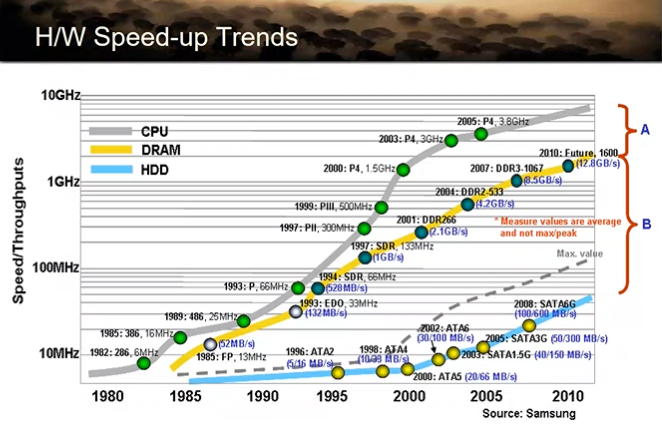
Memory Hierarchy
컴퓨터시스템 안에 데이터를 저장할 수 있는 공간의 계층 구조!
가장 빠른 저장장치: 레지스터(cpu안에 있기 때문이다)
계층 구조를 알아보자 (올라갈수록 빠름, 용량은 줄어듦, bit당 가격 올라감, 자주 접근함)
- 레지스터
- 캐시
- 메인메모리 → in board memory (보드 안에 박혀있음)
- 하드디스크, SSD → on-line storage(컴퓨터를 켜면 항상 따라 켜진다) / out board storage (메인보드 밖에 있는 스토리지)
- CD ROM / TAPE (백업 장치) → 필요할 때 붙이는 것으로 ‘offline storage’라고 한다.
참조 지역성(Locality of reference): cpu가 일을 할때 모든 데이터를 균일하게 접근하지 않고, 모든 명령어를 균일하게 접근하지 않고, 특정 명령어, 데이터가 빈번하게 접근되더라
ex) loop 안에 있는 명령어들은 계속 접근함.
loop 밖에 있는 명령어들은 한번 접근하고 끝남
⭐ 아주아주 중요 자주 접근되는 애들은 빠른 메모리에 올리자! → 참조지역성
Cache
일단 캐시가 왜 필요할까?
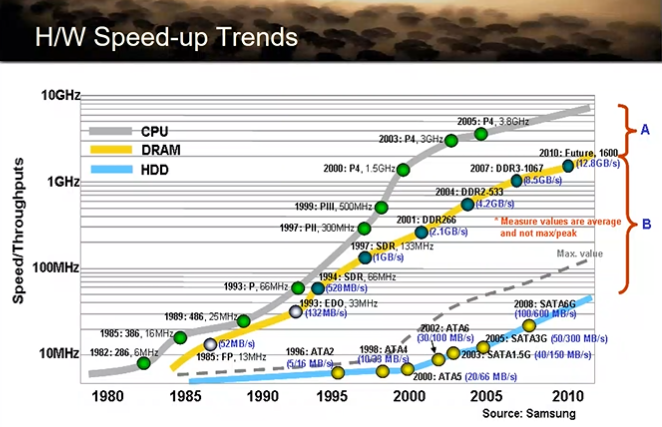
그래프를 보면 A(cpu와 DRAM의 속도차)보다 B(DRAM과 HDD의 속도차)가 더 커보인다.
사실은 그렇지 않다. 왜냐면 저 그래프 log scale임
실은 A가 B보다 훨씬 크다
cpu 입장에서 DRAM은 매우 느려터졌다..!!
병목은 HDD에 있는거 아님? → i/o를 발생시키지 않는 프로그램이 있다고 치면, cpu DRAM만 일을하기 때문에 DRAM이 병목임
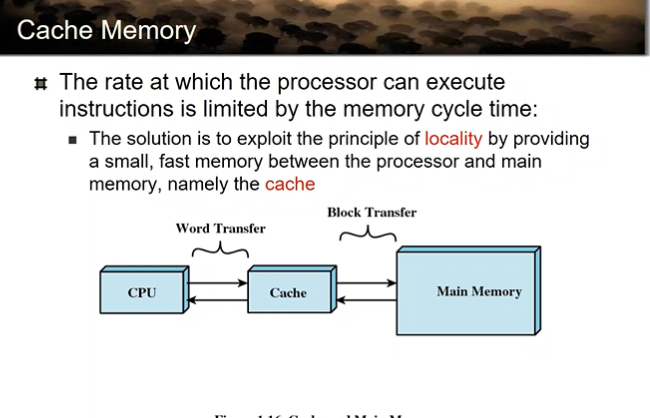
cpu와 메모리 사이에 빠른 SRAM을 두자!
메인 메모리 데이터 중에서 자주 접근되는 데이터를 캐시에 가져다 두자.
그럼 캐시에 접근하는 것이기 때문에 접근속도 빨라진다.
CPU는 Cache에서 Word 단위로 데이터를 읽어온다!
Cache는 Main memory에서 Block 단위로 데이터를 읽어온다!
여러개의 워드로 구성된 하나의 블록
Cache Memory
RA - read address
메모리에 있는 데이터 중에서 그 주소 영역에 있는 데이터가 캐시에 올라와 있는지를 먼저 확인한다.
있으면 그냥 거기서 읽어와서 CPU로 가져가지
만약 없으면? → 메모리로 접근 → 메모리에 있는 데이터를 한 블록 읽어옴 → 그 중에 필요한 데이터만 word 단위로 읽어서 cpu로 가져간다.
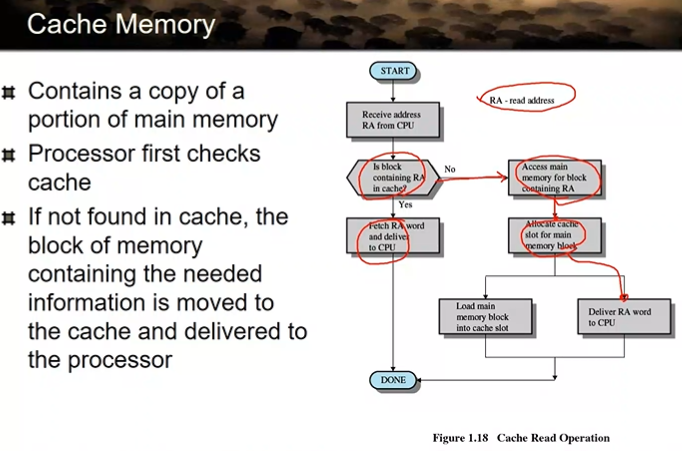
참조 지역성: 자주 접근되는 데이터, instruction이 존재 → 이런 애들을 캐시에다 올려놓으면 효과 굉장히 좋음
정리하자면, cache가 효과가 좋으려면 인기있는 놈이 올라와야함. 인기있는 애들은 항상 존재. 그런 애들을 cache에 올리면 효과가 굉장히 좋다.
SRAM == cache
Cache Design
자주 접근되는 데이터나 명령어의 크기가 생각보다 크지 않음을 알게됨
즉, 캐시의 크기가 그렇게 크지 않더라도 효과가 좋다는 뜻!
적은 사이즈만 써도 캐시 효과 좋다.
캐시가 불필요하게 커지게 되면 자주 접근되는 데이터를 올리고도 공간이 남는다.
그러면 자주 접근되지 않는 애들도 올라가게 된다. → 비용 대비 효과가 떨어진다.
따라서 캐시의 사이즈는 딱히 크지 않다.
커봐야 16MB 정도임(이것만 있어도 효과 충분)

왜 메모리에서 캐시로 block 단위로 읽어오는 걸까
참조 지역성과 관련이 있다.
cpu가 어떤 데이터에 접근했다면 그 주변에 있는 데이터에 접근할 가능성이 높아진다. → 그래서 블록 단위로 가져오는거임
block의 크기는 실험을 통해 64byte 이정도로 정한다고 합니다.
왜냐면 블록이 너무 커져도 필요없는 데이터가 올라와서 문제, 너무 작아도 문제이기 때문에
mapping function: 그 블록이 캐시에 어디에 위치하고 있는지를 결정하는 function
replacement: cache로 새 블록을 가져오려고 했는데 캐시가 꽉 찼을 때 안쓰는 블록 내리고 새 블록 가져오는 것 → 이것도 알고리즘에 따라 해야함
cpu가 사용 안할 것 같은 블록을 내쫓는게 좋다.
LRU(Least-Recently-Used) algorithm: 최근에 사용되지 않은 애를 내쫓겠다! (메모리에서도 사용되는 알고리즘)
→ 기본적인 가정: 최근에 사용된 블록은 다시 사용될 가능성이 높다
store하려는 데이터가 있는데, 그 써야하는 곳이 cache에 올라와있으면? → 캐시에다가 써버림 → inconsistency 문제가 발생할 가능성이 있다. (메모리에 새로운 값이 업데이트 되지 않아서 메모리와 캐시 값이 다름)
- inconsistency 어케 해결? :
- 정책 1: cache에 업데이트가 일어날 때마다 메모리에도 같이 써주자 (아주 보수적인 방법. 근데 캐시 효과가 없어지는 방법..)
- 정책 2: 1은 너무 비효율적. 일단은 cache에다가만 적고, 그 블록이 (LRU에 의해) 쫓겨날 때 메모리에 적어주자. (부작용: 메모리와의 inconsistency, cache coherence problem== 코어1에 올라와 있는 데이터봐 코어2에 올라와 있는 데이터가 다름)
Disk Cache

DRAM의 일부분은 Disk Cache로 사용
메모리와 하드디스크의 속도차이도 많이 난다. → 따라서 하드디스크에 접근하는 횟수를 최소화해야함
Computer-system Operation
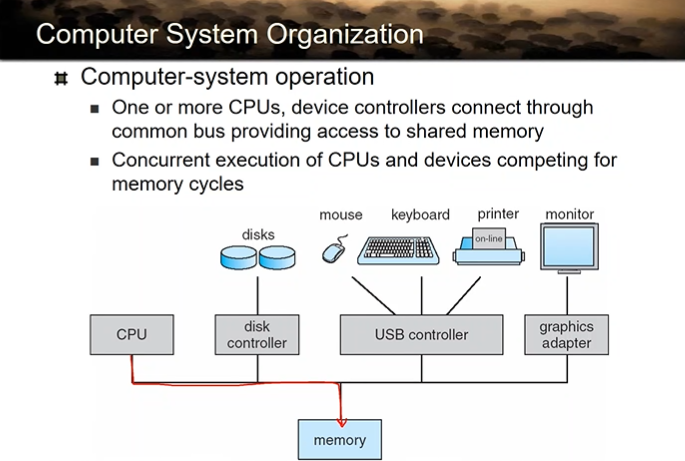
cpu와 주변장치는 완전 별도의 장치이다.
cpu가 바쁠때 주변장치도 바쁠 수 있다.
별도의 장치들이기 때문에 메모리 접근도 별도로 일어남
I/O 디바이스마다 컨트롤러가 반드시 존재한다! 얘네가 다 USB에 연결이 되기 때문에 USB 컨트롤러가 제어가 제어한다.
Computer-System Operation
각각의 IO 장치는 버퍼를 가지고 있다. 정확히 말하면 컨트롤러 안에 있음
각각의 디바이스 컨트롤러는 그 안에 로컬 버퍼를 가지고 있다.
하드디스크 안에 컨트롤러라는 칩이 박혀있는데, 그 안에 버퍼가 있다.
I/O → 메모리와 디바이스 컨트롤러 버퍼 사이의 입출력을 의미한다.
output: 메모리에 있는 데이터가 컨트롤러의 버퍼로 나가는 것을 아웃풋이라 한다.
input: 컨트롤러의 버퍼에 있는 데이터를 메모리로 가지고 오는 것을 인풋이라 한다.
하드디스크 입장에서 보면 하드디스크 버퍼로 데이터가 내려오고 그 버퍼에 있는걸 컨트롤러가 마그네틱 디스크에다가 써주게 되는 것이다. (SSD도 마찬가지임)
🍋 하드 디스크 컨트롤러는 절대로 메인 메모리에 데이터를 쓰지 않는다! 그 대신, 마그네틱 디스크에서 읽어온 데이터를 자신의 컨트롤러에 있는 버퍼에 올려놓고, I/O가 끝났다는 인터럽트를 보낸다. 그리고 그 데이터를 실제로 메모리로 가지고 오는 건 인터럽트 핸들러가 해준다.cpu가 핸들러 코드를 수행하면서 메모리로 가져온다고 한다.
왜 이렇게 할까 (걍 하드디스크가 메인메모리에 직접 쓰면 안됨? 왜 cpu가 인터럽트를 받고 읽어올까)
→ cpu 입장에서 하드디스크는 못 믿을 놈. 하드디스크가 메인메모리 구조를 알지 못하기 때문이다. (=메모리의 어느 위치에 써줘야 하는지 모름)
주변 장치는 메모리에 대한 접근 권한을 가지지 못한다! → cpu가 안전하게 i/o에 계속 관여 (하드디스크: cpu야 내 방에 데이터 가져다 놨으니까 가져가셈)

Programmed I/O → io의 모든 과정을 cpu가 관여해서 하기 때문에 이렇게 부른다.
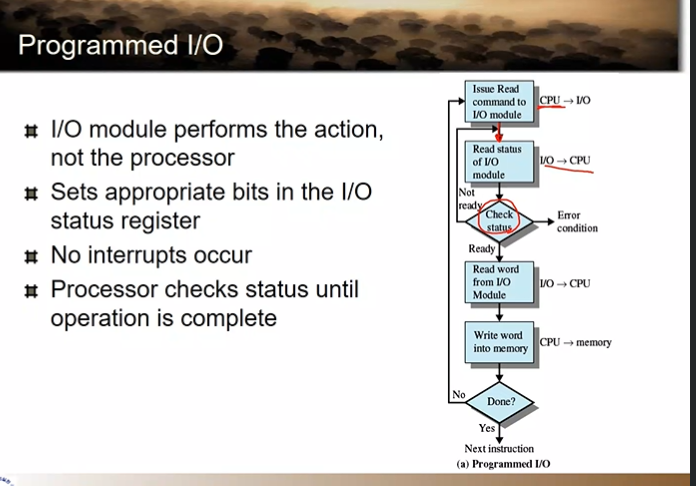
cpu: 바쁘니? i/o디바이스: 바빠요
cpu: 바쁘니? i/o 디바이스: 바빠요
cpu: 바쁘니? i/o: 안바빠요 cpu: 자 일하자
cpu가 한 워드를 읽어가고 (cpu는 다 워드 단위로 접근)
그 읽어간 거를 메모리에 쓰게 되는 것이다.
바쁘니, 안바쁘니 루프 → cpu를 쓰면서 무의미한 일
디바이스가 안바쁘면 cpu한테 인터럽트로 알려주면 되겠다!
→ interrupt driven i/o
Interrup-Driven I/O
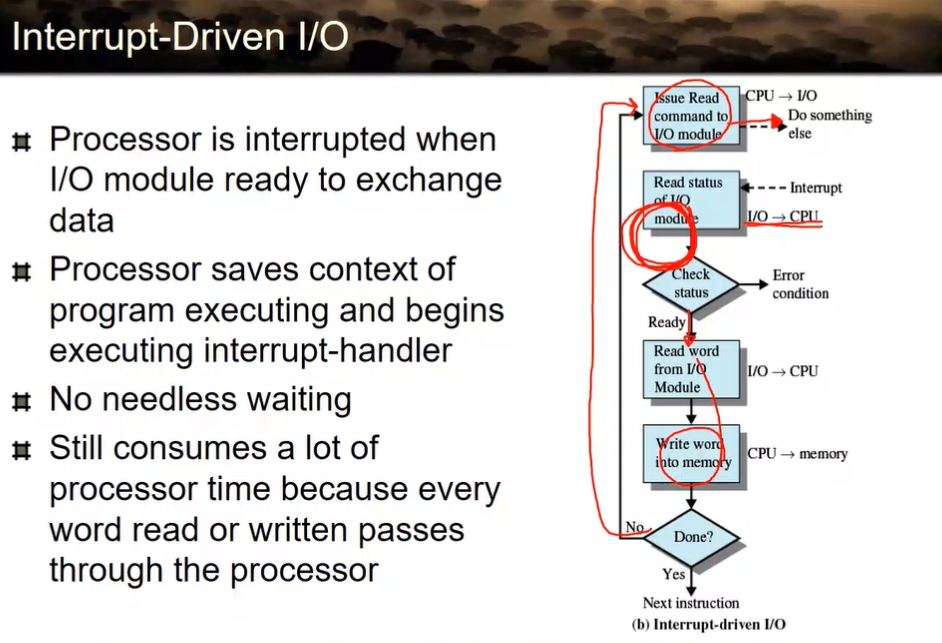
이러면 programmed보다는 효율적이지만
사실은 이것도 효율적이지 않다.
왜냐면 아까 말했듯이 모든 메모리 접근은 cpu가 데이터 가져와서 접근하기 때문에, 한번에 워드 단위로 읽어옴
→ 디바이스가 직접 메모리에 쓸 수 있게 해주면? 모든 문제 해결
근데 디바이스는 믿을 수 없어… → 그럼 신뢰할 수 있는 존재를 만들자!
Direct Memory Access (DMA) == 직접 메모리 접근
→ cpu 말고 다른 장치가 직접 메모리에 접근할 수 있게 함 (근데 그 다른 장치는 아이오 장치는 아님)
- DMA controller: 원래 cpu가 해오던 행위는 워드 단위로 데이터 읽어서 쓰는 행위를 대신해줌. 그리고 그 일이 다 끝나면 cpu에게 다 끝났다고 인터럽트로 알려줌
cpu가 DMA controller한테 “어느 위치에서 4 KB 읽어줘”
그럼 DMA가 읽어서 메모리에 올릴 동안 cpu는 다른 유의미한 일을 할 수 있다.
A Dual-Core Design
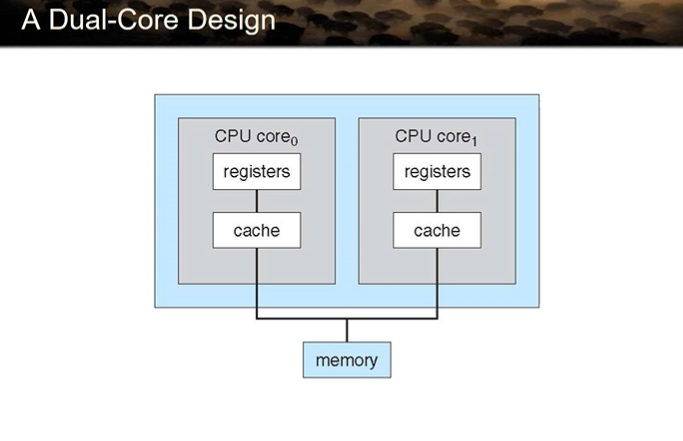
코어 == cpu
코어들을 한 덩어리로 묶어서 cpu라고 부른다.
하나의 코어 안에는 cpu가 갖춰야할 모든 것이 들어가 있음 → 캐시 다 따로 갖고 있음
(L1 cache)
Computer Startup

- bootstrap program: 프로그램을 부팅 시키는 프로그램
-
ROM(read only memory)에 들어가 있음
-
부트스트램 프로그램이 하는 일: 운영체제와 상관없이 모든 하드웨어를 초기화 시켜 줌.
-
하드 디스크엔 뭐가 있고, 메모리엔 뭐가 있고 체크하면서 화면에 뿌려주는 일? → 이해 X
-
마지막으로 OS를 메모리로 load
-
OS가 메인메모리로 올라와서 OS의 첫번째 명령어 pc가 세팅되면 그때부터 OS가 구동된다.
아이오: 디바이스 컨트롤러에 있는 버퍼와 메모리 사이에 데이터가 왔다갔다 하는것을 말함
-
