1. 클러스터 와 샤딩
DBMS 서버 의 물리적인 분산 이라고 생각.
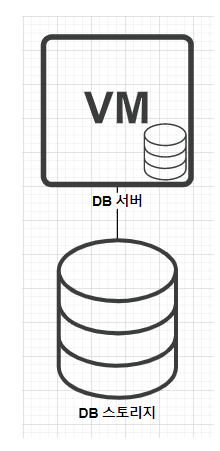 위 그림은 가장 기본적인 DB 구조이다. 이 구성에서 DB 서버가 죽게되면 서비스 전체가 중단된다.
위 그림은 가장 기본적인 DB 구조이다. 이 구성에서 DB 서버가 죽게되면 서비스 전체가 중단된다.
1) 클러스터링(active-active)
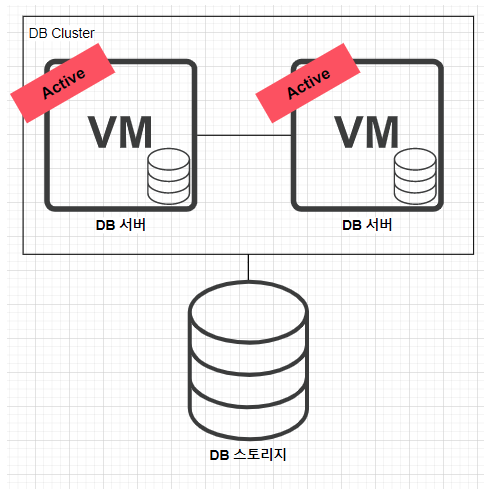 따라서 이에 대한 가장 간단한 방안은 위 그림에서 볼 수 있듯 DB 클러스터링이다.
따라서 이에 대한 가장 간단한 방안은 위 그림에서 볼 수 있듯 DB 클러스터링이다.
장점은 아래와 같으며
(고가용성) 동일한 DB 서버를 두 대를 묶고 두 DB 서버를 Active-Active 상태로 운영하면, 하나의 DB 서버가 죽더라도 나머지 DB 서버가 살아있기 때문에 정상적으로 서비스가 가능하고,
(부하분산) 서버 부하를 두 개의 DB가 나눠서 감당하므로 CPU, Memory 자원의 부하도 적어지게 된다.
단점은 아래와 같다.
(스토리지 병목) DB 스토리지를 두 DB 서버가 공유하기 때문에 병목이 생길 수가 있다는 점과 이전보다 많은 비용이 투자되어야 한다는 점
스토리지 병목 현상?
스토리지 병목 현상은 스토리지 시스템에서 발생하는 병목 현상 상황입니다. 병목 현상은 시스템 성능에 심각한 영향을 미쳐 응용 프로그램 충돌을 일으킬 수 있습니다.
2) 클러스터링(active-standby)
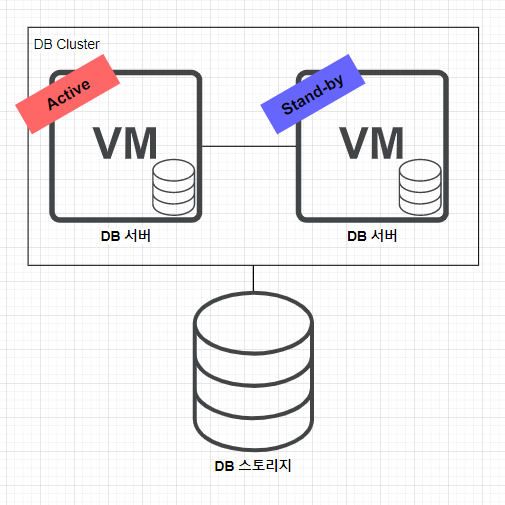
클러스터링(active-active)의 단점을 보완하기 위해 DB 서버 중 한대를 standby 서버로 사용할 수 있다.
장점은, active 상태의 DB 서버에서 문제가 발생하면 fail over 를 통해 장애를 대응할 수 있다는 점이며, 클러스터링(active-active) 일때의 DB 스토리지 병목 현상이 해결된다.
단점은, fail over 발생하는 수초~수분 시간 동안 영업 손실이 필연적으로 발생하고 DB 서버 2대를 구비해야하기 때문에 비용적인 측면에서 비효율적이다.
또한, 클러스터링 전체의 단점으로는 DB 스토리지를 하나만 두는 것에 대한 위험성이 있다. DB 스토리지에 문제가 생기면 데이터를 복구 할 수 없게 되기 때문이다.
3) 리플리케이션
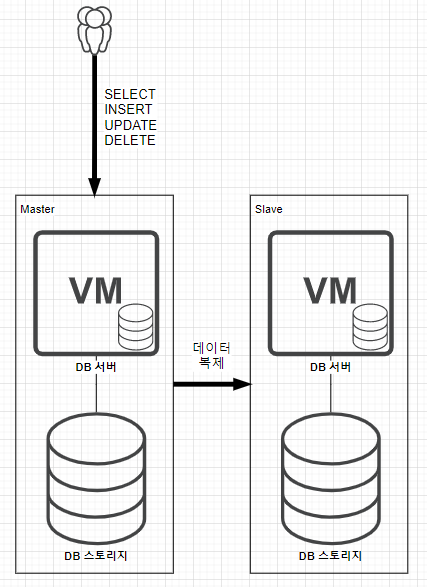
클러스터링의 단점을 보완하기 위해 나온 것이 리플리케이션이다.
DB서버&DB스토리지 두쌍으로 만들기
사용자는 마스터 DB 서버에 DML(SELECT/INSERT/UPDATE/DELETE) 작업을 하면 Master DB는 그 데이터를 Slave 쪽에 데이터 복제를 한다.
이를 통해 DB 스토리지가 한 대여서 발생 할 수 있는 데이터 손실을 방지할 수 있다.
하지만 단점은, slave 서버가 놀게된다는 점이다.
4) 리플리케이션(부하분산용)
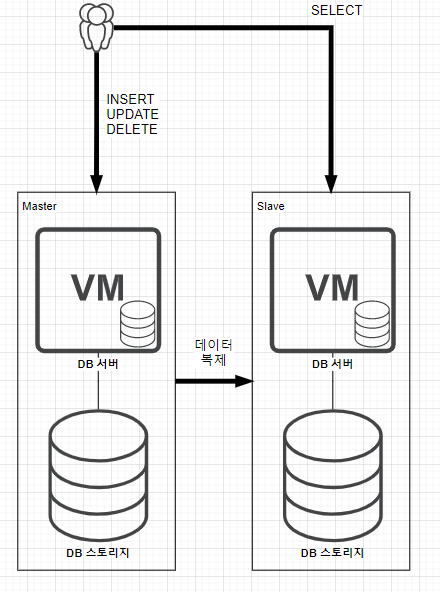
해당 구조에서는 Master DB 서버에는 INSERT, UPDATE, DELETE 작업을 하고 Slave DB 서버에는 SELECT를 함으로써 양 DB 서버에 부하를 분산할 수 있다.
단점은, 테이블에 데이터 자체가 아주 많다면 slave DB 서버를 늘려도 원하는 데이터를 찾는데에 많은 시간이 소요될 것이다.
리플리케이션(이중화) 집중공부 ✏️
리플리케이션, 즉 이중화는 스토리지를 공유하여 고가용성을 실현하는 방식이 아니라, 네트워크를 통해서 DB가 소유한 각각의 스토리지에 데이터를 동기화(복제)하는 방식!
이중화는 "SHARED NOTHING ARCHITECTURE"에 기반을 둔 기술인데, 이름 그대로 공유하는 자원 없이 고가용성(High Availability / HA)을 구현하기 위한 아키텍처!
이중화 장점 : 디스크를 공유하지 않고 데이터를 네트워크를 통해서 복제하기 때문에 성능이 빠른 장점을 가지고 있음
이중화 단점 : 네트워크 복제의 특성상 노드간의 데이터 불일치 현상이 발생할 수 있음!
이중화 목적 : 고가용성 확보, 부하분산, 장애 시 데이터손실 최소화
5) 샤딩
리플리케이션읟 단점을 보완하는 것이 샤딩이다.
샤딩은 테이블을 특정 기준으로 나눠서 저장 및 검색하는 것을 말하는데, 샤딩의 핵심은 Data를 어떻게 잘 분산 시켜 저장할 것인지, 그리고 어떻게 잘 읽을 것인지에 대한 결정이다.
샤딩, 정말 써도 될까?
2. 파티셔닝
DBMS 내 데이터의 논리적인 분산 이라고 생각.
파티셔닝이란 개념은 데이터베이스를 여러 부분으로 분할하는 것이다. 큰 테이블이나 인덱스를 작은 파티션(Partition) 단위로 나누어 관리하는 기법을 뜻한다.
파티셔닝이 나오게 된 배경은 이렇다. 하나의 DBMS에 너무 큰 테이블이 들어가면서 용량과 성능 측면에서 많은 이슈가 발생하게 되었기 때문에 이를 파티션이라는 작은 단위로 나누어 관리하며 성능 개선을 하게되었다.
파티셔닝의 목적은 크게 3가지로,
1. 첫번째 성능. 쿼리성능을 높일수 있고, 필요한 데이터만 조회하기 때문에 빠르며 full scan 에서의 데이터 접근 범위를 줄일 수 있다.
2. 두번째 가용성. 장애 상황에서 전체 데이터의 훼손 가능성이 줄고 데이터 가용성이 향상된다. 파티션별로 독립적 백업/복구 가능.
3. 세번째 관리용이성. 큰 테이블을 제거해서 관리를 용이하게 한다.
파티셔닝 종류는 2가지로,
1. 수평 파티셔닝 : 하나의 테이블의 각 행을 다른 테이블에 분산시키는 것
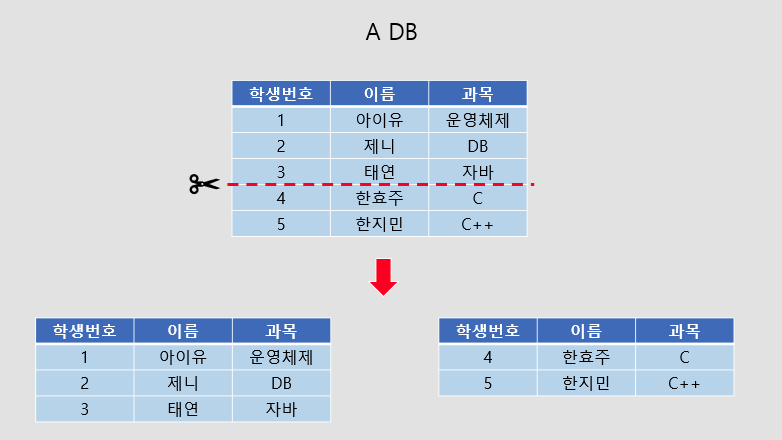
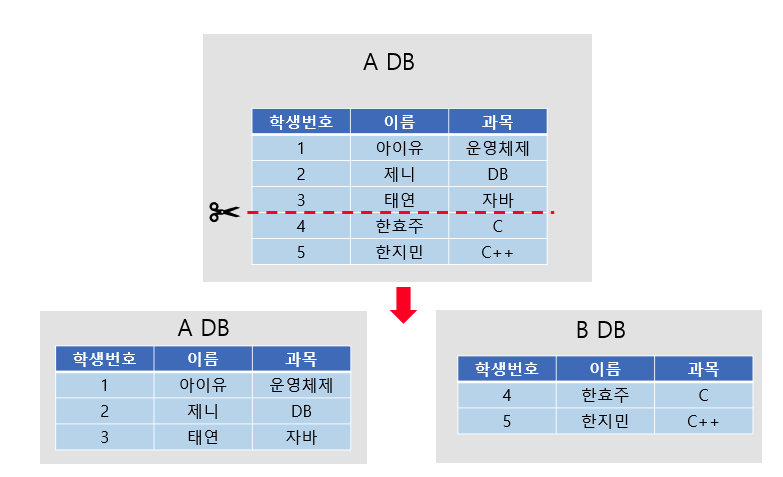
수평 파티셔닝과 샤딩의 차이점
파티셔닝은 같은 데이터베이스 내에서 하나의 큰 테이블을 쪼개 분산 저장하는 기법
<->
샤딩은 하나의 큰 테이블을 쪼개 각각 다른 데이터베이스에 분산 저장하는 기법
따라서 샤딩은 수평 파티셔닝의 장점을 모두 갖지만, 데이터베이스 서버 간의 연결 과정이 많아져 비용이 증가할 수 있다. 또한 하나의 서버가 고장 나면 데이터의 무결성이 깨질 수 있다는 단점도 있다.
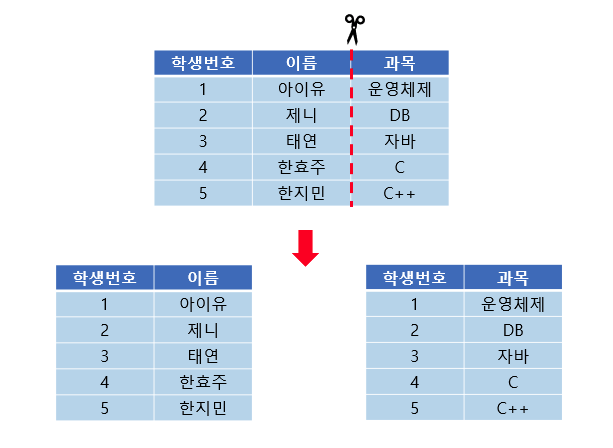
- 수직 파티셔닝 : 테이블의 일부 열을 빼내는 형태로 분할. 즉, 테이블의 칼럼을 기준으로 나누어 파티셔닝 하는것
파티셔닝을 하게 되면 성능이 향상되지만 데이터를 찾는 과정이 기존보다 복잡하므로 응답시간이 증가하게 된다.
참고링크)
