
row_num = len(land)
dxs = [1,-1,0,0]
dys = [0,0,1,-1]
visited = [[False]*col_num for _ in range(row_num)]
cols_score = [0]*col_num
for i in range(row_num):
for j in range(col_num):
if land[i][j] == 1 and not visited[i][j]:
q = deque([(i,j)])
visited[i][j] = True
cnt = 0
cols = set()
while q:
x, y = q.popleft()
cols.add(y)
cnt += 1
for dx, dy in zip(dxs, dys):
nx, ny = dx+x, dy+y
if -1<nx<row_num and -1<ny<col_num and land[nx][ny] == 1 and not visited[nx][ny]:
q.append((nx, ny))
visited[nx][ny] = True
for idx in cols:
cols_score[idx] += cnt
return max(cols_score) 