2.3 장
개념적인 튜닝 용어
1) 기초 용어
2) 응용 용어
개념적인 튜닝 용어
기초 용어
오브젝트 스캔 유형
- 테이블 스캔 : 인덱스 거치지 않고 바로 디스크에 위치한 테이블 데이터에 접근
- 테이블 풀 스캔- 인덱스 스캔 : 인덱스로 테이블 데이터에 접근
- 인덱스 범위 스캔/인덱스 풀 스캔/인덱스 고유 스캔/인덱스 루스 스캔/인덱스 병합 스캔
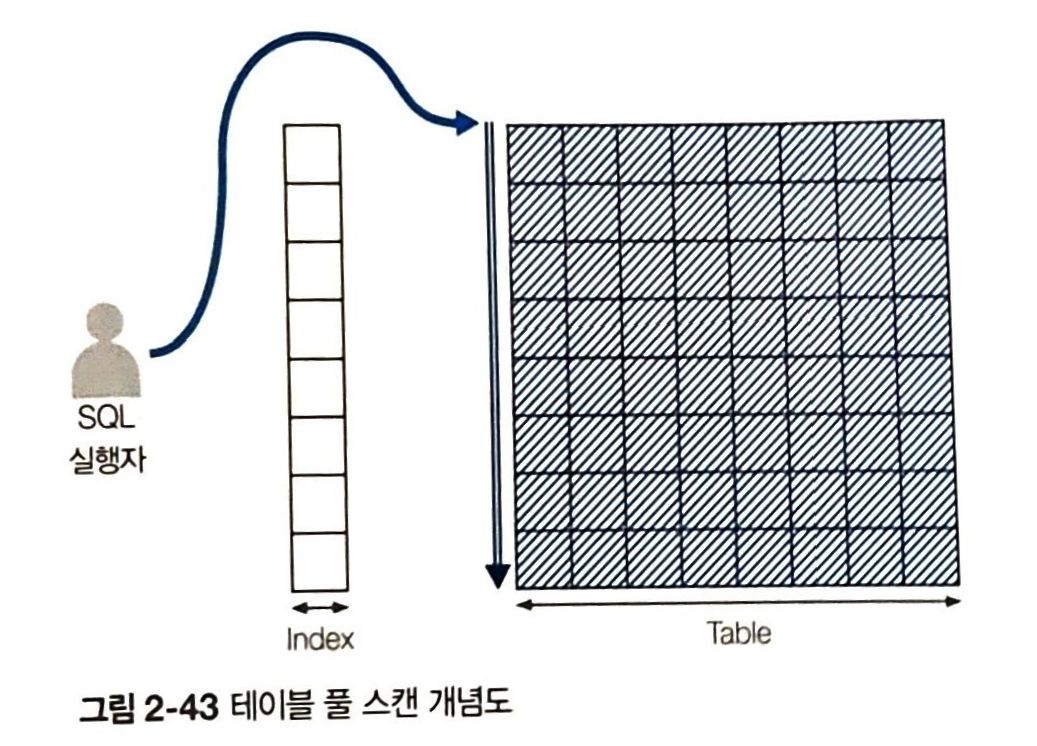
1) 테이블 풀 스캔
- 인덱스 거치지 않고 테이블로 직행해서 처음부터 끝까지 데이터 훑어보는 방식
- where 절의 조건문을 기준으로 활용할 인덱스 없을 경우
- 전체 데이터 대비 대량의 데이터가 필요할 경우
- 성능 측면에서 부정적
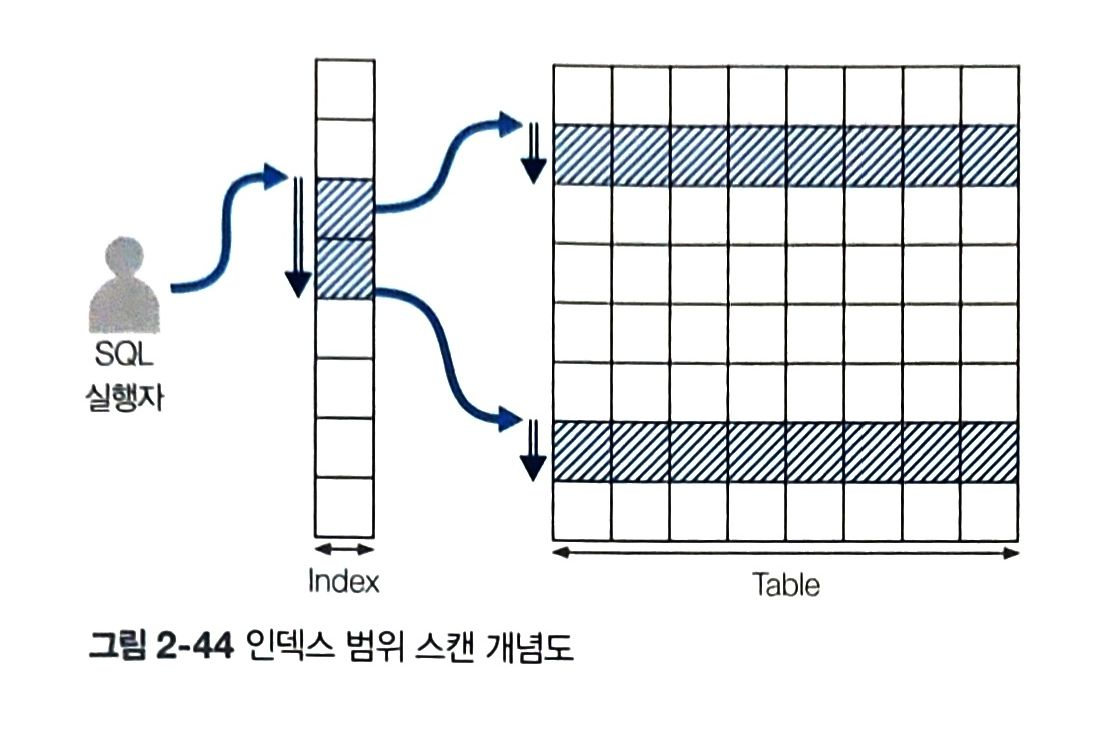
2) 인덱스 범위 스캔
- 인덱스 범위 기준으로 스캔 후, 스캔 결과를 토대로 테이블의 데이터 찾아가는 방식
- between~and, <, >, like 등의 비교연산 및 구문에 포함될 경우
- 좁은 범위 스캔 시 효율
- 넓은 범위 스캔 시 비효율
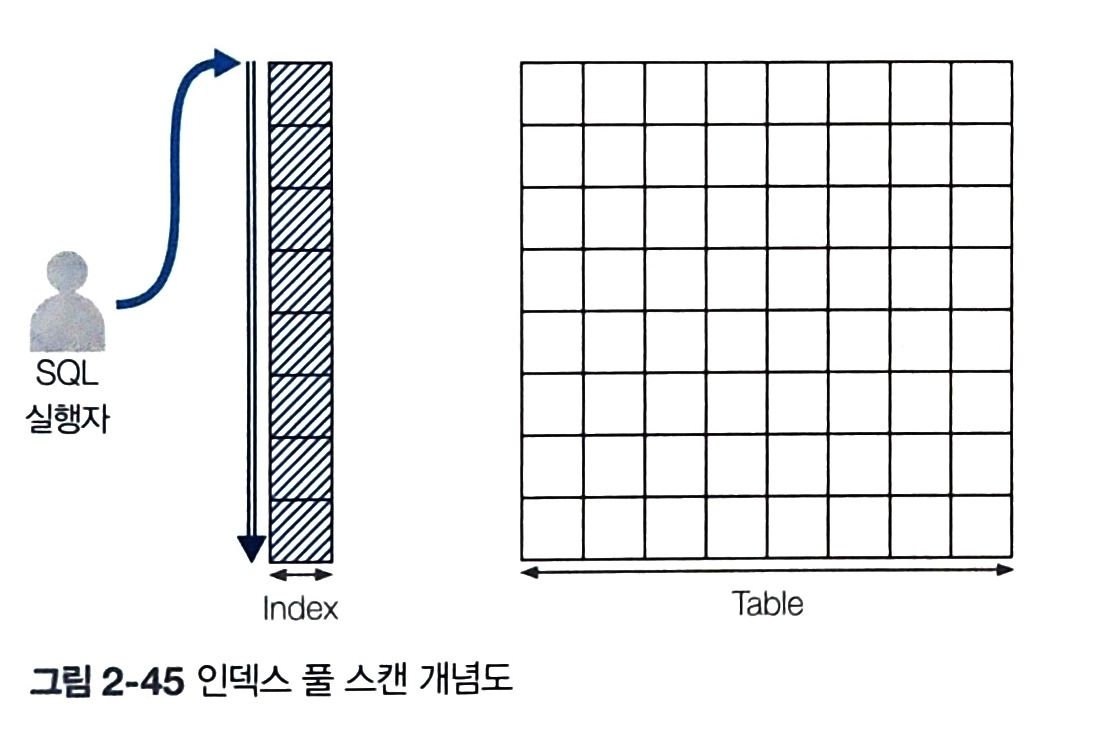
3) 인덱스 풀 스캔
- 인덱스를 처음부터 끝까지 수행하는 방식. 단, 테이블에 접근하지 않고 인덱스로 구성된 열 정보만 요구하는 SQL문에서 인덱스 풀스캔 수행
- 성능유리 : 인덱스 풀 스캔 > 테이블 풀 스캔
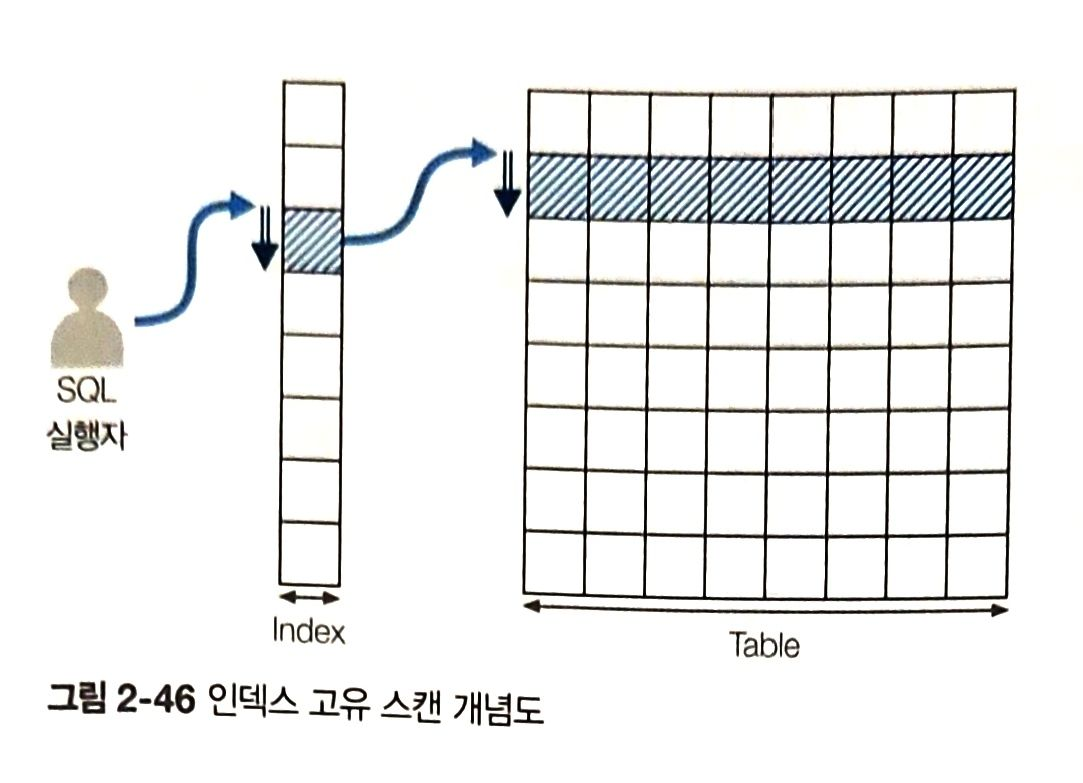
4) 인덱스 고유 스캔
- 기본 키, 고유 인덱스로 테이블 접근하는 방식
- 인덱스를 사용하는 스캔 방식 중 가장 효율적인 스캔 방식
- where 절에 = 조건으로 작성
- 해당 조인 열이 기본키,고유 인덱스의 선두 열로 선정되었을때 활용
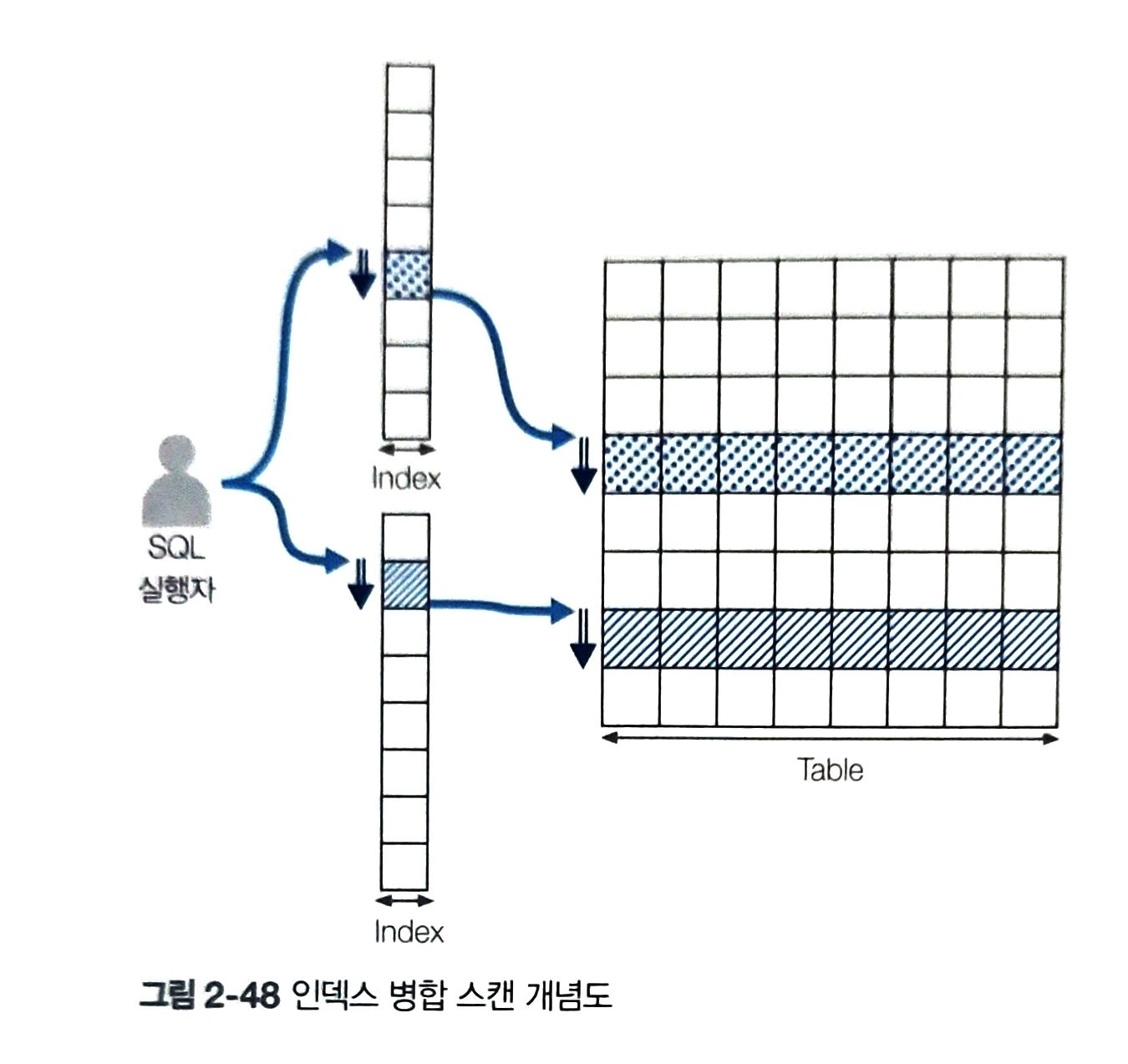
5) 인덱스 루스 스캔
- 인덱스 필요부분만 골라 스캔하는 방식
- 인덱스 범위 스캔처럼 넓은 범위에 전부 접근하는 것이 X
- where 절 조건문 기준으로 필요한 데이터와 필요하지 않은 데이터 구분한 뒤 불필요한 인덱스 키는 무시
- GROUP BY, MAX(), MIN() 함수 포함되면 작동
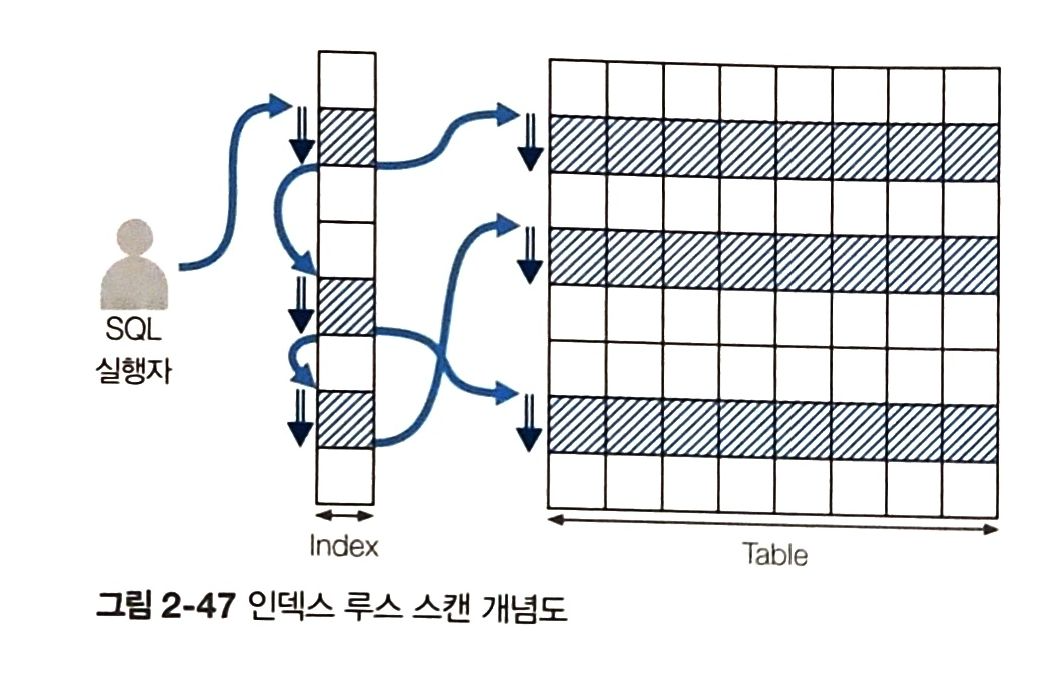
6) 인덱스 병합 스캔
- 테이블 내에 생성된 인덱스들을 통합해서 스캔하는 방식
- where 문 조건절의 열들이 서로 다른 인덱스로 존재하면 옵티마이저가 해당하는 인덱스를 가져와서 모두 활용하는 방식
- 통합하는 방법 : 결합/교차 -> 이들은 모두 실행계획으로 출력됨
디스크 접근 방식
데이터 검색을 위해 저장된 스토리지의 페이지(데이터를 검색하는 최소 단위로, 페이지 단위로 데이터 R/W 가능)에 접근
- 시퀀셜 액섹스 : 서로 연결된 페이지를 차례로 읽음
- 랜덤 액세스 : 여기저기 원하는 페이지를 임의로 열어보면서 데이터 읽음
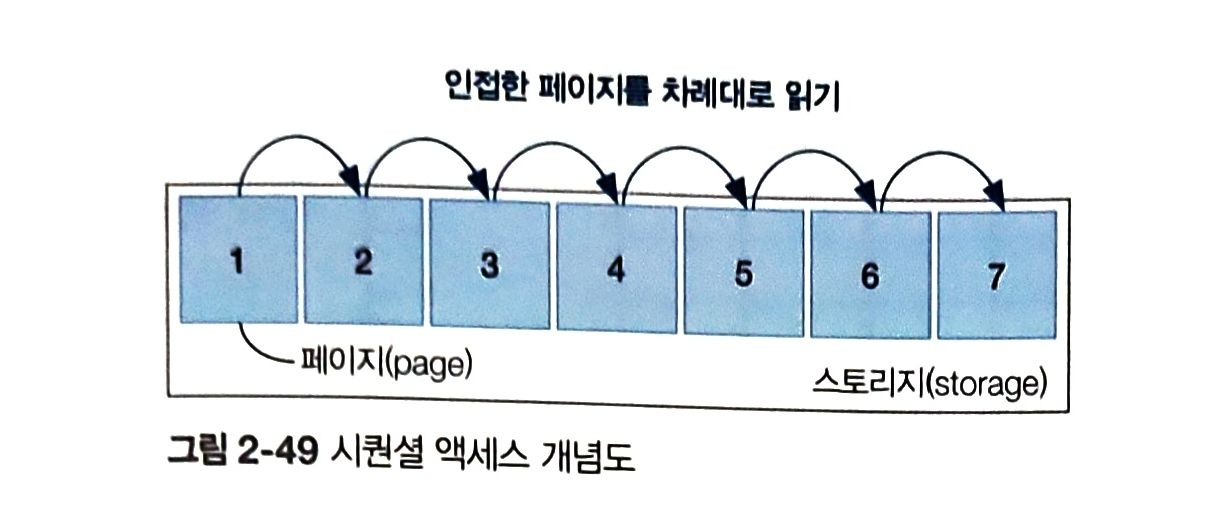
1) 시퀀셜 액세스
- 물리적으로 인접한 페이지를 차례대로 읽는 순차 접근 방식
- 테이블 풀 스캔에서 활용 ( 이때는 인접한 페이지를 여러 개 읽는 다중 페이지 읽기 방식 수행 )
- 데이터를 찾고자 이동하는 디스크 헤더의 움직임을 최소화->작업시간,리소스 점유 비용 줄임
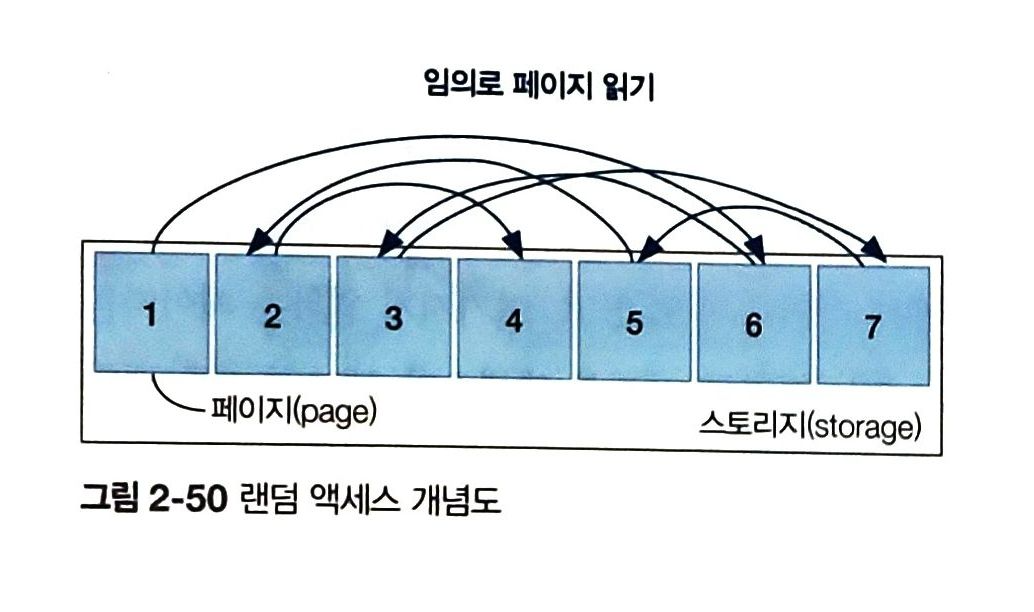
2) 랜덤 액세스
- 물리적으로 떨어진 페이지들에 임의로 접근하는 임의 접근 방식
- 페이지가 위치한 물리적인 위치를 고려하지 않고 접근
- 디스크 헤더가 정해진 순서 없이 이동하는 만큼 데이터 접근 수행 시간 오래 걸림
- 최소한의 페이지에 접근할 수 있도록 접근 범위 줄이고 효율적 인덱스를 활용할 수 있도록 튜닝해야함
조건 유형
where 조건문 기분으로 데이터가 저장된 디스크에 접근
=> 이때 필요한 데이터에 액세스하는 조건문으로 데이터 가져옴 (액세스 조건)
=> 가져온 데이터에서 다시 한번 출력할 데이터만 추출 (필터 조건)
1) 액세스 조건
디스크에 어떻게 접근할 것인지를 다루는 액세스 조건
< 옵티마이저 역할 >
- where 절의 특정 조건문을 이용해 소량의 데이터 가져옴
- 인덱스 통해 시간 낭비 줄이는 조건절 선택
- 스토리지 엔진의 데이터에 접근
- MySQL 엔진으로 데이터 가져옴
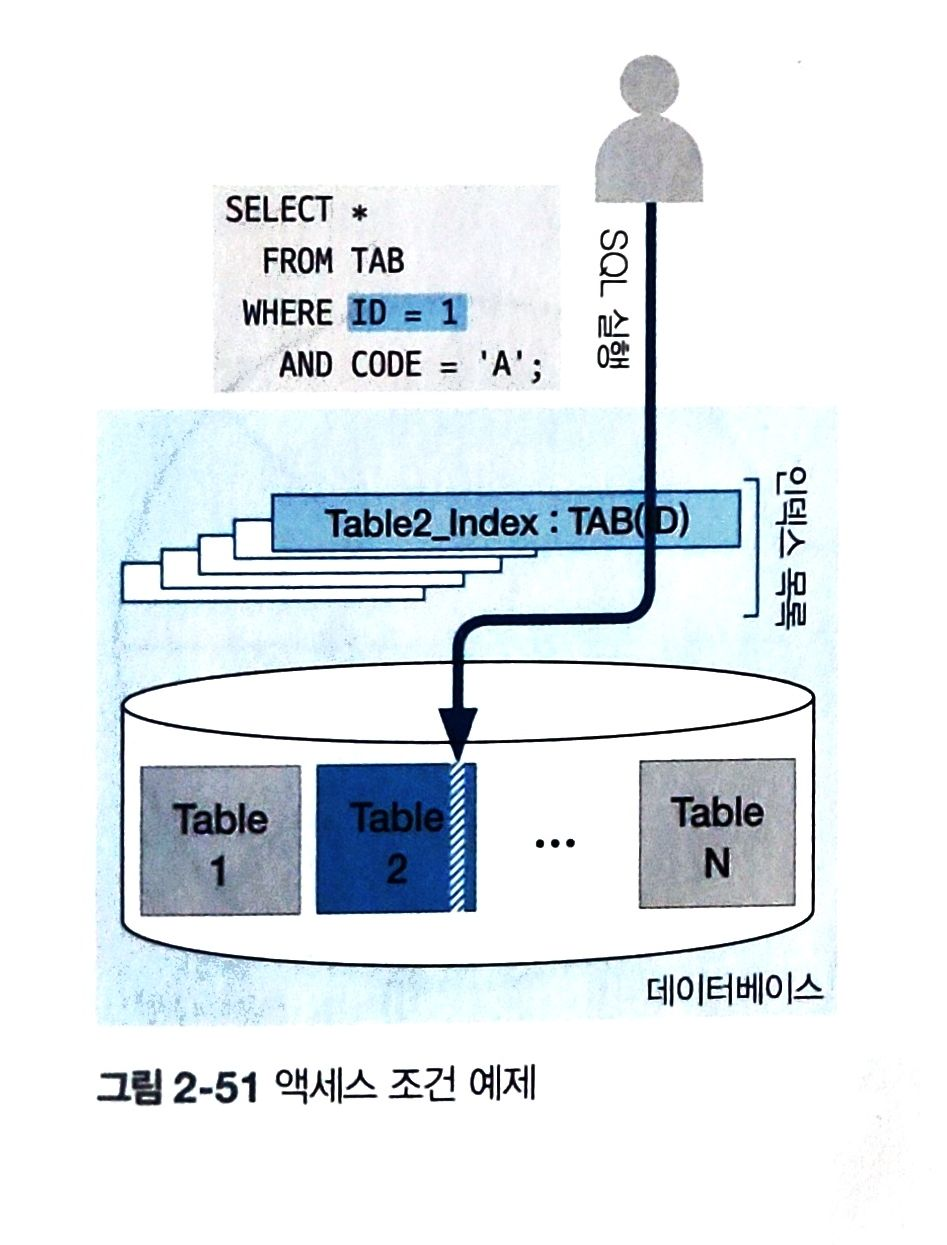
액세스 조건 예제)
- where 절에 ID=1 과 CODE='A' 존재하지만, ID 열로 생성된 인덱스(Table2_index) 를 활용해서 TABLE2 테이블의 일부 데이터에 접근
- 즉, ID=1 조건문이 액세스 조건
- 만약, CODE='A' 조건문을 액세스 조건으로 삼아 데이터에 접근한다면 인덱스 활용없이 대량의 데이터에 접근
2) 필터 조건
엑세스 조건을 사용해 MySQL 엔진으로 가져온 데이터를 기준으로 추가로 불필요한 데이터를 제거하거나 가공하는 필터 조건
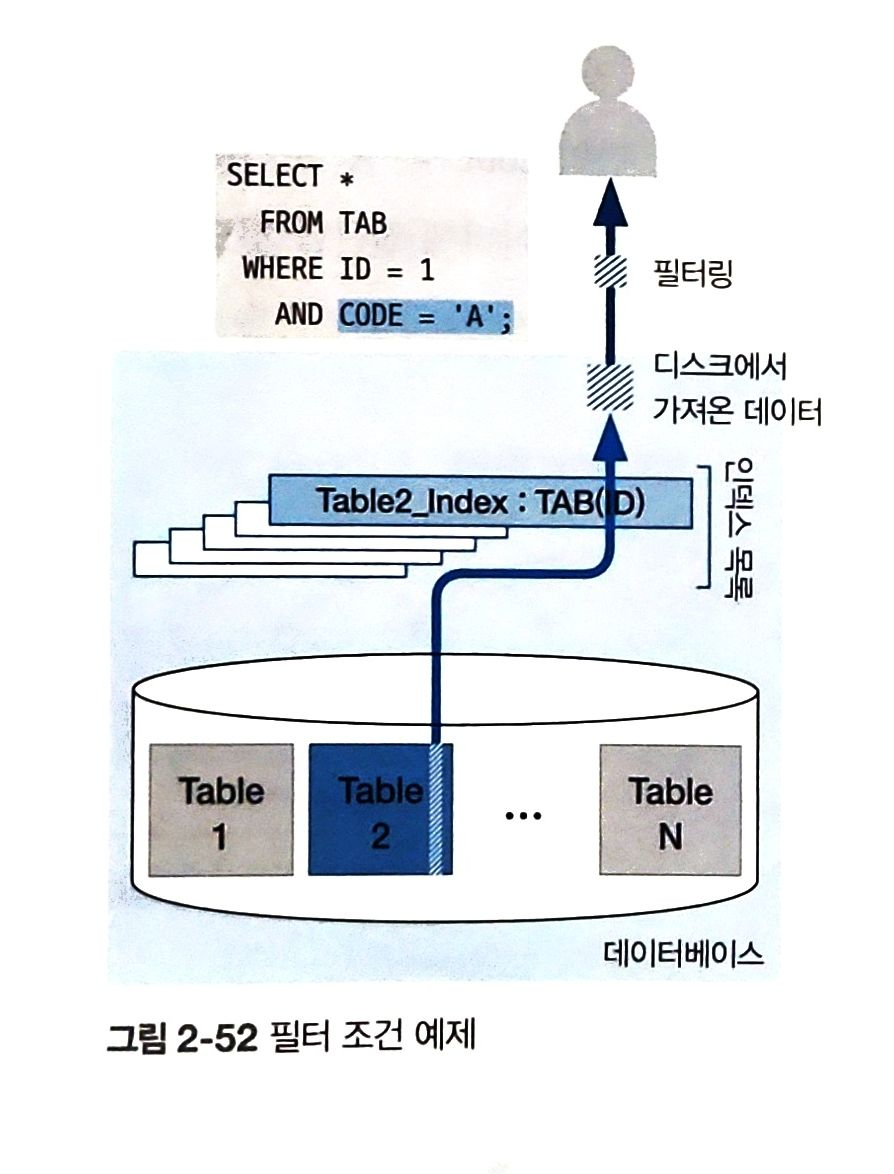
필터 조건 예제)
- 액세스 조건으로 가져온 데이터를 대상으로 필터조건인 CODE='A'를 적용해 필터링 작업 진행
필터링할 데이터가 없으면 => GOOD SQL
필터링되어 제거된 데이터 다수 존재하면 => BAD SQL
응용 용어
선택도
- 테이블의 특정 열을 기준으로 해당 열의 조건절(where절)에 따라 선택되는 데이터 비율
- 해당 열에 중복되는 데이터가 많다면 => 선택도가 높은 것
- 해당 열에 중복되는 데이터가 적다면 => 선택도가 낮은 것
- 선택도가 낮은 것이 대용량 데이터에서 원하는 데이터만 골라냄 => 인덱스 열을 생성할 때 고려대상
- 선택도 = 선택한 데이터 건수 / 전체 데이터 건수
- 선택도 = 1 / DISTINCT(COUNT 열명)
선택도 예제 )
학생 테이블 데이터 100건 (학번,이름,성별)
1000 이라는 학번을 가진 선택
학번 열의 선택도 = 선택한 데이터 건수 / 전체 데이터 건수 = 1 / DISTINCT(COUNT 학번) = 1 / 100 = 0.01
성별='여' 조건을 가진 선택
성별 열의 선택도 = 선택한 데이터 건수 / 전체 데이터 건수 = 1 / DISTINCT(COUNT 열명) = 50 / 100 = 1 / 2 = 0/5
카디널리티
- 하나의 데이터 유형으로 정의되는 데이터 행의 개수
- 전체 행에 대한 특정 열의 중복 수치
- 카디널리티 = 전체 데이터 건수 * 선택도
카디널리티 예제 )
학생 테이블 데이터 100건 (학번,이름,성별)
1000 이라는 학번을 가진 선택
학번 열의 선택도 = 선택한 데이터 건수 / 전체 데이터 건수 = 1 / DISTINCT(COUNT 학번) = 1 / 100 = 0.01
학번 열의 카디널리티 = 전체 데이터 건수 선택도 = 100 0.01 = 1
모든 학번의 데이터값이 고유한 만큼 1건의 데이터만 출력되리라 예측
MySQL에서 카디널리티란??
MySQL 은 중복을 제외한 유일한 데이터값의 수로 계산합니다. 따라서 특정 열에 중복된 값이 많다면 카디널리티는 낮고, 해당 열을 조회하면 많은 수의 데이터를 거르지 못한 채 대량의 데이터가 출력된다고 예측합니다. 반대로 특정 열에 중복된 값이 적으면 카디널리티는 높고, 해당 열을 조회하면 많은 수의 데이터를 거르고 소수의 데이터만 출력된다고 예측합니다.
카디널리티가 높은 것 : 주민등록번호, 휴대폰 번호, 계좌 번호
카니널리티가 중간인 것 : 이름
카디널리티가 낮은 것 : 성별, 졸업여부
힌트
- 데이터베이스에게 힌트를 전달해 의도대로 작동하도록 돕는 것
- 데이터를 빨리 찾을 수 있게 추가 정보 전달하는 것
select 학번,전공코드
from 학생 /*! USE INDEX (학생_IDX01) */
where 이름='유재석';
select 학번,전공코드
from 학생 USE INDEX (학생_IDX01)
where 이름='유재석';- 힌트를 준다고 무조건 힌트를 참고하는 것은 아니고, 옵티마이저가 비효율적이라고 예측하면 힌트는 무시될 수 있음
- 힌트가 적용된 서비스 환경에서는 데이터 건수가 급변하거나 테이블/인덱스/뷰 에 변화 생기면 SQL문 실행 시 오류 발생 가능성이 있음
select 학번,전공코드
from 학생 USE INDEX (학생_IDX01)
where 이름='유재석';
# 다음날, 옵티마이저가 불필요한 인덱스라고 판단하고 삭제
ALTER TABLE 학생 DROP_INDEX 학생_IDX01;
# 인덱스 삭제됐으므로 오류 발생
select 학번,전공코드
from 학생 USE INDEX (학생_IDX01)
where 이름='유재석';
=> ERROR ...콜레이션
- 특정 문자셋으로 데이터베이스에 저장된 값을 비교하거나 정렬하는 작업의 규칙


캐릭터셋 vs 콜레이션

통계정보
- 옵티마이저는 통계정보에 기반을 두고 SQL문 실행계획을 수립
테이블 통계정보/인덱스 통계정보/선택적인 열 통계정보를 토대로어떤 인덱스를 활용해 데이터에 액세스하고어떤 테이블을 드라이빙 테이블로 선택할지 등을 결정 => 통계정보의 최신성 유지 및 관리가 매우 중요
히스토그램
- 테이블의 열값이 어떻게 분포되어 있는지를 확인하는 통계정보
- 옵티마이저가 실행계획을 최적화하고자 참고하는 정보
- 저장된 데이터값 종류가 수만개 이상이므로 이 데이터값들을 그룹화하고 정해진 버킷으로 분리해서 열의 통계정보 데이터를 저장
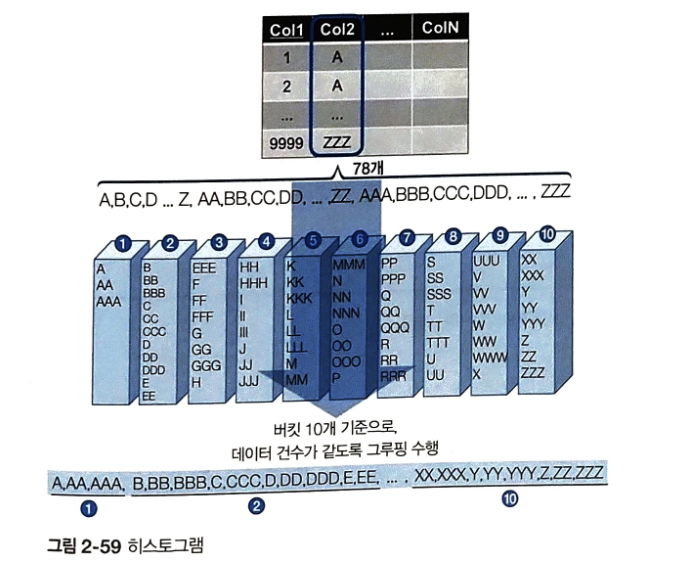
실제 데이터베이스에서 관리하는 히스토그램의 버킷은 최댓값을 보관
where 절 조건문에Col1='A'->버킷 1에만 접근해 데이터 분포 파악
where 절 조건문에Col1 BETWEEN E AND O->버킷 2~버킷 6까지 접근 -> 50%이상의 영역을 스캔해야하므로 인덱스 스캔보다 테이블 풀스캔을 추천

