1. 개요
전자상거래에서 할인은 소비자의 구매 결정을 유도하는 핵심 전략 중 하나다. 이번 분석에서는 Olist 데이터를 기반으로 상품 카테고리별 할인율과 주문 증가율 간의 상관관계를 분석하고, 최소한의 할인으로도 성과를 낼 수 있는 전략적 인사이트를 도출하고자 했다.
또한, 할인율 대비 주문 증가율이 유독 높게 나타나는 ‘이상치 상품’의 물리적 특성(크기, 무게 등)을 분석하여,할인에 민감하게 반응하는 상품 유형을 식별하고 비효율적인 할인 비용을 줄일 수 있는 가능성도 탐색했다.
그러나 분석을 진행하며, 할인율을 정의하고 활용하는 방식에서 구조적인 문제와 나의 실수를 발견 했다.
나는 '할인율'을 상품별 판매가 중 최고가와 최저가의 차이로 정의 했지만, 이것은 실제 할인 정책이 아니라 판매된 가격들에서의 단순 변동폭을 의미할 뿐이였다.
Olist 데이터는 정가, 프로모션 여부, 판매되지 않은 상품의 가격 정보가 포함되어 있지 않기 때문에, 할인 전략을 실질적으로 분석하기엔 중요한 맥락이 빠져 있다.
그럼에도 불구하고 이번 분석은 불완전한 데이터 속에서 분석가로서 어떤 질문을 던졌고, 어떤 한계에 부딪혔지를 기록한 과정이다. 데이터가 혀용하는 범위 안에서 어떤 인사이트를 도출하려고 했고, 결과적으로 그 분석이 어디까지 의미있고 어디서부터 왜곡될 수 있는지를 알게 됐다.
2. 데이터 준비 및 전처리
데이터셋
분석을 위해 다음과 같은 데이터셋을 활용했다:
[기존 테이블]
order_items.csv: 주문 내역 데이터(판매 가격 제이터 포함 됨)products.csv: 제품 정보 데이터product_category_name_translation.csv: 제품 카테고리 번역 데이터order_reviews.csv: 고객 리뷰 데이터orders.csv: 주문 및 배송 데이터
[분석을 위해 신규 생성 테이블]
detailed_grouped_products.csv: 상품 크기 및 무게 정보
주요 변수 정의
-
할인율 (
discount_rate): 제품이 판매된 최고 가격과 최저 가격을 비교하여 계산 -
주문 증가율 (
order_increase_rate): 정가(최대 가격)로 판매된 주문 수와 정가 외의 가격으로 판매된 주문 수를 비교하여 증가율을 계산
3. 분석 과정 및 결과
3.1 할인율 적용 된 상품 선별
- 할인율이 0보다 큰 상품만을 필터링하여 분석에 사용
- 상품의 할인율이 0.1%~84%로 분포 되어 있어서, 데이터의 극단값을 제거하고 중앙 95%(2.5% ~ 97.5% 분위수)의 데이터만 활용하는 절사 방법 적용.
3.2 주문 증가량 및 증가율 계산
- 상품의 정가(최대 가격)과 할인 된가격(최대 가격 외 가격들) 기준의 주문량 계산했고, 이후 두 주문량의 차이를 기반으로 order_increase 및 order_increase_rate 변수를 생성.
- 두 주문량 데이터를 활용한 '주문 증가량 및 증가율' 계산.
- 주문 증가율도 상품 할인율과 같이 절사 방법을 적용하여 중앙 95% 데이터만 사용.
3.3 카테고리별 할인율과 주문 증가율 간의 상관관계 분석
- 할인율과 주문 증가율 간의 Pearson 상관계수와 p-value 계산.
- 아래 기준으로 통계적으로 유의미한 관계가 있는 Top 10 카테고리를 선정.
Top 10 카테고리 선정 기준
- Pearson 상관계수가 높고, p-value < 0.05인 카테고리
Top 10 카테고리별 상관계수와 p-value
| 카테고리 | 상관계수 | p-value |
|---|---|---|
| computers | 0.863 | 0.000298 |
| fixed_telephony | 0.756 | 0.030128 |
| books_technical | 0.715 | 0.030396 |
| signaling_and_security | 0.712 | 0.013894 |
| industry_commerce_and_business | 0.548 | 0.008301 |
| small_appliances | 0.518 | 0.000007 |
| luggage_accessories | 0.464 | 0.000099 |
| costruction_tools_garden | 0.433 | 0.038825 |
| consoles_games | 0.418 | 0.000255 |
| furniture_living_room | 0.418 | 0.006523 |
3.4 최소한의 할인율로도 주문량이 증가하는 상품 분석
- Top 10 카테고리에 해당하는 데이터만 필터링.
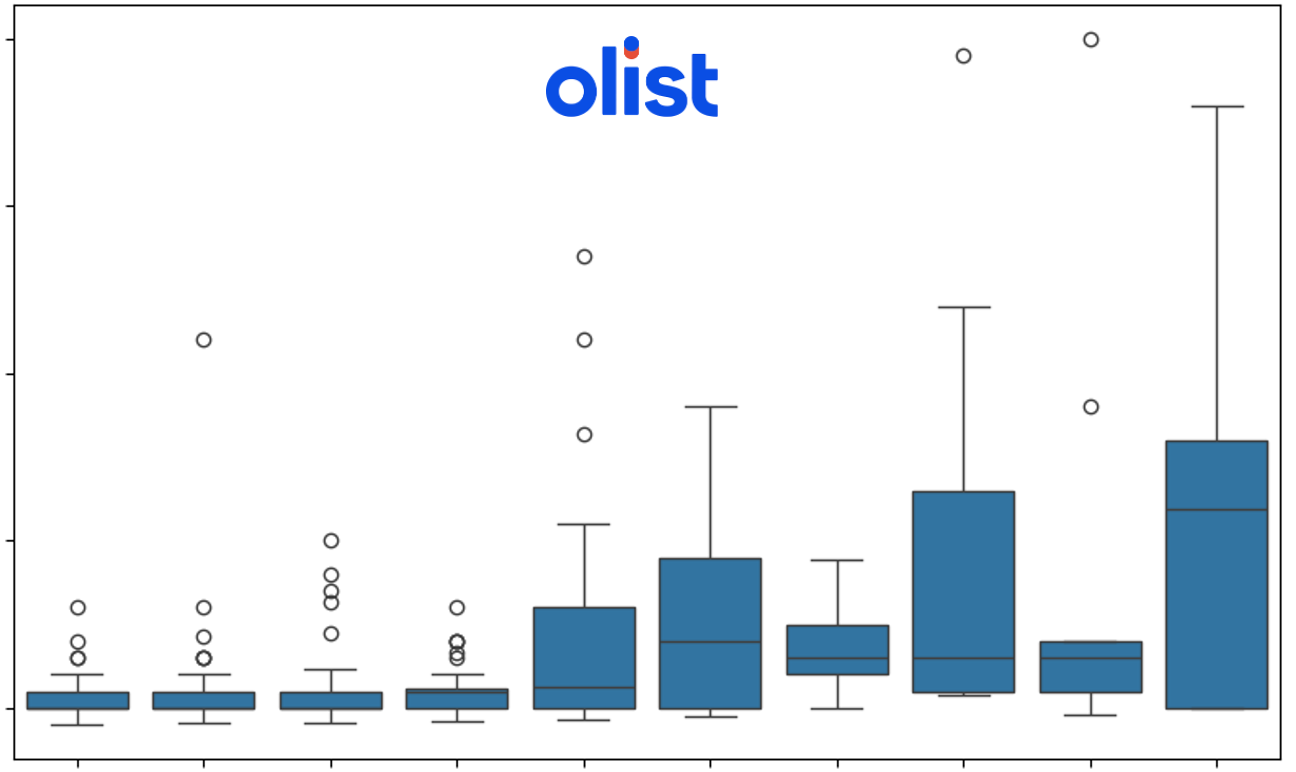
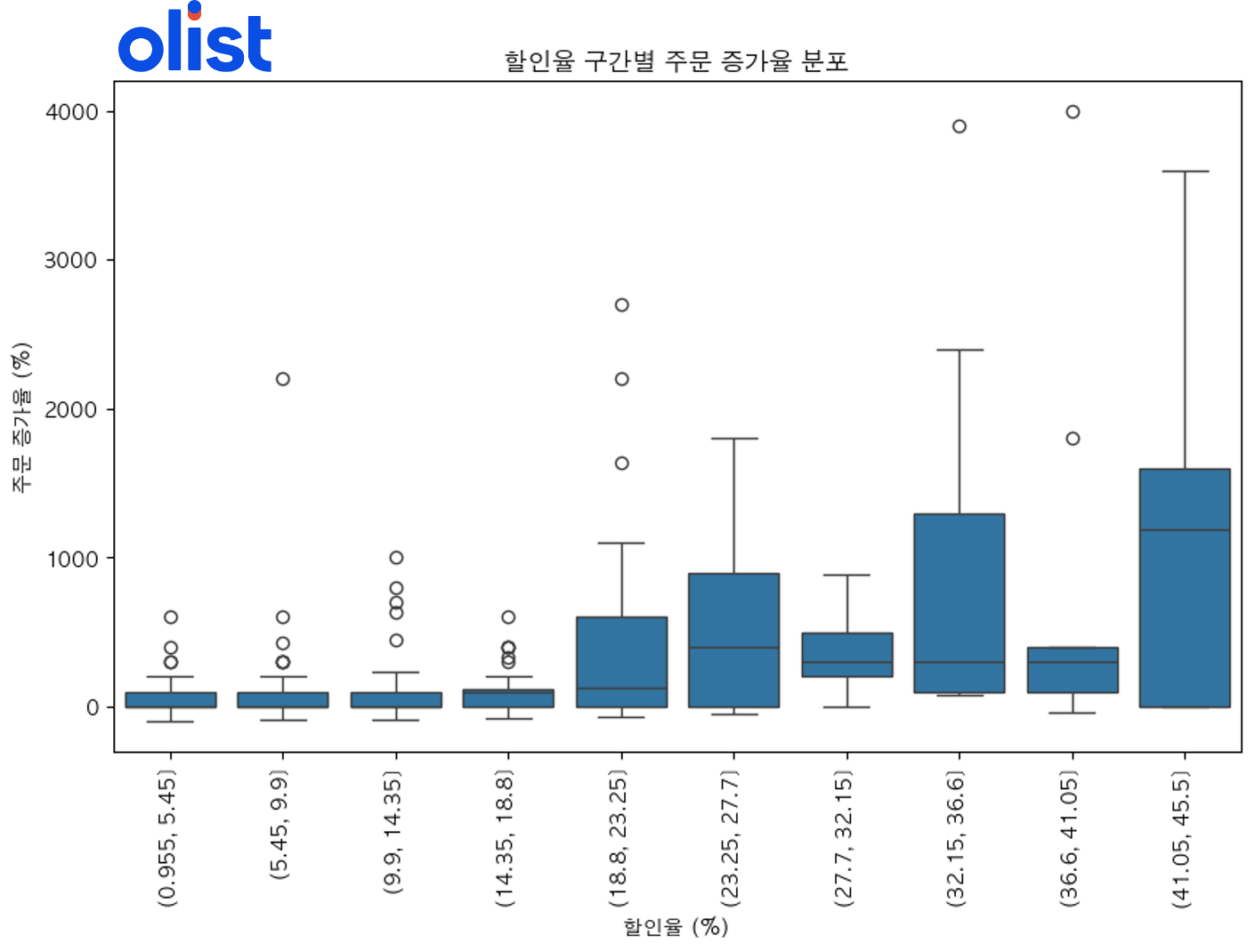
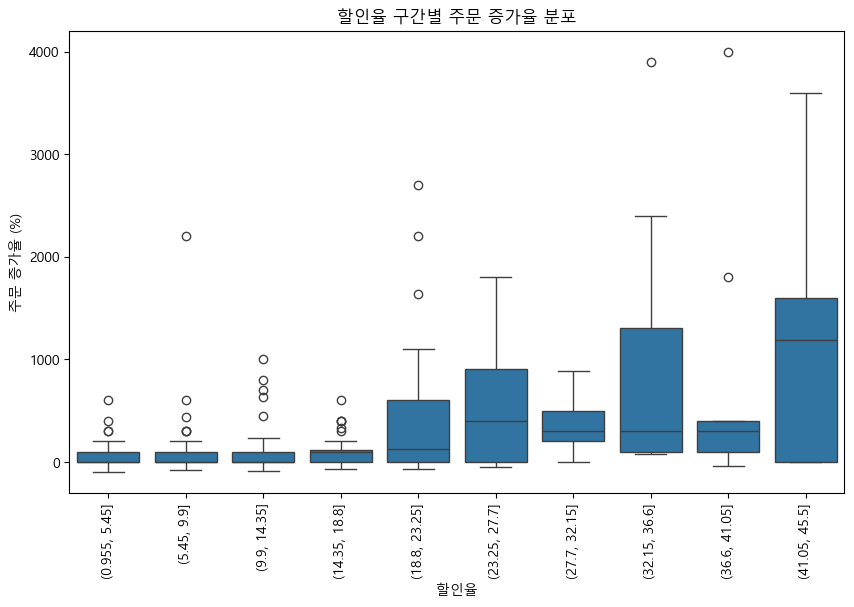
- 박스플롯: 할인율 구간별 주문 증가율의 분포를 보여줌.
- 바플롯: 할인율 구간별 평균 주문 증가율의 분포를 보여줌.
- 박스플롯의 상단 이상치 상품: 최소한의 할인율로도 주문량 증가 효과가 있는 상품으로 해석할 수 있음.
할인율 구간의 개수를 구하는 공식
- 'Sturges'공식을 통해 'bin=10'로 정함.
- 'Sturges'공식 선택 이유: 데이터의 크기가(326개의 행) 작고, 계산이 간단하고 직관적이여서(k=1+log2(n))
주요 분석 결과
- 할인율이 18% 이상일 때 주문 증가율이 급격히 상승
- 카테고리별로 할인율과 주문 증가율 간의 관계가 다름
- 특정 할인율 구간에서 주문 증가 효과가 있는 상품이 존재(상단 이상치=Q3 + 1.5 * IQR)
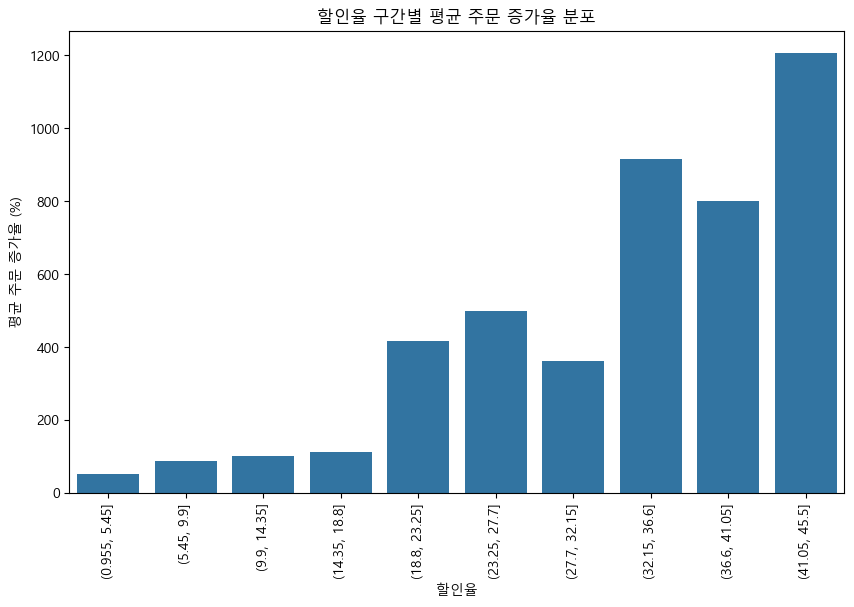
[할인율 구간별 평균 주문 증가율 및 상품 수]
| 할인율 구간 (discount_rate_bin) | 평균 주문 증가율 (avg_order_increase_rate) | 상품 수 (count) |
|---|---|---|
| (0.955, 5.45] | 50.57 | 54 |
| (5.45, 9.9] | 85.68 | 69 |
| (9.9, 14.35] | 100.70 | 58 |
| (14.35, 18.8] | 110.87 | 36 |
| (18.8, 23.25] | 414.35 | 36 |
| (23.25, 27.7] | 498.85 | 29 |
| (27.7, 32.15] | 361.11 | 15 |
| (32.15, 36.6] | 915.91 | 11 |
| (36.6, 41.05] | 801.11 | 9 |
| (41.05, 45.5] | 1207.05 | 9 |
4. 할인율 구간별 이상치(Q3 + 1.5 * IQR) 상품들의 특정 분석
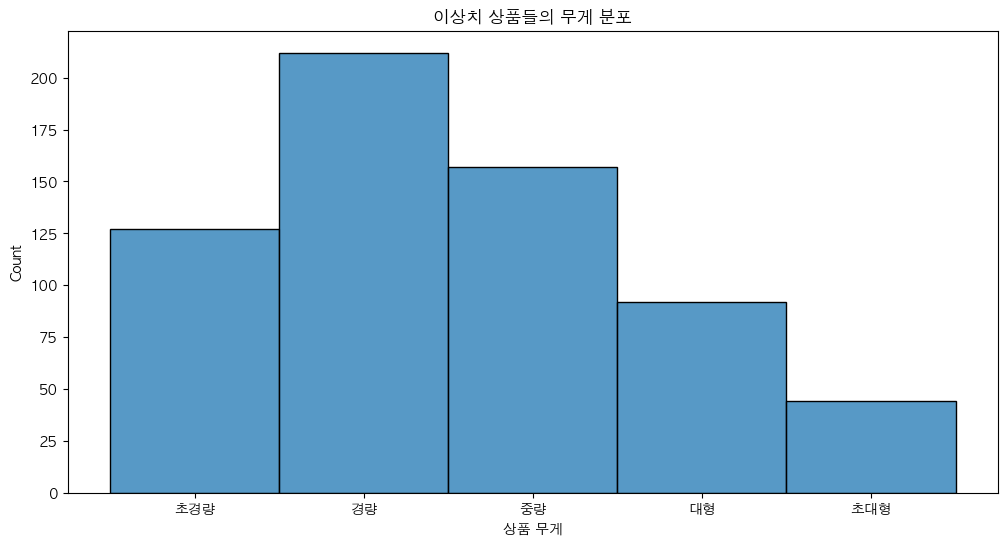
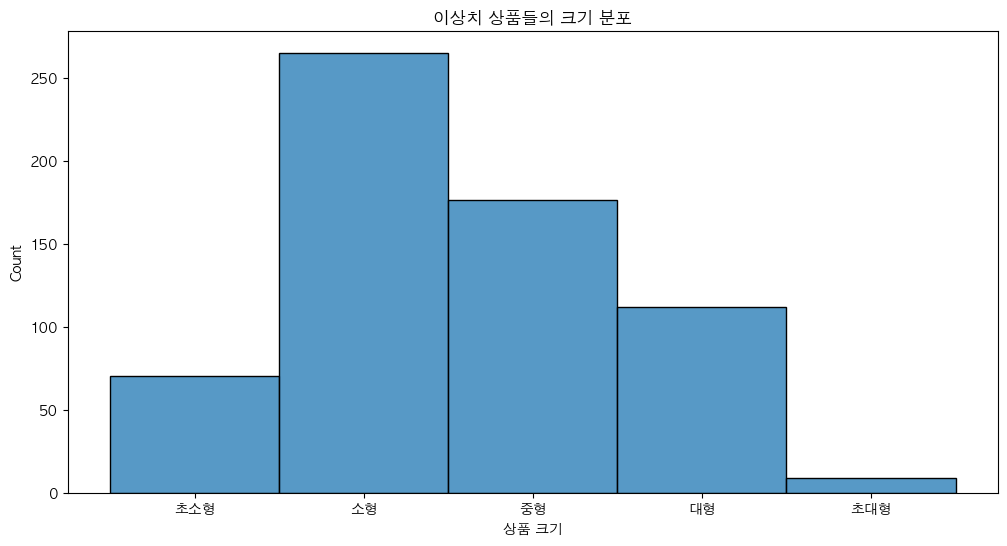
할인율 구간에서 다른 상품들과는 다르게 주문 증가율이 높은 제품은 어떤 물리적 특성을 가지고 있는지 분석 했다. 이 분석은 '최소한의 할인으로도 높은 반응을 얻는 상품의 공통된 특성'을 파악해보고자 실시 했다.
- 이상치 상품(할인율 대비 주문 증가율이 매우 높은 상품)의 물리적 특성을 가지고 있는지 분석
상품의 무게, 크기, 길이, 너비, 높이를 기준으로 새로운 그룹 생성
- 무게별 그룹명: 초경량, 경량, 중량, 대형, 초대형
- 크기별 그룹명: 초소형, 소형, 중형, 대형, 초대형
- 길이별 그룹명: compact, medium, large
- 너비별 그룹명: slim, regular, wide
- 높이별 그룹명: flat, tall, extra tall
- 상단의 기준으로 기준으로 그룹화한 데이터 테이블'detailed_grouped_products.csv'생성
주요 분석 결과
이상치 상품의 주요 특성
- 경량 & 소형 제품: 137개 (경량 & 소형 제품은 작은 할인율에도 주문 증가율이 급격히 상승할 가능성이 큼)
- 경량 & 중형 제품: 47개
- 대형 & 대형 제품: 55개 (대형 & 대형 제품도 일부는 할인에 높은 반응을 보임)
6. 결론
분석을 마치며 강하게 남는 질문이 하나 있다.
" 이 분석은 실제로 어떤 비즈니스 의사결정에 기여할 수 있는가?"
분석에서 사용한 '할인율'은 가격 인하의 폭처럼 보이지만, 실제로는 판매된 가격 내에서의 단순 변동에 불과하다. 할인되지 않은 상태에서 판매되지 못한 가격은 데이터에 존재하지 않으며, 정가 또는 시스템상 할인된 가격의 데이터도 없다.
결국 이 분석은 정책적 할인 효과를 반영한다고 보기 어렵고, 오히려 가격 변동이 있었던 상품만으로 만든 통계적 상관을 보여준 셈이다.
이런 구조적 한계는 분석에 생존 편향을 유발한다. '할인되어 팔린 상품만을 보며, 할인하면 잘 팔린다고 결론짓는 오류'가 발생한다는 것이다. 또한 여러 단계에 걸쳐 가격이 변경된 상품의 전략적 흐름은 전혀 고려되지 않았다. 예를 들어, A상품이 100→95→90→85→80으로 가격을 변경하며 판매되었다면, 우리는 이 상품의 ‘실제 할인 전략’이 어떤 방식으로 작동했는지를 충분히 파악해야 한다. 그러나 이 분석에서는 단순히 100과 80만 비교한 셈이다. 이처럼 복잡한 가격 전략이 단일 수치(최고가 - 최저가)로 요약 되면서, 분석의 정확도는 더 낮아진 것이다.
한 가지 더 중요한 의문이 생겼다.
"하나의 상품에 여러 판매자가 서로 다른 가격으로 판매하고 있다면, 그 중 저렴한 가격은 구매자 입장에서 '할인'처럼 인식되지 않을까?"
이 질문은 현실적인 의문이고, 소비자 관점에서 본다면 타당하다. 아래의 이미지처럼 브라질 1위 마켓플레이스인 메르카도리브레에는 Olist 스토어를 통해 하나의 상품이 여러 판매자에의해 서로 다른 가격으로 판매되며, 구매자는 그 중 가장 저렴한 가격을 '할인된 것'으로 받아들일 가능성이 높다.
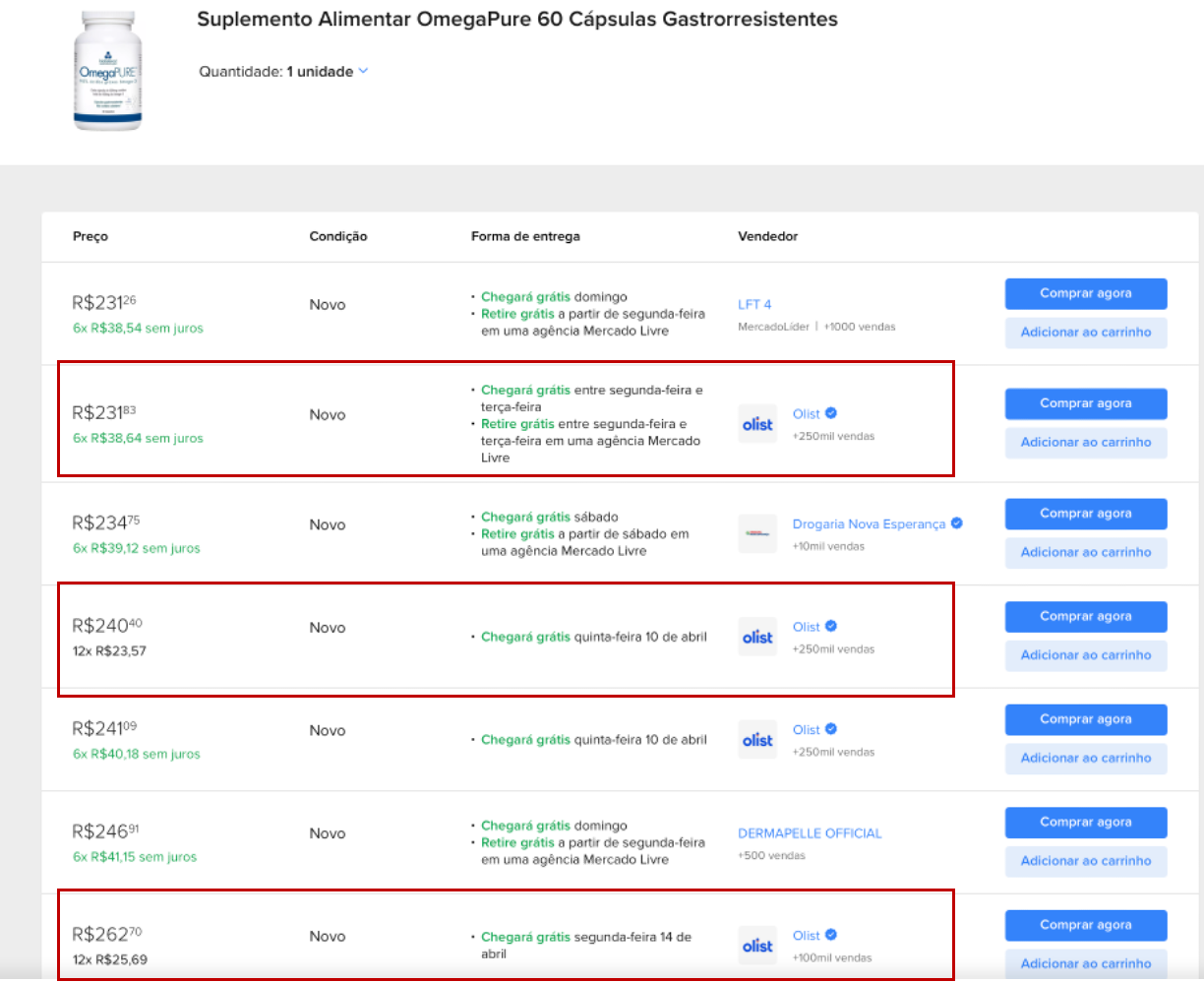 [이미지: 메르카도리브레 사이트 내 상품 판매자별 가격비교 화면]
[이미지: 메르카도리브레 사이트 내 상품 판매자별 가격비교 화면]
하지만 데이터 분석의 관점에서는 이러한 상황을 정책적 할인과 구분해야 한다는 것이다. 판매자 간 가격 차이를 단순히 '할인율'로 정의하면, 이는 판매 전략의 효과가 아닌 시장 내 가격 다양성을 분석한 것에 불과하다. 정책척 할인 효과를 분석하려면, 동일 판매자 기준의 가격 변화 흐름을 추적하거나, 정가, 프로모션 여부, 광고 노출, 조회수 등 추가 정보가 필요할 것 같다.
결론적으로 이 분석이 가진 한계는 "무엇을 분석 했는가"가 아니라 "그 분석이 무엇을 말해줄수 있는가"에 대한 성찰이 부족했다는 점이다. 이번 분석은 데이터 분석가로서 "이 데이터로 무엇을 할 수 있고, 무엇을 할 수 없는가"를 구분하는 감각을 키울 수 있었다. 실행 가능한 인사이트를 도출하려면, 올바른 질문과 적절한 데이터가 먼저 필요하다는 사실을 알게 됐다.
상품별 가격 변동성 확인을 위해 EDA를 실시한 블로그 글: EDA: 상품별 판매 가격 변동 탐색
