2. Methodology
2.1 Model Figure
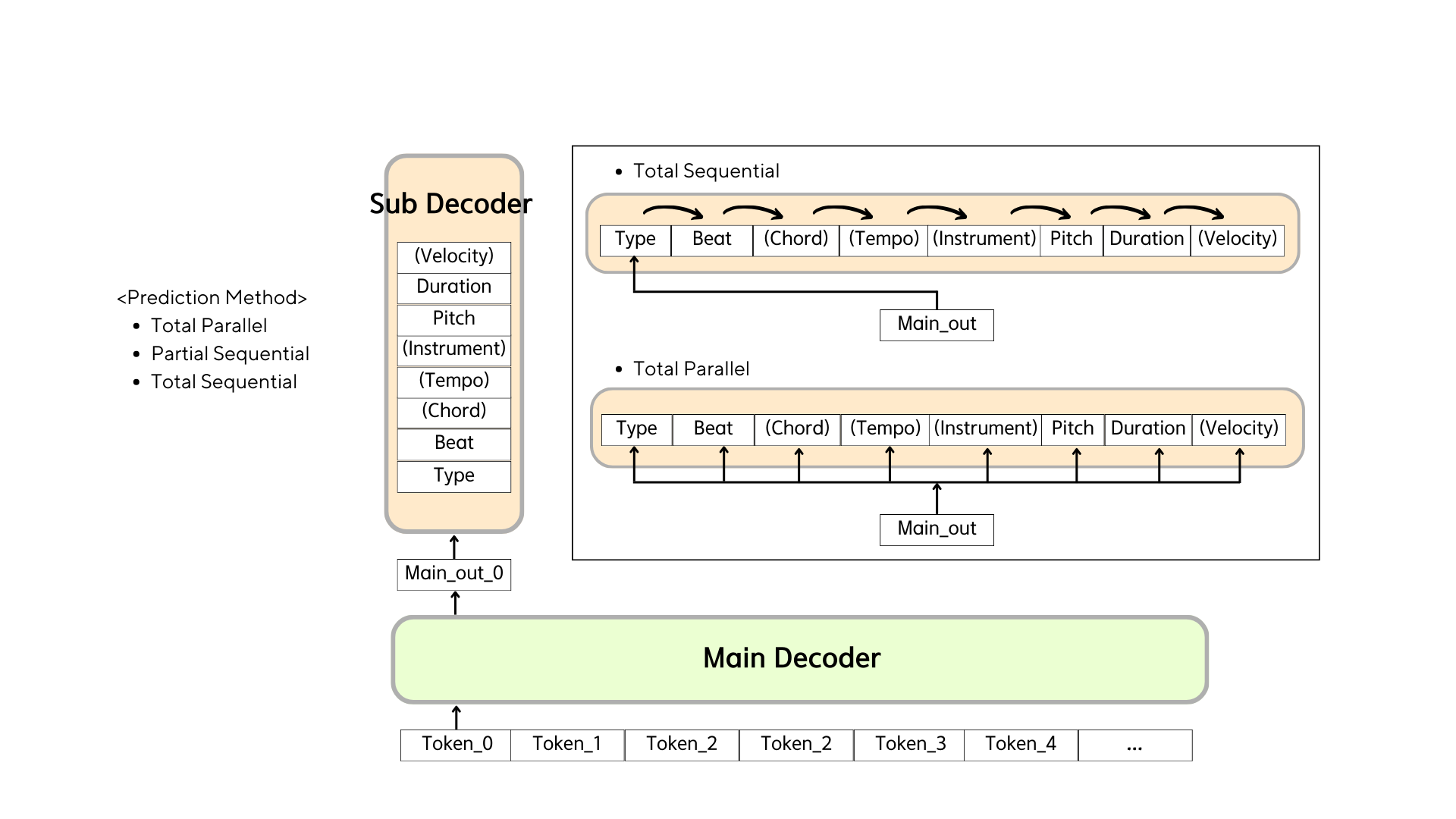
3. Proposed Method
3.1 Data Representation
Note-based Encoding
We propose note-based encoding which is similar to proviously introduced encoding from MusicBert and Multitrack Music Tranformer. In this style we encoded 8 variables in each events. These are (type, beat, chord, tempo, instrument, pitch, duration, velocity).
Different set of features
We prepared 4 different set of features to apply different style of datasets.
4 features: (type, beat, pitch, duration)
5 features: (type, beat, instrument, pitch, duration)
7 features: (type, beat, chord, tempo, pitch, duration, velocity)
8 features: (type, beat, chord, tempo, instrument, pitch, duration, velocity)
4. Experiments
4.1 Experiment Settings
Dataset
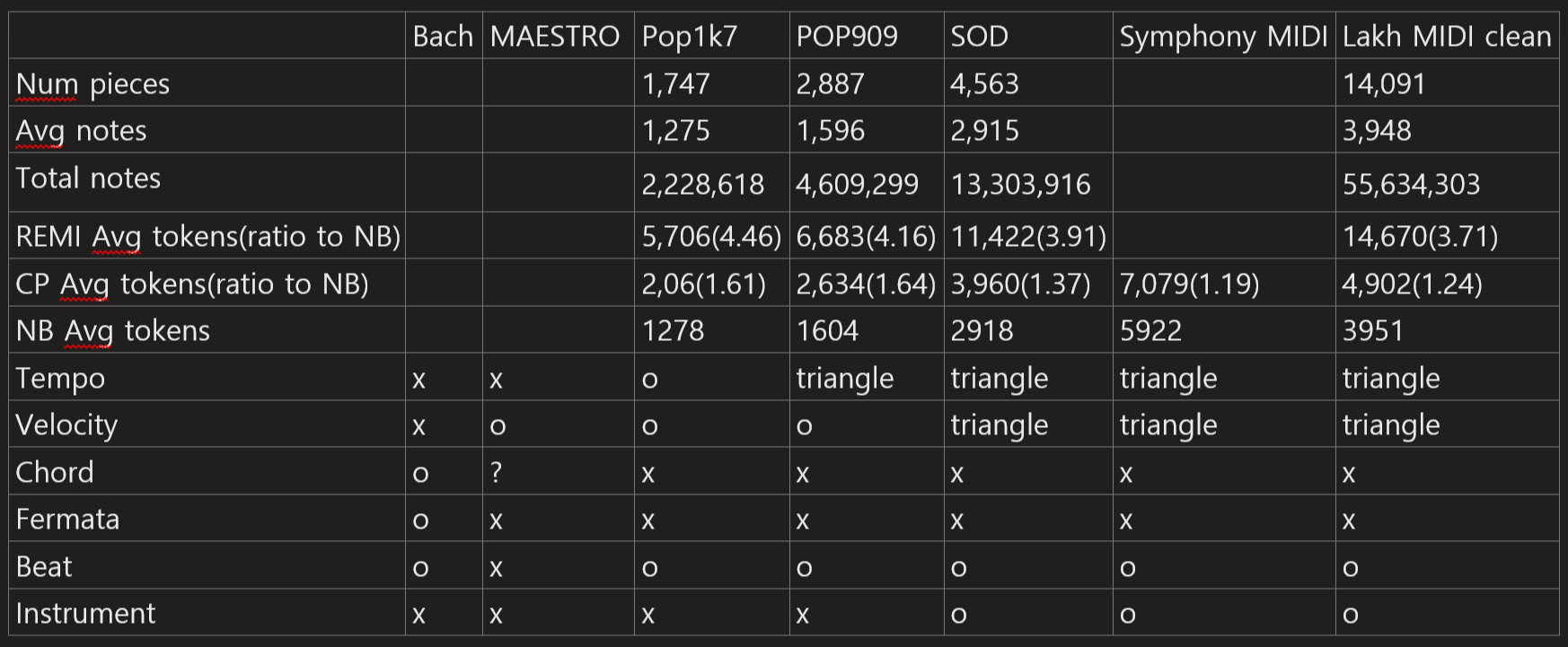
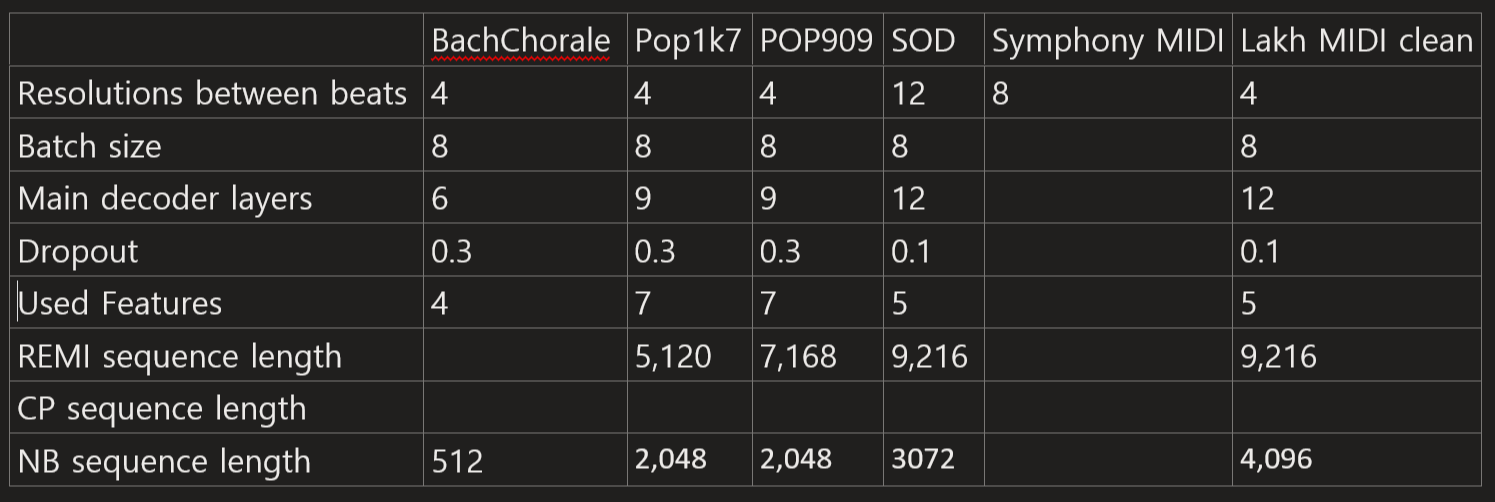
We conduct our experiments on 5 diffenent datasets including Pop1k7, POP909, Symbolic Orchestral Database(SOD), Symphony MIDI, Lakh MIDI clean version datasets. The detail information for these datasets are proposed in Table x. We used 16 instruments by filtering all the 128 MIDI instruments. We used randomly splitted train/valid/test set with ratio of 90/5/5. The pitch and chord varialbes are augmented from -5 to 6, which covers all possible variations. We validate all the models with 100K steps of iterations. However, as some of datasets are small, we adapt different learning rate decay ratio and input sequence length to each dataset. Adapted hyperparamters to each datasets are summarized in Table x.
dataset table x.
dataset table x.
Model and Training
As we use large input sequence which can cover most part of tunes, no sequence aided models are needed. We use Vanilla transformer with learnable positional embeddings. Models's layer number = 6, hidden size = 512, number of attention heads = 8, and FFN hidden = 2048. The batch size is set to 8. We use AdamW optimizier with beta1 = 0.9, beta2 = 0.95 and epsilon = 1e-08, and the weight decay is set to 0.01. We used a single 24gb 4090, A5000 GPUs to each experiment on the Table x.
Evaluation
Objective evaluation
We compare the overall performance of each models with encoding-adapted perplexity calculation.
Subjective evaluation
For sampling we used nucleus sampling(top-p) with 1.0 on p, and used temperature of 1.0.
Appendix
Preprocess Method
- used 16 different types of instruments
- maximum tracks are limited to 16
- used most common 11 ticks per beat values
- used base 24 time signatures, and splitted unusual time with those values
- chord recognition algorithm is used by chorder, we only use pitch between 21~108 MIDI values
- length are limited differently to each datasets
- in Lakh and Symphony dataset we filtered tunes with at least 4 instruments
- number of subsequent empty bars are limited to 4
- maximum durations are limited to length of 8 beats
- selected duration
