
외래 키가 없는 RDB
데이터베이스의 이론적인 베이스 지식보다 실제 개발을 먼저 접하면서, DB의 물리적인 설계에 외래 키를 설정하지 않고 시작했다. 그래서 실제 개발에선 사용하지 않는 것이 당연하다는 감각으로 진행했고, 이후 DB에 대한 기초 지식을 공부하면서 왜 실제론 제약 조건을 사용하지 않는지 고민했던 경험이 있다.
이후 SSAFY를 진행하면서 프로젝트 DB 설계에 대한 피드백 시간이 있었다. 피드백 중 다른 팀에서 FK를 제거하라는 이야기를 듣고, 무슨 소린지 이해하지 못해 나에게 질문이 한 일이 생겼다. 질문에 대답하면서 예전에 했던 고민이 떠올라 따로 정리해두면 좋다고 생각해 작성했다.
FK, 외래 키란?
설명에 앞서 정확히 RDB 내에서 FK란 무엇일까?
무결성
우리는 생각보다 많은 양의 데이터를 생성하고, 이를 저장하다보면 자연스레 중복이 발생한다. 중복 데이터를 모두 저장하면, 참조하는 데이터에 따라 오류가 발생하고 정확하지 않은 데이터가 제공된다. 결과적으로 원하는 결과의 서비스를 만들지 못하고, 오류가 발생하게 된다.
이런 문제를 해결하기 위해 데이터를 모델링함에 있어, 무결성을 지키고자 설계하게 된다. 그리고 RDB에선 이를 PK(Primary Key)를 통해서 개체에 고유함을 부여하고 이에 대한 개체 무결성을 보장한다.
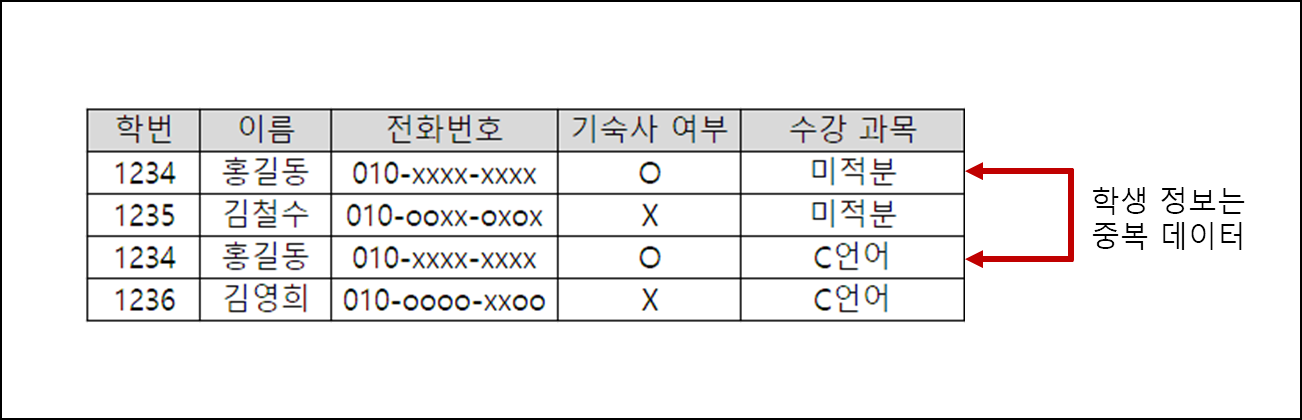
그림을 보면 수강 과목과 과목을 수강하는 학생에 대한 정보를 같이 저장하고 있다. 그 과정에서 홍길동이란 학생이 중복 입력되나, 학번이라는 고유한 값을 통해 미적분과 C언어를 수강하고 있는 홍길동이 동일한 학생임을 보장할 수 있다.
정합성
하지만 데이터의 종류에 데이터에서 공통으로 사용하는 부분이 중복되고, 이런 데이터는 전체가 관리되지 못하면 한 쪽만 수정이 이뤄져 각 데이터가 공통 데이터를 사용함에도 다른 값을 가지게 된다.
예를 들어, 이전과 동일한 그림에서 홍길동 학생이 기숙사에서 퇴실하게 되었다. 그래서 명부에서 제일 최근 데이터에서 기숙사 여부를 X 처리했는데, 전체 명부를 보면 데이터가 불일치하는 문제가 발생한다.
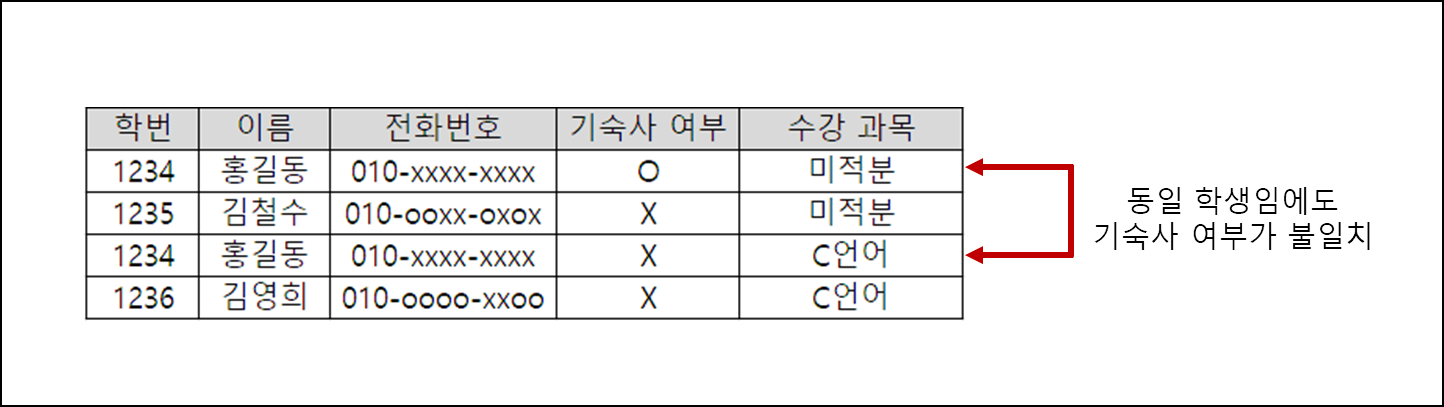
이렇게 동일한 데이터가 같은 값을 가져야 한다라는 개념이 정합성이다. 그림처럼 어떠한 이유로 데이터의 정합성이 맞지 않는 경우, 정합성이 훼손되었다고 한다. 그리고 위 사례처럼 데이터를 수정하면서, 중복 데이터 중 일부 데이터만 수정되면서 정합성이 훼손되는 경우를 갱신 이상이라고 한다.
그럼 정합성을 보장하기 위해 어떻게 해야 할까? 아래 그림처럼 테이블을 분리해보자.
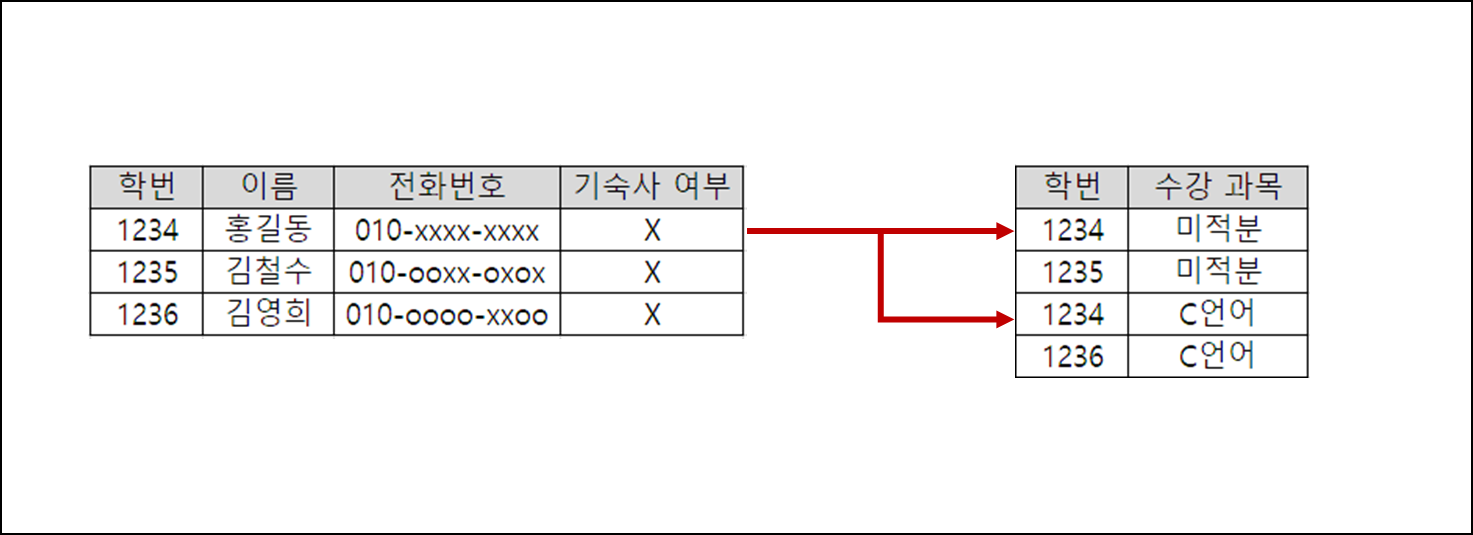
그림처럼 테이블을 분리하면 학번이라는 고유한 값을 통해 다른 과목임에도 동일한 학생을 가리킨다. 이렇게 되면 학생 데이터가 갱신되어도 과목에 따라 다른 값을 가져올 염려가 없어진다. 이런 과정을 정규화라고 한다.
Foregin Key
위 그림을 그대로 가지고 데이터베이스 설계에 사용해보자. 우린 데이터베이스에서 학생 테이블을 만들었고, 이에 대한 PK로 학번을 만들었다. 그리고 수강 과목 테이블을 만드는데, 학생 테이블의 정보를 그림처럼 가리키고 싶다.
이처럼 정규화 이후 화살표와 같이 특정 컬럼을 가져와 다른 테이블을 레코드를 가리킬 수 있는데 가져온 컬럼을 FK(Foregin Key), 외래 키라고 한다. DBMS 상에서 FK에 대한 제약을 사용할 수 있고, 이를 바탕으로 DB 상에서 각 데이터의 정합성, 무결성을 보장할 수 있다.
근데 안 써?
이야기를 들으면 데이터의 정합성을 지키기 위해 무조건적으로 FK를 사용해야 할 것 같다. 하지만 배경에서 말한 사례처럼 FK를 제거하고 개발하는 경우가 존재한다. 엄밀히 말하면 논리적으로 테이블 간의 관계를 설정해두고, DBMS 상에서 FK 제약조건만 제거한다.
FK가 불편한 사람들
성능 이슈
- FK도 하나의 제약조건으로 데이터를 삽입하는 과정에 있어서 DBMS는 항상 FK를 검사하는 추가적인 과정을 거친다
- 삭제, 수정하는 과정에도 외래 키 옵션에 따라 추가적인 과정이 소요된다
개발, 확장 과정에서의 처리
- 개발을 진행하면서, 무조건적으로 먼저 부모 테이블을 만들고 부모 레코드를 생성해야 한다. 다시 말해 테이블의 관계에 따라 각 Task 간의 순서가 정해지고, 이 순서에 얽매여 작업이 진행되어야 한다
- 개발 과정에서 테이블 구조가 수정되는 경우 외래키를 별도로 다 처리하면서 진행하면서 당초 작업보다 더 큰 시간과 계획이 필요해진다
- FK가 없는 기존 데이터에 대해서 테이블이 추가되어 확장되며, 기존 데이터와의 정합성이 불일치하는 문제가 발생할 수 있다
데드락 이슈
- FK에 따라 Lock이 전파되기 때문에 부모 자식 테이블을 접근하는 순서에 따라 데드락이 발생할 수 있다
- 데드락 가능성을 최대한 줄이기 위해 FK 제약 조건 설정하는 경우를 피하는 경우가 존재한다
꼭 삭제해야 할까?
FK가 불편한 점이 많다고는 하나 삭제함으로 얻는 이점이 있다면, 삭제해서 생기는 부작용도 있다. 뿐만 아니라 경우에 따라 삭제해야 하는 이유가 없어지기도 한다. 고로 우리는 넓게 생각하고 넣는다면 넣는 이유, 삭제한다면 삭제하는 이유에 대해서 고민해야 한다.
성능 이슈?
- 대부분 FK 제약 조건 검증이 문제가 될 정도로 지연되는 경우는 적다
- 성능이 아주 아주 중요한 시스템이 아니라면 약간의 성능 상승을 위해 데이터 정합성을 희생하면서까지 삭제할 이유가 없다
어플리케이션 내 처리
- FK 제약 조건을 삭제하면 제약 조건에 대한 검증을 어플리케이션 측면에서 검증하는 방향으로 수정이 이뤄진다
- 어플리케이션에서 처리한다고 해도 결국 부모 테이블의 데이터를 가져와 검증하는 로직이 필요하고, 이 과정에서 DBMS 내에서 처리되는 것보다 더 큰 지연이 있다는 의견도 있다
대용량 관리
- 시스템에 의한 제약 조건 처리에서 사람에 의한 검증 및 처리로 변경되고, 이에 휴먼 에러가 발생할 가능성이 생긴다
- 현재 내가 진행하는 작은 규모의 프로젝트라면 괜찮지만, 테이블의 갯수나 데이터의 갯수가 훨씬 많아지는 대규모 데이터 프로젝트에선 모든 데이터 관리가 힘들어진다
후기
예전부터 가진 의문에 대한 대답을 좀 더 구체화해보았다. 어떻게 보면 매 프로젝트의 설정에 맞춰 따라가면서 개발했는데, 조금 명확해지는 기분이 든다. 하지만 역시 완벽한 방법은 없다고 생각한다. 성능, 안정성 사이의 줄다리기는 설계를 진행하는 한 계속 사이에 매달려 있어야 하지 않을까
참고
Foreign Key 없이 구축하는 관계형 데이터베이스 시스템에 대한 생각
대용량 디비에서는 외래키를 안쓰나요?
Foreign Key
[트러블슈팅 - DB] 외래키(Foreign Key)와 데드락(DeadLock) 그리고 쿼리 지연 실행
