지난 주 일요일에 이어서 랭체인을 살펴보자.
이따 오후에 Pintos read-normal 안 되는 거 살펴보기
Add fallbacks
API 요청이 주된 처리 경로로 성공적으로 완료되지 못했을 때 사용되는 대체 처리 경로나 방법
예) API요청이 실패하면 재요청하지 않고 종료
LLM API 에러 처리
특정 LLM에서 오류가 나면 다른 LLM으로 대체해서 처리하는 방식
llm = openai_llm.with_fallbacks([anthropic_llm]) // 실패할 경우 대체한다는 뜻
...
chain = prompt | llm
with patch("openai.resources.chat.completions.Completions.create", side_effect=error):
try:
print(chain.invoke({"animal": "kangaroo"}))
except RateLimitError:
print("Hit error")특정 에러 처리
별도 체인을 생성
llm = openai_llm.with_fallbacks(
[anthropic_llm], exceptions_to_handle=(KeyboardInterrupt,)
)
chain = prompt | llm
with patch("openai.resources.chat.completions.Completions.create", side_effect=error):
try:
print(chain.invoke({"animal": "kangaroo"}))
except RateLimitError:
print("Hit error")시퀀스 대체
특정 오류에 대해서만 처리
시퀀스 단계마다 에러 처리 조건을 설정하는 방식
chain = bad_chain.with_fallbacks([good_chain])생성기 함수
이건 파이썬 기본 iterator를 사용하는 것
동시 생성기 함수
비동기 생성기 함수
메모리
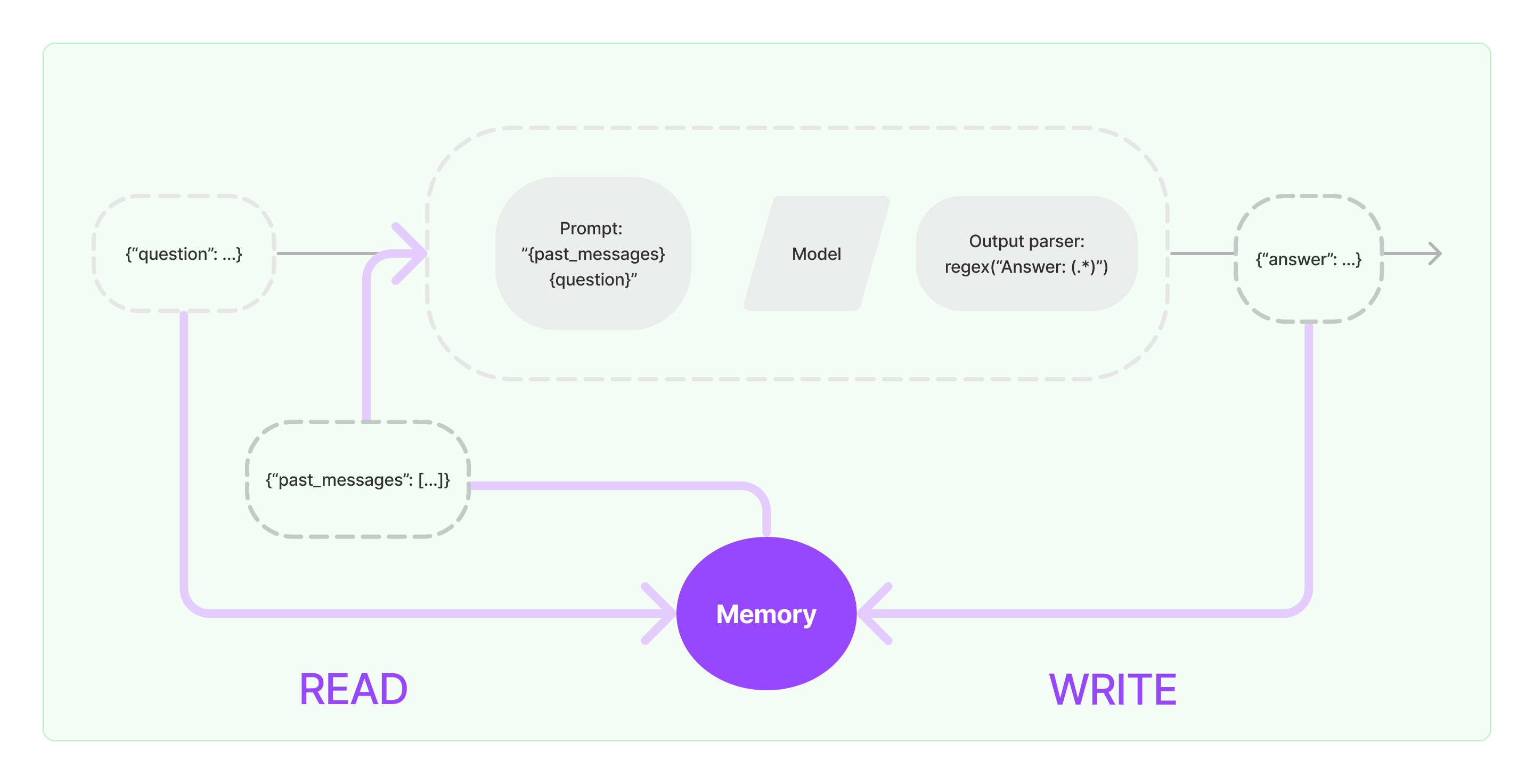
메모리 설계의 핵심
- 어떻게 상태를 저장하냐
- 어떻게 상태를 쿼리하냐
저장
모든 메모리 기본은 채팅 상호 작용 기록
전부 직접 기록하지 않더라도 어떤 형태로든 저장해야 함.
쿼리
최근 메시지 반환하거나, 과거 K개의 메시지 간결 요약본 반환
ChatHistory 모듈
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")주요 메모리 기법
ConversationBufferMemory
ConversationBufferWindowMemory : 마지막 K개 상호 작용(슬라이딩 창 유지)
ConversationEntityMemory : 특정 엔터티에 대한 사실 기억
ConversationKGMemory : 지식 그래프 사용, 메모리 재생성
ConversationSummaryMemory : 대화 요약
ConversationSummaryBufferMemory : 대화 요약 버퍼 (과거는 없애지 않고 요약하고, 최근은 걍 버퍼)
ConversationTokenBufferMemory: 버퍼를 사용하되, 토큰 길이로 상호 작용 플러시할 시기 결정
VectorStoreRetrieverMemory : 벡터 저장소에 메모리 저장. 상위 K개 주요 문서 쿼리
기본 개념
모델 I/O
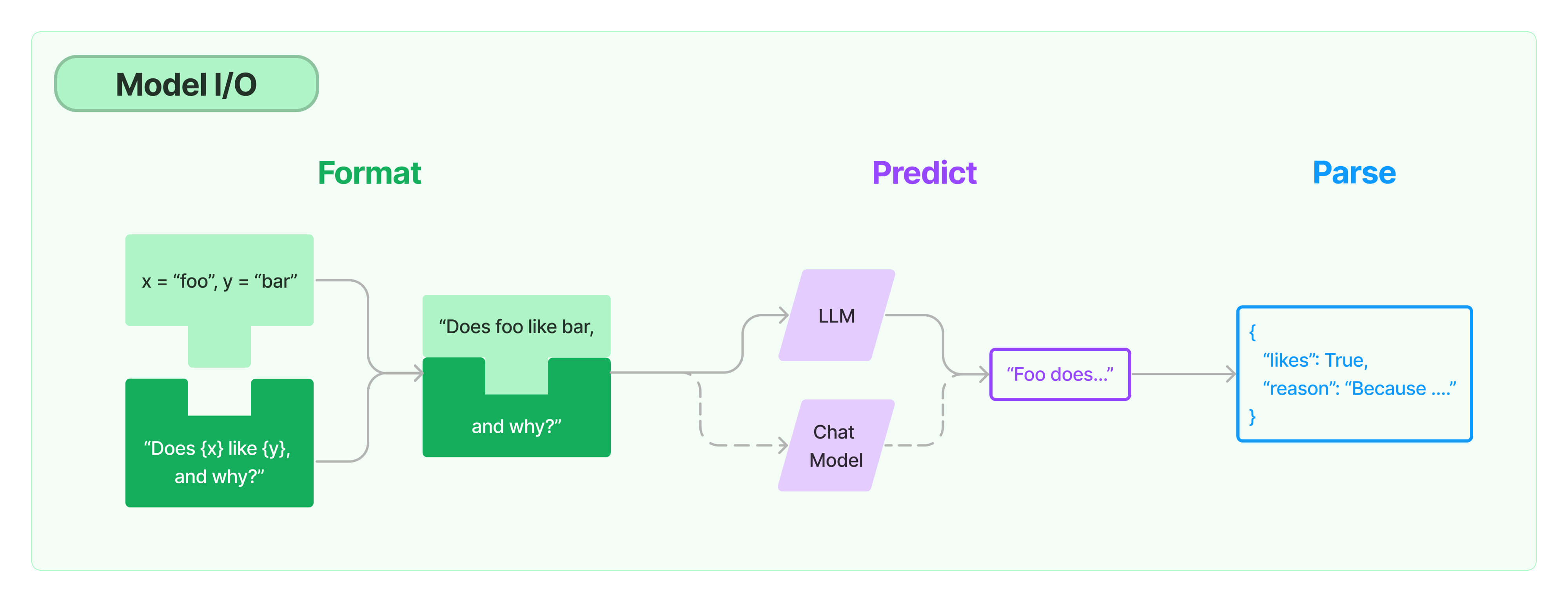
프롬프트 템플릿
입력 검증도 가능
from langchain.prompts import PromptTemplate
invalid_prompt = PromptTemplate(
input_variables=["adjective"],
template="Tell me a {adjective} joke about {content}.",
)채팅 모델
채팅 모델은 언어 모델의 변형임.
내부적으로는 언어 모델을 사용하지만 인터페이스가 다를 뿐
언어 모델이 텍스트 입력 -> 텍스트 출력이라면,
채팅 모델은 채팅 메시지 입력 -> 채팅 메시지 출력 구조
loader
당양한 종류의 로더가 있음.
근데 이거 쓰면 알아서 불러옴.
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("./files/chapter_one.docx")
loader.load()임베딩
입력 -> Transform(쪼개기) -> Enbed(벡터 공간 변환) -> Store(벡터 저장) -> 모델
벡터 값을 저장하는 곳이 vetor store이고, 이 곳에서 특정 문구를 검색할 수 있음.
embeddings = OpenAIEnbeddings()
vectorstore = Chroma.from_documents(docs, embeddings)
result = vectorstore.similarity_search("where does winston live")문서를 적절히 쪼개야하는 이유는 그렇지 않으면 너무 많은 데이터가 LLM으로 들어가서 과다 비용
그리고 이 결과는 캐싱하는 게 좋음.
질문이 요청오면 해당 결과가 캐시에 있는지 먼저 찾기
그 다음 없으면 벡터 스토어에서 찾기
코로나 컨디션이 너무 안 좋다.. 목도 너무 아프고..
계속 잠.. 그냥 푹 쉬는 게 낫겠음
