📖Chapter 03
📌회귀
▪ 클래스 중 하나로 분류하는 것이 아니라 임의의 어떤 숫자를 예측하는 문제.
▪ 정해진 클래스가 없고 임의의 수치를 출력함.
▪ 두 변수 사이의 상관관계를 분석하는 방법.
📌k-최근접 이웃 회귀
▪ 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측.
📌결정계수(R2)
▪ 대표적인 회귀 문제의 성능 측정 도구.
▪ 1에 가까울수록 좋고, 0에 가까울수록 성능이 나쁜 모델.
R2 = 1 -
📌과대적합 vs 과소적합
과대적합
▪ 훈련 세트에만 잘 맞는 모델.
▪ 테스트 세트와 새로운 샘플에 대한 예측이 잘 동작하지 않음.
▪ 훈련 세트와 테스트 세트의 점수를 비교했을 때 훈련 세트가 너무 높은 경우.
->과대적합일 경우 모델을 덜 복잡하게 만들어야함.
(k-최근접 이웃의 경우 k값을 늘림.)
과소적합
▪ 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 너무 낮은 경우.
▪ 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 경우.
▪ 훈련 세트와 테스트 세트의 크기가 매우 작은 경우 일어남.
->과소적합일 경우 모델을 더 복잡하게 만들어야함.
(k-최근접 이웃의 경우 k값을 줄임.)
📌선형 회귀
▪ 대표적인 회귀 알고리즘.
▪ 특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식을 찾음. (특성이 하나면 직선 방정식)
▪ 선형 회귀가 찾은 특성과 타깃 사이의 관계는 선형 방정식의 계수 또는 가중치에 저장됨.(가중치는 종종 방정식의 기울기와 절편을 모두 의미하는 경우가 많음.)
📌다항 회귀
▪ 다항식을 사용한 선형 회귀
▪ 다항식을 사용하여 특성과 타깃 사이의 관계를 나타냄.
▪ 함수는 비선형일 수 있지만 선형 회귀로 표현할 수 있음.
📌다중 회귀
▪ 여러 개의 특성을 사용한 선형 회귀
▪ 특성이 많으면 선형 모델은 강력한 성능을 발휘함.
▪ 특성 공학: 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업.
📌규제
▪ 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것.
▪ 모델이 훈련 세트에 과대적합되지 않도록 만드는 것.
▪ 선형 회귀 모델의 경우 특성에 곱해지는 계수(또는 기울기)의 크기를 작게 만드는 일.
선형 회귀 모델에 규제를 추가한 모델: 릿지, 라쏘
릿지
▪ 계수를 제곱한 값을 기준으로 규제 적용.
▪ 비교적 효과가 좋음.
라쏘
▪ 계수의 절댓값을 기준으로 규제 적용.
▪ 릿지와 달리 계수 값을 0으로 만들 수 있음.
💡기본미션: Ch 03-1. 2번 문제 출력 그래프 인증샷
✅확인문제
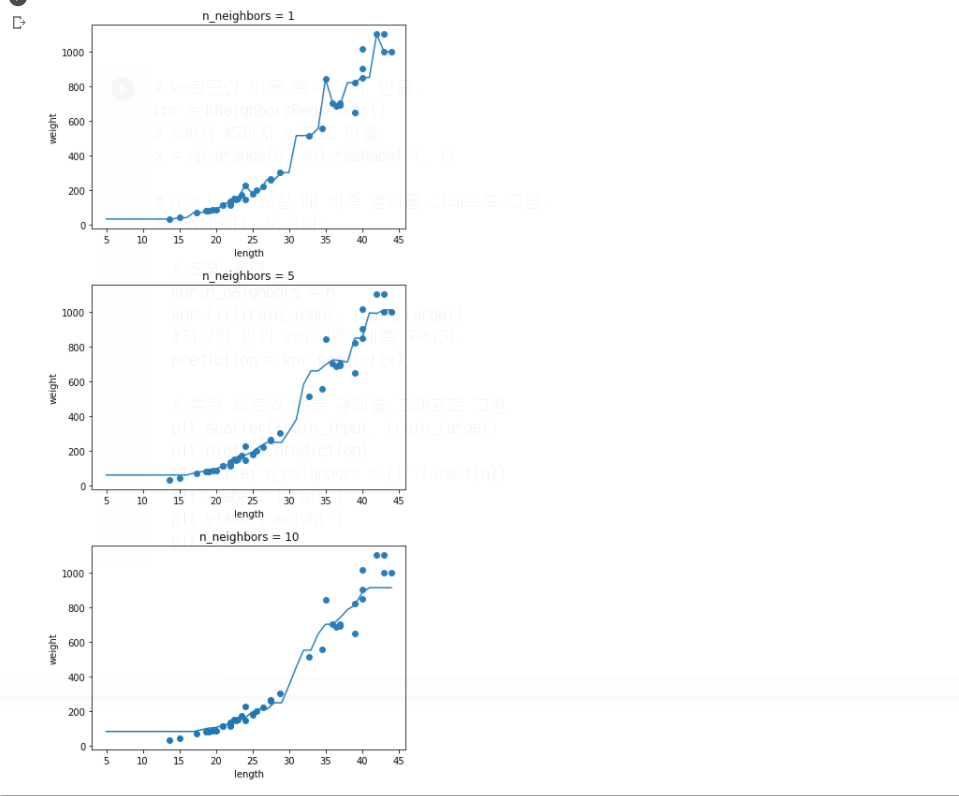
- 과대적합과 과소적합에 대한 이해를 돕기 위해 복잡한 모델과 단순한 모델을 만들겠습니다. 앞서 만든 k-최근접 이웃 회귀 모델의 k 값을 1, 5, 10으로 바꿔가며 훈련해 보세요. 그다음 농어의 길이를 5에서 45까지 바꿔가며 예측을 만들어 그래프로 나타내 보세요. n이 커짐에 따라 모델이 단순해지는 것을 볼 수 있나요?

💡선택미션: 모델 파라미터에 대해 설명하기
모델파라미터
▪ 머신러닝 모델이 특성에서 학습한 파라미터
ex) 선형 회귀가 찾은 가중치 값.
모델 기반 학습: 머신러닝 알고리즘의 훈련 과정이 최적의 모델 파라미터를 찾는 것.
사례 기반 학습: 모델 파라미터가 없고 훈련 세트를 저장하는 것이 훈련의 전부. ex) k-최근접 이웃
📒혼자 공부하는 머신러닝+딥러닝 책을 참고하여 작성하였습니다.
https://www.hanbit.co.kr/store/books/look.php?p_code=B2002963743
