Examining the issue inherent in NB
main problem
why NB can't perform as much as it should be?
- It shortens the length of tokens by 40% compared to CP
- It holds a wealth of information, effectively doubling the amount compared to CP by compressing musical data into single notes
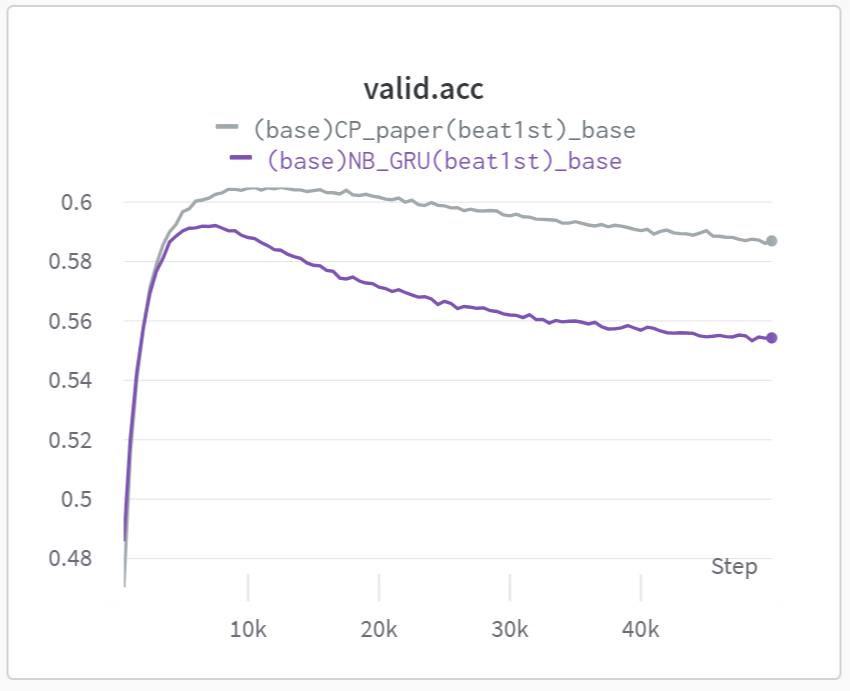
Recognition of the weird point
We observed that NB leads to a significant amount of overfitting. It reaches the optimal point swiftly but deteriorates rapidly in comparison to CP.
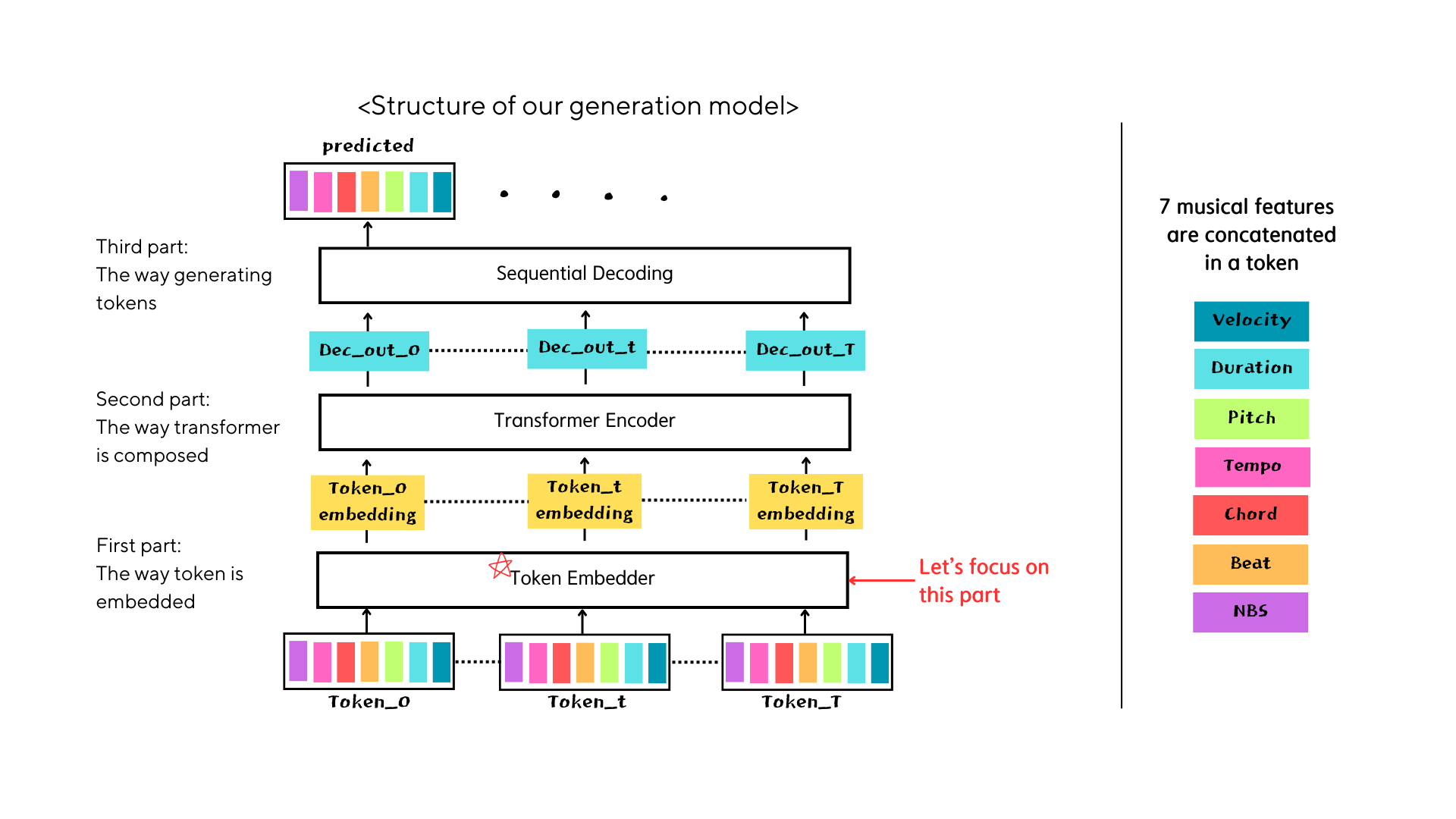
Break down & Examine by part
In the initial stages, numerous alterations were made in an attempt to enhance the model through NB encoding. However, it became apparent that a more focused approach was necessary, targeting three distinct components. Subsequently, experimentation was conducted on the "token embedder" segment, with concurrent adjustments made to the remaining two components, namely the "transformer encoder" and "sequential decoding" sections.
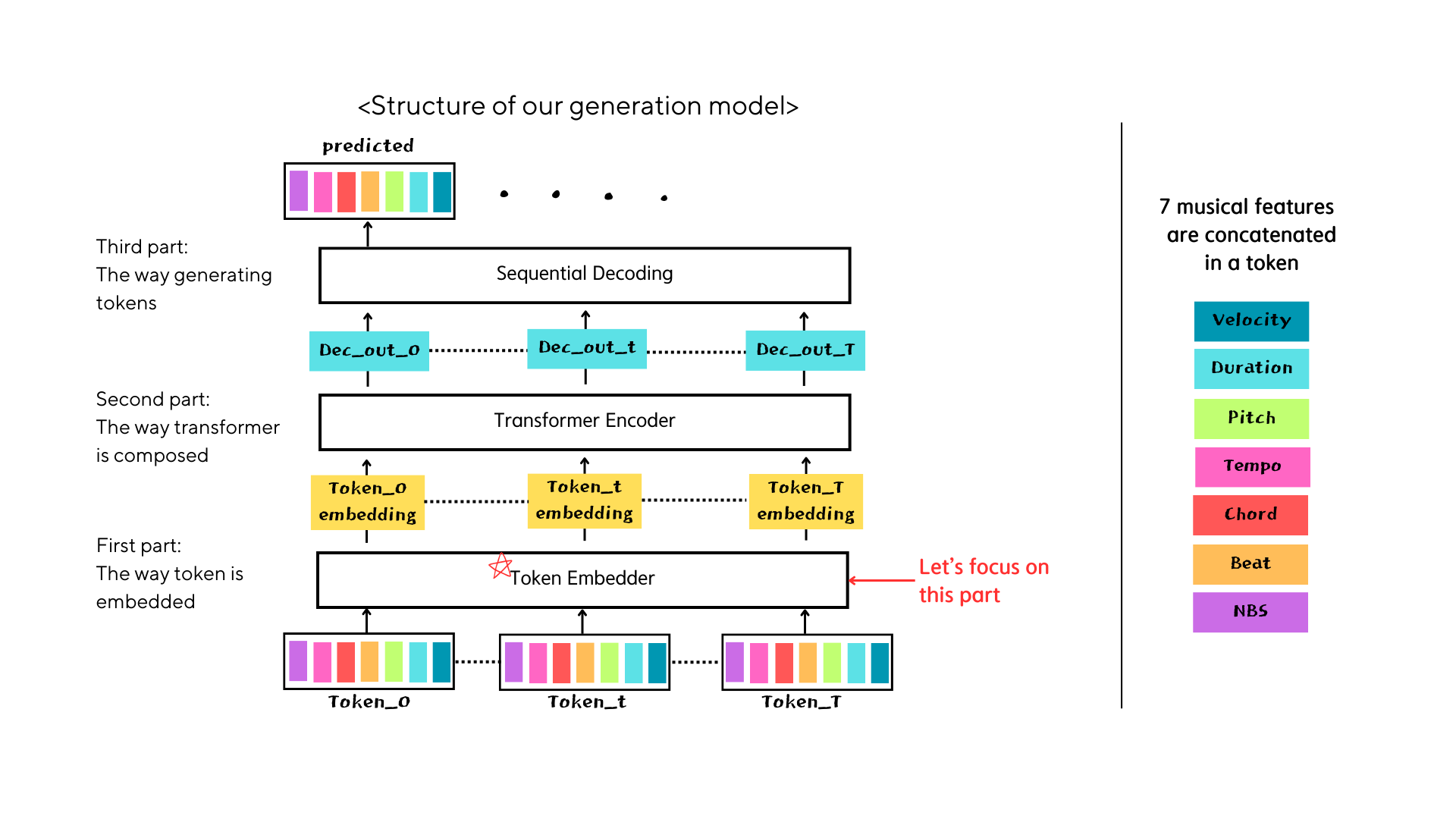
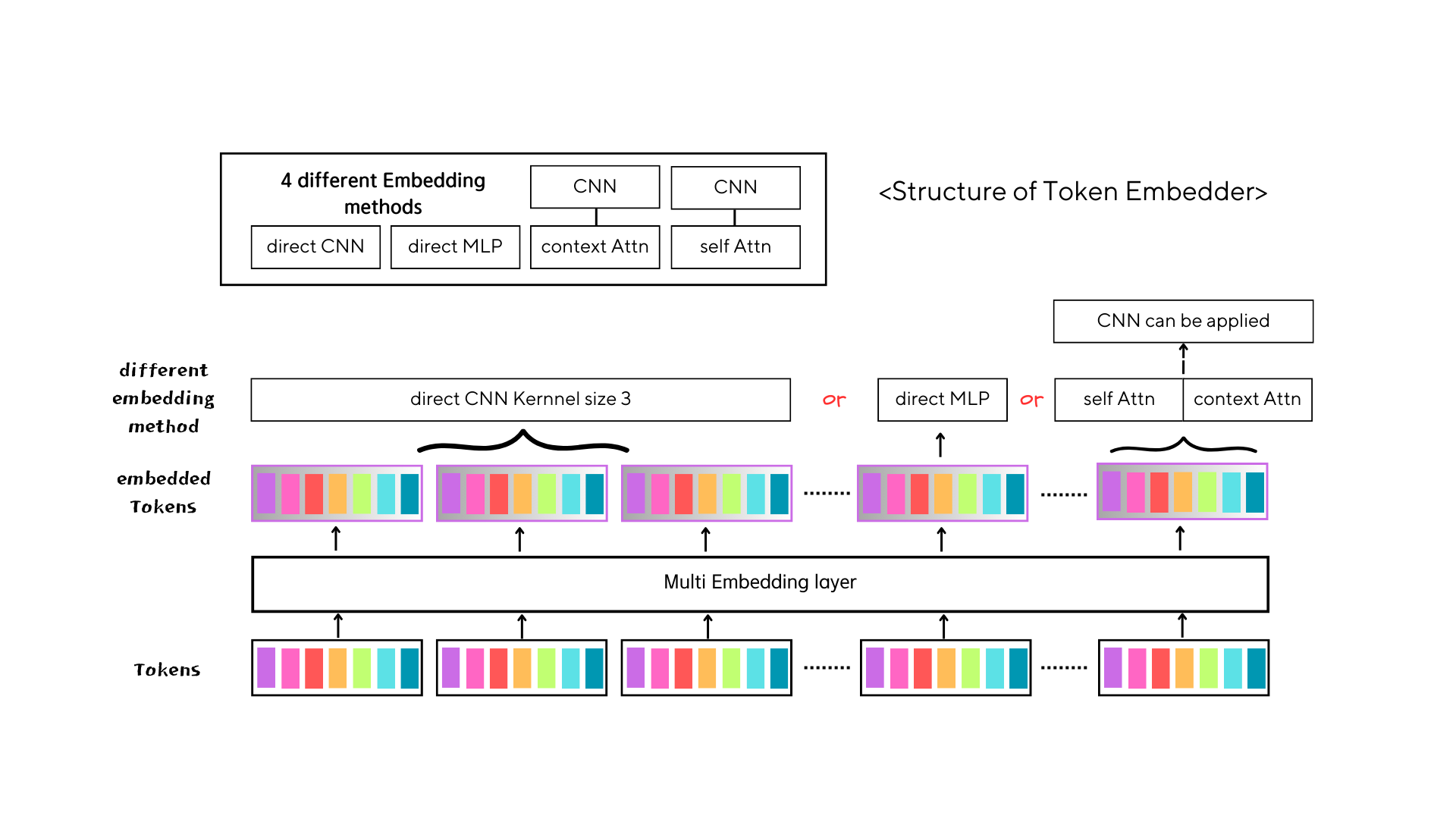
get to the bottom, 4 token embedders
We conducted experiments using four distinct token embedders while keeping the size of the "transformer encoder" constant. Additionally, we transformed the "sequential decoding" sections into "parallel decoding," enabling simultaneous prediction of seven musical features to reduce the consuming time in that part.
Direct CNN
We applied CNN on the embedding of the tokens, in this case the size of in_channels of the CNN is the sum of embedding of 7 features, and the out_channels is d_model.
Direct MLP
By concatenating the embedding of 7 features, we can apply multi layer perceptron(MLP) on it. we tried different layers and hidden_size of MLP.
self attention
We used transformer encoder on summarizing 7 features respectively with different size of layers. While previous methods are concatenating features, attention method is using weighted sum of these values. CLS tokens are used for getting purposed vectors.
context attention
By using learnable vectors(context vectors) as a query for a cross attenton operation. we can easily gain summarized features from the given 7 features.
Data Augmentation
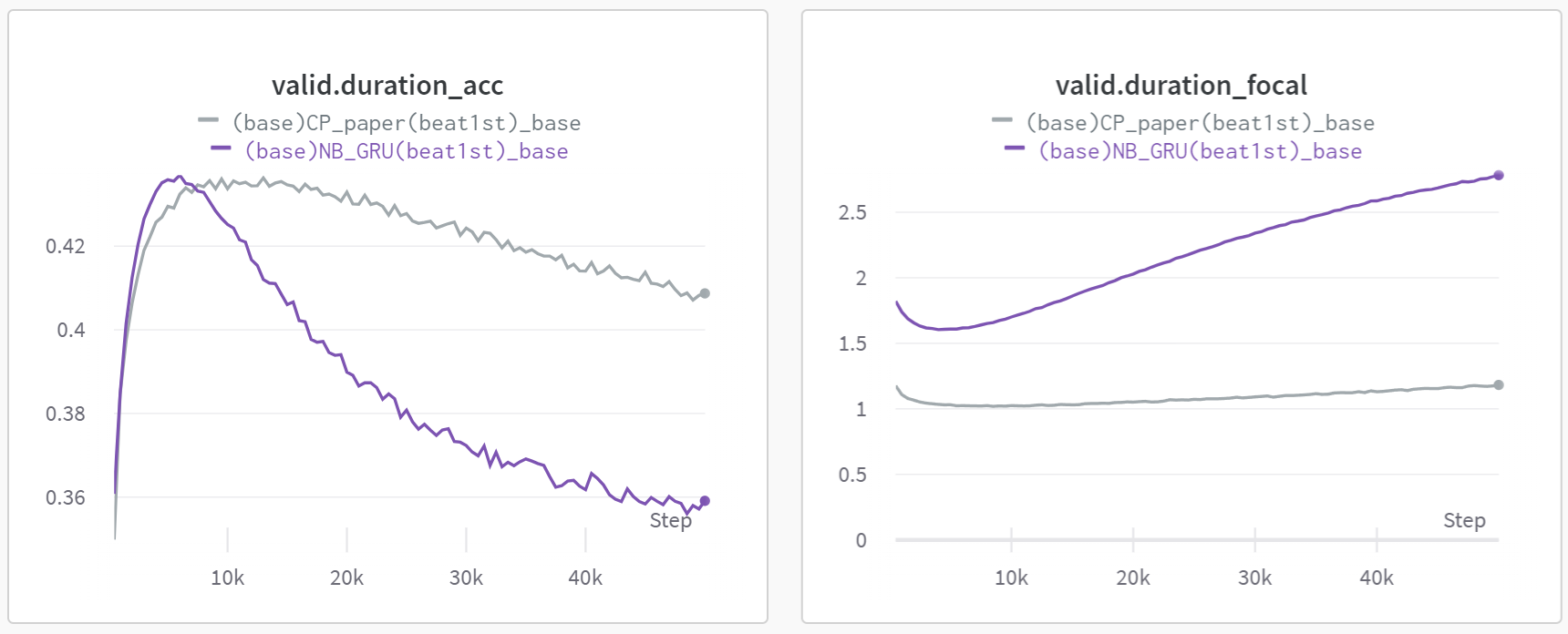
Unfortunately, none of these approaches effectively addressed the overfitting problems associated with NB. Upon analyzing the outcomes of CNN, it became evident that the introduction of CNN actually accelerated overfitting. This observation implies a plausible assumption: the uniqueness of tokens encoded with NB might make it easier for models to memorize token patterns.
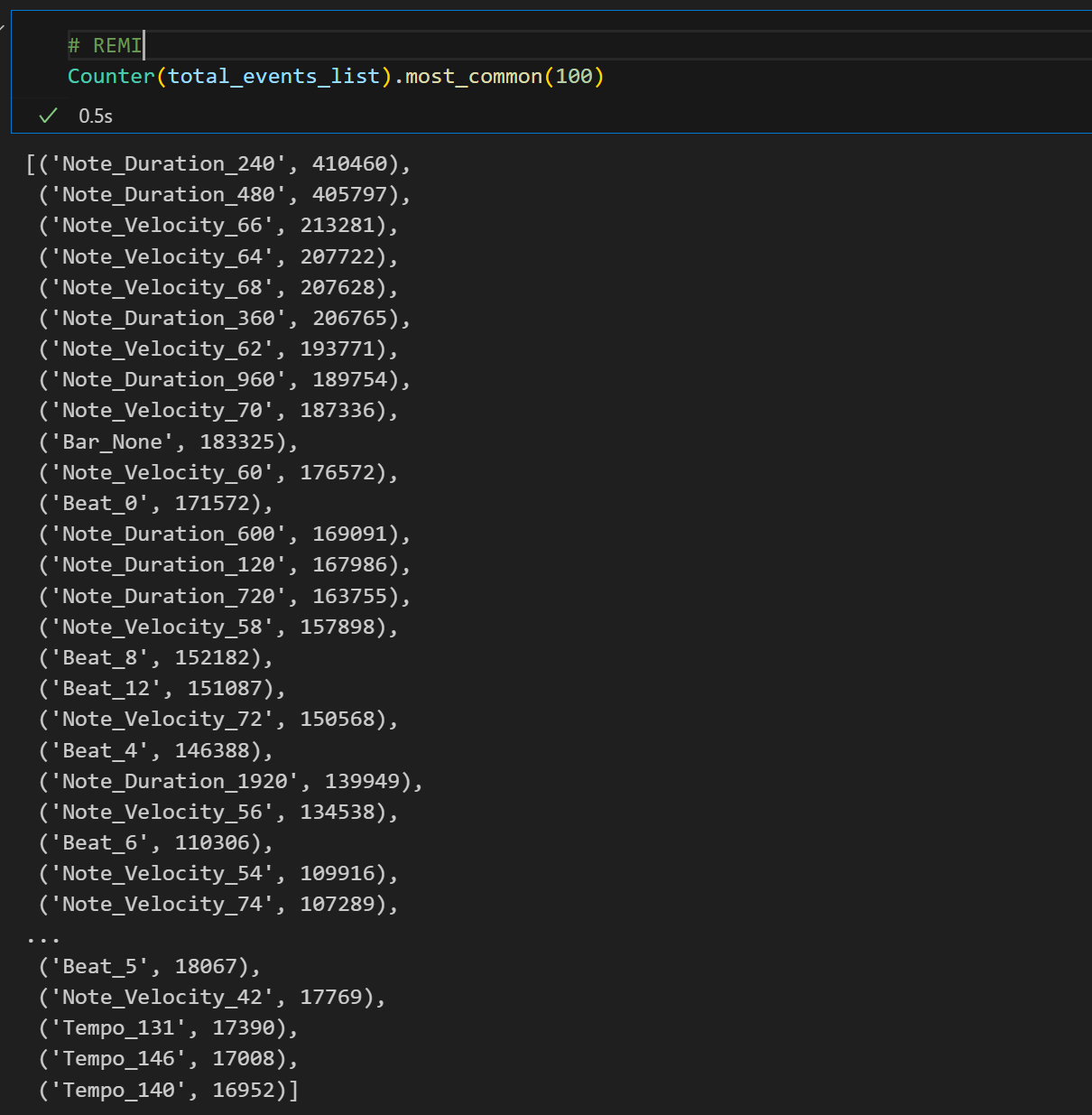
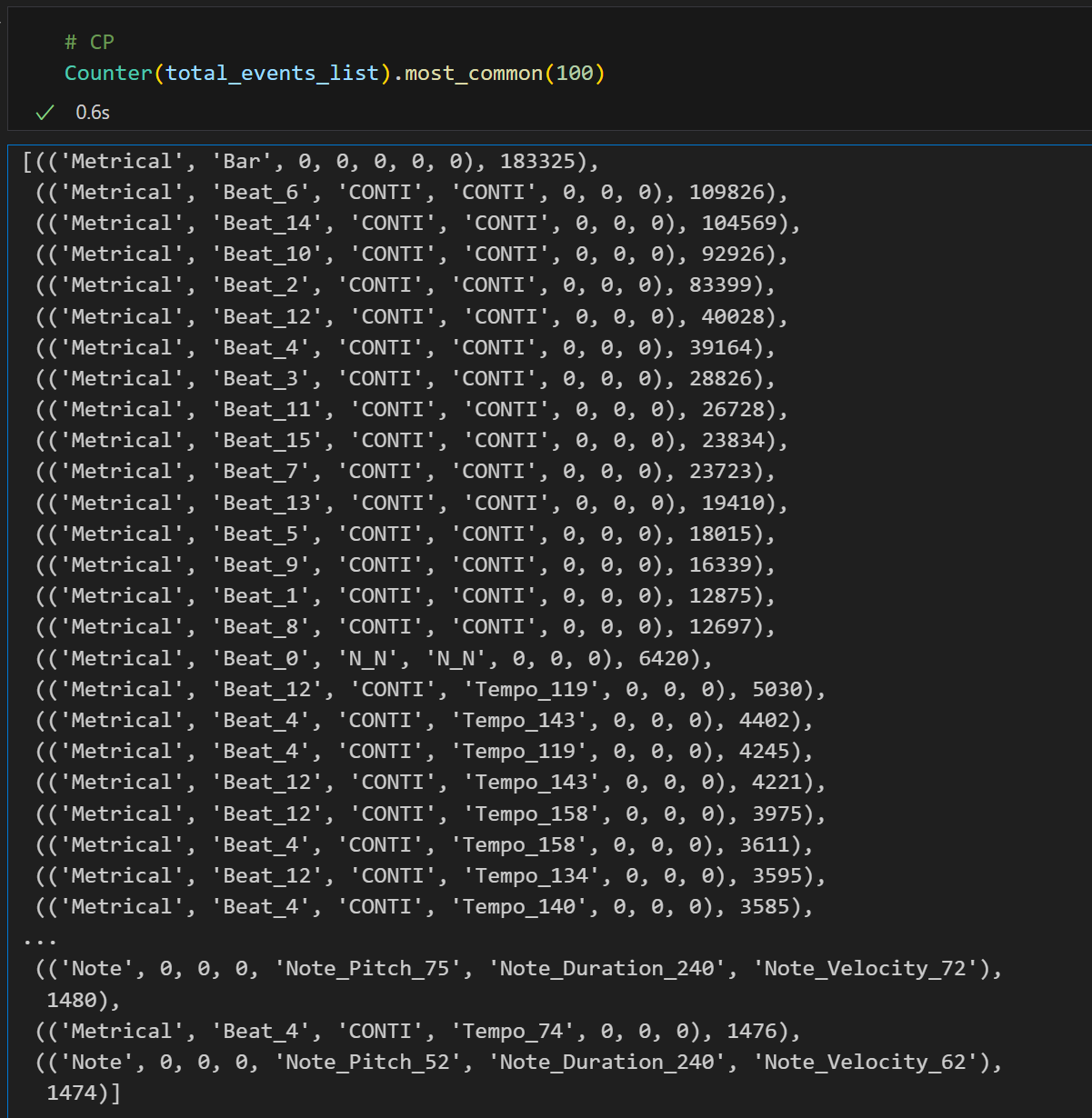
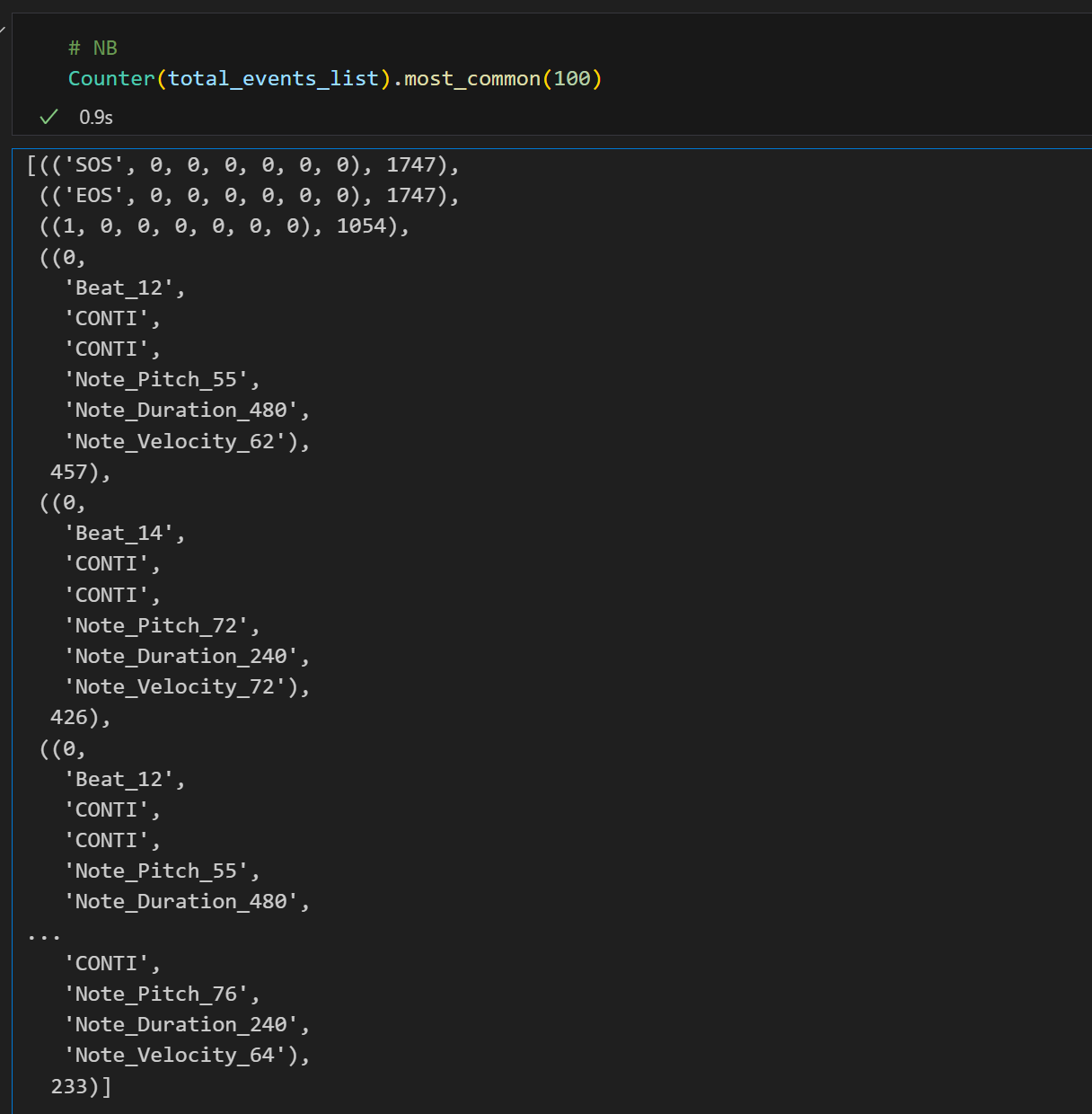
number of tokens in the valid dataset
Within the 2 million tokens, the NB-encoded representation of the most frequently occurring token amounts to 457, excluding metric-related tokens (SOS, EOS, bar_start).
REMI
CP
NB
Augmentation methods
We believed that employing augmentation techniques might resolve the challenges in NB, where the seven musical features are tightly interwoven into a single token. We experimented with three distinct approaches aimed at untangling this information.
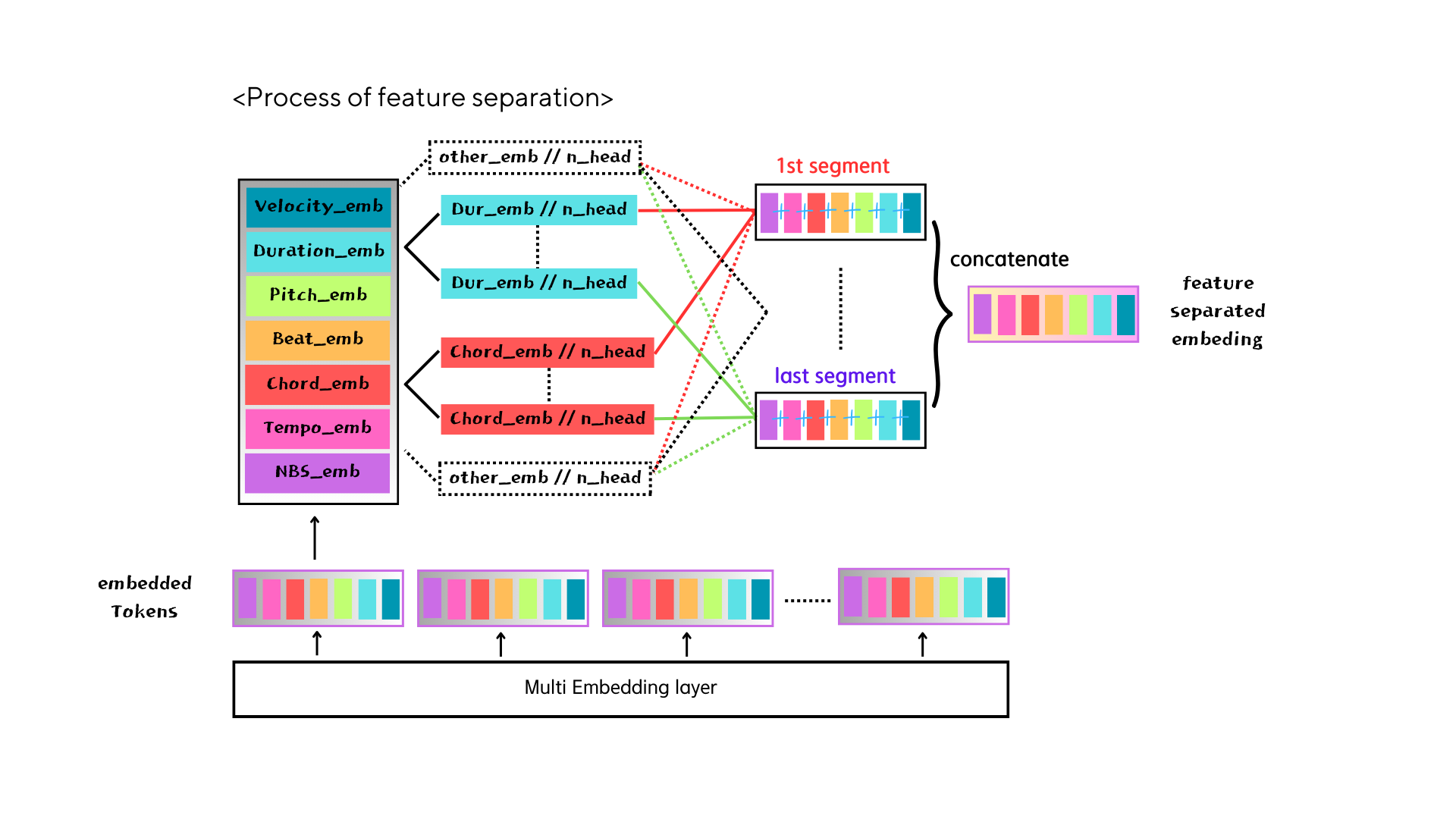
separating 7 feature embeddings
We attempted to distribute the seven features among the number of num_heads in the transformer, aiming to enable the model to perceive all seven features independently. Our anticipation was that tokens could be disentangled through this approach, but unfortunately, it did not yield satisfactory results. It seems that even with manual separation of each feature, the token with distinct embeddings remains unchanged. However, there is potential in utilizing this method differently. We can try it in a later experiment.
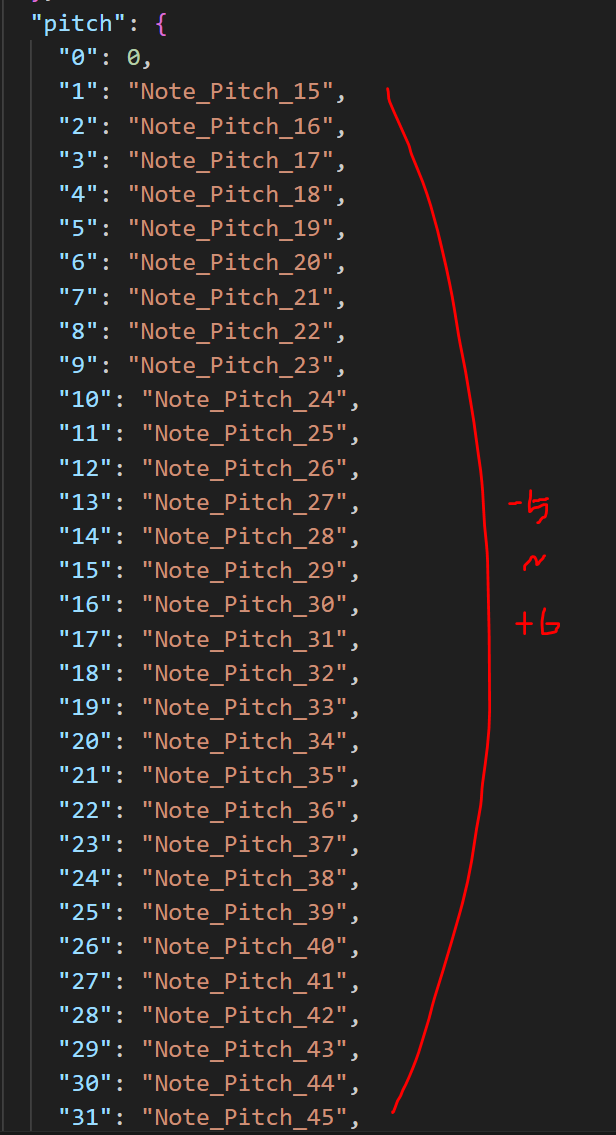
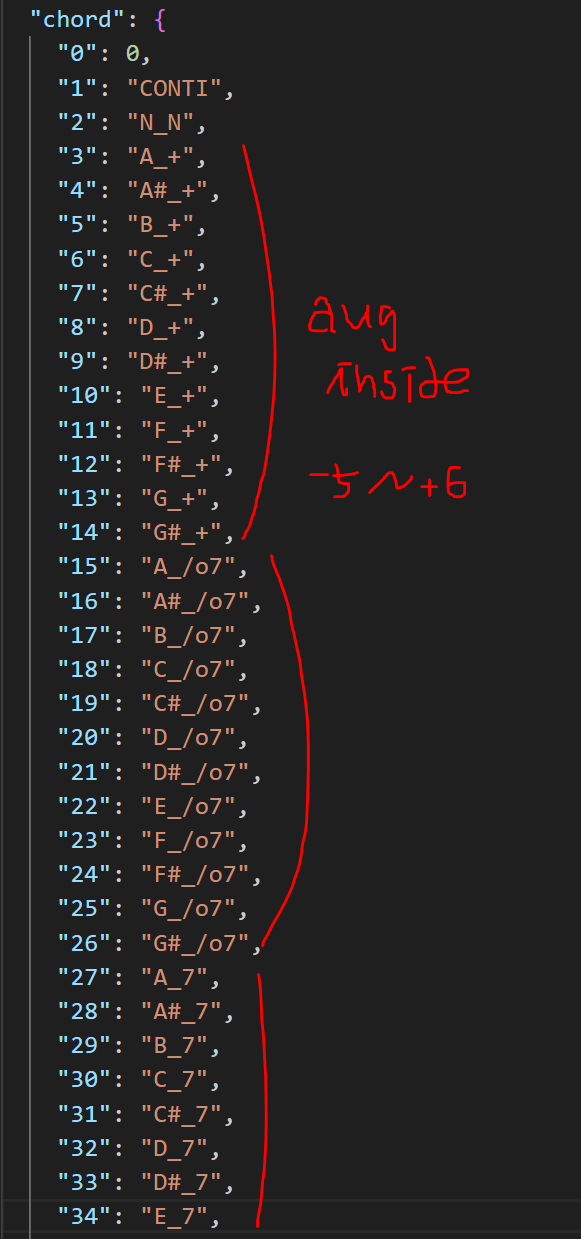
Pitch related
Pitch values and chord values undergo transposition within the range of -5 to +6 values (covering 12 keys). This approach proved highly effective in mitigating overfitting in NB. It appears that this augmentation prevents the model from memorizing all possible variations.
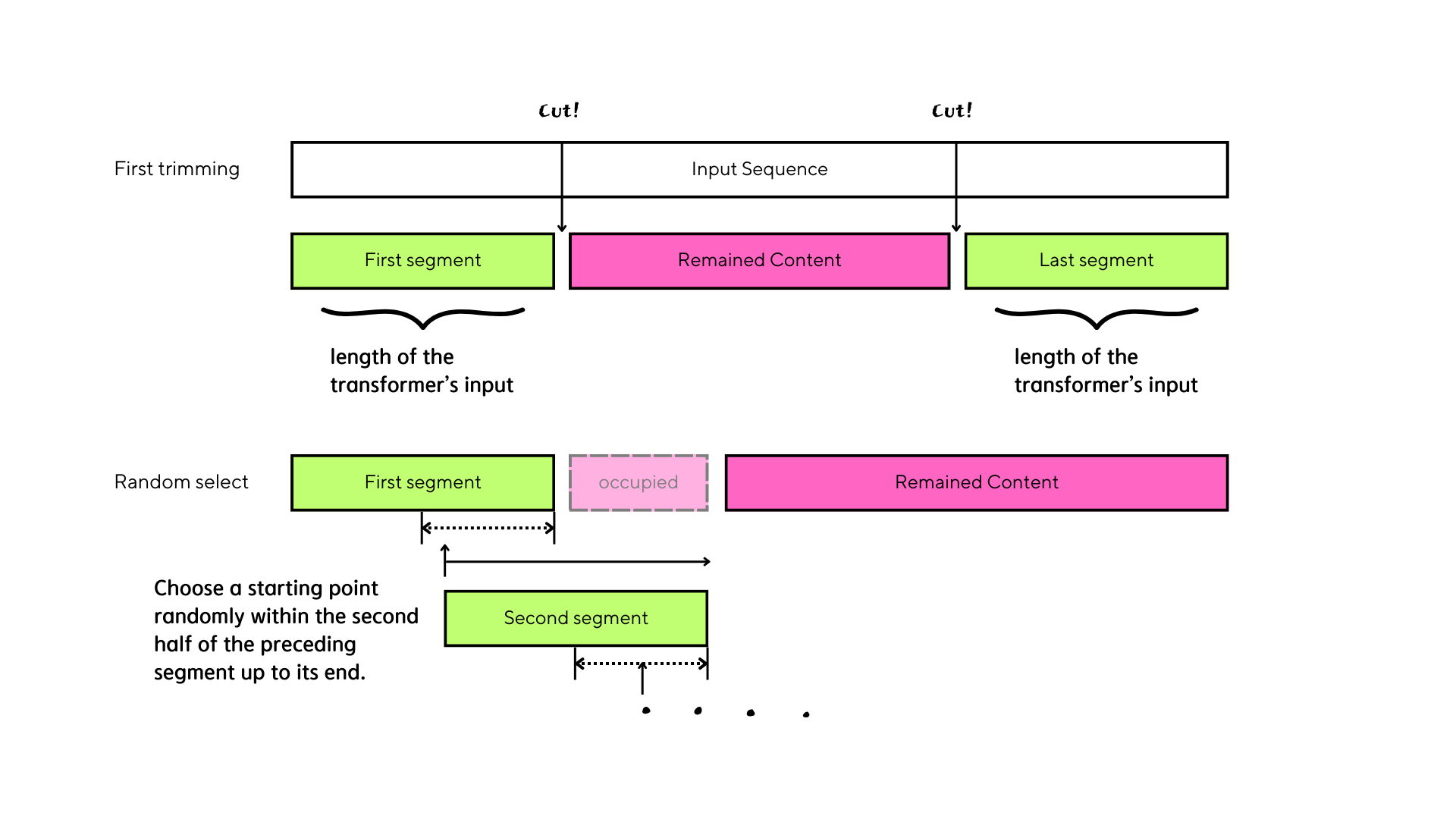
Augment in making segments
In contrast to the previous method, we introduced randomness in segment creation for data generation. Initially, we trimmed both the beginning and ending parts of the tune to match the length of the transformer's input. Subsequently, we randomly selected the content remaining between the first and last segments.
Pitch-first encoding
We implemented pitch-first encoding on NB, as illustrated in the figure below. Notably, pitch-first encoding is exclusive to NB encoding. Our observation indicates that this method enhances the performance of pitch and duration features. This effectiveness arises from the transformer's endeavor to generate hidden vectors that incorporate current position information, specifically beneficial for predictions related to upcoming notes, distinguishing it from beat-first encoding methods.
currently the figure is deleted to protect idea before publication
please let me know if you are intereted in this idea :)
or please wait until our idea is published or opened in a paper form What is Next?
The overall performance of REMI, CP, NB
Despite REMI being the sole method predicting seven musical features sequentially in these three encoding schemes(we restricted our model to use parallel prediction except for REMI for now, but actually CP encoding itself also performs on sequential prediction in "Metric->Note order"), NB demonstrates a performance that is comparable to REMI(This is fabulous because some features like new_bar_started and beat postion are closely related).
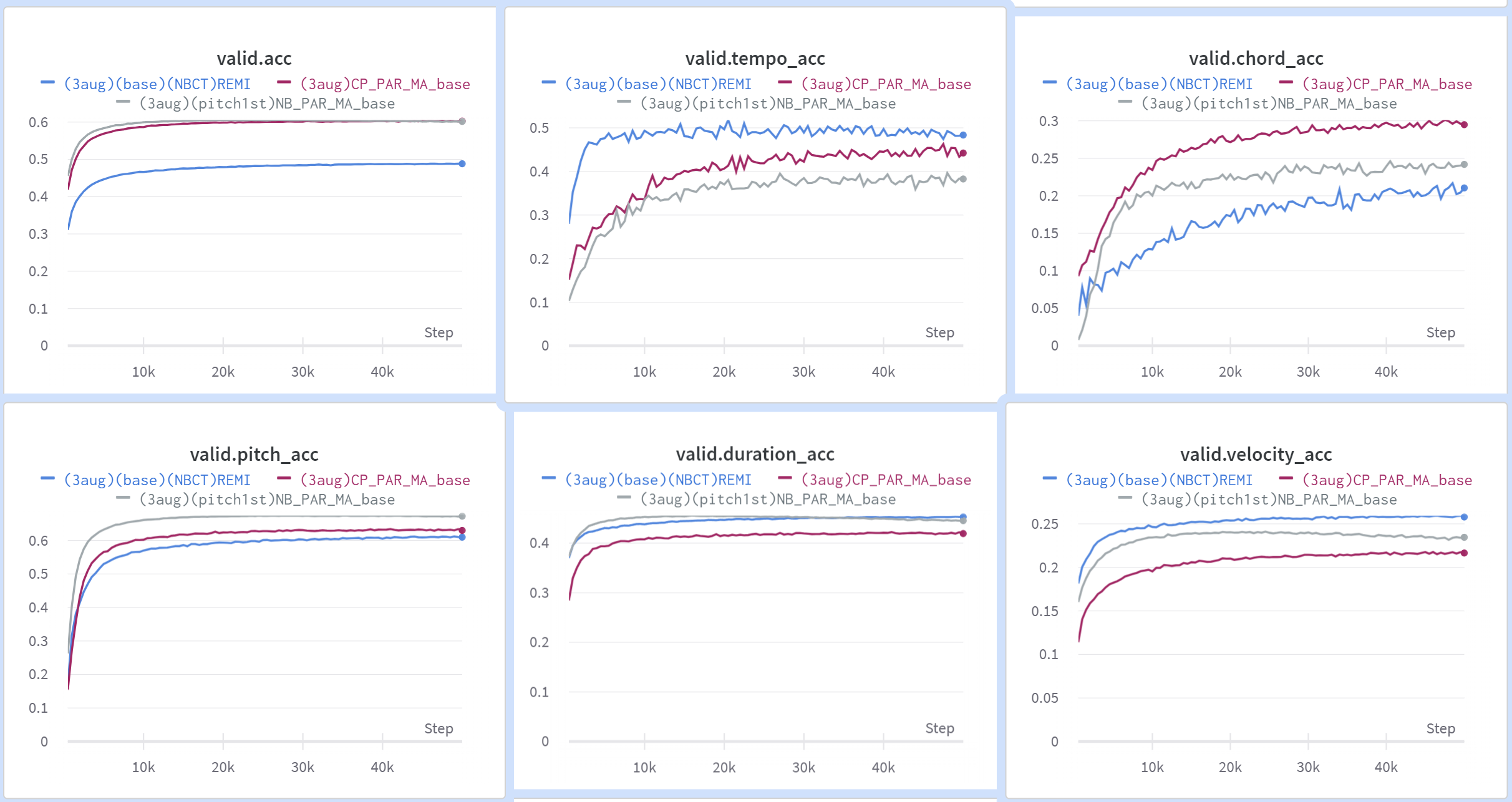
Presently, our emphasis shifts towards the significance of sequential prediction, a crucial aspect linked to the NB encoding scheme. Additionally, we will extend our model's scope from the pop piano cover set (as outlined in the CP word paper) to the Symphony MIDI dataset (referenced in the SymphonyNet paper).
Let's go NB, we can do this!!

One of the best things about https://mp3juice.com.ph is that it gives you control. No need to sign up or commit to anything. Just go in, search your track, and download it instantly. You can find rare songs that aren't even available on major streaming platforms. The fact that it’s mobile-friendly and completely free makes it even more appealing.