REPL
Read(읽기)
Eval(해석)
Print(결과물 반환)
Loop(종료할 때까지 반복)
노드의 콘솔이다.
터미널에서 node를 입력하면 실행할 수 있다.
즉, JS코드를 실행하게 해주는 일종의 node 내장 프로그램(또는 환경)
브라우저에서는 콘솔을 이용할 수 있고,
node에서는 REPL을 이용할 수 있음.
콘솔(터미널)에서 REPL로 들어가는 명령어가 node
모듈
모듈: 특정한 기능을 하는 함수나 변수들의 집함
JS에서는 모듈을 다루는 두 가지 방식이 있다.
- CommonJS
- ESM(ECMAScript Module)
ESM에서는 명시적으로 이 모듈이 ESM인 것을 나타내기 위해 확장자를 .mjs로 표기함.
타입스크립트에서는 .mts로 표기하면 CommonJS 방식은 .cts로 표기함.
CommonJS 모듈
비표준
노드 생태계에서 가장 널리 쓰이는 모듈
require로 불러오면 requre.cache에 저장됨.
다음에 require할 때는 캐싱된 걸 사용함.
require('.a/'); // require는 함수다!
module.exports = A; // module은 객체다.
exports.C = D;require라는 함수로 모듈을 불러오면 변수에 해당 모듈의 모듈 객체에 exports에 저장된 내용이 변수에 저장되는 것
ECMAScript 모듈
import // 객체가 아닌 문법
export // 객체가 아닌 문법다이내믹 임포트
조건부로 모듈을 불러오는 것
CommonJS 방식
const a = false;
if (a) {
require('.func');
}ES 방식
하지만 ES 모듈은 if문 안에서 import 할 수 없음.
그래서 import 함수를 비동기적으로 처리함.
import는 Promise를 반환한다.
const a = true;
if (a) {
const m1 = await import ('./func.mjs');
}
filename & dirname
ES 모듈에서는 사용 불가
console.log(__filename); // 현재 파일 위치가 출력
console.log(__dirname); // 현재 디렉토리가 출력ES 모듈에서는 이렇게 씀
console.log(import.meta.url);내장 객체
node에서 기본적으로 제공함. import 하지 않아도 쓸 수 있음.
(브라우저 환경의 window 객체와 비슷)
global
전역 객체
모든 파일에서 접근 가능
생략 가능
(console도 global.console임)
console
console.time(레이블)
console.timeEnd()와 함께 씀.
console.time('데이터 처리 시간');
// 데이터 처리 로직
for (let i = 0; i < 100000; i++) {
// 시간이 걸리는 처리...
}
console.timeEnd('데이터 처리 시간');console.error(내용)
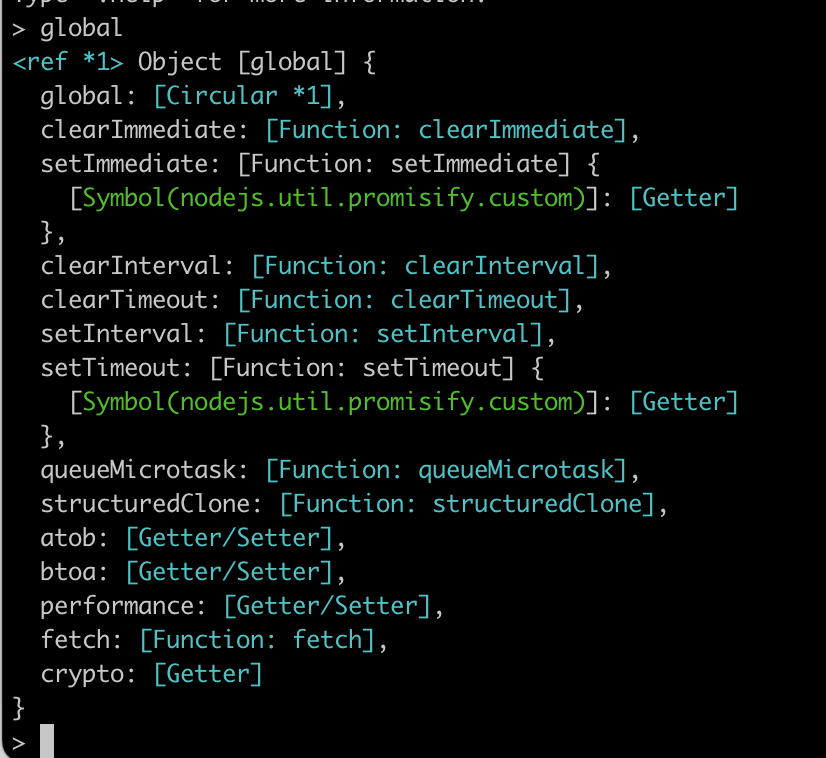
console.table(배열)
아니? 이런 기능이?!!!
console.dir(객체, 옵션)
객체를 콘솔에 표시할 때 사용
.log와 .dir 차이는?
log는 간단한 내용 출력 할 때,
dir은 객체 구조를 자세하게 탐색할 때
console.trace(레이블)
에러 발생 위치 추적
(근데 에러 발생하면 위치가 나오니까 잘 사용하지는 않음)
정확히하면, 이건 현재 실행 중인 콜 스택을 출력하는 거!
> function firstFunction() {
... secondFunction();
... }
undefined
>
> function secondFunction() {
... thirdFunction();
... }
undefined
>
> function thirdFunction() {
... console.trace("Trace");
... }
undefined
>
> firstFunction();
Trace: Trace
at thirdFunction (REPL11:2:11)
at secondFunction (REPL7:2:3)
at firstFunction (REPL3:2:3)
at REPL13:1:1
at ContextifyScript.runInThisContext (node:vm:121:12)
at REPLServer.defaultEval (node:repl:599:22)
at bound (node:domain:432:15)
at REPLServer.runBound [as eval] (node:domain:443:12)
at REPLServer.onLine (node:repl:929:10)
at REPLServer.emit (node:events:530:35)타이머
- setTimeout(콜백, ms)
- setInterval(콜백, ms)
- setImmediate(콜백): 콜백 함수를 즉시 실행
타이머는 아이디를 반환하고, 아이디로 취소 가능
- clearTimeout(id)
- clearInterval(id)
- clearImmediate(id)
process
환경 변수를 사용할 때 쓰던 process.env가 이거였다!!!!
process는 node의 내장 객체였던 것!!
process.nextTick(콜백)
이벤트 루프가 해당 콜백을 다른 것보다 항상 우선 처리하도록 만듦.
참고로 resolve된 Promise도 다른 콜백보다 우선시 된다.
process.nextTick과 Promise를 태스크 큐보다 우선 순위를 갖는 마이크로태스크 큐라고 한다.
console.log('1. 동기 코드 시작');
setTimeout(() => {
console.log('5. setTimeout 실행');
}, 0);
Promise.resolve().then(() => {
console.log('3. 프로미스 콜백 실행');
});
process.nextTick(() => {
console.log('2. nextTick 콜백 실행');
});
console.log('4. 동기 코드 종료');1. 동기 코드 시작
4. 동기 코드 종료
2. nextTick 콜백 실행
3. 프로미스 콜백 실행
5. setTimeout 실행교재의 설명과 좀 다름 점이 있음.
교재에서는 nextTick도 마이크로태스크 큐에 들어간다고 하는데,
검색 결과 nextTick는 별도 큐에 들어간다고 함.
검증 필요.
nextTick큐가 마이크로태스크 큐보다 우선 순위가 높음.
-
마이크로태스크 큐: 이는 주로 프로미스의 .then(), .catch(), .finally() 콜백과 같이 JavaScript의 마이크로태스크에 의해 사용되는 큐입니다. 이 큐의 작업들은 현재 실행 중인 스크립트가 완료되고, 이벤트 루프의 다른 단계로 넘어가기 전에 실행됩니다.
-
넥스트 틱 큐: process.nextTick() 함수에 의해 예약된 콜백을 위한 큐로 설명되곤 합니다. 이 콜백들은 현재 실행중인 작업이 완료되자마자, 다른 I/O 이벤트가 처리되기 전에 실행됩니다.

process.exit()
const fs = require('fs');
fs.readFile('nonexistentFile.txt', (err, data) => {
if (err) {
console.error("파일을 읽는 도중 에러가 발생했습니다.", err);
process.exit(1); // 에러가 발생했으므로 에러 상태로 종료
}
console.log("파일 읽기 성공:", data.toString());
});내장 모듈
노드는 브라우저 환경보다 더 많은 기능을 제공함.
예를 들어 운영체제 정보에도 접근할 수 있음.
(process객체와 겹치는 부분도 있음.)
os
// Node.js의 os 모듈을 사용한 예시 코드입니다.
const os = require('os');
// 운영체제의 기본 정보 출력
console.log("운영체제 플랫폼:", os.platform()); // 예: 'darwin', 'win32'
console.log("운영체제 릴리즈:", os.release()); // 운영체제 버전
console.log("운영체제의 호스트 이름:", os.hostname()); // 컴퓨터의 호스트 이름
console.log("시스템의 총 메모리:", os.totalmem(), "bytes"); // 시스템의 총 메모리 양
console.log("시스템의 사용 가능 메모리:", os.freemem(), "bytes"); // 사용 가능한 메모리 양
console.log("시스템의 아키텍처:", os.arch()); // 프로세서의 아키텍처
console.log("시스템의 CPU 정보:", os.cpus()); // CPU의 코어 정보 배열
console.log("시스템의 네트워크 인터페이스:", os.networkInterfaces()); // 네트워크 인터페이스 정보path
파일 경로 조작을 도와줌.
이게 필요한 이유는 운영체제마다 경로 구분자가 다르기 때문
- 윈도 타입:
\로 구분 - POSIX 타입(유닉스 기반 운영체제)
/로 구분
path.join vs path.resolve
path.join
무조건 합해서 경로로 만듦.
path.resolve
오른쪽부터 읽어나가면서 절대 경로를 만듦.
그래서 읽다가 절대 경로(/로 시작하는 경로)를 만나면 경로 생성을 멈춤.
path.join('/a', '/b', '/c'); // /a/b/c
path.resolve('/a', '/b', 'c'); // /b/c
url 모듈로 주소 객체를 만드는 것!
dns
dns.resolve(도메인, 레코드 이름)으로 조회
레코드
- A(ipv4)
- AAAA(ipv6)
- NS(네임서버)
- SOA(도메인 정보)
- CNAME(별칭)
- MX(메일 서버)
const dns = require("dns");
// lookup 메서드를 사용하여 도메인 이름에 대한 첫 번째 IP 주소 찾기
dns.lookup("google.com", (err, address, family) => {
if (err) throw err;
console.log(`주소: ${address}, 패밀리: IPv${family}`);
});
// 주소: 172.217.161.238, 패밀리: IPv4crypto
암호화 모듈
const crypto = require('crypto');
// Create a SHA-256 hash
const hash = crypto.createHash('sha256'); // 해시 객체를 생성
hash.update('Hello World'); // 해싱, 내부 버퍼에 추가. 여러 번 호출하면 이어짐.
console.log(hash.digest('hex')); // 해싱된 값을 인코딩해서 출력digest는 '소화하다'는 의미
update()는 해시 함수의 입력 데이터에 추가하는 기능
실제 해싱은 digest()을 호출하면 이루어지며, 이때 매개변수의 인코딩으로 반환한다.
해시 알고리즘
sha256같은 기본 알고리즘은 해시 충돌, 레인보우 테이블 등의 문제가 있다.
그래서 기본 해시 알고리즘을 바탕으로 파생된 다양한 비밀번호 암호화 알고리즘이 있다.
const crypto = require("crypto");
const password = "userPassword123";
const salt = crypto.randomBytes(16).toString("hex");
const iterations = 100000;
const keylen = 64;
const digest = "sha512";
crypto.pbkdf2(password, salt, iterations, keylen, digest, (err, derivedKey) => {
if (err) throw err;
console.log(derivedKey.toString("hex")); // The hashed password.
});pbkdf2는 간단하지만 bcrypt, scrypt보다 취약함.
양방향 암호화
const crypto = require("crypto");
const algorithm = "aes-256-cbc";
const key = crypto.randomBytes(32);
const iv = crypto.randomBytes(16);
// 문자를 utf8로 인코딩해서 암호화하고, base64로 출력하라는 의미
const cipher = crypto.createCipheriv(algorithm, key, iv); // iv는 초기화 벡터
let result = cipher.update("Hello, world!", "utf8", "base64");
result += cipher.final("base64"); // update는 분할 방식. 나머지를 처리.
console.log(result);
const decipher = crypto.createDecipheriv(algorithm, key, iv);
let result2 = decipher.update(result, "base64", "utf8");
result2 += decipher.final("utf8");
console.log(result2);HArEr7EVzce29josbo8odw==
Hello, world!

util
유용한 여러 기능을 제공해준다 정도로만 정리..
worker_threads
노드에서 멀티 스레드 방식으로 작업
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
// 메인 스레드 로직
// 워커 스레드에 전달할 작업 데이터 준비
const workData = { start: 1, end: 1e8 }; // 예: 1부터 1억까지 합계 계산
// 현재 파일을 워커 스레드로 사용
const worker = new Worker(__filename, { workerData: workData });
// 워커 스레드로부터 계산 결과 수신
worker.on('message', (sum) => {
console.log(`계산 결과: ${sum}`);
});
// 워커 스레드 종료 처리
worker.on('exit', (code) => {
if (code !== 0) {
console.error(`워커 스레드가 비정상 종료되었습니다. 종료 코드: ${code}`);
} else {
console.log('워커 스레드가 성공적으로 종료되었습니다.');
}
});
} else {
// 워커 스레드 로직
const workData = require('worker_threads').workerData;
// 워커 스레드로부터 메시지 수신 (작업 범위)
const { start, end } = workData;
let sum = 0;
// 계산 작업 수행 (예: 주어진 범위의 합계 계산)
for (let i = start; i <= end; i++) {
sum += i;
}
// 계산 결과 메인 스레드로 전송
parentPort.postMessage(sum);
}
child_process
노드에서 다른 프로그램 실행하고 싶을 때
예를 들어 파이썬을 실행시키고 결과를 받을 수 있음!
const { exec } = require('child_process');
// 파이썬 스크립트 실행 예시
exec('python3 script.py', (error, stdout, stderr) => {
if (error) {
console.error(`exec error: ${error}`);
return;
}
// 표준 출력
console.log(`stdout: ${stdout}`);
// 표준 에러
if (stderr) {
console.error(`stderr: ${stderr}`);
}
});const { spawn } = require('child_process');
// 파이썬 스크립트 실행 예시
const child = spawn('python3', ['script.py']);
// 표준 출력 스트림 처리
child.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
// 표준 에러 스트림 처리
child.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
});
// 프로세스 종료 처리
child.on('close', (code) => {
console.log(`child process exited with code ${code}`);
});exec는 쉘에서 실행하고, spawn은 프로세스를 생성함.
각 프로그램에서 표준 출력으로 보내는 데이터를 받을 수 있음.
즉, 표준 출력이라는 하나의 공간을 공유하는 것.
리눅스에서 표준 출력도 결국 파일처럼 다뤄지니까 가능.

그 외 모듈
- async_hooks: 비동기 코드 흐름 추적
- dgram: UDP
- net: TCP, IP
- perf_hooks: 성능 측정 console.time보다 정교
- string_decoder: 버퍼 데이터 -> 문자열
- tls: TLS, SSL
- tty: 터미널
- v8: v8 엔진 직접 접근
- vm: 가장 머신 직접 접근
- wasi: 웹어셈블리 실행
node 기능이 엄청 많구나..를 느낌.
