In this post I will review the paper MULTITRACK MUSIC TRANSFORMER(Accepted by ICASSP 2023), Hao-Wen Dong et al. arxiv.
Abstract
what makes multitrack music hard
- the number of instruments
- the length of the music segments
- slow inference
Why?
- memory requirements of the lengthy input sequences necessitated by existing representations
Multitrack Music Transformers(MMT)
- achieves comparable performance compared to two recently proposed models in a subjective listening test
- speedups and memory reductions
- examine how self-attention work for symbolic music
Introduction
previous works using transformer on symbolic music
- Music transformer: Generating music with long-term structure(2019), Cheng-Zhi et al.
- Pop music transformer:Generating music with rhythm and harmony(2020), Yu-Siang Huang et al.
- Compound word transformer: Learning to compose full-song music over dynamic directed hypergraphs(2021), Wen-Yi Hsiao et al.
- Symbolic music generation with transformer-GANs(2021), Aashiq Muhamed et al.
previous works applying transformer models to generate multitrack music
- MuseNet(2019), Christine Payne
- LakhNES: Improving multi-instrumental music generation with cross-domain pretraining(2019), Chris Donahue et al.
- MMM: Exploring conditional multi-track music generation with the transformer(2020), Jeff Ens et al.
- FIGARO: Generating symbolic music with finegrained artistic control(2023), Dimitri von Rütte et al.
limitations
- limited set of instruments
- short music segments
What we want to solve
long sequence issue in existing multitrack music representations
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.

Method
preprocessed data by muspy
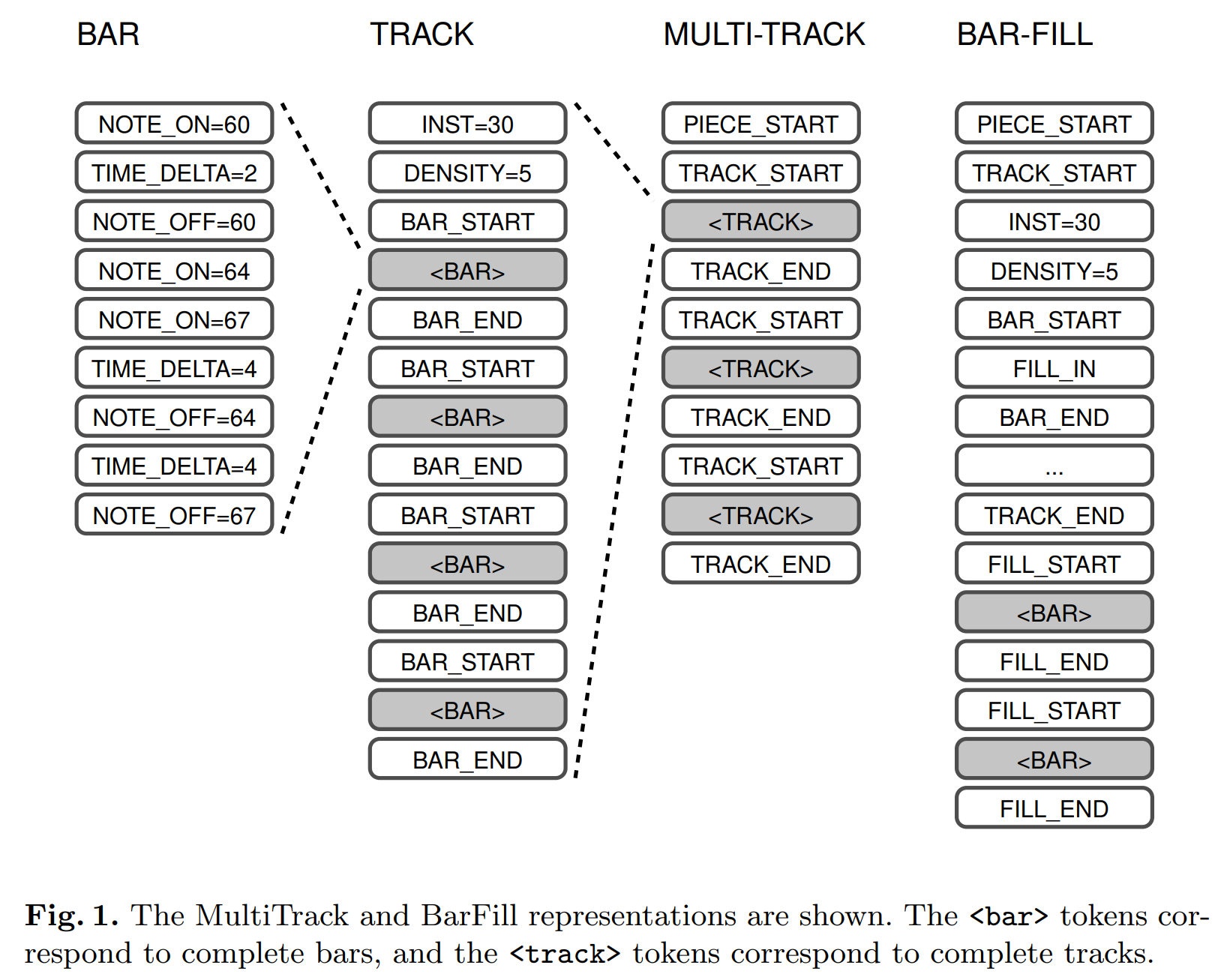
Data Representation
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.

type
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.

beat - position split
duration
instrument
reduced length
On an orchestral dataset(SOD), an encoded sequence of length 1,024 using our proposed representation can represent 2.6 and 3.5 times longer music samples compared to "MMM" and "FIGARO", respectively.
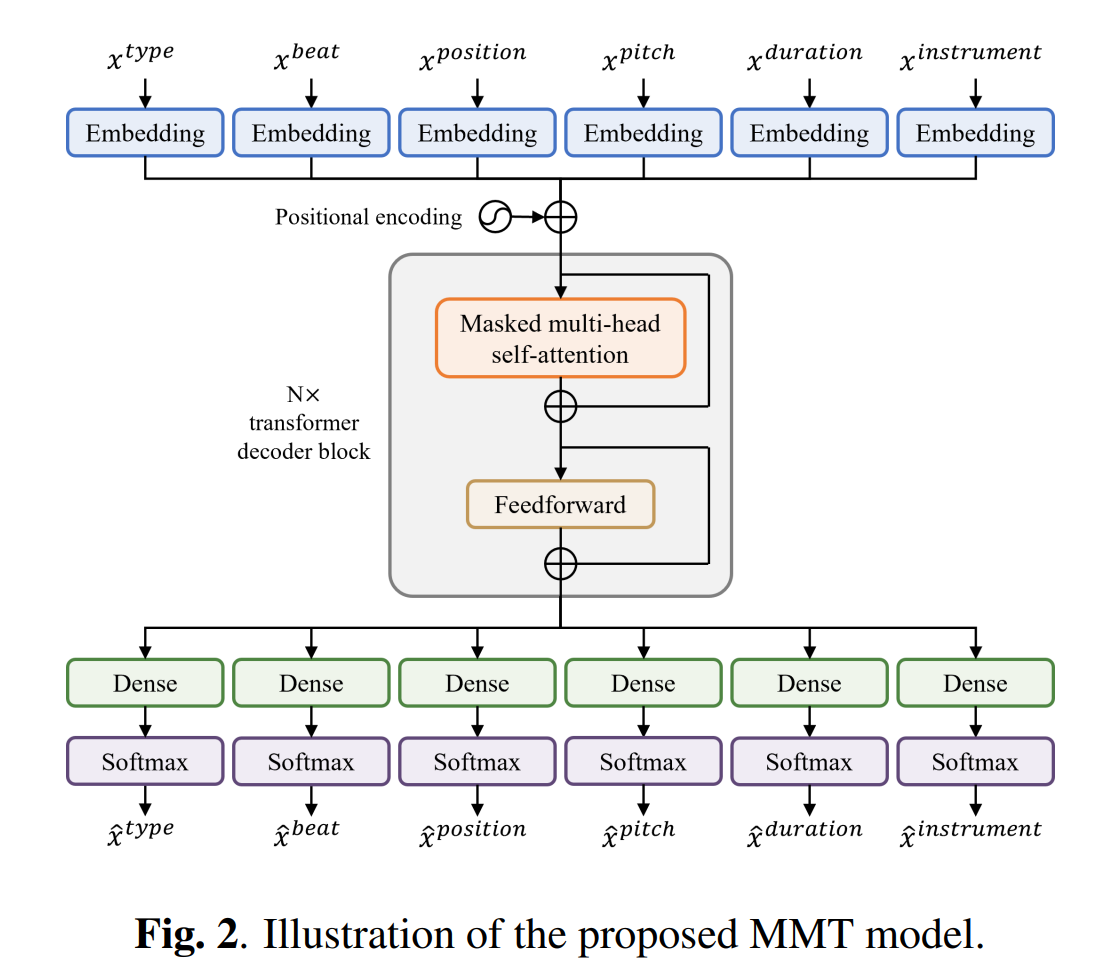
Model
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.
Inference mode
- Unconditioned generation: Only a ‘start-of-song’ event is provided to the model.
- Instrument-informed generation: The model is given a ‘start-of- song’ event followed by a sequence of instrument codes and a ‘start-of-notes’ event to start with.
- N-beat continuation: All instrument and note events in the first N beats are provided to the model.
Sampling
We adopt the top-k sampling strategy on each field and set k to 10% of the number of possible outcomes per field
Applied rule for sampling type
when sampling for Xtype i+1, we set the probability of getting
a value smaller than Xtype i to zero. This prohibits the model from
generating events in certain invalid order
Results
Experiment Setup
- consider Symbolic Orchestral Database(SOD), 5,743 songs (357 hours)
- set the temporal resolution to 12 time steps per quarter note
- discard all drum tracks
- 6 transformer decoder blocks, with a model dimension of 512 and 8 self-attention heads
- All input embeddings have 512 dimensions
- trim the code sequences to a maximum length of 1,024 and a maximum beat of 256
- augment the data by randomly shifting all the pitches by (-5,6)
- validate the model every 1K steps and stop the training at 200K steps
Subjective Listening Test
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.

we conducted a listening test with 9 music amateurs recruited from our social networks
In the questionnaire, each participant was asked to listen to 10 audio samples generated by each model and rate each audio sample according to three criteria—coherence, richness and arrangement.
- For a fair comparison, we trimmed all generated samples to a maximum of 64 beats
- compared with MMM and REMI+ models(from FIGARO)
MMM style representation
from the paper "MMM : Exploring Conditional Multi-Track Music Generation with the Transformer", Jeff Ens et al.
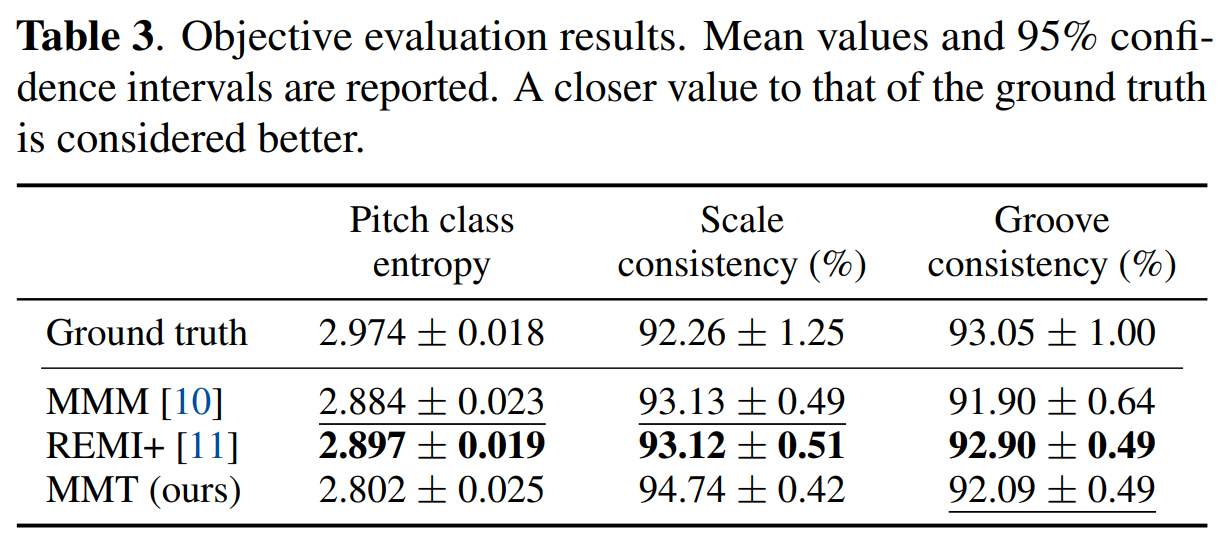
Objective Evaluation
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.
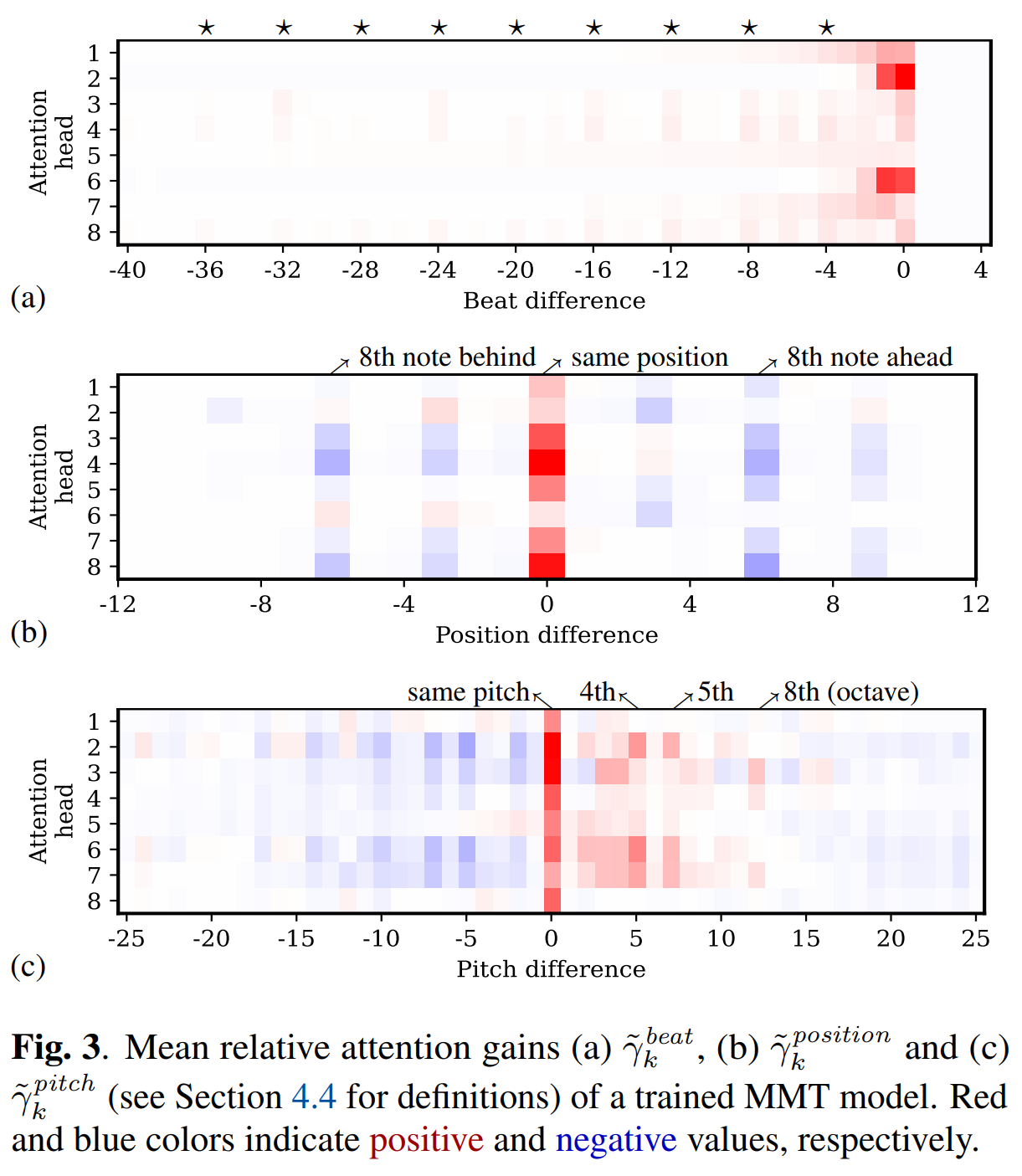
Musical Self-attention
from the paper Multitrack Music Transformers(MMT), Hao-Wen Dong et al.