This thread implements codes from Professor Jeong's NLP class. You can find the full codes at the link below:
https://github.com/jdasam/aat3020-2023
Word2Vec
Let's explore the difference between Continuous Bag of Words and Skip-Gram methods, which are two ways of implementing Word2Vec.
Corpus
We will be using a corpus from the book Harry Potter 1. While I won't be sharing the algorithms for CBOW and Skip-Gram, you can find instructions on how these methods work elsewhere. Instead, I'll be sharing the codes for creating datasets using these two methods, so that you can see the difference between them directly.
with open("J. K. Rowling - Harry Potter 1 - Sorcerer's Stone.txt", 'r') as f:
strings = f.readlines()
sample_text = "".join(strings).replace('\n', ' ').replace('Mr.', 'mr').replace('Mrs.', 'mrs').split('. ')print(corpus[0][0:10])
['harry',
'potter',
'and',
'the',
'sorcerers',
'stone',
'chapter',
'one',
'the',
'boy']CBOW
def make_word_pair_for_cbow(corpus, window_size=3):
pair_list = []
for sentence in corpus:
for i, word in enumerate(sentence):
context_words_for_wrd = []
for j in range(max(i-window_size, 0), min(i+window_size+1, len(sentence))):
if j==i:
continue
context_word = sentence[j]
context_words_for_wrd.append(context_word)
pair_list.append((word, context_words_for_wrd))
return pair_list
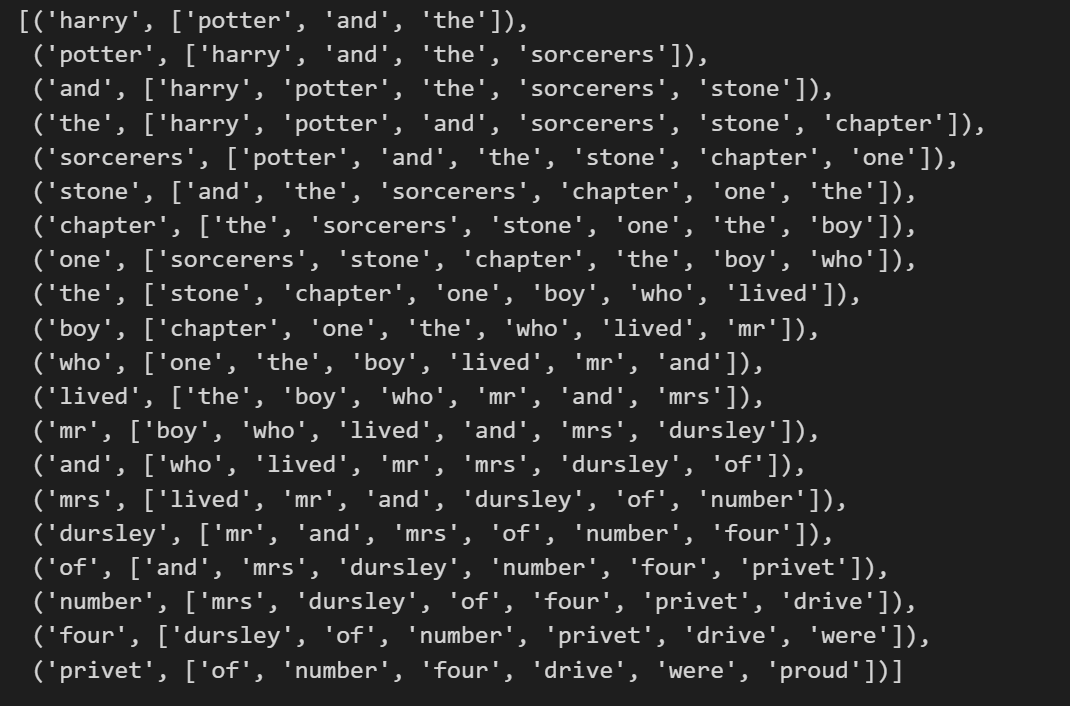
pair_list_cbow = make_word_pair_for_cbow(corpus)
pair_list_cbow[0:20], len(pair_list_cbow)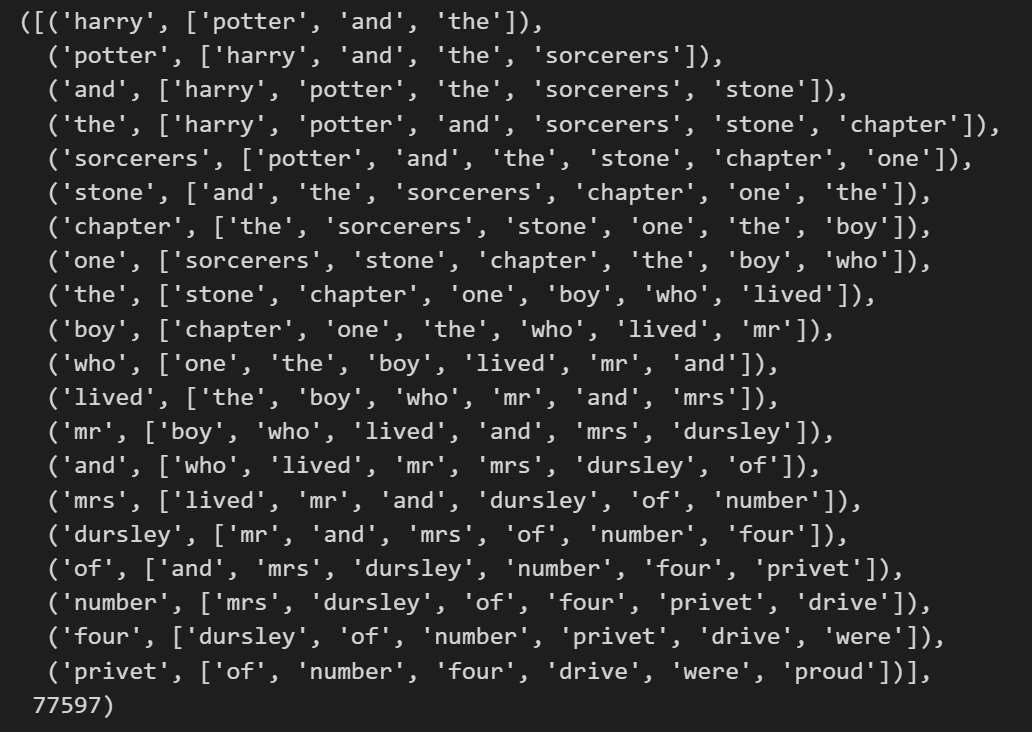
Skip-gram
def make_word_pair_for_sg(corpus, window_size=3):
pair_list = []
for sentence in corpus:
for i, word in enumerate(sentence):
if word not in word_to_idx_dict:
continue
# if I can know the index of the word that should be a center word of context words
# then I can use it as the base of checking the other indexes of countext words
# center_index - window_size to center_index + wondow_size
for j in range(max(i-window_size, 0), min(i+window_size+1, len(sentence))):
if j==i:
continue
context_word = sentence[j]
if context_word not in word_to_idx_dict:
continue
pair_list.append((word, context_word))
return pair_list
pair_list_sg = make_word_pair_for_sg(corpus)
pair_list_sg[0:20], len(pair_list_sg)
Negative Sampling
It needs only in Skip-gram. Lets think about CBOW, the architecture of CBOW is simple. We can use look up table to find vectors of context words and we can calculate the mean of these vectors to get a center vector. So the loss function can be easily processed by using this center vector to a target of one-hot vector of center word.
But Skip-gram is different it needs process of calculating center word to all the other vectors in a vocab. So that's the reason why there is negative sampling technique for skip-gram.
reference
https://wikidocs.net/69141
