10장
section1 : 인덱스의 개요
1. 인덱스의 개요
인덱스란?
- 데이터 검색할 때 데이터에 빠르게 접근할 수 있도록 도와줌
- 데이터베이스 튜닝 시 가장 큰 효과를 볼 수 있음
- 서버 입장에서는 적은 처리량으로 결과를 얻음으로써 다른 요청을 더 많이 할 수 있음
- 결과적으로, 전체 시스템의 성능이 향상
찾아보기가 있는 책은 주요 용어가 가나다순, 알파벳순으로 정렬돼 있고 용어 옆에 쪽수가 적혀 있어 해당 페이지를 펼치면 원하는 내용을 바로 찾을 수 있음 => 인덱스는 이와 같은 찾아보기와 비슷한 개념
2. 인덱스의 문제점
- 인덱스는 단점도 있기 때문에 효율적으로 사용하는 것이 간단하지만은 않음
- 필요없는 인덱스를 만드는 바람에 데이터베이스가 차지하는 공간만 늘어나고, 인덱스를 이용해 데이터를 찾는 것이 전체 테이블 검색보다 훨씬 느린 경우가 있음
- 인덱스를 저장할 공간이 필요함
- 처음 인덱스를 생성하는 데 많은 시간이 소요
- 데이터의 변경 작업이 자주 일어날 경우 오히려 성능이 나빠질수도 있음
주의❗️ 인덱스는 잘 사용해야지만 속도가 향상되고 시스템의 성능이 좋아집니다!
section2 : 인덱스의 종류와 자동생성
1. 인덱스의 종류
1) 클러스터형 인덱스
- 영어사전
- 영어사전처럼 책의 내용 자체가 순서대로 정렬
- 테이블당 하나만 생성 가능
- 행 데이터를 인덱스로 지정한 열에 맞춰 자동 정렬
2) 보조 인덱스(=논클러스터형 인덱스=비클러스터형 인덱스)
- 찾아보기가 있는 책
- 찾아보기가 별도로 있고, 찾아보기에서 먼저 단어를 찾은 후 해당 페이지로 이동해 내용찾기
- 테이블당 여러개 생성 가능
2. 자동으로 생성되는 인덱스
- 인덱스는 테이블의 열(column) 단위로 생성
- 하나의 열에 생성할수도 있고 여러 열에 생성할 수도 있음
- 아이디 열을 기본키로 설정하면 자동으로 아이디 열에 클러스터형 인덱스가 생성
* why? ,, 기본키는 테이블당 하나 & 클러스터 형 인덱스는 테이블당 하나
3. 실습으로 알아봅시다!!
1. 테이블 만들고 자동으로 생성된 인덱스 확인
기본키를 지정해봅시다!
CREATE TABLE TBL1
( a INT PRIMARY KEY,
b INT,
c INT
);
SHOW INDEX FROM TBL1;- a 열에 고유 인덱스가 생성됨

SHOW INDEX FROM 테이블이름;
- key_name의 PRIMARY : 클러스터형 인덱스
- Non_unique : 0이면 고유 인덱스, 1이면 비고유 인덱스
1) 고유 인덱스 : 인덱스 값이 중복되지 않는 인덱스
2) 비고유 인덱스 : 인덱스 값이 중복되는 인덱스- Seq_in_index : 해당 열에 여러 개의 인덱스가 설정됐을 때 순서를 나타냄. 대부분 1
- Cardinality : 중복되지 않은 데이터의 개수
- Index_type : 인덱스가 어떤 형태로 구성되있는지 -> MySQL은 기본 B-Tree 구조
기본키와 UNIQUE 제약 조건을 설정해봅시다!
CREATE TABLE TBL2
( a INT PRIMARY KEY,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM TBL2;- 테이블에 UNIQUE 조건을 설정하면, 보조 인덱스(b,c)가 자동으로 생성됨
- 보조 인덱스는 테이블당 여러개 설정 가능

다음으로는 기본키 없이 UNIQUE 제약 조건만 설정해봅시다!
CREATE TABLE TBL3
( a INT UNIQUE,
b INT UNIQUE,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM TBL3;- 모두 보조 인덱스로 생성
- 클러스터형 인덱스가 자동 생성되는 것 X

UNIQUE 제약 조건을 설정한 열 중 하나에 클러스터형 인덱스를 생성해봅시다!
CREATE TABLE TBL4
( a INT UNIQUE NOT NULL,
b INT UNIQUE ,
c INT UNIQUE,
d INT
);
SHOW INDEX FROM TBL4;- UNIQUE 제약 조건에 NOT NULL을 설정하면 클러스터형 인덱스 생성
- a 열의 Non_unique 값 0 이므로 고유인덱스이고, Null 값이 비어있으므로 Not null이다.
- 따라서 a열에 클러스터형 인덱스 생성

a열에는 UNIQUE 제약조건에 NOT NULL을 설정하고, d열에는 기본키 설정해봅시다!
CREATE TABLE TBL5
( a INT UNIQUE NOT NULL,
b INT UNIQUE ,
c INT UNIQUE,
d INT PRIMARY KEY
);
SHOW INDEX FROM TBL5;- 우선순위는 기본키이므로 기본키를 설정한 열에 클러스터형 인덱스가 생성
- NOT NULL을 설정한 a열은 보조 인덱스 생성

2. 클러스터형 인덱스의 정렬 확인하기
CREATE TABLE userTBL
( userID char(8) NOT NULL PRIMARY KEY,
userName varchar(10) NOT NULL,
birthYear int NOT NULL,
addr char(2) NOT NULL
);
INSERT INTO userTBL VALUES('YJS', '유재석', 1972, '서울');
INSERT INTO userTBL VALUES('KHD', '강호동', 1970, '경북');
INSERT INTO userTBL VALUES('KKJ', '김국진', 1965, '서울');
INSERT INTO userTBL VALUES('KYM', '김용만', 1967, '서울');
INSERT INTO userTBL VALUES('KJD', '김제동', 1974, '경남');
SELECT * FROM userTBL;| userId | userName | birthYear | addr |
|---|---|---|---|
| kHD | 강호동 | 1970 | 경북 |
| KJD | 김제동 | 1974 | 경남 |
| KKJ | 김국진 | 1965 | 서울 |
| KYM | 김용만 | 1967 | 서울 |
| YJS | 유재석 | 1972 | 서울 |
- 데이터를 입력할때의 순서와는 다르게 정렬됨
- 아이디(userID) 열에 클러스터형 인덱스가 생성돼 데이터를 입력하는 동시에 아이디 순으로 정렬하기 때문
- 아이디 열의 기본키를 제거하고 이름(userName)열을 기본키로 설정하면 아래 테이블과 같이 이름 열을 기준으로 정렬
| userId | userName | birthYear | addr |
|---|---|---|---|
| kHD | 강호동 | 1970 | 경북 |
| KKJ | 김국진 | 1965 | 서울 |
| KYM | 김용만 | 1967 | 서울 |
| KJD | 김제동 | 1974 | 경남 |
| YJS | 유재석 | 1972 | 서울 |
최종 결론
- PRIMARY KEY로 지정한 열에 클러스터형 인덱스 생성
- UNIQUE NOT NULL로 지정한 열에 클러스터형 인덱스 생성
- UNIQUE 또는 UNIQUE NULL로 지정한 열에 보조 인덱스 생성
- PRIMARY KEY와 UNIQUE NOT NULL이 같이 있으면 PRIMARY KEY로 지정한 열에 우선 클러스터형 인덱스 생성
- PRIMARY KEY로 지정한 열을 기준으로 데이터가 오름차순 정렬
section3 : 인덱스의 내부 작동
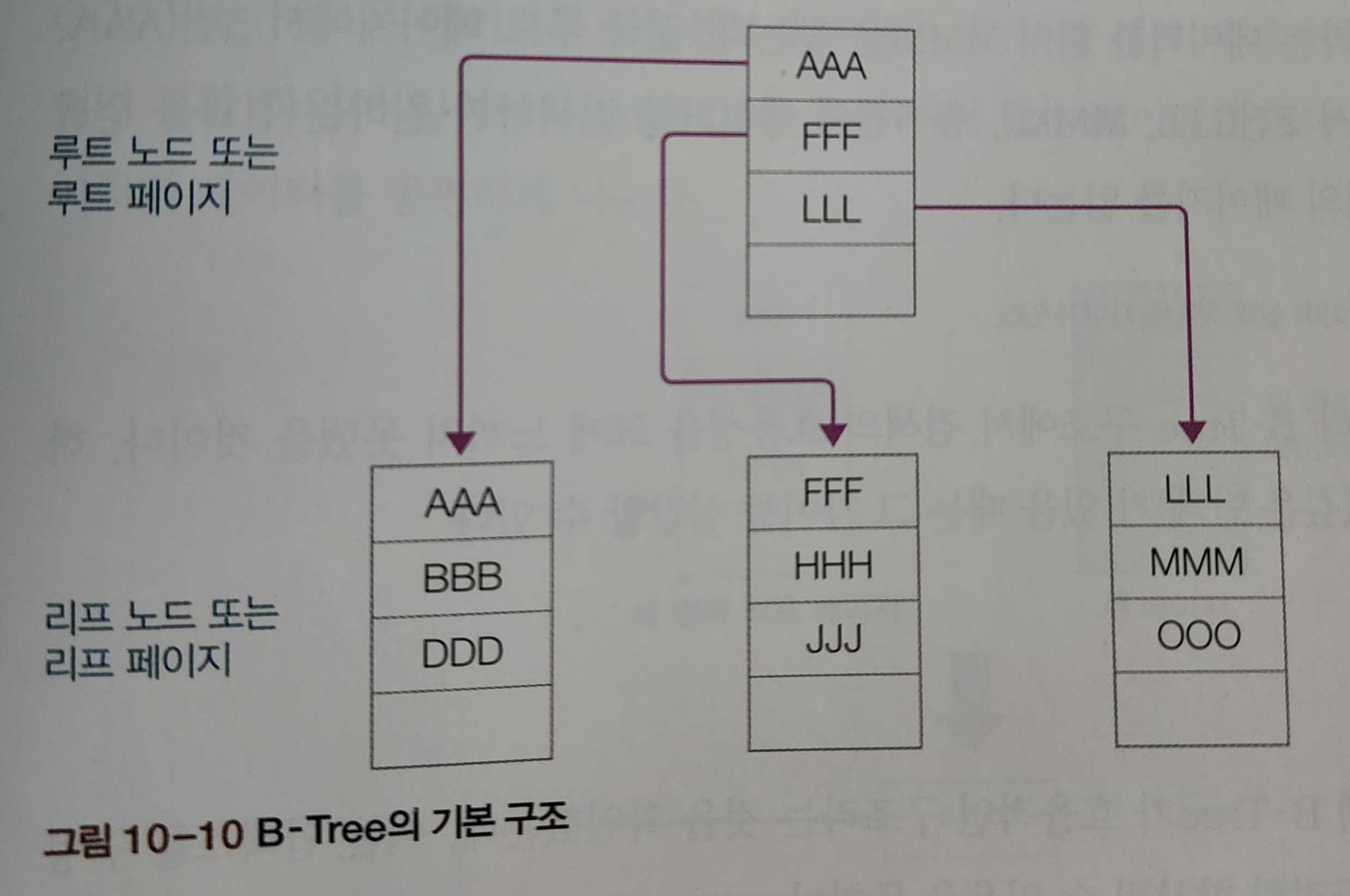
1. B-Tree의 개요
B-Tree : 균형이 잡힌 트리
- 노드 : 트리구조에서 데이터가 존재하는 공간
- 루트노드 : 가장 상위에 있는 노드로 모든 출발은 이 노드에서!
- 리프노드 : 가장 말단에 있는 노드
- 중간 수준 노드 : 루트노드&리프노드 중간에 끼인 노드
<B-Tree 구조가 아닌 경우>
B-Tree 구조가 아니라면 루트 페이지와 그 아래 연결은 존재하지 않고 리프 페이지만 있을 것. 이런 상황에서는 처음부터 검색하는 수밖에 없으므로 AAA~MMM 8개의 데이터를 검색하고 나야 결과를 얻을 수 있음
<B-Tree 구조일 경우>
B-Tree 구조는 데이터를 검색할 때 매우 뛰어난 성능 발휘함. MMM 데이터를 검색하는 경우,
1) 먼저 루트 페이지를 검색. AAA, FFF, LLL 이라는 데이터 읽기
2) MMM은 LLL 이후에 나오므로 3번째 리프 페이지로 이동
3) 3번째 리프 페이지에서 LLL,MMM이라는 데이터 읽어 MMM 찾기
결국, 루트페이지에서 3건(AAA,FFF,LLL) + 리프페이지에서 2건(LLL,MMM) 검색
2. 페이지 분할
예시를 통해 알아봅시다!!
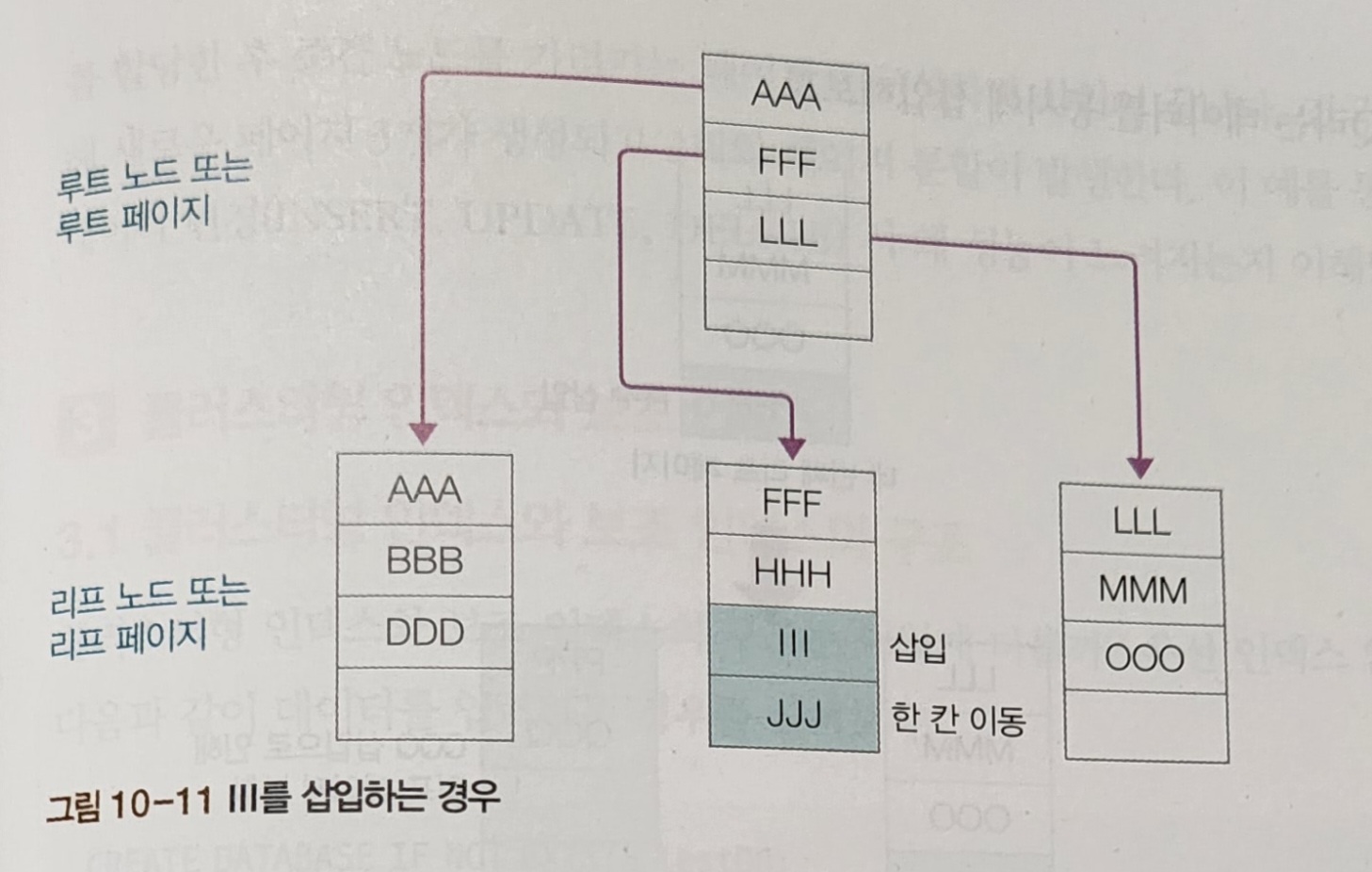 III 라는 데이터를 넣는다고 가정하면, JJJ가 한칸 이동하고 데이터 정렬
III 라는 데이터를 넣는다고 가정하면, JJJ가 한칸 이동하고 데이터 정렬
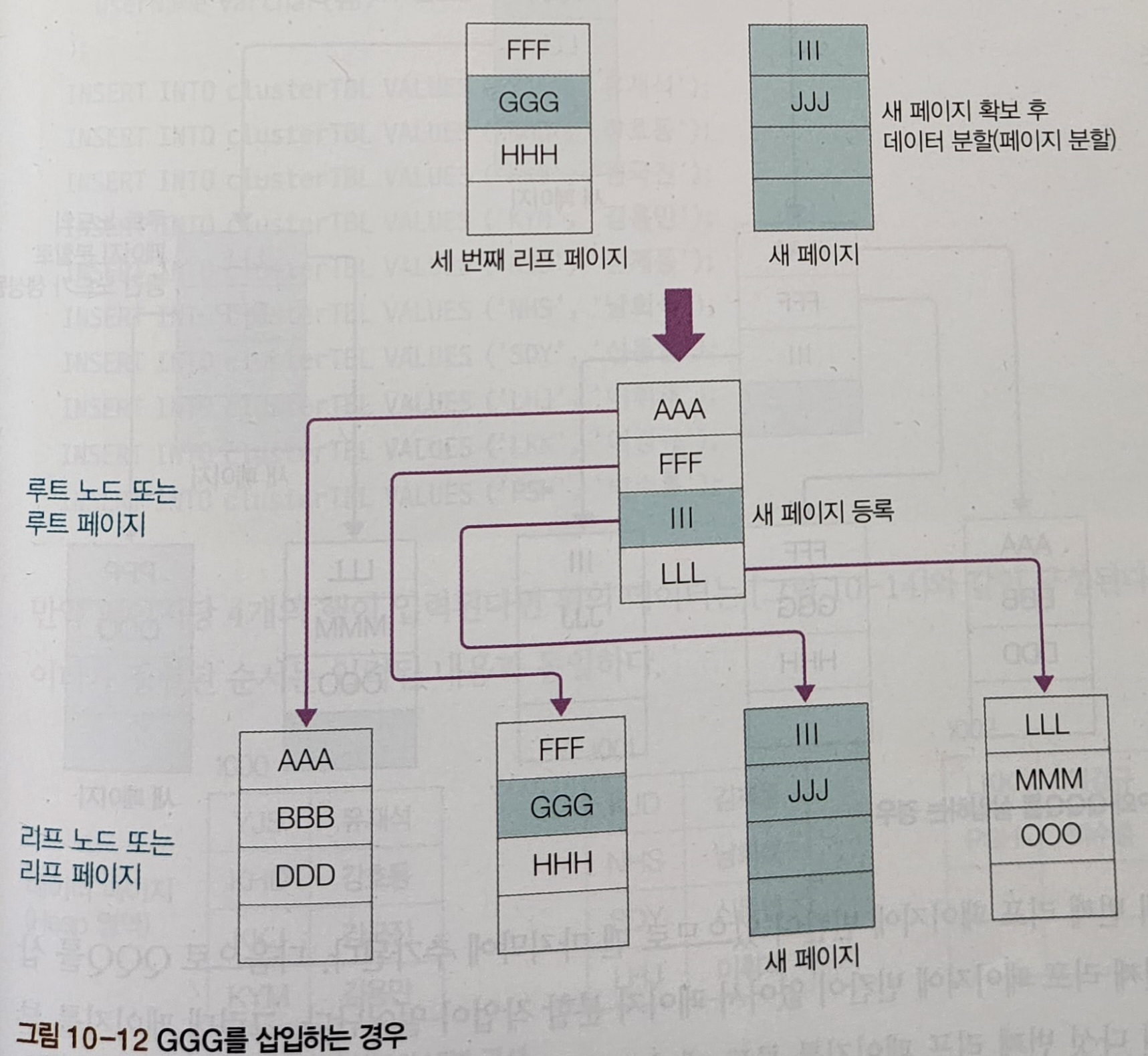
GGG라는 데이터를 넣는다고 가정하면, 두번째 리프 페이지에 빈 공간이 없기 때문에 페이지 분할 작업 일어납니다. MySQL은 비어 있는 페이지 하나 확보하고 두 번째 리프 페이지의 데이터를 공평하게 나눕니다.
이렇듯, 데이터를 1개만 추가했는데도 많은 작업이 일어납니다.
이번에는 PPP와 QQQ라는 데이터를 동시에 삽입한다고 가정하면,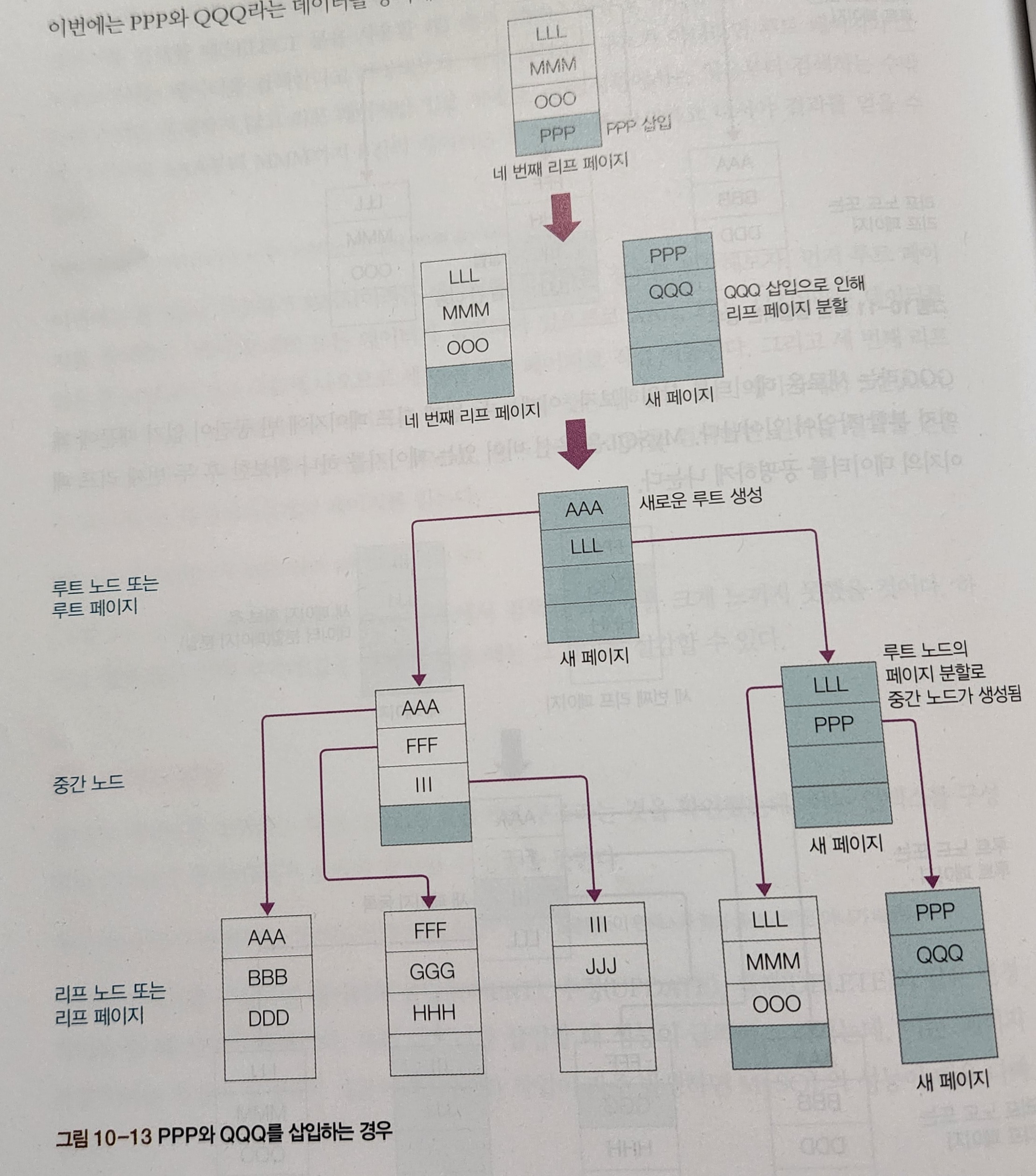 PPP는 네 번째 리프 페이지 맨 마지막에 추가. QQQ를 삽입하려면 페이지 분할 작업이 일어납니다. 페이지 분할 후 추가된 다섯번째 리프 페이지를 루트 페이지에 등록하려고 했지만 등록할 곳이 없어 분할이 필요합니다. 중간 페이지가 생성된 것입니다. QQQ를 삽입하기 위해서는 새로운 페이지 3개 생성, 2회의 페이지 분할 발생합니다.
PPP는 네 번째 리프 페이지 맨 마지막에 추가. QQQ를 삽입하려면 페이지 분할 작업이 일어납니다. 페이지 분할 후 추가된 다섯번째 리프 페이지를 루트 페이지에 등록하려고 했지만 등록할 곳이 없어 분할이 필요합니다. 중간 페이지가 생성된 것입니다. QQQ를 삽입하기 위해서는 새로운 페이지 3개 생성, 2회의 페이지 분할 발생합니다.
결론 : 인덱스를 구성하면 데이터의 삽입, 수정, 삭제와 같은 변경 작업을 할 때는 성능이 나빠짐.
3. 클러스터형 인덱스와 보조 인덱스
3.1.클러스터형 인덱스와 보조 인덱스의 구조
클러스터형 인덱스를 만들어봅시다!
CREATE TABLE clusterTBL
( userID char(8) ,
userName varchar(10)
);
INSERT INTO clusterTBL VALUES('YJS', '유재석');
INSERT INTO clusterTBL VALUES('KHD', '강호동');
INSERT INTO clusterTBL VALUES('KKJ', '김국진');
INSERT INTO clusterTBL VALUES('KYM', '김용만');
INSERT INTO clusterTBL VALUES('KJD', '김제동');
INSERT INTO clusterTBL VALUES('NHS', '남희석');
INSERT INTO clusterTBL VALUES('SDY', '신동엽');
INSERT INTO clusterTBL VALUES('LHJ', '이휘재');
INSERT INTO clusterTBL VALUES('LKK', '이경규');
INSERT INTO clusterTBL VALUES('PSH', '박수홍');
SELECT * FROM clusterTBL;| userId | userName |
|---|---|
| YJS | 유재석 |
| kHD | 강호동 |
| KKJ | 김국진 |
| KYM | 김용만 |
| KJD | 김제동 |
| NHS | 남희석 |
| SDY | 신동엽 |
| LHJ | 이휘재 |
| LKK | 이경규 |
| PSH | 박수홍 |
위 테이블의 userID에 클러스터형 인덱스 구성해봅시다! userID를 기본키로 지정하면 클러스터형 인덱스가 자동 생성
ALTER TABLE clusterTBL
ADD CONSTRAINT PK_clusterTBL_userID
PRIMARY KEY (userID);
SELECT * FROM clusterTBL;| userId | userName |
|---|---|
| kHD | 강호동 |
| KJD | 김제동 |
| KKJ | 김국진 |
| KYM | 김용만 |
| LHJ | 이휘재 |
| LKK | 이경규 |
| NHS | 남희석 |
| PSH | 박수홍 |
| SDY | 신동엽 |
| YJS | 유재석 |
- 결과는 userID를 기준으로 오름차순 정렬되었습니다.
- userID를 기준으로 클러스터형 인덱스가 생성됐기 때문! 구조는 아래 그림과 같습니다.
- 클러스터형 인덱스는 행 데이터를 해당 열로 정렬한 후 루트 페이지를 만드는 식으로 구성됩니다!
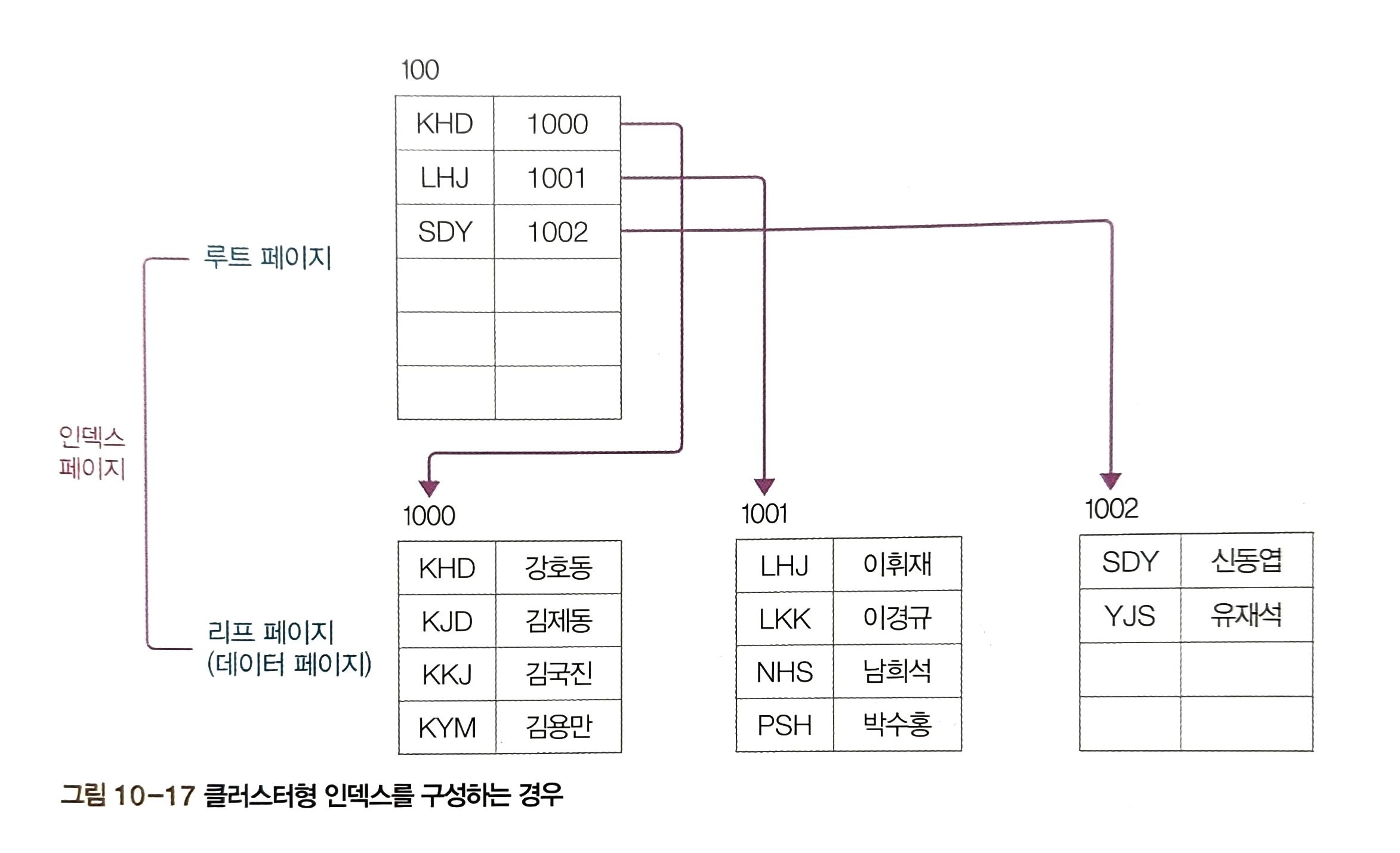
클러스터형 인덱스 : 인덱스 페이지의 리프 페이지가 데이터 그 자체!!
다음은 보조인덱스를 만들어봅시다!
CREATE TABLE secondaryTBL
( userID char(8),
userName varchar(10)
);
INSERT INTO secondaryTBL VALUES('YJS', '유재석');
INSERT INTO secondaryTBL VALUES('KHD', '강호동');
INSERT INTO secondaryTBL VALUES('KKJ', '김국진');
INSERT INTO secondaryTBL VALUES('KYM', '김용만');
INSERT INTO secondaryTBL VALUES('KJD', '김제동');
INSERT INTO secondaryTBL VALUES('NHS', '남희석');
INSERT INTO secondaryTBL VALUES('SDY', '신동엽');
INSERT INTO secondaryTBL VALUES('LHJ', '이휘재');
INSERT INTO secondaryTBL VALUES('LKK', '이경규');
INSERT INTO secondaryTBL VALUES('PSH', '박수홍');테이블 특정열에 UNIQUE 제약조건을 설정해 보조 인덱스 생성!
ALTER TABLE secondaryTBL
ADD CONSTRAINT UK_secondaryTBL_userID
UNIQUE (userID);
SELECT * FROM secondaryTBL;입력한 순서와 같습니다.
| userId | userName |
|---|---|
| YJS | 유재석 |
| kHD | 강호동 |
| KKJ | 김국진 |
| KYM | 김용만 |
| KJD | 김제동 |
| NHS | 남희석 |
| SDY | 신동엽 |
| LHJ | 이휘재 |
| LKK | 이경규 |
| PSH | 박수홍 |
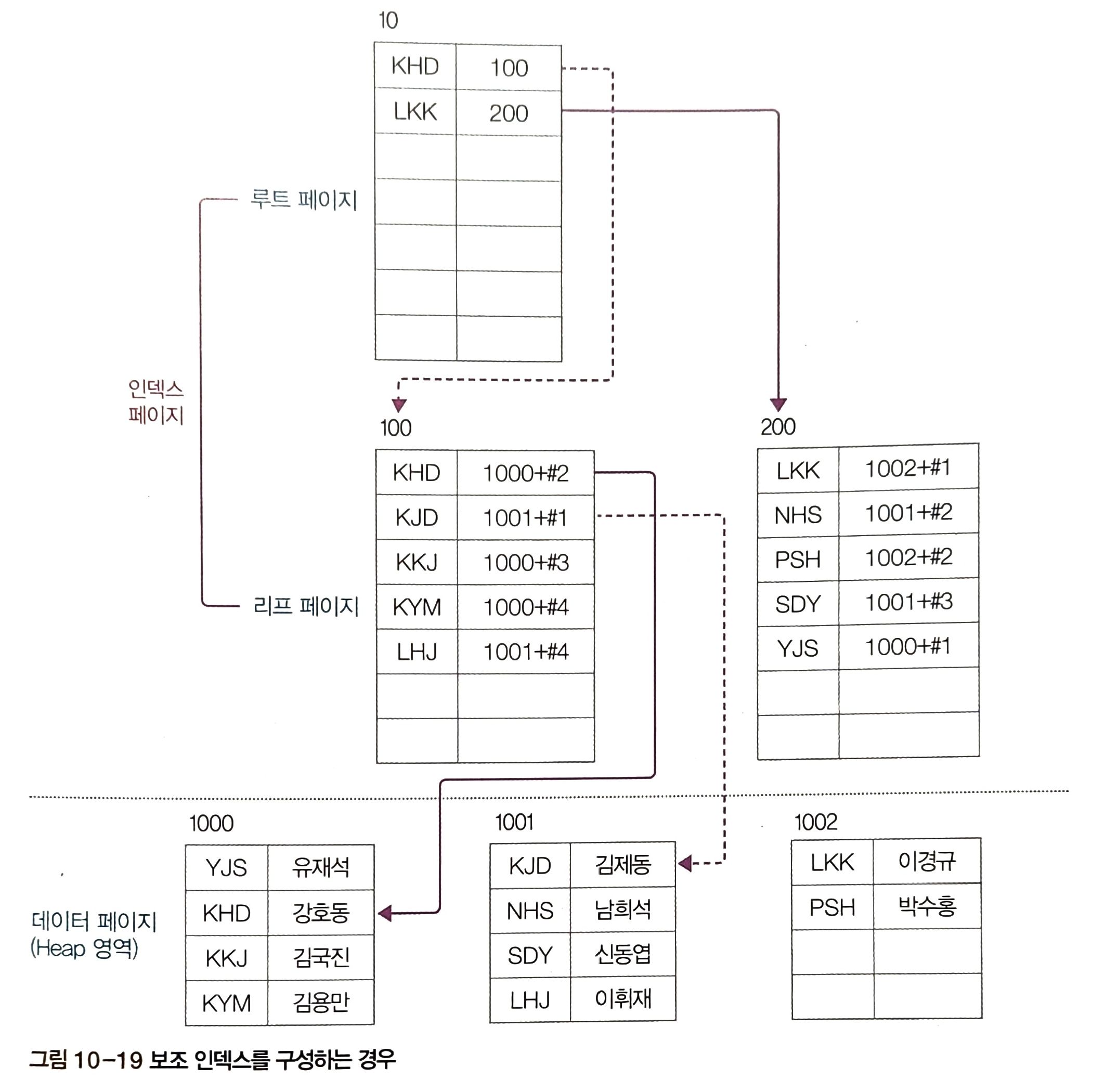
구조는 위 그림과 같습니다.
- 보조 인덱스는 데이터 페이지를 건드리지 않고 별도의 장소에 인덱스 페이지 생성
- 인덱스 페이지의 리프 페이지에 인덱스로 구성한 열을 정렬한 후 데이터 위치 포인터 생성
- 데이터 위치 포인터: 클러스터형 인덱스와 달리 주소값(페이지번호+#오프셋)을 기록해 데이터 위치 가리킴
3.2.클러스터형 인덱스와 보조 인덱스의 활용
1) 검색의 경우
클러스터형 인덱스가 보조 인덱스보다 효율적입니다.
NHS(남희석)을 검색한다고 가정,
- 클러스터형 인덱스 : 루트 페이지(100번), 리프 페이지(1001번)
- 보조 인덱스 : 루트 페이지(10번), 리프 페이지(200번), 데이터 페이지(1002번)
2) 삽입의 경우
보조 인덱스가 클러스터형 인덱스가 효율적입니다.
먼저, 클러스터형 인덱스를 살펴봅시다!
INSERT INTO clusterTBL VALUES('KKK', '크크크');
INSERT INTO clusterTBL VALUES('MMM', '마마무');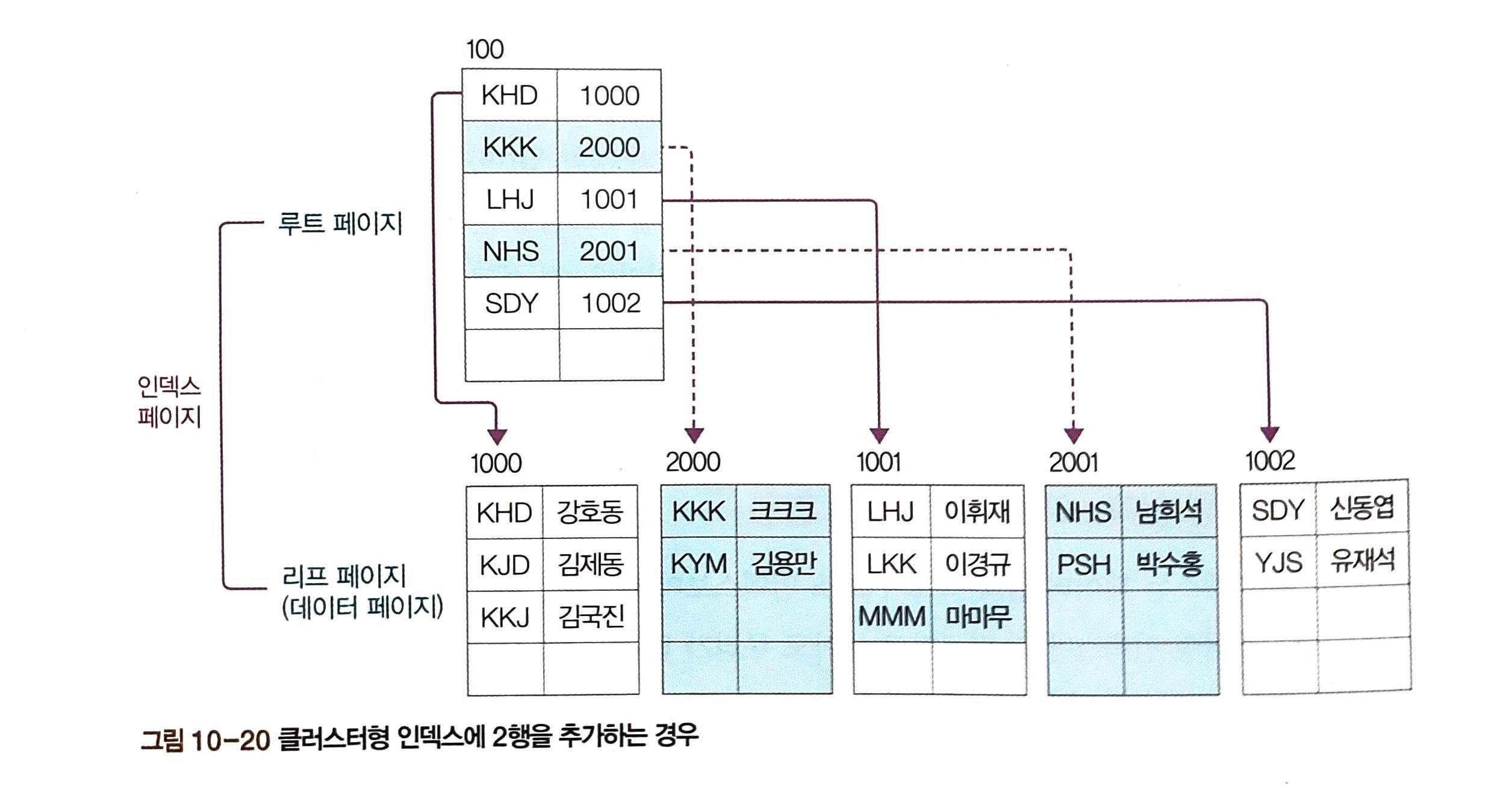
첫번째 리프페이지와 두번째 리프페이지에서 페이지 분할이 일어남. 2개 페이지가 추가로 생성되는 과정에서 많은 부하를 주어 속도 느려짐
다음은, 보조 인덱스를 살펴봅시다!
INSERT INTO secondaryTBL VALUES('KKK', '크크크');
INSERT INTO secondaryTBL VALUES('MMM', '마마무');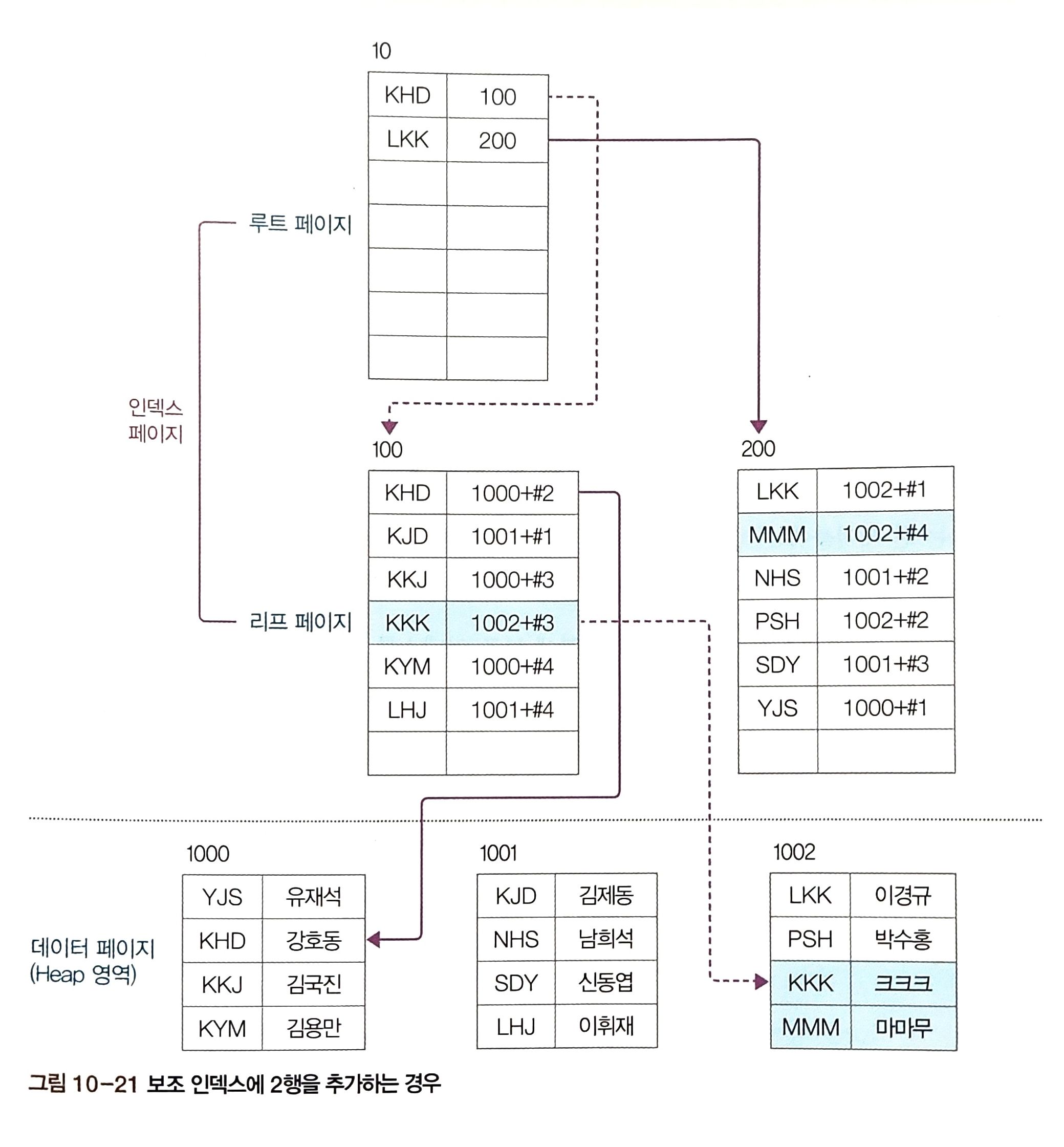
보조 인덱스는 데이터 페이지를 정렬하는 것이 아니므로 데이터 페이지의 뒤쪽 빈 부분에 데이터가 삽입. 인덱스의 리프 페이지에 약간의 순서 변경만 있고 페이지 분할은 일어나지 않음
section4 : 인덱스 생성 및 삭제
1. 인덱스 생성
인덱스 생성하는 방법
1) 테이블에 제약조건을 설정해 자동으로 생성
2) 인덱스를 생성하는 구문을 입력해 생성
- CREATE INDEX 문으로 인덱스를 만들면 보조 인덱스 생성
- CREATE INDEX 문으로는 클러스터형을 만들 수 없고 ALTER TABLE 문 사용
2. 인덱스 삭제
DROP INDEX 인덱스 이름 ON 테이블이름;- 클러스터형 인덱스를 삭제하려면 위 sql문의 인덱스 이름 부분에 PRIMARY 넣기
- 인덱스를 모두 삭제할때는 보조 인덱스부터 삭제 -> 클러스터형 인덱스부터 삭제하는것보다 더 빨리 삭제
3. 인덱스 생성하고 활용을 실습을 통해 알아봅시다!
1. cookDB 초기화
2. 인덱스 생성하고 활용
SHOW INDEX FROM userTBL;| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation |
|---|---|---|---|---|---|
| usertbl | 0 | PRIMARY | 1 | userID | A |
- key_name의 PRIMARY 는 클러스터형 인텍스 의미
- 현재 회원테이블에는 userID 열에 클러스터형 인덱스 하나만 설정돼 있음
- 이 테이블에는 더 이상 클러스터형 인덱스 생성 불가
CREATE INDEX idx_userTBL_addr
ON userTBL (addr);
SHOW INDEX FROM userTBL;| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation |
|---|---|---|---|---|---|
| usertbl | 0 | PRIMARY | 1 | userID | A |
| usertbl | 1 | idx_userTBL_addr | 1 | addr | A |
- 주소 열에 단순 보조 인덱스를 생성함
- 여기서 단순 = 중복을 허용한다는 의미
- Non_unique 가 1로 설정되어 있는데, 이는 UNIQUE 옵션이 설정된 인덱스가 아니라는 의미
CREATE UNIQUE INDEX idx_userTBL_userName
ON userTBL (userName);
SHOW INDEX FROM userTBL;| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation |
|---|---|---|---|---|---|
| usertbl | 0 | PRIMARY | 1 | userID | A |
| usertbl | 0 | idx_userTBL_userName | 1 | userName | A |
| usertbl | 1 | idx_userTBL_addr | 1 | addr | A |
- 이름(userName)열에 고유 보조 인덱스를 생성하면 문제없이 생성됨
- 하지만!!!! 예를들어 강호동과 이름이 같되 아이디가 GHD인 회원을 삽입한다면, 중복되는 값을 입력할 수 없게 된다.
INSERT INTO userTBL VALUES('GHD', '강호동', 1988, '미국', NULL , NULL , 172, NULL);Error Code : Duplicate entry '강호동' for key 'idx_userTBL_userName'
따라서 이렇게 이름이 중복되는 경우를 허용하지 않는다면 문제가 될 수 있기 때문에 고유 인덱스는 현재 중복되는 값이 없다고 무조건 설정하면 안됨.
절대 중복 허용하지 않는(주민등록번호,학번)등에만 UNIQUE 옵션 사용하기
3. 인덱스 삭제하기
- 보조 인덱스를 삭제하는 두가지 방법
1) DROP
DROP INDEX idx_userTBL_addr ON userTBL;
DROP INDEX idx_userTBL_userName_birthYear ON userTBL;
DROP INDEX idx_userTBL_mobile1 ON userTBL;
2) ALTER
ALTER TABLE userTBL DROP INDEX idx_userTBL_addr;
ALTER TABLE userTBL DROP INDEX idx_userTBL_userName_birthYear;
ALTER TABLE userTBL DROP INDEX idx_userTBL_mobile1;- 클러스터형 인덱스를 삭제하는 방법
ALTER TABLE userTBL DROP PRIMARY KEY;section5 : 인덱스 생성 기준
- 인덱스는 열단위에 생성
- 인덱스는 WHERE절에서 사용되는 열에 만듦
ex)SELECT userName, birthYear, add FROM userTBL WHERE userID='KHD'sql문을 보면, 이름,출생연도 등에 인덱스를 생성해도 전혀 사용할일이 없음->WHERE절에 있는 userID에만 인덱스 생성할 필요가 있음 - WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있음
- 데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없음
ex) gender와 같은 열은 거의 같은 데이터가 있음->성능향상효과를 보지 못함 - 외래키를 설정한 열에는 자동으로 외래키 인덱스 생성
- 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음
- 데이터 변경(삽입,수정,삭제) 작업이 얼마나 자주 일어나는지 고려
=> 인덱스는 검색할때만 시스템의 성능을 향상하고 데이터변경작업을 할때는 성능 떨어뜨림 - 클러스터형 인덱스는 테이블당 하나!
- 테이블에 클러스터형 인덱스가 아예 없는 것이 좋은 경우도 있음
- 사용하지 않는 인덱스는 제거
=> 인덱스 제거하면,, 추가공간 확보+데이터 삽입할때 발생하는 부하 줄임
중간 Question
질문 1
LIKE 검색 시 % 를 붙이게 되면, 인덱스를 참조하지 못하나요?
%단어%, %단어, 단어%
이유는 값이 무엇인지 모른다면 인덱스를 참조하는 것이 불가능하기 때문
테이블 풀 스캔이 진행됨질문 2
인덱스를 사용했을 때 효율이 좋은 기준은 무엇인가요?
전체 테이블의 15% 이내
12-2장
section 2
1. 파티션의 개요
파티션
대량의 데이터를 한 테이블에 저장할 때 그 내용을 물리적으로 별도의 테이블에 분리해서 저장하는 기법
파티션을 사용하는 이유는?
몇 개의 파티션으로 분리되었든 사용자 입장에서는 하나의 테이블로 보이기 때문에 테이블 사용법은 동일.
MySQL 내부적으로 데이터가 분리되어 처리하기 때문에 시스템 성능 향상
EXAMPLE> 수십억건의 테이블에 쿼리를 수행한다고 가정,
- 하나의 테이블을 10개의 파티션으로 나누어 저장하면 부담이 1/10 로 줄어들수 있음
- 테이블 행 데이터가 많은 경우 삽입,수정 등의 작업이 많을수록 느려질 수 밖에 없는데 이에 대한 시스템 성능이 향상
MySQL은 최대 8192개의 파티션을 지원
2. 파티션 구현
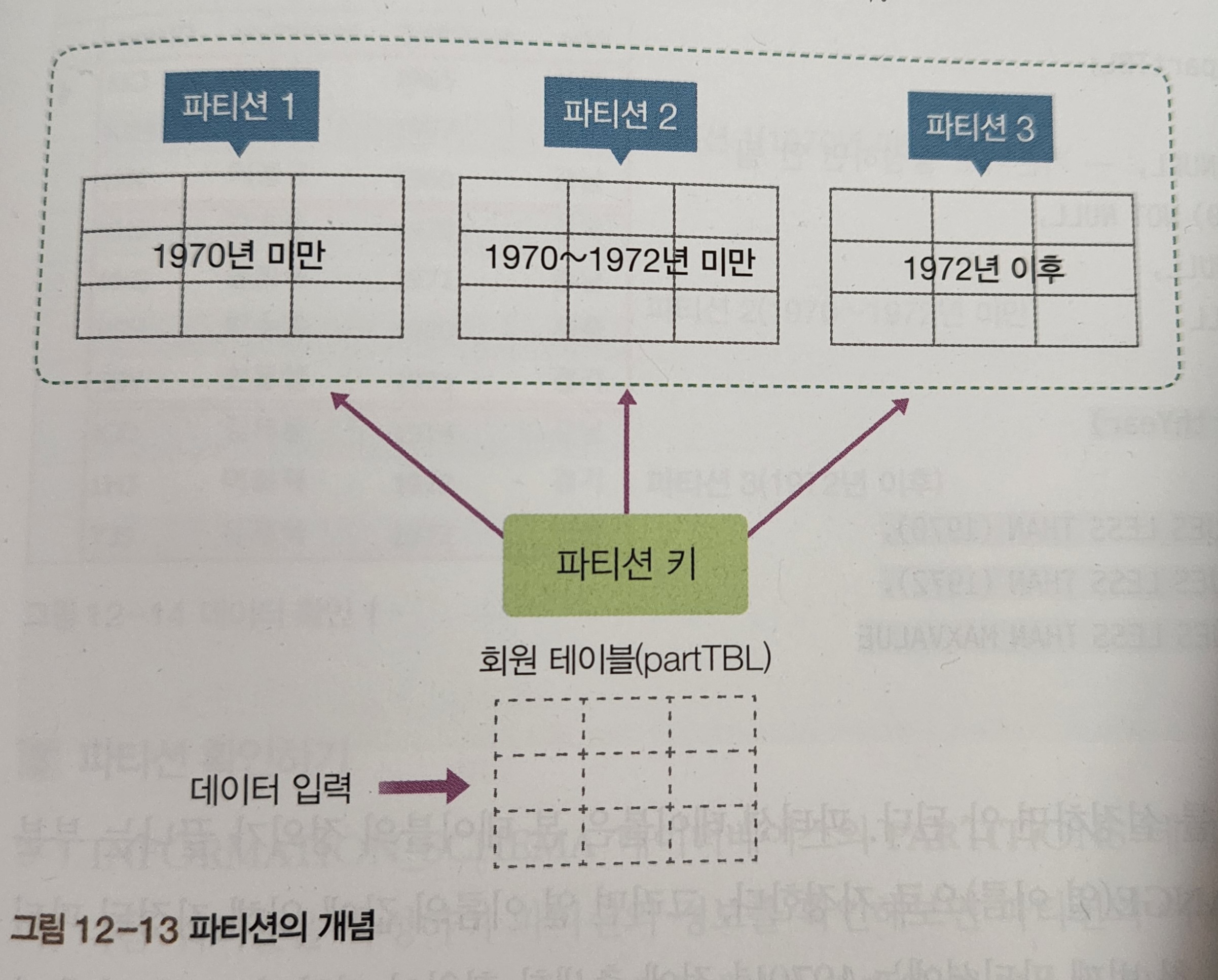
- 출생연도별로 3개의 파티션으로 구분한 것
- 테이블을 생성하면서 파티션 키를 함께 지정하면 데이터를 입력할 때 지정된 파티션 키에 의해 데이터가 각각의 파이션에 입력
- 사용자는 테이블 하나에만 접근한다고 생각(파티션이 나뉘어지는 것에 대해 신경쓰지 x)
실습을 통해 파티션을 구현해봅시다!
- cookDB초기화
- 파티션으로 분리되는 테이블 생성
CREATE DATABASE IF NOT EXISTS partDB;
USE partDB;
DROP TABLE IF EXISTS partTBL;
CREATE TABLE partTBL (
userID CHAR(8) NOT NULL, -- Primary Key로 지정하면 안됨
userName VARCHAR(10) NOT NULL,
birthYear INT NOT NULL,
addr CHAR(2) NOT NULL )
PARTITION BY RANGE(birthYear) (
PARTITION part1 VALUES LESS THAN (1970),
PARTITION part2 VALUES LESS THAN (1972),
PARTITION part3 VALUES LESS THAN MAXVALUE
);part1 : 1970년 이전에 출생한 회원 저장
part2 : 1970-1971 출생한 회원 저장
part3 : 1972년 이후에 출생한 회원 저장
파티션 테이블에는 기본키를 설정하면 안됨!!
WHY?
파티션 테이블에 기본키를 설정하면 그 열로 정렬이 되기 때문에 기본키를 설정하면 안됩니다.
위의 정의된 파티션에 cookDB 데이터를 삽입하고 조회해봅니다.
INSERT INTO partTBL
SELECT userID, userName, birthYear, addr FROM cookDB.userTBL;SELECT * FROM partTBL;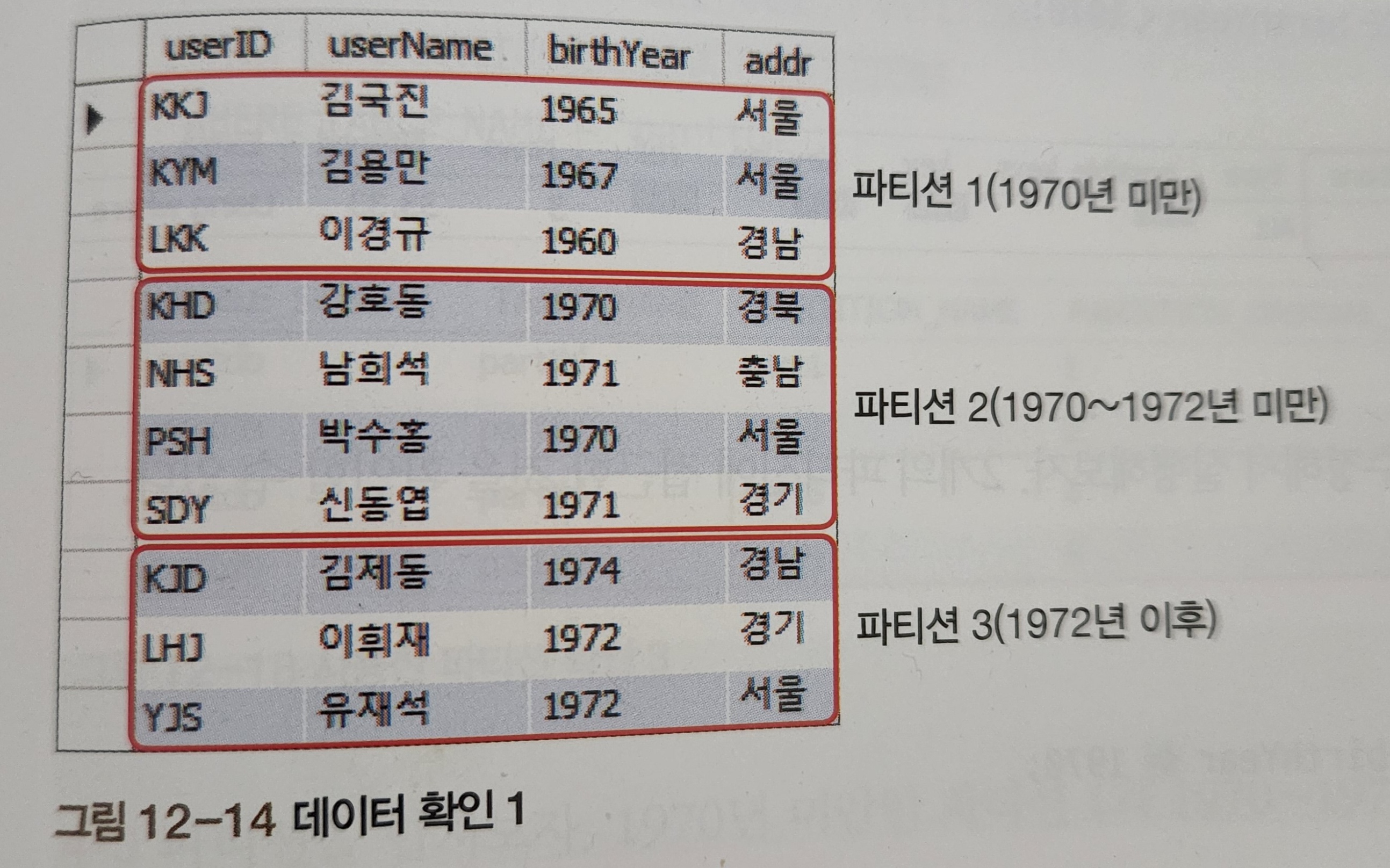
- 파티션 확인하기
INFORMATION_SCHEMA 데이터베이스에 PARTITIONS 테이블에 관련 정보 있음
위에서 작성한 PARTTBL 을 조회해봅시다.
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_ORDINAL_POSITION, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'parttbl';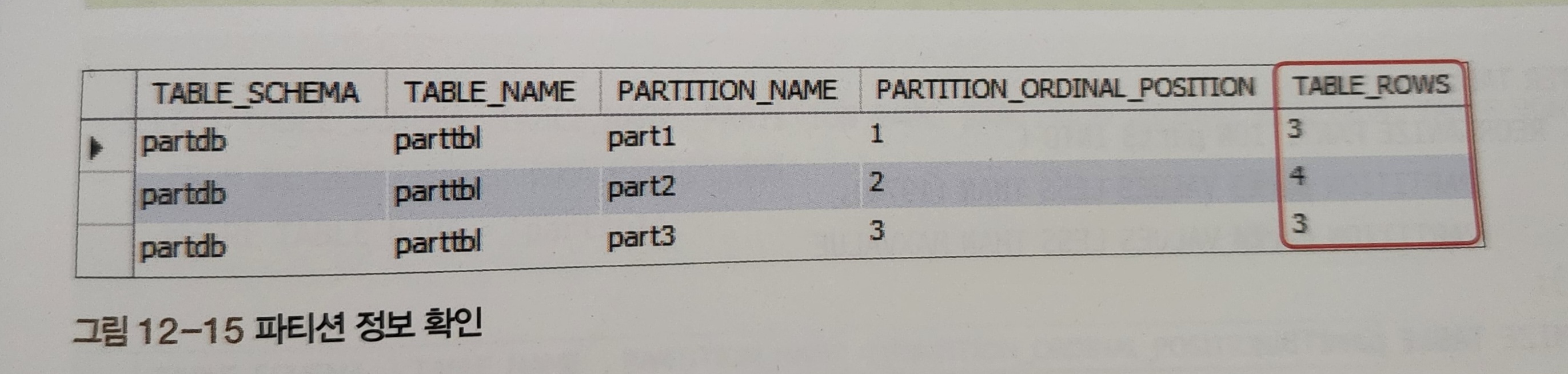
SELECT * FROM partTBL WHERE birthYear < 1970 ;위의 sql문으로 1970년 이전에 출생한 회원을 조회하게 된다면, 파티션2와 파티션3에는 접근조차하지 않고 효율적으로 조회하는 것이 가능합니다!
EXPLAN
SELECT * FROM partTBL WHERE birthYear < 1970 ;동일한 sql문 앞에 EXPLAN 만 붙여주게 된다면 어떤 파티션에 접근했는지도 알려줍니다. 예상대로 part1 에만 접근했습니다.
- 파티션 관리하기
1) 파티션을 재구성 해봅시다!
ALTER TABLE partTBL
REORGANIZE PARTITION part3 INTO (
PARTITION part3 VALUES LESS THAN (1974),
PARTITION part4 VALUES LESS THAN MAXVALUE
);
OPTIMIZE TABLE partTBL;원래의 파티션 3을 1972~1974 와 1974 이후 로 분리하여 재구성하려고 한다면, 위와 같은 sql 문을 작성하면 됩니다.
분리 : ALTER TABLE~REORGANIZE PARTITION
재구성 : OPTIMIZE TABLE
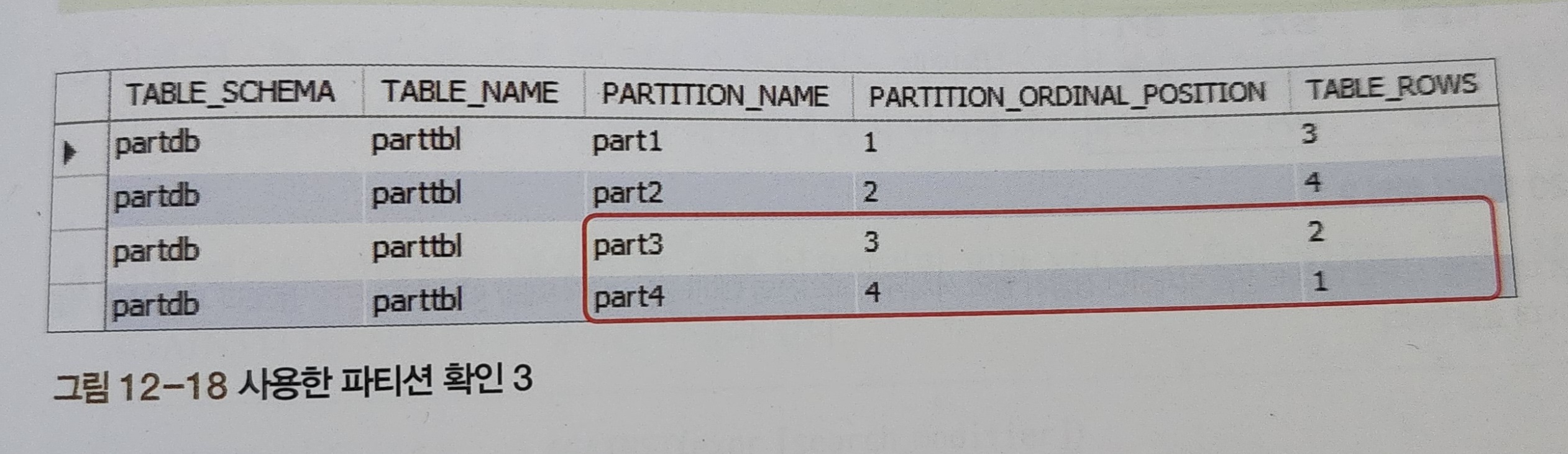
2) 파티션을 합쳐 봅시다!
ALTER TABLE partTBL
REORGANIZE PARTITION part1, part2 INTO (
PARTITION part12 VALUES LESS THAN (1972)
);
OPTIMIZE TABLE partTBL;원래의 파티션 1과 파티션 2를 합쳐 1972년 미만 파티션 12로 재구성해본다면,
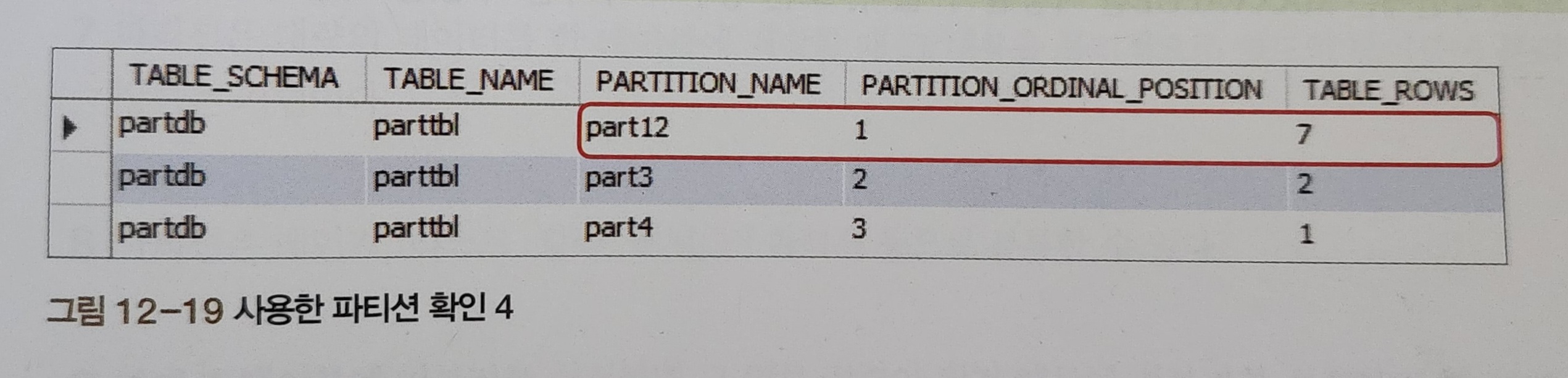
결과는 위와 같습니다.
3) 파티션을 삭제해 봅시다!
ALTER TABLE partTBL DROP PARTITION part12;
OPTIMIZE TABLE partTBL;
SELECT * FROM partTBL;파티션12를 삭제하게 되면 파티션과 함께 해당하는 데이터가 모두 삭제됩니다. 따라서 part3, part4 만 남게 됩니다.
3. 파티션의 제한 사항
- 파티션 테이블에는 외래키 설정 할 수 없음
- 임시 테이블에는 파티션 기능 사용 불가
- 스토어드 프로시저, 스토어드 함수, 사용자 변수 등을 파티션 함수에 적용 불가
- 파티션 키에는 일부 함수만 사용가능
인덱스와 파티션에 대한 공부를 마무리하며,,
최종 정리
인덱스와 파티션 모두 속도와 성능향상
💡 차이점?
인덱스 : 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
파티셔닝 : 데이터베이스 분할 또는 파티셔닝은 데이터베이스를 여러 부분으로 분할하는 튜닝기법
- 하나의 테이블이 너무 커서 인덱스의 크기가 물리적인 메모리보다 훨씬 크거나, 데이터 특성상 주기적인 삭제 작업이 필요한 경우 등이 파티션이 필요
- 파티션은 데이터와 인덱스를 조각화해서 물리적 메모리를 효율적으로 사용할 수 있게 만들어 줌
- 테이블 파티셔닝에서 사용하는 인덱스의 종류
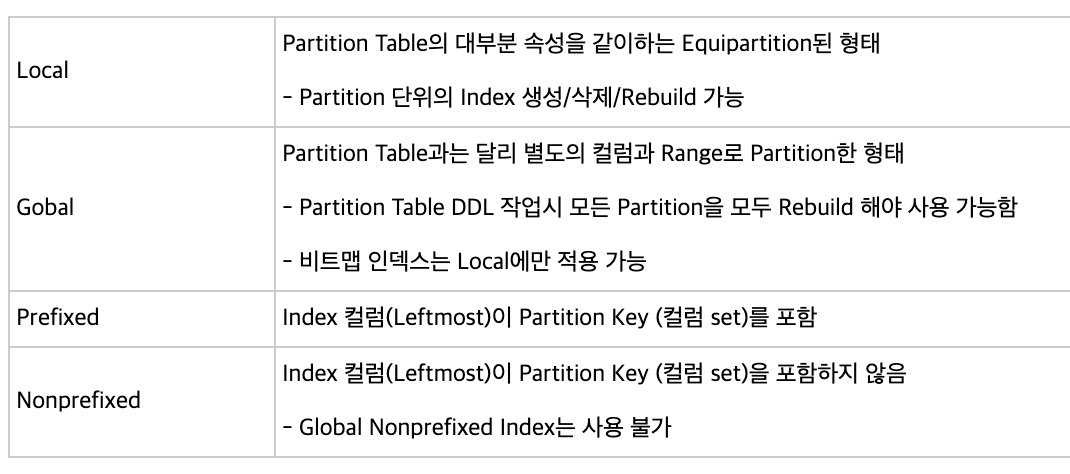
참고링크

2개의 댓글
# 왜 공부했는데도 까먹나요?
DDL인 DROP문은 테이블 자체를 삭제하고 트랜잭션 로그를 기록하지 않음
DDL인 TRUNCATE문은 DELETE문과 결과 동일하지만 트랜잭션 로그를 기록하지 않음
리뷰 피드백
%단어%, %단어, 단어%
이유는 값이 무엇인지 모른다면 인덱스를 참조하는 것이 불가능하기 때문
(%단어%, %단어 -> 인덱스 참조 불가능 값을 모르기 때문 / 단어% -> 인덱스 참조 가능 처음값을 알기 때문)