10:20 착석
기침이 좀 나오지만 내일은 강의실 갈 수 있을 듯..?
알고리즘 복습
재귀
재귀는 호출 타임과 반환 타임이 있다.
각 타임에 특정 작업을 할 수 있음.
재귀로 작성해도 컴파일러가 최적화 과정을 통해 루프처럼 바꿀 수 있음.
(ex. 꼬리재귀)
- tail recursion: 함수의 마지막 부분에서 재귀 호출. 이후에는 다른 작업 없음
(재귀 리턴 값에 다른 연산은 하면 꼬리 재귀가 아님) - head recursion: 앞 부분이 없이 함수 첫 부분에서 재쥐 호출. 이 경우 모든 작업은 반환 타임에 수행되면 된다.
- linear recursion(선형 재귀): 재귀 호출을 1회
- tree recursion: 재귀 호출을 여러 번
- indirect recursion(간접 재귀): 재귀에 사이클이 생김 a -> b -> c 호출 형태
- nested recursion(중첩 재귀): 함수 파라미터로 재귀 호출
Pintos
발표 준비
filesize(int fd), write(int fd), seek(int fd), tell(int fd), close(int fd)
FD는 그냥 숫자잖아? 근데 이걸로 어떻게 파일을 식별하는 거야?
스레드 별로 FD Table이 관리된다!
struct thread {
...
struct file **fd_table
...
}FD는 FD Table의 인덱스 번호구나!
즉, FD를 통해서 특정 파일 구조체를 식별하는군!
파일 구조체가 파일인가?
struct file {
struct inode *inode; /* File's inode. */
off_t pos; /* Current position. */
bool deny_write; /* Has file_deny_write() been called? */
}off_t는 커서의 오프셋.(읽기/쓰기가 시작되는 시점)
deny_write는 읽기 전용 여부.
파일 구조체는 i-node랑 연결되는구나!
i-node는 물리 디스크에 적재된 데이터에 대한 위치 정보와 메타데이터를 지닌 일종의 포인터 같은 역할!
i-node가 핵심인가?
struct inode {
struct list_elem elem; /* Element in inode list. */
disk_sector_t sector; /* Sector number of disk location. */
int open_cnt; /* Number of openers. */
bool removed; /* True if deleted, false otherwise. */
int deny_write_cnt; /* 0: writes ok, >0: deny writes. */
struct inode_disk data; /* Inode content. */
}disk_sector_t sector; : 해당 i-node 자체가 저장된 물리 디스크 위치
struct inode_disk data; : 여기에 파일 사이즈 및 물리 디스크 상의 데이터 시작 위치가 저장되어 있음.
struct inode_disk {
disk_sector_t start; /* First data sector. */
off_t length; /* File size in bytes. */
unsigned magic; /* Magic number. */
uint32_t unused[125]; /* Not used. */
};magic number는 파일 형식 식별과 데이터 무결성 검증에 사용된다.
i-node는 파일의 메타데이터와 같은 역할을 한다!
FD로 파일에 접근해서 다양한 작업을 할 수 있다!
/* 파일의 커서 위치를 새롭게 설저한다. */ void seek (int fd, unsigned position) { struct file *f = get_file_from_fd_table(fd); if (f == NULL) { return; } file_seek(f, position); }
실제 물리디스크로 어떻게 데이터가 넘어가는건가?
off_t
file_write (struct file *file, const void *buffer, off_t size) {
off_t bytes_written = inode_write_at (file->inode, buffer, size, file->pos);
file->pos += bytes_written;
return bytes_written;
}file_write를 래핑하는 write() 단계에서 버퍼에 데이터를 임시 저장한 상태임!
inode_write_at()를 살펴보자
off_t
inode_write_at(...)
{
...
disk_write (filesys_disk, sector_idx, bounce);
...
}disk_write() 이거다!
void
disk_write (struct disk *d, disk_sector_t sec_no, const void *buffer) {
struct channel *c;
ASSERT (d != NULL);
ASSERT (buffer != NULL);
c = d->channel;
lock_acquire (&c->lock);
select_sector (d, sec_no);
issue_pio_command (c, CMD_WRITE_SECTOR_RETRY);
if (!wait_while_busy (d))
PANIC ("%s: disk write failed, sector=%"PRDSNu, d->name, sec_no);
output_sector (c, buffer);
sema_down (&c->completion_wait);
d->write_cnt++;
lock_release (&c->lock);
}디스크d의 섹터sec_no에 buffer 내용을 쓴다.
issue_pio_command (c, CMD_WRITE_SECTOR_RETRY)
static void
issue_pio_command (struct channel *c, uint8_t command) {
/* Interrupts must be enabled or our semaphore will never be
up'd by the completion handler. */
ASSERT (intr_get_level () == INTR_ON);
c->expecting_interrupt = true;
outb (reg_command (c), command);
}pio는 Programmed Input/Output
CPU가 데이터 전송을 직접 제어하는 방식 <-> DMA
outb()
/* Writes byte DATA to PORT. */
static inline void
outb (uint16_t port, uint8_t data) {
/* See [IA32-v2b] "OUT". */
asm volatile ("outb %0,%w1" : : "a" (data), "d" (port));
}outb는 Output Byte
FD에서 출발한 여행 끝~
키워드
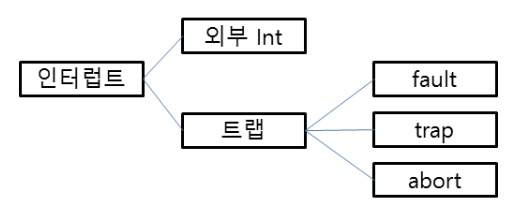
인터럽트
인터럽트 코드 실행을 위해 기존 CPU작업과 인터럽트 작업이 교환되는 걸 문맥교환이라고 함.
이 문맥 교환 시에는 유휴 작업이므로, 오버헤드가 발생한다.
인터럽트가 발생하면 스택에 인터럽트 프레임이 생성됨.
인터럽트가 발생한 시점의 CPU 레지스터 상태, 프로그램 카운터, 상태 레지스터 등을 포함
트랩이 발생해도 인터럽트 프레임이 발생한다?!
트랩은 일종의 소프트웨어 인터럽트로 간주될 수 있음.
세그멘테이션
세그멘테이션이 없이 베이스와 바운드 레지스터 기반의 메모리 관리는 일종의 연속 할당임.
근데 이 방식은 하나의 단일 블록으로 인한 내부 단편화가 발생해서 비표율적임.
이걸 다양한 크기로 쪼개서 메모리는 관리하는 게 세그멘테이션
단, 가변 크기이기 때문에 외부 단편화가 발생할 수 있다.
(반대로 고정 크기이면 내부 단편화가 발생한다.)
세그멘트마다 베이스와 바운드가 존재하는 방식!
베이스와 바운드 레지스터
세그멘테이션 메모리 관리 기법 구현 시 필요한 레지스터
베이스 레지스터
- 세그먼트 시작 주소 저장
- 베이스 주소에 오프셋이 더해져서 실제 메모리 주소 계산
바운드 레지스터
- 세그먼트 크기 결정
- 해당 세그먼트의 유효 주소 범위 정의
페이징과 세그멘테이션 차이!
페이지는 고정 크기의 불연속 메모리 할당 방식,
세그멘테이션은 다양한 크기 불연속 메모리 할당 방식!
segmentaion fault
프로세스가 허용되지 않는 메모리 영역에 접근할 때 운영체제가 발생시키는 오류
운영체제는 해당 프로세스를 강제로 중단시킨다.
원인
- 잘못된 메모리 참조
- 버퍼 오버플로우
- 해제된 메모리 참조
- NULL 포인터 참조
처리 과정
- 불법 접근 감지
- 인터럽트 발생(트랩)
- 프로세스 중단
참고로 세그멘테이션을 지원하지 않는 컴퓨터에서도 세그멘트 폴트가 발생한다.
이 경우에는 오류 원인 알 수 없다?🤣
페이징
메모리를 고정된 일정 크기로 나누는 것
페이지 테이블의 주요 역할은 주소 공간의 가상 페이지 주소 변환 정보를 저장하는 것
(논리적인 페이지와 실제 물리 메모리 위치를 매핑하는 것)
