[paper review] MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
Paper Review
Paper Link : https://arxiv.org/abs/2106.05630
Abstract & Introduction
제목에 Bert가 들어가는 것에서 눈치를 챌 수 있겠지만 이 논문은 자연어 처리 분야의 BERT모델을 symbolic music domain에 적용을 한 내용을 다루고 있다.
Inspired by the success of pre-training models in natural language processing, in this paper, we develop MusicBERT, a large-scale pre-trained model for music understanding.
모델의 구조나 학습의 방식을 제안한 것과 더불어 이 논문은 Million MIDI Dataset (MMD)이라는 새로운 데이터셋을 만든 것에 contribution이 있다고 볼 수 있다.
To this end, we construct a large-scale symbolic music corpus that contains more than 1 million music songs.
논문이 강조하는 것은 NLP에서의 방식을 그대로 적용하는 것은 그리 좋은 결과를 만들어내지 못한다는 것이다. 이를 해결하기 위해 논문에서는 OctupleMIDI encoding and barlevel masking strategy라는 두 가지 mechanism이 제안이 되었다.
The authors are saying that simply adopting pre-training techniques from NLP to symbolic music only results in marginal improvements, meaning that the results are not substantial.
Why BERT & Obstacles
Labled data를 활용하는 방식의 한계를 넘어서기 위해 제안된 Unlabeled data를 통해 pre-trained model을 down stream task에 적용하는 BERT와 같은 모델은 성능이 좋은 것임에는 틀림이 없지만,
Since the labeled training data for each music understanding task is usually scarce, previous works (Liang et al., 2020; Chuan et al., 2020) leverage unlabeled music data to learn music token embeddings, similar to word embeddings in natural language tasks. Unfortunately, due to their shallow structures and limited unlabeled data, such embedding-based approaches have limited capability to learn powerful music representations.
First Contribution : OctupleMIDI
먼저 구조적structural으로나 음악이 가지는 특징 때문에나 symbolic token을 만드는 작업은 NLP에 비해 어려우며,
First, since music songs are more structural (e.g., bar, position) and diverse (e.g., tempo, instrument, and pitch), encoding symbolic music is more complicated than natural language.
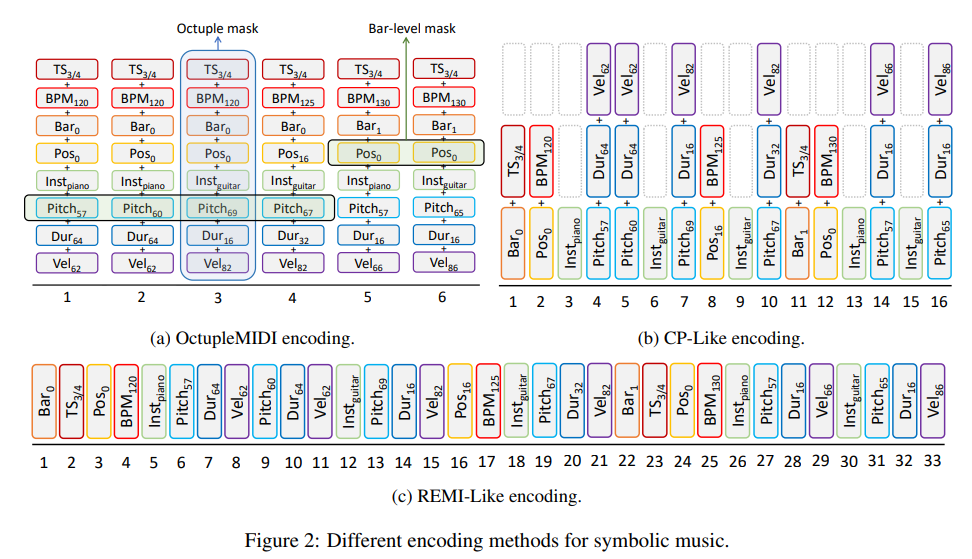
pianoroll-like and MIDIlike 와 같은 방식은 토큰의 길이가 너무 길어진다는 단점이 있다.
The existing pianoroll-like (Ji et al., 2020) and MIDIlike (Huang and Yang, 2020; Ren et al., 2020) representations of a song are too long to be processed by pre-trained models.
그렇기에 본 논문에서는 OctupleMIDI라는 encoding 방식을 고안해 냈다.
Second Contribution : bar-level masking strategy
음악 도메인에서의 토큰의 정보는 BERT에서 사용이 되는 text의 토큰과는 다르므로 BERT에서 사용이 되는 mask는 변형이 되어 사용이 되어야 한다.
Second, due to the complicated encoding of symbolic music, the pre-training mechanism (e.g., the masking strategy like the masked language model in BERT) should be carefully designed to avoid information leakage in pre-training.
Third Contribution : Million MIDI Dataset (MMD)
pre-training 할거라면 더 큰 데이터셋이 필요하다.
Third, as pre-training relies on large-scale corpora, the lack of large-scale symbolic music corpora limits the potential of pre-training for music understanding.
SOTA in four downstream tasks
멜로디 짝을 맞추기, 반주 짝을 맞추기, 장르 분류, 스타일 분류와 같은 네 가지의 downstream task에서 SOTA를 달성 했다고 한다.
We fine-tune the pre-trained MusicBERT on four downstream music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification, and achieve state-of-the-art results on all the tasks.
Related Works
Symbolic Music Understanding
- Huang et al. (2016); Madjiheurem et al. (2016) regard chords as words in NLP and learn chords representations using the word2vec model.
- Herremans and Chuan (2017); Chuan et al. (2020); Liang et al. (2020) divide music pieces into non-overlapping music slices with a fixed duration and train the embeddings for each slice.
- Hirai and Sawada (2019) cluster musical notes into groups and regard such groups as words for representation learning.
Symbolic Music Encoding
- In pianoroll-based methods (Ji et al., 2020; Brunner et al., 2018), music is usually encoded into a 2-dimensional binary matrix, where one dimension represents pitches, and the other represents time steps.
paper link : https://arxiv.org/abs/2010.08091
In a pianoroll-like representation, each note in a piece of music is divided into multiple small fixed intervals, such as quarter notes or eighth notes, and each of these intervals is represented by a token. For example, a quarter note might be represented by 8 consecutive tokens. The problem with this representation is that it is not efficient, as each note is divided into many small intervals, which leads to a large number of tokens being used to represent the piece of music.
- REMI (Huang and Yang, 2020) improves the basic MIDI-like encoding using note-duration, bar, position, chord, and tempo.
paper link : https://arxiv.org/abs/2002.00212
In MIDI-like representation, a note in a piece of music is encoded into several tokens based on MIDI events. This representation is more compact than the pianoroll-like representation and has been widely used in music generation tasks. The advantage of this representation is that it uses fewer tokens to represent each note, making the overall representation shorter and more manageable.
Methodology
OctupleMIDI
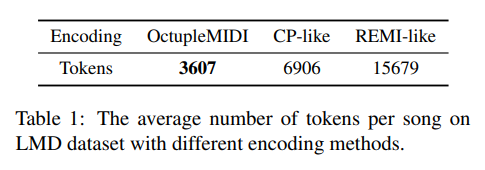
Each octuple token corresponds to a note and contains 8 elements, including time signature, tempo, bar, position, instrument, pitch, duration, and velocity.
Time Signature
the denominator is a power of two in range [1, 64]
the numerator is an integer in range [1, 128]
there are 254 different valid time signatures in OctupleMIDI
the authors of the paper added a procedure to limit the length of the bar by dividing a bar with a duration longer than two whole notes into several equal-duration bars, each of which is no longer than two whole notes. This helps keep the size of the representation manageable and maintain the computational efficiency of the model. The statement "there are 254 different valid time signatures in OctupleMIDI" indicates that the set of valid time signatures has been limited to 254, as a result of this procedure.
Tempo
For OctupleMIDI encoding, we quantize tempo values to 49 different values from 16 to 256, forming a geometric sequence.
A geometric sequence is a sequence of numbers where each term after the first is found by multiplying the previous term by a fixed, non-zero number called the common ratio.
Bar and position
In the coarse level, we use 256 tokens ranging from 0 to 255 to represent the bar, supporting up to 256 bars in a music piece, which is sufficient in most cases.
In the fine-grained level (inside each bar) we need 128 tokens to represent position since the duration of a bar is no more than two whole notes, as described above. For example, in a bar with a time signature of 3/4, the possible value of position is from 0 to 47.
Position은 Time Signature를 고려해서 계산하면 되는 것 같다. 같은 position 값인 16이라도 time signature가 3/4이면 그 값은 whole note를 64개로 본다고 했으니까 1바가 가지는 총 48개의 값 중에서 2번째 비트가 되고, time signature가 4/4가 되면 1바가 가지는 총 64개의 값에서 2번째 비트가 된다. 6/8에서는 1바가 가지는 48개의 값에서 3번째 비트가 된다.
Instrument
According to the MIDI format, we use 129 tokens to represent instruments
Pitch
For notes of general instruments, we use 128 tokens to represent pitch values following the MIDI format.
Duration
we propose a mixed resolution method: using high resolution (e.g., sixty-fourth note) when the note duration is small and using a low resolution (e.g., thirtysecond note or larger) when the note duration is large. Specifically, we use 128 tokens to represent duration, starting from 0, with an increment of sixty-fourth note for the first 16 tokens, and double the increment (i.e., thirty-second note) every time for next 16 tokens.
Velocity
We quantize the velocity of a note in the MIDI format into 32 different values with an interval of 4 (i.e., 2, 6, 10, 14, . . . , 122, 126).
Masking Strategy
BERT에서 사용하듯이 하나의 token을 naive 하게 마스킹하는 것은 음악의 토큰에 있어서는 그리 효율적이지 못하다.
A naive masking strategy is to randomly mask some octuple tokens (mask all the elements in an octuple token), which is denoted as octuple masking as shown in Fig. 2a.
왜냐하면 Instrument와 position value, chord의 경우에는
Specifically, time signature, tempo, and bar usually remain the same in the same bar. Instrument and position values in the same bar follow regular patterns, where the instrument is limited to a small-scale fixed set of values, and the position values are non decreasing. Moreover, a chord is a fixed combination of pitches, which always appear in adjacent positions.
masking technic
For the masked elements, 80% of them are replaced with [MASK], 10% of them are replaced with a random element, and 10% remain unchanged, following the common practice (Devlin et al., 2018; Joshi et al., 2020; Liu et al., 2019).
adopt a dynamic masking strategy, where the masked sequence is generated every time when feeding a sequence to the model.
Pre-training Corpus
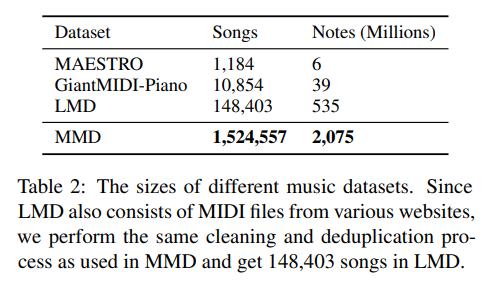
1) the MAESTRO dataset (Hawthorne et al., 2019) contains only one thousand piano performances
2) the GiantMIDI-Piano dataset (Kong et al., 2020a,b) contains slightly larger but still only ten thousands of piano performances
3) the largest open-sourced symbolic music dataset by now is the Lakh-MIDI Dataset (LMD) (Raffel, 2016), which contains about 100K songs.
먼저 클리닝 작업을 한 뒤에,
we first crawled a large amount of music files, cleaned files that are malformed or blank, and then converted those files into our symbolic music encoding.
중복된 자료를 제거deduplication하는 작업을 진행했다고 한다.
Therefore, we developed an efficient way to deduplicate them: we first omitted all elements except instrument and pitch in the encoding, then got hash values of the remaining sequence and use it as the fingerprint of this music file
Experiment & Results
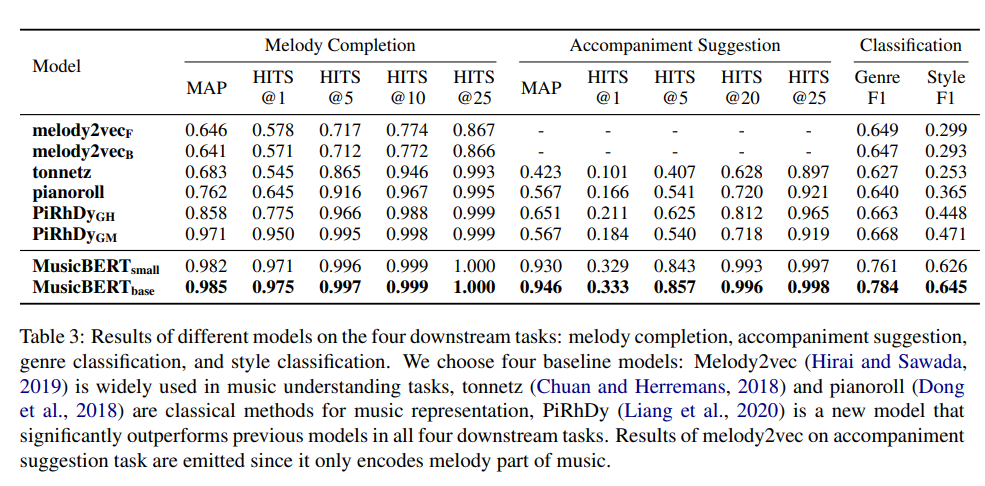
Pre-training Setup
We pre-train two versions of MusicBERT:
1) MusicBERTsmall on the smallscale LMD dataset
2) MusicBERTbase on the large-scale MMD dataset
we randomly sample segments with a length of 1024 tokens for pre-training.
we pretrain MusicBERT on 8 NVIDIA V100 GPUs for 4 days, and there are 125,000 steps in total, with a batch size of 256 sequences, each has a maximum length of 1024 tokens.
We use Adam (Kingma and Ba, 2014) optimizer with β1=0.9, β2=0.98, epsilon=1e-6 and L2 weight decay of 0.01.
β1: A parameter that controls the exponential decay rate for the moving average of the first moment (mean) estimates. A value of 0.9 means that the first moment estimate will decay by a factor of 0.1 each iteration.
β2: A parameter that controls the exponential decay rate for the moving average of the second moment (variance) estimates. A value of 0.98 means that the second moment estimate will decay by a factor of 0.02 each iteration.
epsilon: A small value added to the denominator of the division operation to prevent division by zero. A value of 1e-6 means that 1e-6 is added to the denominator.
L2 weight decay: A regularization term applied to the weights of the model to prevent overfitting. A value of 0.01 means that the weights will be penalized by a factor of 0.01 each iteration.
Fine-tuning MusicBERT
We fine-tune MusicBERT on four downstream tasks: two phrase-level tasks (i.e., melody completion and accompaniment suggestion) and two song-level tasks (i.e., genre and style classification).
Method Analysis(Ablation Study)
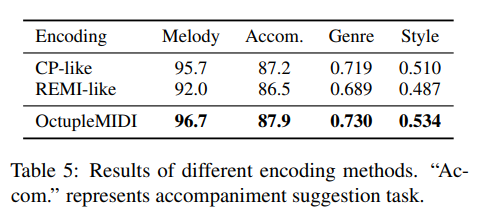
Effectiveness of OctupleMIDI
We compare our proposed OctupleMIDI encoding with REMI (Huang and Yang, 2020) and CP (Hsiao et al., 2021) by training MusicBERTsmall models with each encoding respectively and evaluate on downstream tasks.
For phrase-level tasks (melody completion and accompaniment suggestion), the
input sequence length is usually less than the truncate threshold. Thus, benefiting from the short representation, OctupleMIDI significantly reduces the computational complexity of the Transformer encoder, which is only 1/16 of that with REMI-like encoding and 1/4 of that with CP-like encoding
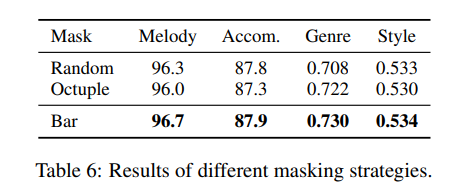
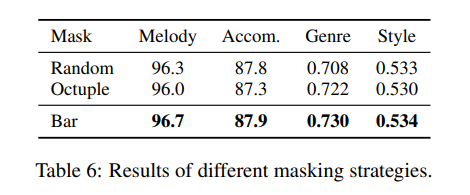
Effectiveness of Bar-Level Masking
We compare our proposed bar-level masking strategy with two other strategies:
1) Octuple masking, as mentioned in Sec. 3.3 and Fig. 2a
2) Random masking, which randomly masks the elements in the octuple token similar to the masked language model in BERT.
Effectiveness of Pre-training
we compare the performance of MusicBERTsmall with and without pre-training.

I like not symbolic music, but finding some tracks and endowing them with their own meaning and signs, connecting them with some significant moments. In short, I love it when every song has some meaning to me. To download songs, I prefer Tubidy because it's free in the first place. But in general, it's cool that the quality here does not get worse, as in other alternative services. So be sure to check it out.