[paper review] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Paper Review
목록 보기
15/17

This post focuses on code structures based on lucidrains' work. As lucidrain used several techniques (axial positional embedding, hyper connections), I will also look into those methods.
Transfusion
Transfusion creates a single model that fully integrates text and images without losing information. Key ideas:
- Train the model on both text and images at the same time.
- Language modeling for text (predicting the next word).
- Diffusion for images (gradually building an image from random noise).
- Use separate mechanisms to process text tokens (discrete) and image patches (continuous).
- For text, the model uses causal attention (which focuses only on past data), while for images, it uses bidirectional attention (which looks at the entire image).
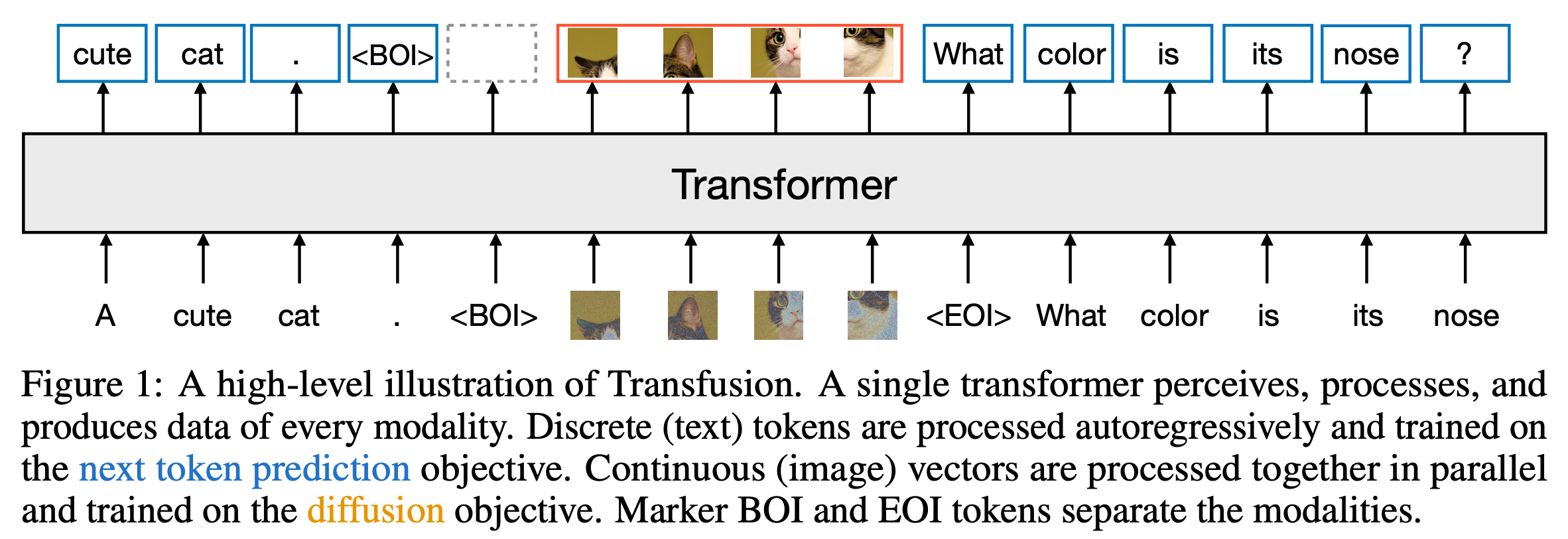
from the paper "Transfusion", Zhou et al. (2024)
Axial Positional Embedding
Continuous Axial Positional Embedding Process
-
Input Setup:
The input is a high-dimensional tensor (e.g., video tensor of shape (1, 8, 16, 32, 512)->batch x frame x height x width x dimension).
The embedding aims to represent positions in each axis (e.g., frames, height, width). -
Per-Axis MLP Generation:
For each axis (e.g., 8, 16, 32):
- Create a sequence of positions using torch.arange, e.g., [0, 1, 2, ...].
- Add an extra dimension to the sequence with rearrange(seq, 'n -> n 1') to prepare it as a 2D input for the MLP (shape [N, 1]).
- Pass this sequence into the MLP, which maps the position (1D) to a high-dimensional embedding (e.g., 512D).
- Independent Embedding for Each Axis:
Each axis's MLP generates its embedding independently, resulting in embeddings for:
- Frame positions (size 8 → embedding shape [8, 512]).
- Height positions (size 16 → embedding shape [16, 512]).
- Width positions (size 32 → embedding shape [32, 512]).
- Combining Axial Embeddings:
Combine the embeddings across axes using addition:
Each embedding is broadcast along the other axes and added together to form the final positional embedding tensor (shape [8, 16, 32, 512]).
EX) 2D inputs with 32 x 32 shape would be like:
# input tokens
[T1, T2, T3, ..., T32]
[T33, T34, T35, ..., T64]
...
[T993, T994, T995, ..., T1024]# embedding for each token
Token Embedding (T1) = Row_Emb[0] + Col_Emb[0]
Token Embedding (T2) = Row_Emb[0] + Col_Emb[1]
...- Integration with Input:
The combined positional embedding is added to the input tensor to inject positional information.

chords & code // harmony with structure