조인은 1:N이 기본입니다. N쪽은 없을 수도 있지만, 1쪽은 반드시 하나는 있어야합니다.
EX) N(카테고리),1(상품) / N(결재이력),1(결재)
조인
cross join(카티션 곱)
- 2개 테이블의 모든 행 연결
- select c.cust_id,c.cust_name,p.prod_cd,pr.prod_name from cust c, prod p(이렇게 많이 씀)
- select c.cust_id,c.cust_name,p.prod_cd,pr.prod_name from cust c corss join prod p(위와동일)
- ANSI 표준으로 작성하면 오라클에서도 적용가능
- c x p가 결과값 갯수
- 나오는 일이 거의 없음
inner join
- 조인 대상 테이블 사이의 컬럼 값 동등(=) 비교를 통해 갑ㅌ은 값을 가진 행끼리 연결
- from A,B where A.key=B.key
- from A inner join B ON B.key=A.key
- from A natural join B ->본인이 동일한 이름 가지는 컬럼 모두 조인해줌(중요x)
- from A inner join B using (A.key) -> 지정된 컬럼과 동일한 이름(key)의 컬럼 조인(중요x)
outer join
- 조인 시 한쪽 테이블에서 조인 조건에 맞지 않은 row도 결과에 포함하기 위해 사용
- from A left outer join B on A.key=B.key
- A가 left가 될지,B가 left가 될지 순서 중요
- filter 조건이 없으면 한쪽은 무조건 full scan
- a가 1, b가 N 쪽
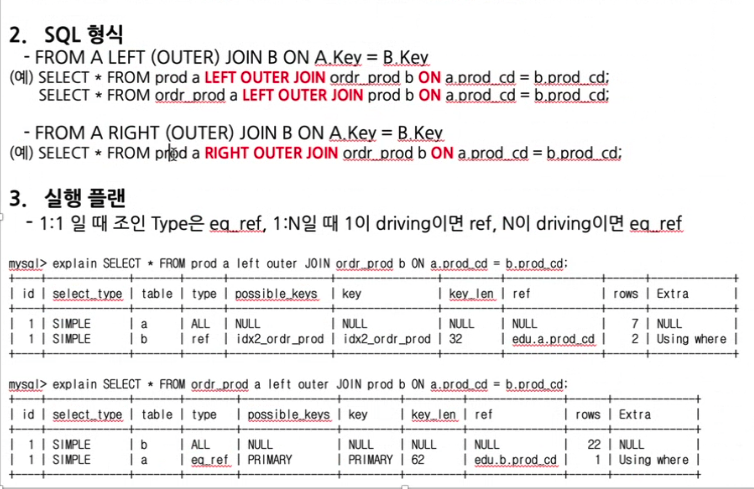
참고
* 중복된 컬럼도 당연히 인덱스 생성가능 * PK/UK 만 중복 불가능 * Ref => 중복값 있는 인덱스 사용하는것 * eq_ref => PK/UK 사용 * 1:N 일때 1이 driving 이면 ref * 후행테이블이 N으로 중복값이 있기 때문에 ref * N이 driving 이면 eq_ref * 후행테이블이 1으로 중복값이 없기 때문에 eq_ref
semi join
- 서브 쿼리와 메인쿼리와의 연결처리를 위한 유사 조인방식
- in
- select * from prod a where a.prod_cd in (select b.prod_cd from ordr_prod b where ordr_prod_cnt >3{->있는지없는지만확인하는것}); - exists
- select * from prod a where exists (select 1 from ordr_prod b where a.prod_cd=b.prod_cd and b.ordr_prod_cnt >3{->있는지없는지만확인하는것}); - 밖에꺼랑 연결되어있는 것 (a.prod_cd, b.prod_cd 이름공유)
- 한명의 사원은 반드시 하나의 부서에 포함되어야 함
- 그림은 부서 테이블은 미리 만들어놓을 수 있음
- semi join 확인 gogo
- inner join
- select a.dept_cd, a.dept_nm from dept a, emp b
(조인조건)where a.dept_cd=b.dept_cd
and enter_ymd >= ‘2016-01-01’;- 5건
- (이름(이름은 안나옴),부서코드,부서명) 박가수,aaaa, 가수팀 박성우,cccc,성우팀
송성우,cccc,성우팀
정아나,dddd,아나운서팀
최아나,dddd,아나운서팀- 따옴표가 안들어가면 조건이 제대로 적용이 안됨
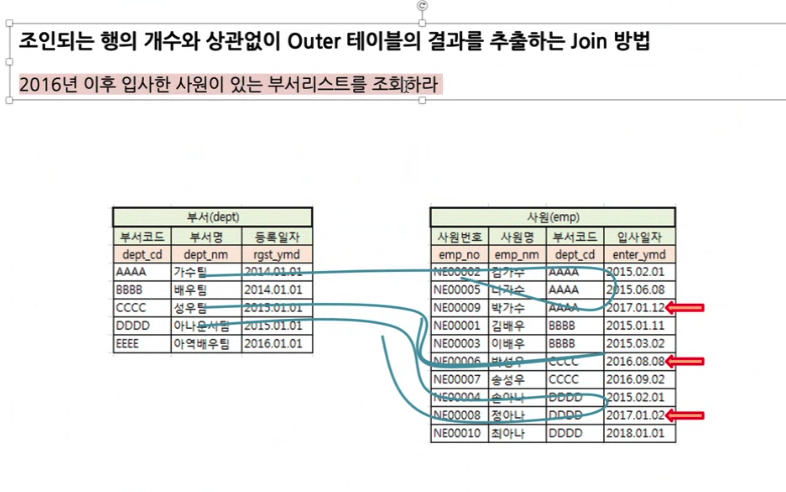
- 원하는 조건이 아닙니다! 입사한 사원이 있는 부서리스트를 중복없이 조회
해야합니다!- select distinct a.dept_cd, a.dept_nm from dept a, emp b
(조인조건)where a.dept_cd=b.dept_cd
and enter_ymd >= ‘2016-01-01’;- 원하는 결과가 나오긴 하지만, 비효율적입니다.(distinct를 하기 때문)
- semi join
- 다 들여다보는 힘든 작업을 하지 않겠다.
- 그게 semi join을 하는 이유
- 사원이 있는 부서리스트 한번 확인하면 그 부서에 포함되어있는 사원들은 건너뛰는 것
- meterialized : 날짜 대로 정렬하고 메모리에 올려두었다가(distinct해서) 그 임시테이블과 부서 테이블을 조인해서 결과를 냄
- materialized -> 세미조인의 방법 중에 하나임
- distinct 제거 작업이 없다는 것이 중요(distinct는 굉장히 비싼작업)
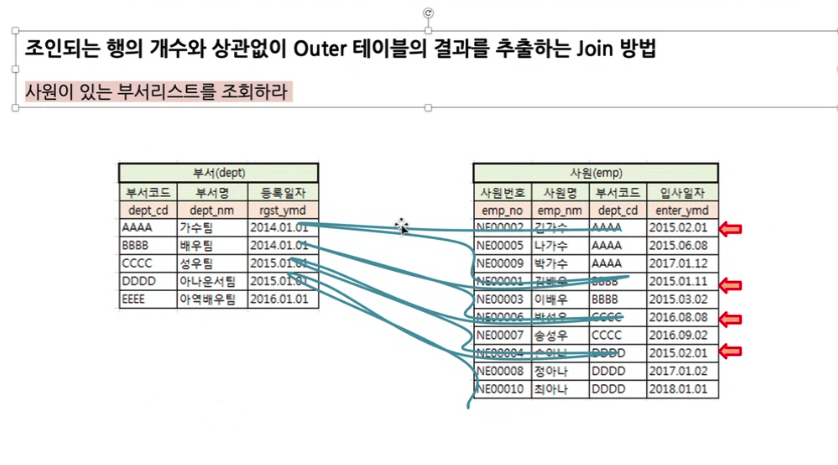
<semi join이 나온이유>
- 중복되어 나오는 것을 없애기 위해
- 중복제거(distinct)는 비쌈
anti join
- left join on where B.key in null
- join되지 않는 것만 찾겠다
조인방식
여기까지의 조인은 nested loop 에서 중요한 조인을 설명
mysql hash를 제공하지 않아서, 위 4개의 조인을 자주 사용했지만, mysql 8.0에서 hash가 들어오면서 그 방식도 알아야겠죠?
- nested loop
- sort merge
스캔한 다음+sort한 다음+merge(특정값뽑아서같은값찾아테이블합치기) 한다 - hash
메모리에다가 올려놓는 방식
메모리를 한번 읽고(메모리에서 참조) -> 시간이 굉장히 빨리,,,
스캔한다음+메모리 올리는 시간+메모리에 액세스해서 같은값 찾기
장점 : sort 보다 빠름
hash가 생겼다=대량처리가 가능해졌다!!!
sort인지 merge인지는 옵티마이저가 결정
nested loop인데 index가 없으면 카티션 곱 -> 처음부터 끝까지 조회
해당값을 빠르게 찾기 위해 특정값을 가지게 하는 것-> 인덱스를 사용하는 것
조인 실습1
실행계획에서 먼저 나오는 테이블이 드라이빙되는 테이블입니다 :)
실행계획
- 1이 driving -> ref : 아 여러개를 읽는구나
- N이 driving -> eq_ref : 1쪽이 한개 밖에 없어서 하나 읽음

- a : ALL, b : ref ->a를 먼저 드라이빙해서 full scan 하겠다
a에서 b를 참조할때 ref로 참조하겠다.
a : 1쪽, b : N쪽 - a : ALL, b : eq_ref -> a쪽은 full scan, b쪽은 단지 한건밖에 없음
a : N쪽, b : 1쪽 - 쿼리결과
N : ordr_prod -> 3개(건수) 결과
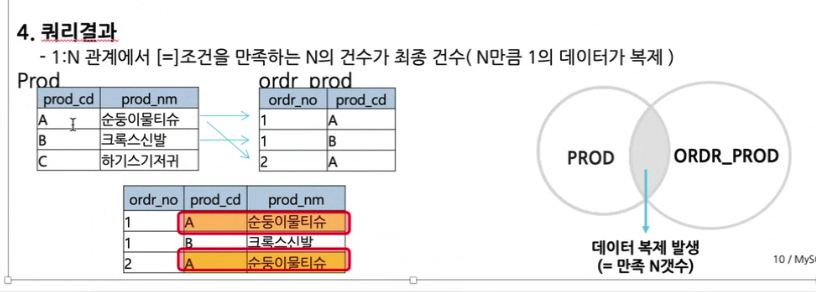
1:N left join
left join = inner join결과(3개)+inner join 되지않은 left(1개:c하기스기저귀)
N:1 left join(inner join으로 많이 쓰기 때문에 outer join 잘하지 않음)->옵티마이저가 알아서 변경->그래서 성능차이는 없음 알아서 Inner join으로 변경되니까
inner,outer join 모두 n의 건수 나옴
조인 실습2
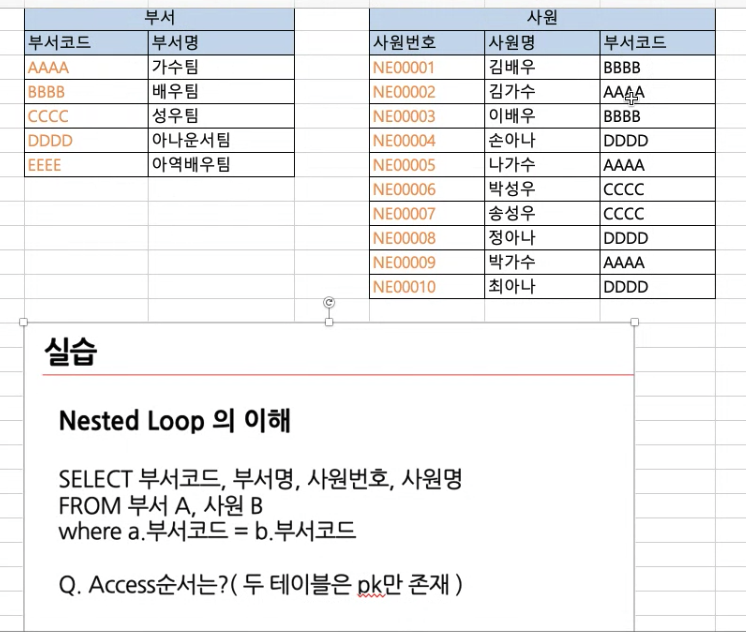
- 필터조건이 더 없으면 한쪽은 무조건 풀스캔해야함
- 기본은 작은 테이블에 드라이빙 하는 것이 더 효율적
- 하지만 위의 테이블에서 부서 테이블에 부서코드 인덱스(PK) 가 걸려있음 따라서 부서 테이블이 후행테이블(드라이븐테이블) 이 되는 것이 효율적
- 부서테이블을 먼저 드라이빙하는 것 보다, 사원테이블이 먼저 드라이빙하는게 적게 액세스함(두 테이블의 pk가 각각의 인덱스가 됨)
- 부서테이블을 먼저 드라이빙하고 싶다면, 사원테이블에 인덱스를 걸어주어야함
- 사원번호와 부서코드를 정렬해서 인덱스를 생성해주게 되면 바로 사원테이블의 특정 정보에 액세스할 수 있음
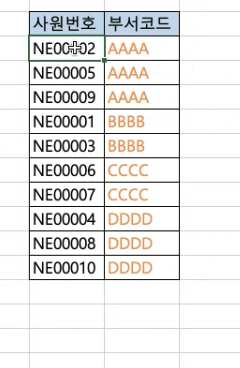
- 따라서 후행테이블에 인덱스가 있어야함!!!! 옵티마이저는 자동으로 인덱스 있는 테이블을 후행테이블로 지정
1:N 관계에서,,
1쪽 데이터만 뽑고 싶다면 select 절에 속한 컬럼을 확인하고(1쪽만 조회하는지,N쪽같이 조회하는지)
=>중복제거를 하는 게 있는 것 같다면, 세미조인을 사용해라
=>액세스 양을 줄일 수 있음
조인예제 1
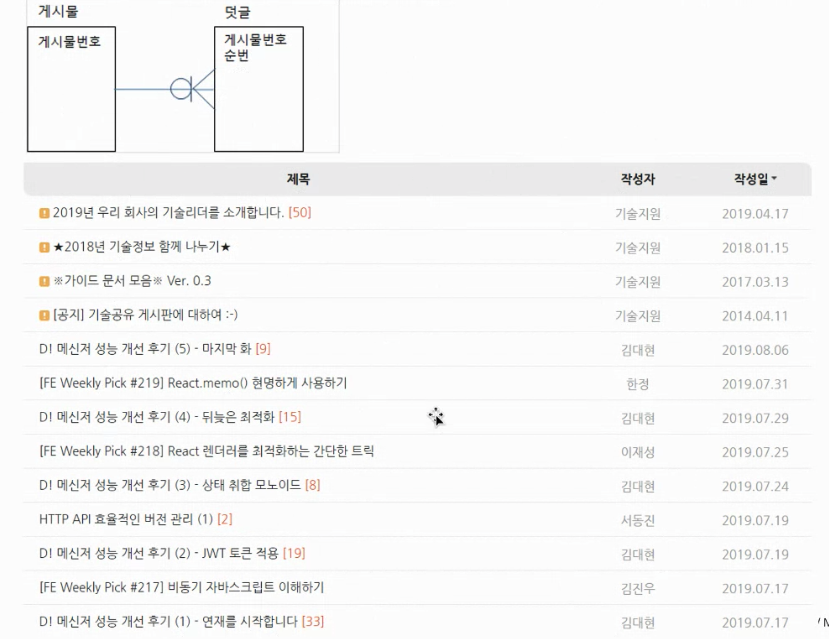
제목 옆에 덧글 갯수가 있다면,,([50])덧글 테이블을 읽어야하기 때문에 쿼리가 느려짐
=> 튜닝 : 덧글의 수를 게시물 테이블의 컬럼으로 하나 놓고 덧글 하나 올라갈때 count 자동으로 올리기
조인실습 3

참고
mysql version확인
select version();옵티마이저는 조인순서를 어떻게 결정?(어떤 테이블을 먼저 드라이빙)
모든 액세스 패스의 cost를 계산해서 최소 cost의 조인 순서 결정explain에서
ref => non clustered index 탄다는것인덱스
인덱스란?
- 튜닝을 위해 아주 중요한,,,
- b-tree 형태의 구조가 기본
- 클러스터형 키 : pk로 데이터를 뽑아왔다면->속도 굉장히 빠름->클러스터형 키 사용하기 때문
- 논클러스터형 키 : b tree를 2번 타는 구조
복합인덱스
2개 컬럼 이상이 복합돼서 인덱스를 구성

- 정답은 1번
- (equal) 조건이 선행으로 와야하고 range는 후행으로 와야함
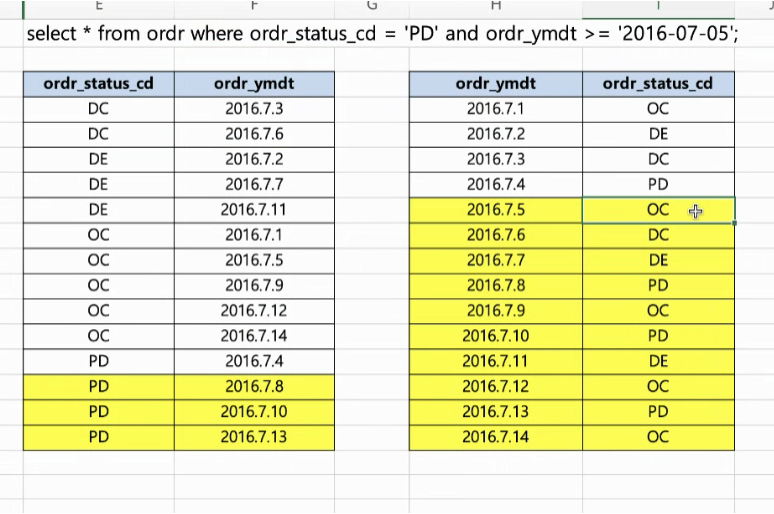
인덱스 형변환
형변환우선순위가 높은쪽으로 변형
숫자>문자
숫자+문자=>숫자
-
select * from cust where ordr_no= '1';
‘1’이 형변환 되므로 인덱스 스캔시 문제없음 -
select * from cust where ordr_status_cd = 10;
ordr_status_cd 쪽이 형변환 되므로 인덱스 활용(X) -
select * from cust where ordr_ymdt = '2011-02-17';
문자형은 date/time형태로 양방향 형변환 되므로 인덱스 활용(O) -
select * from cust where ordr_ymdt = cast('2011-02-01‘ as datetime);
상수쪽이 datetime으로 형변환 되므로 인덱스 활용(O) -
select * from ordr where substring(ordr_ymdt , 1, 4) = '2011' and substring(ordr_ymdt , 4, 2) = '02’;
컬럼쪽에 명시적인 형변환이 일어나므로 인덱스 활용(X) / 변수쪽이 형변환이 일어나면 인덱스는 타지 않음
limit
- ORDER BY col1 LIMIT n 절의 경우 order by절이 인덱스를 이용할 수 없는 경우 where 조건을 만족하는 모든 데이터를 물리정렬 수행후 LIMIT 적용하므로 좋지 않은 응답속도를 보임
union
- Union [ALL] ~ order by 는 order by시 인덱스를 사용할 수 없으므로 언제나 filesort를 유발
- 3개 테이블을 union한 인덱스는 어디에도 없음-> order by 를 사용하면 인덱스를 사용할 수 없음
order by 사용시 filesort
- 인덱스를 걸지 않아서 order by가 생기는듯합니다.
- 인덱스를 걸어도(데이터 중복해서 들어감)->무조건 좋은건 아님/공간낭비/느려짐/insert가 느려짐
- 무엇이 좋은지는 상황에 따라 판단
- 그래도 없애는게 튜닝포인트긴 함!
인덱스 예제
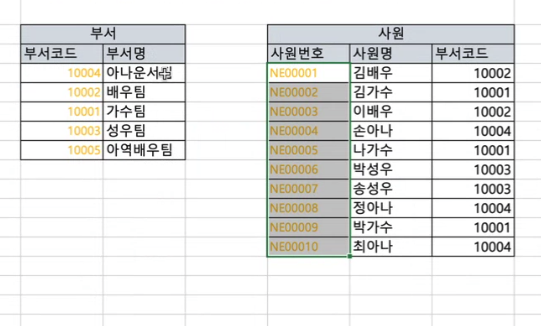
예제 1

- 부서테이블에 부서명,부서코드에 인덱스가 있는 것이 좋음
- emp 테이블의 idx1(dept_cd) 인덱스
- 사원의 사원번호가 PK, 부서의 부서코드가 PK, 사원의 부서코드에 인덱스 생성해주면, 사원테이블이 선행테이블로 드라이빙되어 부서코드를 통해 부서 테이블에 효율적으로 엑세스
- dept 테이블의 idx1(dept_nm) 인덱스
- where 조건의 a.dept_nm 컬럼에 인덱스가 있는 것이 좋기 때문에 dept_nm 에 인덱스 생성
예제 2
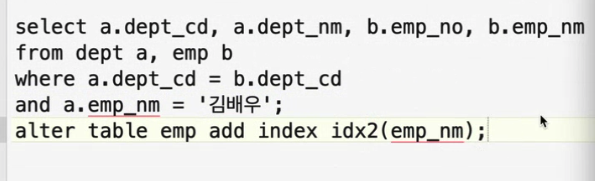
- 사원명에 인덱스가 있다면 가장 좋음(필터조건에 인덱스가 있는 것이 좋음)
예제 3
select a.emp_no, a.emp_nm
from emp a
where a.dept_cd ='DDDD'
order by enter_ymd;- order by 사용할때,,인덱스가 없는데 정렬하려고 하면 filesort가 생김
- 부서코드,입사일자,(pk:사원번호) 로 인덱스를 만들어주게 되면, 됨
- (dept_cd,enter_ymd); -> enter_ymd는 사용x
- (enter_ymd,dept_cd); -> 이 인덱스는 사용할 수 없음 dept_cd가 정렬되지 않았기때문
idx1(dept_cd) 와 idx2(dept_cd,enter_ymd) 는 다른 인덱스
최종 결론 = idx1(dept_cd), idx2(enter_ymd) 혹은 idx2(enter_ynd,dept_cd) 생성
dbms
- 파일에서 데이터를 불러오는것은 비쌈
- 자주쓰는 것을 메모리에 올리자!
- 그 메모리를 크게 만든 것이 데이터베이스
Explain(실행계획)
- type은 Access type을 의미한다
- 좋다 : Const, system, eq_ref
- 나쁘다 : ALL(테이블풀스캔), index(인덱스풀스캔)
- 처리범위에 다르다 : range, ref
- extra는 실행계획을 생성할 때 적용하는 최적화 기법을 표현하거나 부가정보를 담는다
- 좋다 : using index(커버링인덱스), using where(메모리에서 필터링)
- 나쁘다 : using filesort, using join buffer
예제 1
다음은 실행 플랜의 Extra 필드에 나오는 메시지입니다. 각 메시지가 어떤 의미를 가지고 있는지, 또한 쿼리 성능에는 어떤 영향을 미치는지 생각해 보세요.
a) using index : index를 사용한다는 뜻 (좋음)
b) using filesort : 물리적인 정렬작업 (나쁨)->ex>order by(인덱스사용x)
c) not exists : 해당하지 않는것 / left join 조건을 만족하는 하나의 레코드를 찾았을 때 다른 레코드의 조합은 더 이상 검사하지 않는다.
조인/인덱스/실행계획 실습
1. 다음 쿼리를 튜닝하시오
select * from reserve where reserve_state_code = 'RETURN_COMPLETE’;정답 ) alter table reserve add index idx1(reserve_state_code);2. 다음 쿼리를 튜닝하시오
select * from product where product_class_code = 'CONCERT' order by register_datetime;정답 1 ) alter table product add index idx1(product_class_code,register_datetime);정답 2) product_id 는 auto increment 등록되어있고, register_datetime은 등록했을 시간이기때문에 둘의 순서가 동일함
-> product_class_code만 인덱스 걸어주고
-> select * from product where product_class_code = 'CONCERT' order by product_id;
// 이렇게 적어주어도 동일한 결과가 나옴(커버링 인덱스(쿼리를 충족하는데 필요한 모든 데이터를 갖는 인덱스)를 쓸 수 있음)3. 다음 쿼리를 튜닝하시오
select * from product where register_datetime < '2015-02-25 00:00:00’;정답 1) alter table product add index idx2(register_datetime);정답 2) idx2 생성하지 않았다고 가정
-> 코드 분포도 확인하면 concert,exhibion 존재
-> 2번에서 idx1(product_class_code,register_datetime); 걸어줬음
-> select * from product where product_class_code in ('CONCERT’,’EXHIBITION’) and register_datetime < '2015-02-25 00:00:00’;
// 이렇게 적어주어도 동일한 결과가 나옴 ( idx1 사용 )4. 다음 쿼리를 튜닝하시오 ( 조회기간은 무조건 하루 )
select * from product where register_datetime = '2015-02-25' order by product_class_code ;
- 데이터 변환시킨 다음 새로운 컬럼으로 저장해야함
update product set register_ymd=date_format(register_datetime, '%y%m%d');
정답 ) alter table product add index idx3(register_ymd,product_class_code);5. 다음 쿼리를 튜닝하시오
select * from product a, hall b where a.hall_id = b.hall_id and b.register_datetime > '2016-07-01’;시행착오)
- alter table hall add index idx1(register_datetime,hall_id);
- 참고) 위 인덱스 생성은 hall b 테이블에만 해당하는 인덱스!
- 하지만 인덱스만 생성하면, explain 하면 idx 사용하지 못함 (explain을 떠보니 a가 선행테이블이됨(원래는 b 테이블선행되어야함))
why???)
- a.hall_id(varchar) vs b.hall_id(int) 이기 때문에,,a.hall_id가 형변환이 일어남(varchar->int)
- a는 varchar로 이루어진 hall_id인덱스를 가지고 있음 따라서 인덱스를 읽을 수 없어 풀스캔을 하게 됨.
정답) alter table product modify hall_id int not null;
-> hall(b)이 선행테이블이므로 b.hall_id가 기준이되므로 a.hall_id를 int로 변경해야함6. 아래 내용을 보고 쿼리를 튜닝하시오

(단, 응모시마다 숫자는 리프레쉬)
update event_entry set entry_count = entry_count+1 where evend_id = 123;
index idx1(event_id)정답)
-> 추첨을 통해 포르쉐를 주는 것이기때문에, 몇번째 응모자인지 중요하지 않음
-> 응용서버의 메모리 같은 곳에 저장해놓고 db서버의 부하를 줄이자
-> 페이지 자체를 기획해야하는 수준
-> 화면단에서 부하를 어떻게 분산하는지도 중요하다!7. 티켓조회 초기화면이 아래와 같이 주어졌을 때 쿼리를 튜닝하시오.( 공연장 창구에서 예매자의 발권을 확인하기 위한 쿼리 )

select ticket_no,
reserve_no,
reserve_detail_no,
issue_state_code,
issue_datetime,
register_datetime
from ticket
where issue_state_code = ‘USE’
order by register_datetime desc;정답) 시작점이 정해져있지 않아서(default value),
예매한지 한달 정도의 내역을 보여주고 싶은데,
몇십년전까지의 데이터를 가지고 오고 그래서 장애가 났음.- 대면하는 일이 있는 서비스 중요
- 화면에서 간단하게 할 수 있는 일이 있으면 해줘야함
- 데이터가 적으면 모를까 데이터가 많으면 장애 날 확률이 높음.
교육 끝난 후, 개인적인 질문
- 자동완성기능을 구현하고자 할때,
전체 항목값을 가져오고, 이를 따로 저장, 자동완성 기능 실행(한번+속도느림)
vs
사용자 입력 시마다 쿼리문 호출해서 자동완성 기능 실행(여러번+속도빠름+잦은db접근)
입력때마다 db접근<한번에 가지고 오는 것<메모리에 저장해놓는것(어플리케이션)
db에 자주 접근하는 것이 좋지 않기때문에, 처음 한번만 db에 접근해 데이터를 가지고 오고 프론트단에서 문자열 비교로 자동완성 기능 구현
- 다중조건 검색 시, 조건값이 빠질때에도 검색이되는 형태여야합니다. 어떻게 구현 가능? -> ppt 60.61.62 참고 (Dynamic query)
- 프론트단에서 입력값 사용해서 문자열 생성->백엔드단에 전달
- 백엔드에서 입력값 갯수에 따른 쿼리문 생성 함수 생성
- 백엔드에서 입력값[데이터명,데이터값] 받아 문자열 수정해서 쿼리문 생성
- spring에는 다이나믹 쿼리 존재
- 가장 무식하지만 좋은 것은 쿼리 다 적어주는것 조건3개면 8개 쿼리

https://mozi.tistory.com/168