
에어플로우에 대한 정보를 제공하는 정확하고 전문적인 글들이 많고, 여기서는 나와 같은 초보분들을 위해 설치부터 아주 간단한 실습을 다룰 것이기 때문에 이론은 직관적으로만 설명해서 느낌만 가지고 넘어가도록 하겠다.
이론은 필요 없고 바로 실습을 원한다면, Airflow 실습하기 파트로 넘어가자. 😉
🥸 이 튜토리얼의 코드는 여기!
https://github.com/mitchell-pritchett/airflow-tutorial.git
Airflow란?
에어플로우는 한마디로 일련을 일들을 순차적으로 진행시켜주는 프로젝트 관리자 같은 애다. 에어플로우와 에어플로우의 구성 요소를 조금 의인화해서 설명을 하겠다.
우리가 어떤 보석💍 공장의 공장장이라고 해보자. 공장에서 보석 원재료를 긁어오고, 세척하고, 가공하고, 제품을 만들고, 포장해서 판매하기까지 이 일련의 과정들이 주기적으로, 순차적으로 잘돌아가야 한다. 공장장으로서 일이 주기적으로 자동으로 잘돌아가도록 스케줄을 짜고(워크플로우 스케줄링), 사람들이 잘 일하고 있는지 감시(모니터링) 할 수 있는 시스템이 필요하다. 이 시스템으로 우리는 에어플로우라는 애를 쓴다.
에어플로우에서 알아야 할 개념
- 워크플로우 : 워크플로우는 의존성으로 연결된 작업들의 집합이다. 예를 들어 보석 원재료가 잘 도착해야 닦을 수 있고, 잘 닦여야 가공할 수 있고, 가공이 되어야 제품으로 만들 수 있고...
- DAG(대그) : 보석 공정 파이프라인. 순환하지 않고 시작에서 끝으로 진행되는 워크플로우 구조다. (Directed Acyclic Graph - 방향이 있는 순환되지 않는 그래프).
- 보석 원재료를 긁어오고, 닦고, 가공하고, 제품을 만들고, 포장해서 판매하기까지 일련의 순환하지 않는 과정. 에어플로우의 핵심 구조.
- 한 보석 공장에도 여러 대그가 있을 수 있다. 다이아몬드 대그, 사파이어 대그, 진주 대그...
- Task(태스크) : 대그의 단위 작업 (원재료 긁어오기 태스크, 세척하기 태스크, ...)
에어플로우 구성 요소
에어플로우에는 몇 가지 주요 구성 요소가 있다.
- 에어플로우 사용자 (나) 👩💻 : 공장장
- 웹서버 🖥️ : 공장장이 사람들이 잘 일하는지 감시할 수 있도록 보기 좋게 여러 요소가 잘 정리된 화면. 화면을 통해 일을 시작하거나 멈추라고 명령을 내릴 수 있다.
- 스케줄러 💁⌚ : 워크플로우 시간 관리 담당 비서
- Metastore 📑 : 여러 대그 정보를 써놓은 파일철. 대그가 잘 진행되었는지, 중간에 어느 과정에서 망했는지, 성공했는지 등을 적어놓는다.
- Executor 👷 : 작업을 배치하는 작업 반장
- Worker 👩🔧 : 작업을 수행하는 일꾼
- Operator ⚙️ : 작업을 수행할 때 사용하는 기계. 공장장이 이런 기계들을 설계해서(파이썬 코드로) 공정 순서대로 엮어주면 한 대그가 완성된다.
✅ 오퍼레이터를 실행(세팅)하면 태스크
예를 들어, 원자재를 세척하는 세척 오퍼레이터가 있다고 해보자. 같은 종류의 세척 기계를 다이아몬드에 대해서도 쓸 수 있고, 사파이어에 대해서도 사용할 수 있다. 이 세척 기계로 다이아몬드를 세척하기로 하고, 다이아몬드 세척에 적합한 조건들을 세팅하고 세척한다면, 이것이 다이아몬드 세척 태스크 가 된다. 즉, 오퍼레이터에 특정 인풋과 조건을 넣어주면 특정 태스크(작업)가 되는 것이다.
간단한 에어플로우 구조 및 동작 방식
다시 한 번 말하지만, 에어플로우 이론에 대한 정확하고 구체적인 정보는 다른 좋은 문서들을 참고하시길 바란다
여기서는 다이아몬드 공정 파이프라인(대그)을 만든다고 해보자.
- 나(공장장)는 다이아몬드 공정에 필요한 기계(오퍼레이터)들을 만든다.
- 다이아몬드 긁어오기 기계
- 다이아몬드 세척하기 기계
- 다이아몬드 가공하기 기계
- 다아아몬드 반지 만들기 기계
- 다이아몬드 반지 출하하기 기계
- 기계들을 어떤 순서로 연결할지 설계해서 하나의 다이아몬드 공정 파이프라인를 만들어준다 (긁어오기 >> 세척 >> 가공 >> 반지 >> 출하). 어떤 주기로 이 대그를 돌릴지도 정해둔다.
- 공정 순서와 기계들이 준비되었으니 모니터(웹서버)를 보고 몇 번의 클릭클릭으로 일 시작을 지시하거나, 비서(스케줄러)에게 직접 말해서 언제 일을 시작하도록 하라고 지시한다.
- 이때 언제, 어떤 대그를 실행했는지 파일(메타스토어)에 적어둔다.
- 작업 반장(익제큐터)은 공장장이 설계한 대그를 보고, 할 일을 순서대로 리스트 업해서 일꾼(워커)들에게 순서대로 일을 시킨다.
- 작업 내역(각 작업의 성공 여부, 과정 기록, 작업 완료 등)을 파일(메타스토어)에 적는다.
- 파일을 참고해서 모니터로 보여줄 내용을 업데이트한다. 공장장은 이 업데이트된 모니터를 보고 대그가 성공했는지, 성공하지 못했다면 어디서 작업이 막혔는지를 확인한다.
- 반지 만들기 작업에서 오류가 생겼다면 반지 만들기 기계를 고쳐준다. 다시 대그를 시작하라고 지시한다.
✅ 보석 공장을 예시로 든 이유가 있는데, 에어플로우는 실시간으로, 초단위로 진행되어야 하는 공정에는 적합하지 않다. 보석 공장처럼 하루 한 번, 일주일에 한 번 이렇게 진행되는 공정을 관리하는 데에 적합하다.
Airflow 실습하기
📥 설치하기
✅ 나는 맥과 WSL에서 모두 진행해보았다. 둘 다 동일하게 문제없이 아래에 소개할 방식으로 잘돌아갔다.
- 먼저 새로운 콘다 환경을 하나 만들어줬다. 파이썬은 3.7 버전, 환경 이름은 airflow_env라고 정했다. 새로 만든 환경을 활성화시킨다.
conda create -n airflow_env python=3.7
conda activate airflow_env- 에어플로우를 설치한다. 홈 디렉토리에 airflow 라는 폴더가 하나 생겼을 거다.
pip3 install apache-airflowairflow라고 한 번 쳐서 잘 설치되었는지 확인하자. 사용할 수 있는 명령어에 대한 설명이 나온다면 성공.- airflow 폴더로 이동하고, airflow 데이터베이스를 초기화해준다.
cd airflow에어플로우 폴더 안에는 이런 파일들이 있다.

airflow db init여기까지 하고 나면 아래처럼 airflow.db 라는 애가 하나 생겼을 거다. 메타스토어를 만들었다고 생각하면 된다.

- airflow 폴더 안에 dags 라는 디렉토리를 생성해준다.
mkdir dags이 디렉토리에 대그들을 만들어줄 거다. 아래처럼 디렉토리가 생성되면 된다.

- 에어플로우를 사용할 때 필요할 관리자 계정을 만들어준다.
airflow users create -u admin -p admin -f Clueless -l Coder -r Admin -e admin@admin.com-u 다음에 아이디, -p 다음에는 비번 (나는 둘 다 그냥 admin이라고 함), -f 다음에는 본인이 사용할 이름, -l 다음에는 성, 마지막 부분에는 이메일을 쓴다.
- 에어플로우 웹서버와 스케줄러를 켜주겠다. 먼저 웹서버를 한 터미널에서 실행시키고, 포트는 사용할 수 있는 포트를 사용하면 된다(디폴트가 8080 포트이므로 8080 포트를 쓸 거면
-p 8080은 빼도 된다).
airflow webserver -p 8080 아래처럼 나오면 성공이다.
아래처럼 나오면 성공이다.
다른 터미널 창을 하나 더 열어서 스케줄러를 실행한다. (새로 열린 터미널 창에서 아까 만든 콘다 환경 활성화시키는 것을 잊지 않도록 한다.)
airflow scheduler스케줄러도 실행한다. 아래처럼 나오면 성공.
⚠️ 에러가 나는 경우
이런 에러가 난다면, 이미 웹서버가 돌아가고 있는데, 또 돌릴라고 해서 그런 거다. 원래 켜놓은 웹서버 주소로 접속하면 된다.
혹은 한 원격 서버를 여러 유저가 사용하는 경우 동일한 포트를 사용하면서, 에러가 난다. 그럴 경우 그냥 없애 버리고 (맨아래에 써있는The webserver is already running under PID 8050에서 pid 인 8050 자리의 숫자를 확인하고kill <PID>명령으로 삭제해버리자). 포트가 겹치지 않도록 협의한 후에 본인이 사용 가능한 포트로 웹서버를 연다.
- 웹서버에 들어가보자. 나는 로컬로 진행했고, 8080번 포트를 사용하였으므로 브라우저를 열고 주소창에
0.0.0.0:8080아니면localhost:8080을 쳐서 웹서버에 접속한다. 이런 화면이 뜰거다. 여기에 본인 아이디와 비번을 넣고 로그인.
아래처럼 예시 대그들이 보이는 화면이 뜬다. CLI로 스케줄러에게 직접 지시할 수 있으나, 여기서는 웹서버를 활용해서 대그를 실행, 종료해보자.
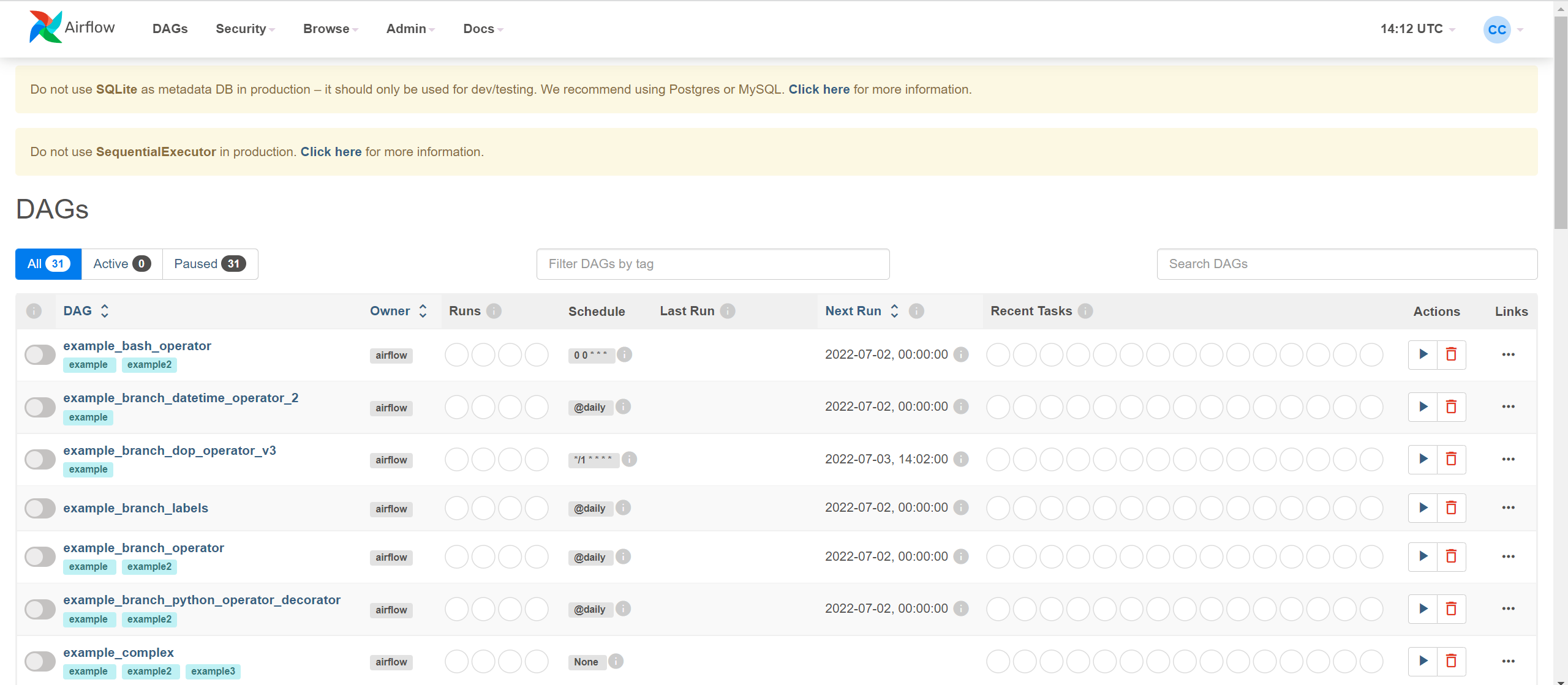
이 화면의 우측에 보면, Actions 칼럼에 실행 표시와 쓰레기통 표시로 각각 대그를 실행, 삭제할 수 있다.
🖥️ 웹서버 사용하기
예시 대그로 웹서버를 통해 어떻게 대그를 실행, 종료시키고 각종 기록을 확인하는지 알아보겠다. 예시 대그 중 하나인 example_branch_datetime_operator_2를 클릭한다. 아래와 같은 페이지가 나올 것이다.
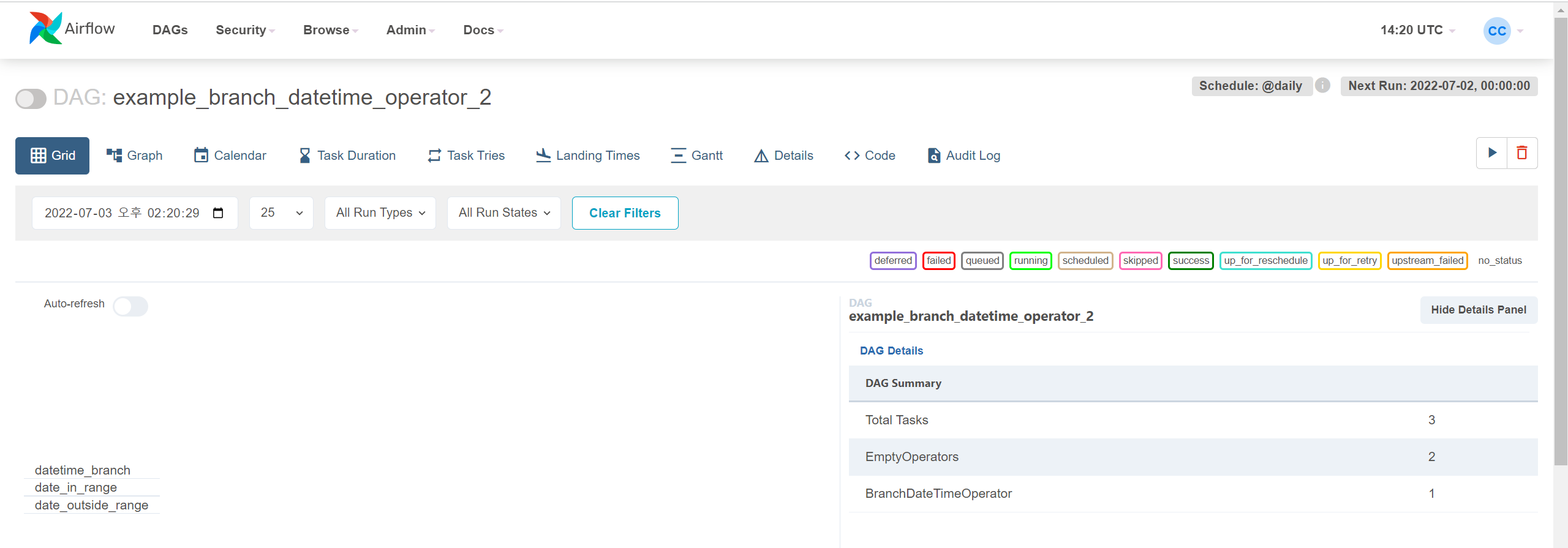
우측 상단의 ▶️ 버튼을 클릭하고 Trigger DAG 를 클릭하여 실행시켜보자. 화면이 아래처럼 바뀌었을 것이다. 긴 바로 된 진한 초록색은 대그가 성공적이었음을 알려주고, 긴 바가 두 개 생긴 것을 보니 대그가 두 번 실행되었다. 그리고 그 아래 작은 박스들은 해당 대그의 각 태스크가 잘 실행되었는지를 나타낸다. 색깔이 의미하는 바는 우측 상단을 참고한다.
우측 표에는 대그에 대한 여러가지 실행 기록이 나온다.
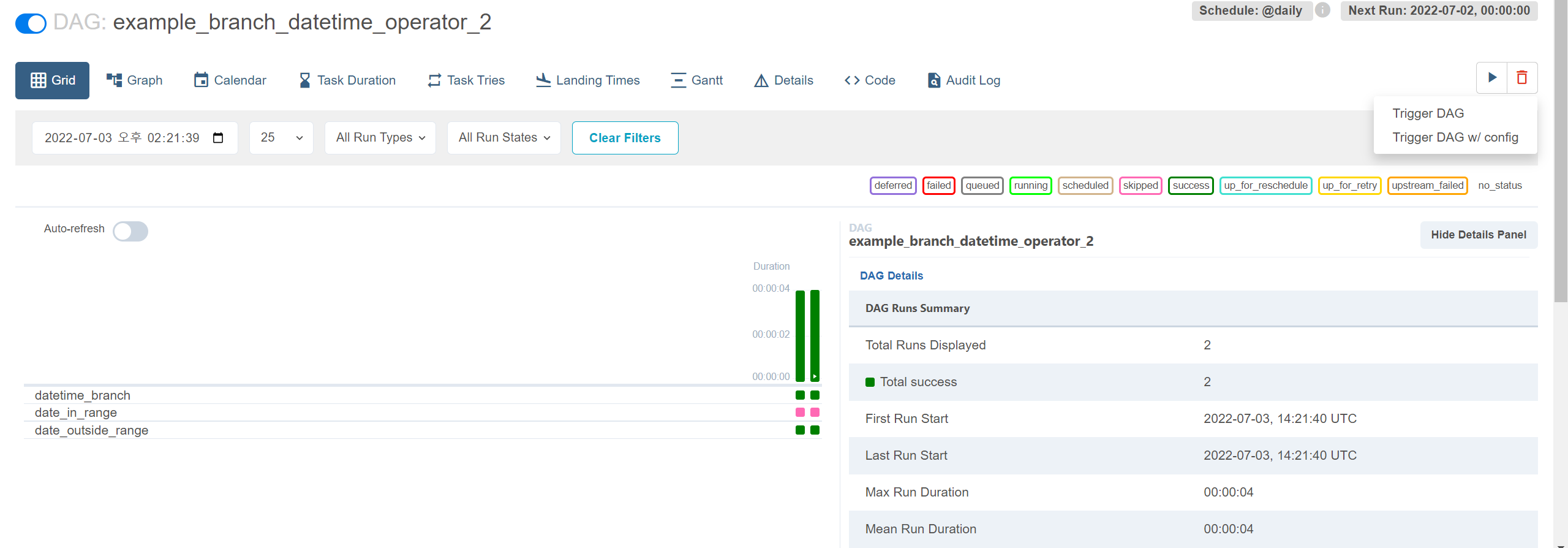
좌측 상단의 Graph 로 들어가보면, 대그가 어떻게 이뤄졌는지 순서도를 보여주고, 어떤 타입의 태스크인지(어떤 종류의 오퍼레이터를 사용했는지) 확인할 수 있다.
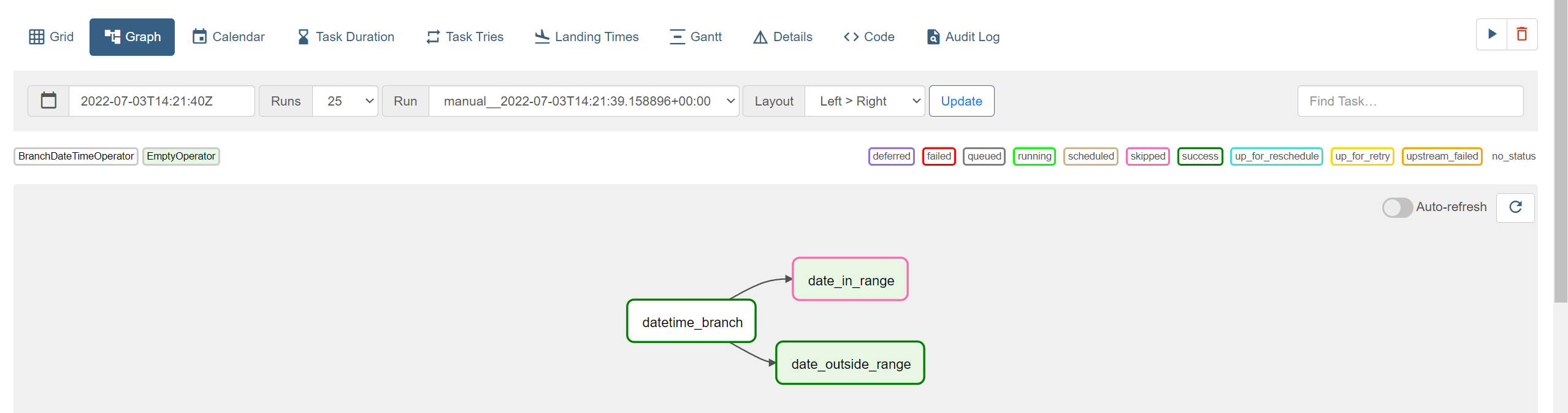
나머지 페이지도 하나씩 눌러보면 어떤 것을 의미하는지 알 것이다. Code 에서는 작성한 대그 코드(공장장이 설계한 오퍼레이터들과 그 연결)를 확인할 수 있다. 이 코드가 앞으로 우리(공장장)가 실제로 프로그래밍(기계 설계하고 순서도 만드는)하는 파트다.
대그를 일시정지 또는 재개하고 싶다면, 아래처럼 왼쪽 상단의 버튼으로 재개/정지한다.

이는 예시 대그이기때문에 아주 잘돌아갔을 거다. 실제로 대그를 만들어서 돌려보면 에러가 뜨는 경우가 많다. 따라서 조금 더 구체적인 웹서버 사용법은 실제 대그를 만들어보면서 익히는 것이 좋겠다.
🛠️ 대그 만들기
대그를 만드는 것은 공장장이 공정 파이프라인을 설계하는 것과 같다고 했다. 이 설계 과정을 우리는 파이썬 코드로 구현한다.
오퍼레이터(기계) 종류 알기
먼저 공정에 사용할 기계들(오퍼레이터)이 어떤 종류가 있는지 알아야 한다. 그래야 이 공정에는 이 기계를 쓰고, 저 공정에는 저 기계를 쓰고 할 것이 아닌가. 아주 다양한 오퍼레이터가 존재하지만 여기서는 실습에 사용할 몇 가지만 소개하겠다(사실 BashOperator랑 PythonOperator만 알고 있어도 (효율성을 생각하지 않는다면) 웬만한 작업은 다 할 수 있다).
오퍼레이터는 크게 다음과 같이 분류된다:
- Action Operator : 간단한 연산 수행 오퍼레이터,
airflow.operators모듈 아래에 존재. 실습에서 사용할 대부분의 오퍼레이터는 여기에 속한다. - Transfer Operator : 데이터를 옮기는 오퍼레이터,
<출발>To<도착>Operator꼴. - Sensor : 태스크를 언제 실행시킬 트리거(이벤트)를 기다리는 특별한 타입의 오퍼레이터 (예를 들어 어떤 폴더에 데이터가 쌓여지기를 기다린다든지, 요청에 대한 응답이 확인되기를 기다린다든지).
이 실습에서 사용할 오퍼레이터는 다음과 같다:
- PythonOperator : 파이썬 코드를 돌리는 작업을 할 때 사용하는 기계
- BashOperator : bash 명령어를 실행시키는 작업을 할 때 사용하는 기계
- SqliteOperator : SQL DB 사용과 관련된 작업을 할 때 사용하는 기계
- SimpleHttpOperator : HTTP 요청(request)을 보내고 응답(response) 텍스트를 받는 작업을 할 때 사용하는 기계
- HttpSensor : 응답(response)하는지 확인할 때 사용하는 센서 기계
대그 프로그래밍하기
이 실습에서는 네이터 지역 검색 데이터를 가져오고 저장해서 과정 완료 이메일을 보내는 것을 다룬다. 순서는
- 데이터 저장할 공간 만들기(SQL 테이블 생성)
- 데이터 가져오는 것이 가능한지 확인하기
- 크롤링(데이터 가져오기)
- 전처리
- 저장
- 대그 완료를 알리기
까지 아주 간단한 과정을 진행해보겠다 (이 뒤로 머신러닝 모델을 돌린다든지, 시각화 자료까지 만든다든지, 여러 태스크가 따라올 수 있겠다). 각 작업(태스크)에서 사용할 방법/툴과 대응되는 에어플로우 기계(오퍼레이터)를 간단한 표로 나타내었다:
| 태스크 | 방법/툴 | 오퍼레이터 |
|---|---|---|
| 테이블 생성 | SQLite 테이블 생성 | SqliteOperator |
| API 확인 | 네이버 오픈 API 중 검색(지역) API | HttpSensor |
| 크롤링 | 네이버 오픈 API 중 검색(지역) API | SimpleHttpOperator |
| 전처리 | 파이썬 Pandas 라이브러리 사용 | PythonOperator |
| 저장 | Bash 명령어 사용하여 csv로 저장하고 테이블에 저장 | BashOperator |
| 완료 알리기 | 파이썬 함수 | PythonOperator |
사전 준비 : 네이버 API 어플리케이션 등록
이 준비단계는 데이터 크롤링을 할 때 API 를 사용한다면 필요한 부분으로 그렇지 않을 경우 생략해도 되고, 사용하는 API에 맞게 (카카오 API를 쓴다면, 카카오 공식 문서를 참고해서) 진행하면 된다.
네이버 API를 사용하려면 네이버 개발자 센터에서 애플리케이션을 등록하고 클라이언트 아이디와 클라이언트 시크릿을 발급받아야 한다.
네이버 API 사용 가이드에서 엄청 친절하게 사용법을 알려준다. 그대로 따라하자.
클라이언트 아이디와 클라이언트 시크릿을 발급받았다면 API 사용은 준비 완료다.
0. 대그 틀 만들기
대그의 기본적인 틀과 대그를 돌릴 주기 등을 먼저 설정해보겠다.
~/airflow/dags 폴더 안에 naver_search_pipeline.py 파일을 만든다. 이 파일에 하나의 대그를 코딩하는 것이다 (공정 파이프라인을 설계하는 것).
대그의 기본 설정(대그 아이디(유일하게), 대그를 돌릴 주기, 태그 등 설정)을 완성한다.
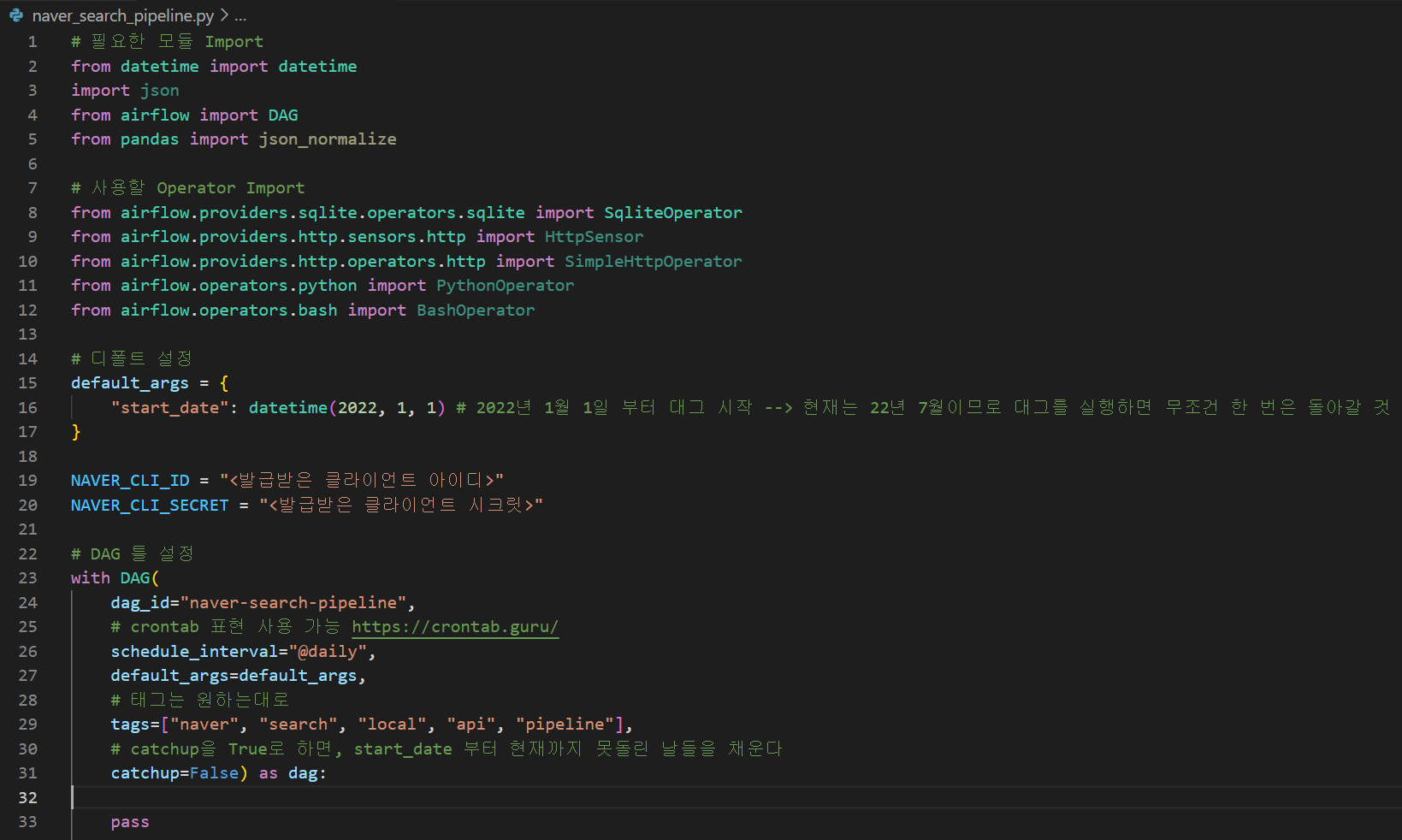
웹서버에 들어가서 태그 중에 하나인 naver를 검색하면, 대그가 새로 추가된 것을 확인할 수 있다(웹서버에 보이기까지 시간이 좀 걸릴 수도 있으니 뜨지 않는다면 조금 기다려보자).

이어서 대그의 작업 순서대로 오퍼레이터들을 만들고, 맨마지막에 연결하는 코드를 작성하는 순으로 설명한다.
1. SqliteOperator - 데이터 저장할 테이블 생성하기
가장 먼저 SqliteOperator 를 이용해서 데이터를 저장할 테이블을 생성해준다. SqliteOperator는 특정 Sqlite 데이터베이스에 대해서 sql 코드를 실행해주는 오퍼레이터다. 따라서 그 특정 Sqlite 데이터베이스가 무엇인지 연결해줄 필요가 있다. 다음과 같이 작성한다.
task_id=<작업을 구분할 아이디>sqlite_conn_id=<나의 Sqlite 인스턴스와 연결할 때 필요한 커넥션 아이디>sql=<sql 쿼리문>
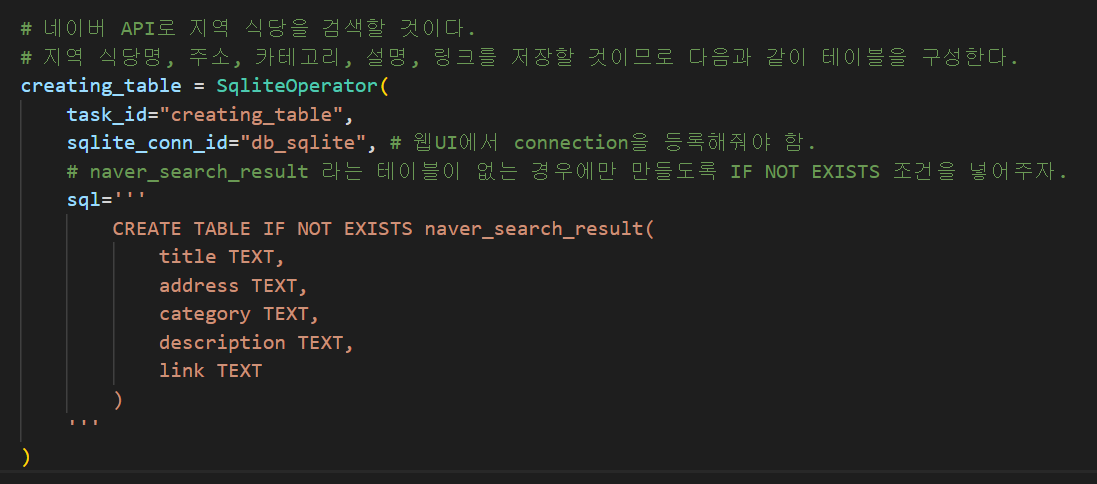
creating_table 이라는 이름은 태스크명으로 본인이 원하는 대로 지어주면 된다. 코드를 저장하고 웹서버에 들어가보자. naver-trend-pipeline 대그 페이지에서 Graph 를 들어가보면 우리가 만든 creating_table 태스크가 보인다.
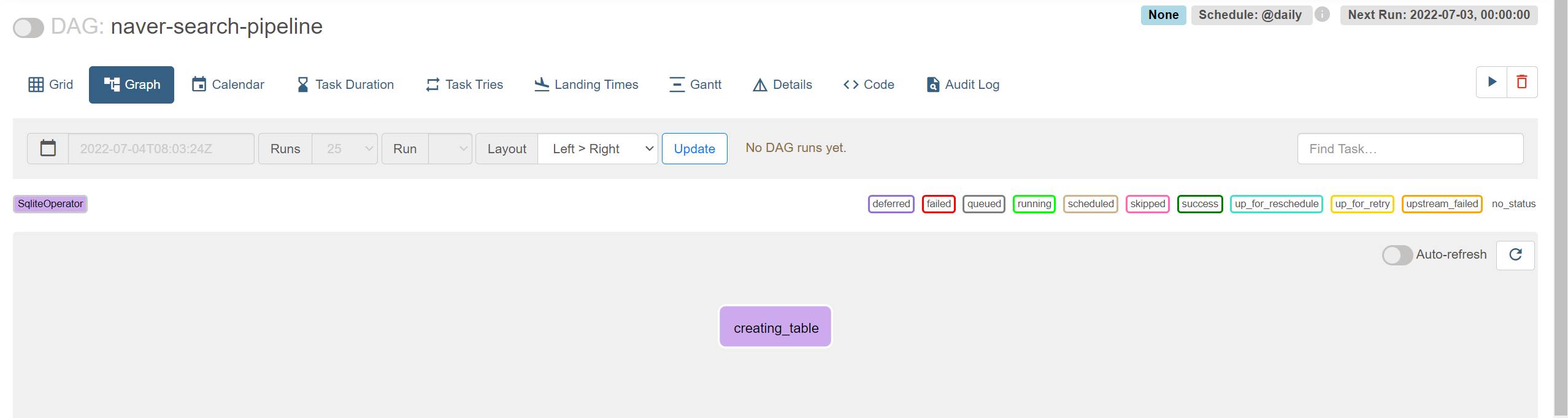
내 Sqlite 인스턴스와 연결하려면 웹서버에 들어가서 등록해줘야 한다. 아래처럼 웹서버 화면 상단에 Admin의 Connections를 클릭.
새로운 커넥션을 추가해주기 위해 우측 상단의 + 버튼 클릭.
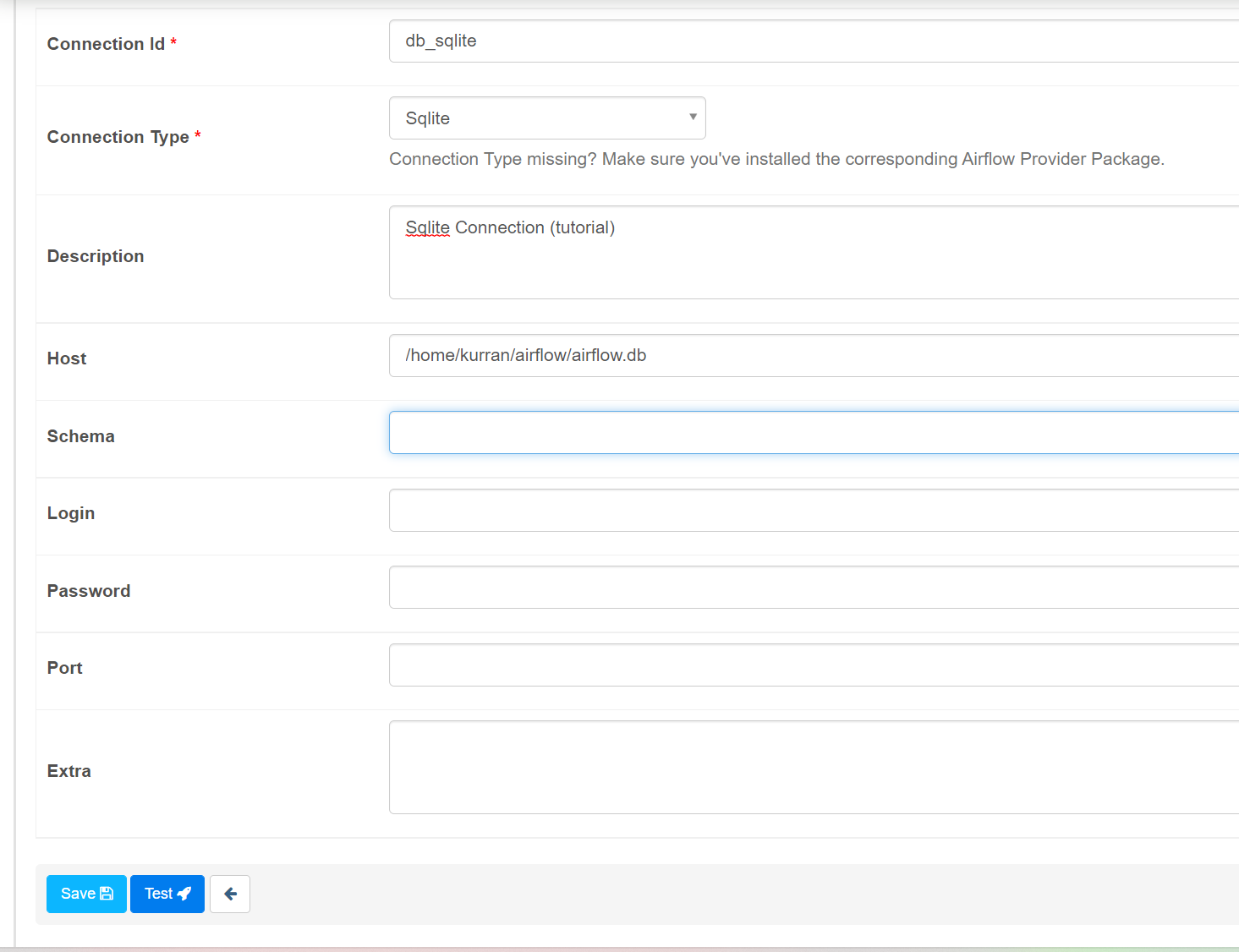
아래와 같이 정보를 기입하고 저장 (Host 에는 본인 airflow.db가 있는 경로).
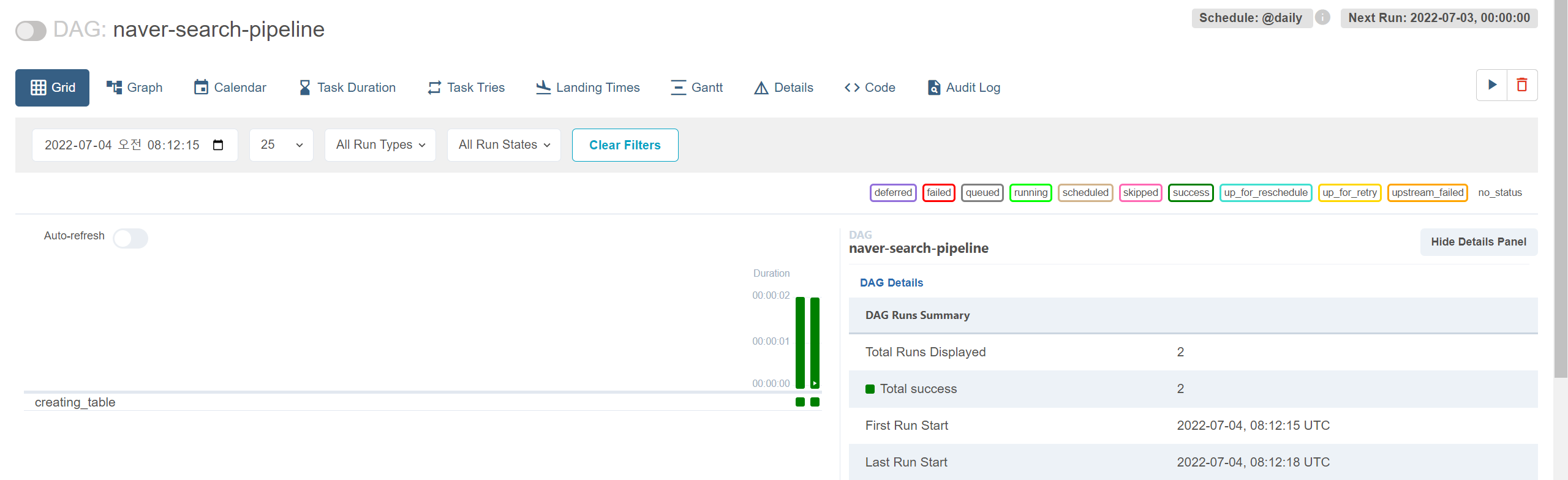
대그를 일단 한번 실행해보자. 터미널에서 실제로 생성되었는지 확인도 하자.
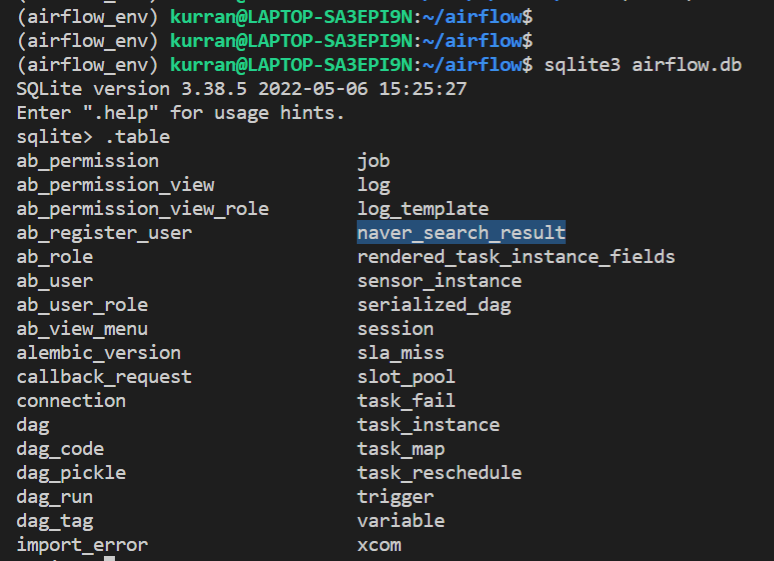
sqlite3 airflow.db 라고 치고, .table 이라고 치면 현재 생성되어있는 테이블들을 모두 확인할 수 있다. naver_search_result 테이블이 만들어져 있는 것을 확인할 수 있다.
2. HttpSensor - 데이터 가져오는 것이 가능한지 확인하기
저장할 곳은 잘생성되었으니, 이제 데이터를 가져오는 것이 가능한지 센서로 확인한다. 먼저 아까처럼 Admin > Connections > + 로 네이버 API에 대한 커넥션을 생성해준다. 커넥션 아이디는 naver_search_api 라고 했다.
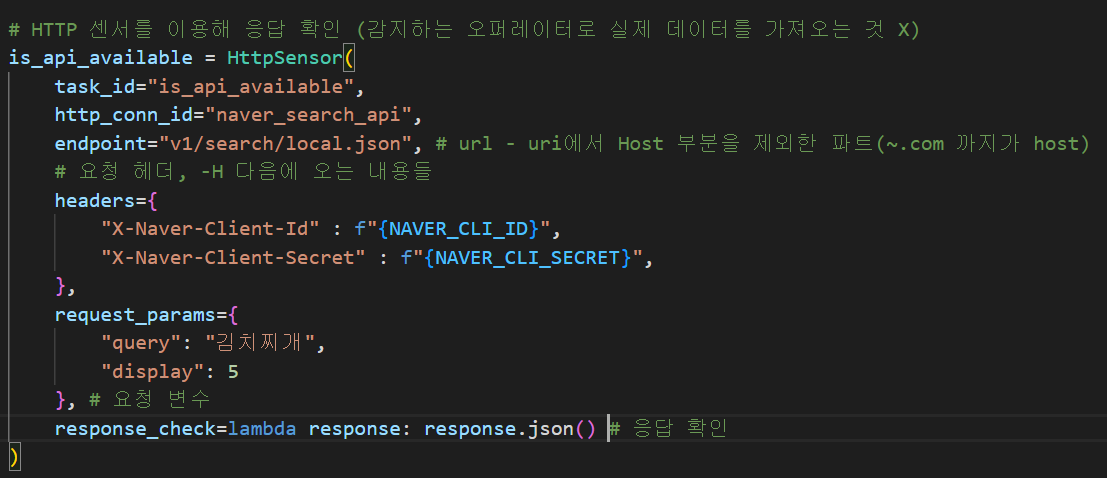
이제 센서에 대한 코드를 작성한다. 네이버 검색(지역) API 가이드를 확인해서 파라미터들을 넣어주도록 하자. 아래 예시를 참고해서 헤더를 체크한다. 아까 발급받은 클라 아이디와 클라 시크릿을 넣어준다. 요청 변수로는 5개까지 검색 결과를 보도록 display는 5를 주고, 필수 파라미터인 query로 김치찌개를 검색해보겠다.

웹서버에 대그에 들어가보면 잘생성되었음을 확인할 수 있다.

이 새로 만든 태스크가 잘돌아가는지 확인하고 싶기때문에(대그 전체를 돌리는 것이 아니라), CLI를 통해서 새로 만든 태스크 하나면 테스트를 해보겠다. 터미널에 다음과 같이 친다.
cd ~/airflow
airflow tasks test <대그 아이디> <태스크 아이디> <날짜>여기서는 airflow tasks test naver-search-pipeline is_api_available 2022-01-01 로 한다. 아래처럼 Success 가 뜨면 태스크가 잘 작동한다는 소리다.

실제로 가져오는 내용을 좀 확인하고 싶다면 아래처럼 response_check 파라미터에서 아웃풋을 print문 처리해주고 다시 테스트를 해보자.

아래처럼 검색된 내용을 확인할 수 있었다.

3. SimpleHttpOperator - 데이터 가져오기
이제 데이터를 가져올 수 있다는 것을 확인했으니, 데이터를 실제로 가져온다.
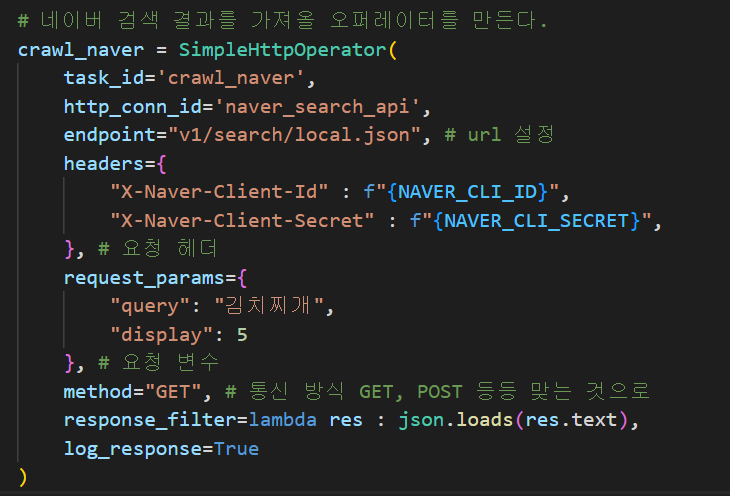
4. PythonOperator - 데이터 전처리하기
3번에서 가져온 데이터를 전처리한다. 같은 파일에 전처리 함수를 만들어줘도 괜찮지만, 더 조직적으로, 효율적으로 만들기 위해서 따로 전처리 폴더를 만들고 그 아래에 네이버 검색 결과 전처리 함수를 만들겠다.
검색 결과는 아래처럼 나온다.
{
"lastBuildDate":"Tue, 05 Jul 2022 00:24:17 +0900",
"total":5,
"start":1,
"display":5,
"items":[
{
"title":"한옥집 김치찜 본점"
"link":"http:\/\/hanokjib.co.kr\/community\/media\/",
"category":"음식점>한식",
"description":"",
"telephone":"",
"address":"서울특별시 서대문구 냉천동 20-1 1층 한옥집김치찜",
"roadAddress":"서울특별시 서대문구 통일로9길 12 1층 한옥집김치찜",
"mapx":"308714",
"mapy":"552177"
},
...
]
}따라서 결과의 items에서 title, link, category, description, address 를 가져오도록 하고, csv 파일로 저장하는 전처리 함수를 만든다.
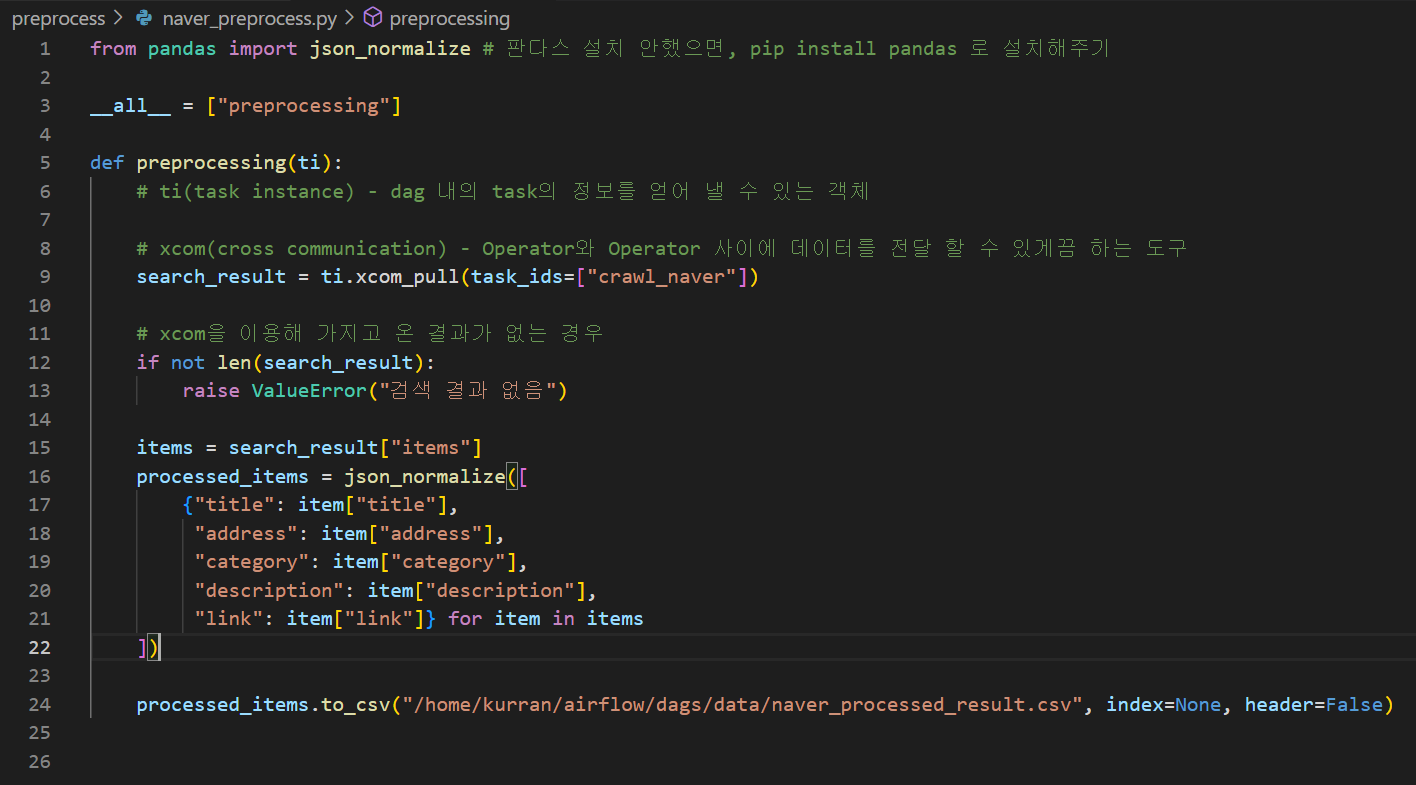
함수를 다 만들었으니 불러와서 대그에서 사용하도록 한다.


5. BashOperator - 데이터 저장하기
다음과 같이 저장된 csv 파일을 테이블로 저장한다.

6. PythonOperator - 대그 완료 알리기
모든 작업이 완료되었음을 알리기 위해 간단한 함수를 만든다. 이 함수에 일부러 에러를 하나 만들어 두었다. 대그를 실행해보면서 어떻게 문제를 확인하고 해결하는지 알아보겠다.


7. 작업들 연결하기 - 파이프라인 구성
맨 마지막에 태스크들을 순서대로 연결해서 파이프라인을 구성해준다.

그러면 웹서버에 다음과 같이 연결된 그래프의 모습으로 업데이트 될 것이다.

전체 DAG 파일 코드
# 필요한 모듈 Import
from datetime import datetime
from airflow import DAG
import json
from preprocess.naver_preprocess import preprocessing
# 사용할 Operator Import
from airflow.providers.sqlite.operators.sqlite import SqliteOperator
from airflow.providers.http.sensors.http import HttpSensor
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.operators.email import EmailOperator
# 디폴트 설정
default_args = {
"start_date": datetime(2022, 1, 1) # 2022년 1월 1일 부터 대그 시작 --> 현재는 22년 7월이므로 대그를 실행하면 무조건 한 번은 돌아갈 것
}
# 본인이 발급받은 키를 넣으세요
NAVER_CLI_ID = "your_cli_id"
NAVER_CLI_SECRET = "your_cli_secret"
def _complete():
print("네이버 검색 DAG 완료")
# DAG 틀 설정
with DAG(
dag_id="naver-search-pipeline",
# crontab 표현 사용 가능 https://crontab.guru/
schedule_interval="@daily",
default_args=default_args,
# 태그는 원하는대로
tags=["naver", "search", "local", "api", "pipeline"],
# catchup을 True로 하면, start_date 부터 현재까지 못돌린 날들을 채운다
catchup=False) as dag:
# 네이버 API로 지역 식당을 검색할 것이다.
# 지역 식당명, 주소, 카테고리, 설명, 링크를 저장할 것이므로 다음과 같이 테이블을 구성한다.
creating_table = SqliteOperator(
task_id="creating_table",
sqlite_conn_id="db_sqlite", # 웹UI에서 connection을 등록해줘야 함.
# naver_search_result 라는 테이블이 없는 경우에만 만들도록 IF NOT EXISTS 조건을 넣어주자.
sql='''
CREATE TABLE IF NOT EXISTS naver_search_result(
title TEXT,
address TEXT,
category TEXT,
description TEXT,
link TEXT
)
'''
)
# HTTP 센서를 이용해 응답 확인 (감지하는 오퍼레이터로 실제 데이터를 가져오는 것 X)
is_api_available = HttpSensor(
task_id="is_api_available",
http_conn_id="naver_search_api",
endpoint="v1/search/local.json", # url - uri에서 Host 부분을 제외한 파트(~.com 까지가 host)
# 요청 헤더, -H 다음에 오는 내용들
headers={
"X-Naver-Client-Id" : f"{NAVER_CLI_ID}",
"X-Naver-Client-Secret" : f"{NAVER_CLI_SECRET}",
},
request_params={
"query": "김치찌개",
"display": 5
}, # 요청 변수
response_check=lambda response: response.json() # 응답 확인
)
# 네이버 검색 결과를 가져올 오퍼레이터를 만든다.
crawl_naver = SimpleHttpOperator(
task_id="crawl_naver",
http_conn_id="naver_search_api",
endpoint="v1/search/local.json", # url 설정
headers={
"X-Naver-Client-Id" : f"{NAVER_CLI_ID}",
"X-Naver-Client-Secret" : f"{NAVER_CLI_SECRET}",
}, # 요청 헤더
data={
"query": "김치찌개",
"display": 5
}, # 요청 변수
method="GET", # 통신 방식 GET, POST 등등 맞는 것으로
response_filter=lambda res : json.loads(res.text),
log_response=True
)
# 검색 결과 전처리하고 CSV 저장
preprocess_result = PythonOperator(
task_id="preprocess_result",
python_callable=preprocessing # 실행할 파이썬 함수
)
# csv 파일로 저장된 것을 테이블에 저장
store_result = BashOperator(
task_id="store_naver",
bash_command='echo -e ".separator ","\n.import /home/kurran/airflow/dags/data/naver_processed_result.csv naver_search_result" | sqlite3 /home/kurran/airflow/airflow.db'
)
# 대그 완료 출력
print_complete = PythonOperator(
task_id="print_complete",
python_callable=_complete # 실행할 파이썬 함수
)
# 파이프라인 구성하기
creating_table >> is_api_available >> crawl_naver >> preprocess_result >> store_result >> print_complete🏃♀️ 대그 실행하기, 에러 해결하기
웹서버에 들어가서 만든 대그를 실행해보자.
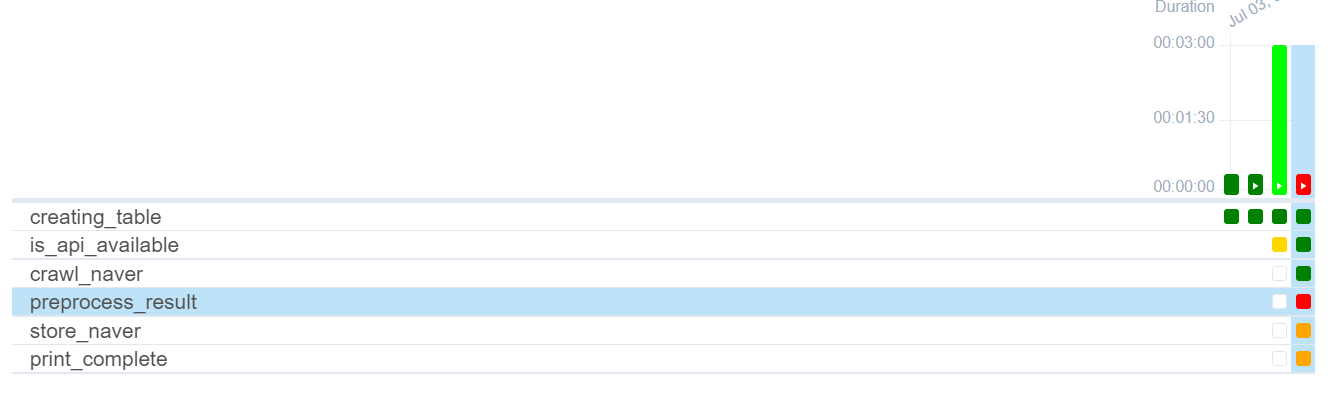
preprocess_result 태스크에서 문제가 생겨 빨간 박스로 표시되었다. 문제를 확인하려면 로그를 확인해야 한다. 문제의 박스를 클릭하고, 우측에 Log 를 클릭한다.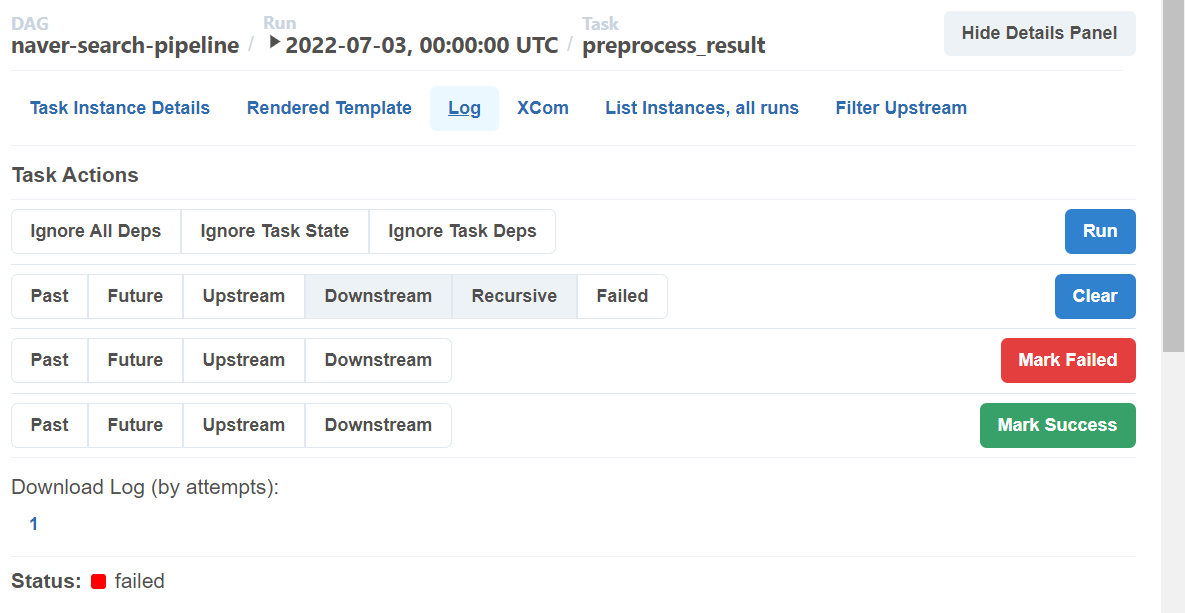
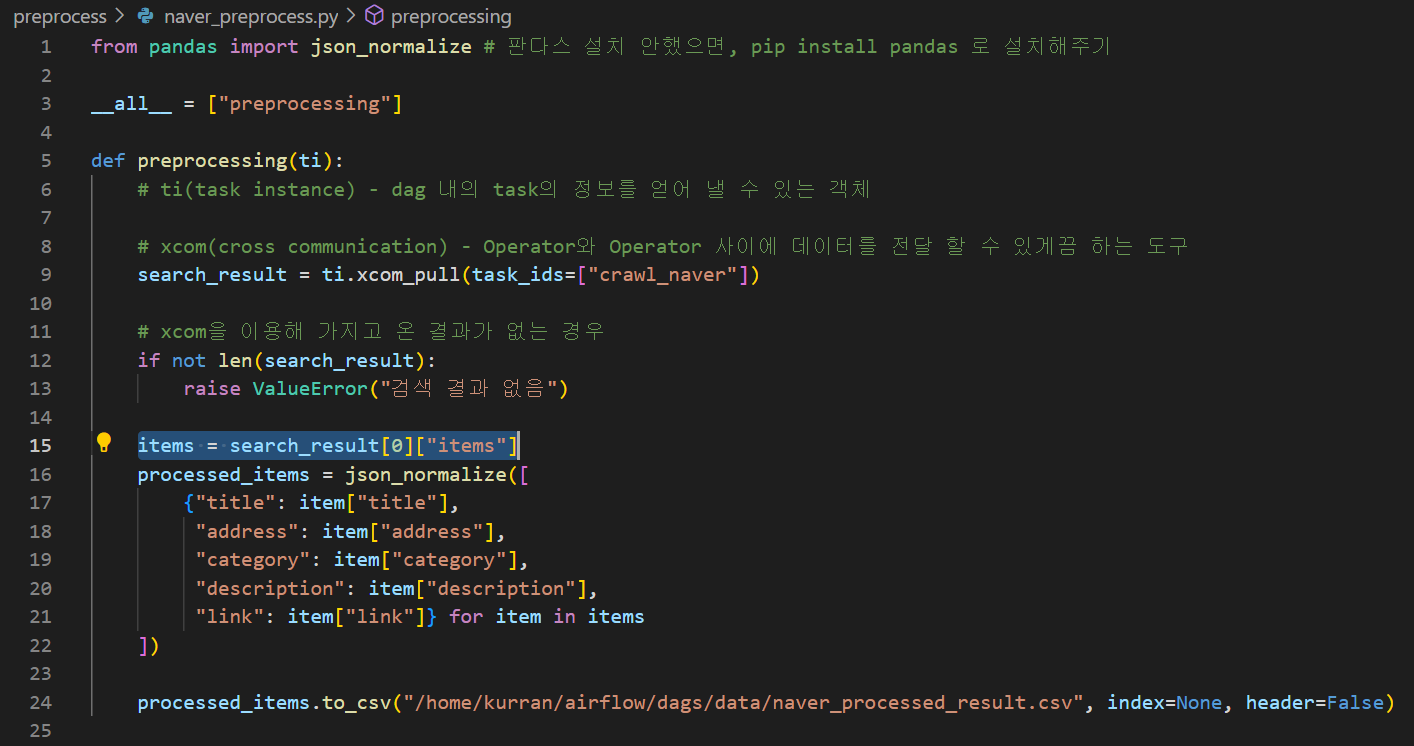
로그를 확인해보니, list indice로는 정수나 slice가 들어갈 수 있는데, string을 넣어버리는 실수를 했다. 코드를 수정해주자.

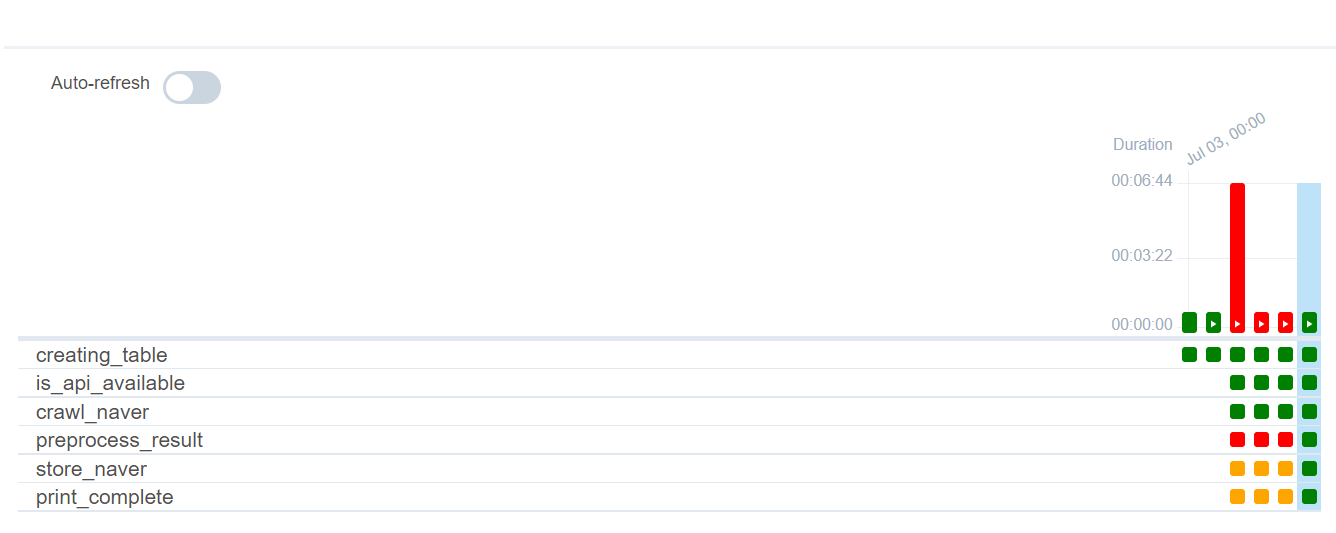
다시 돌려보자. 모든 작업들이 성공했다!
데이터들이 잘 저장되었는지 확인도 해보자. 먼저 전처리된 csv 파일을 보니 원하는대로 잘 저장되었다.

마지막으로 sqlite 테이블로 잘저장되었는지도 보자.
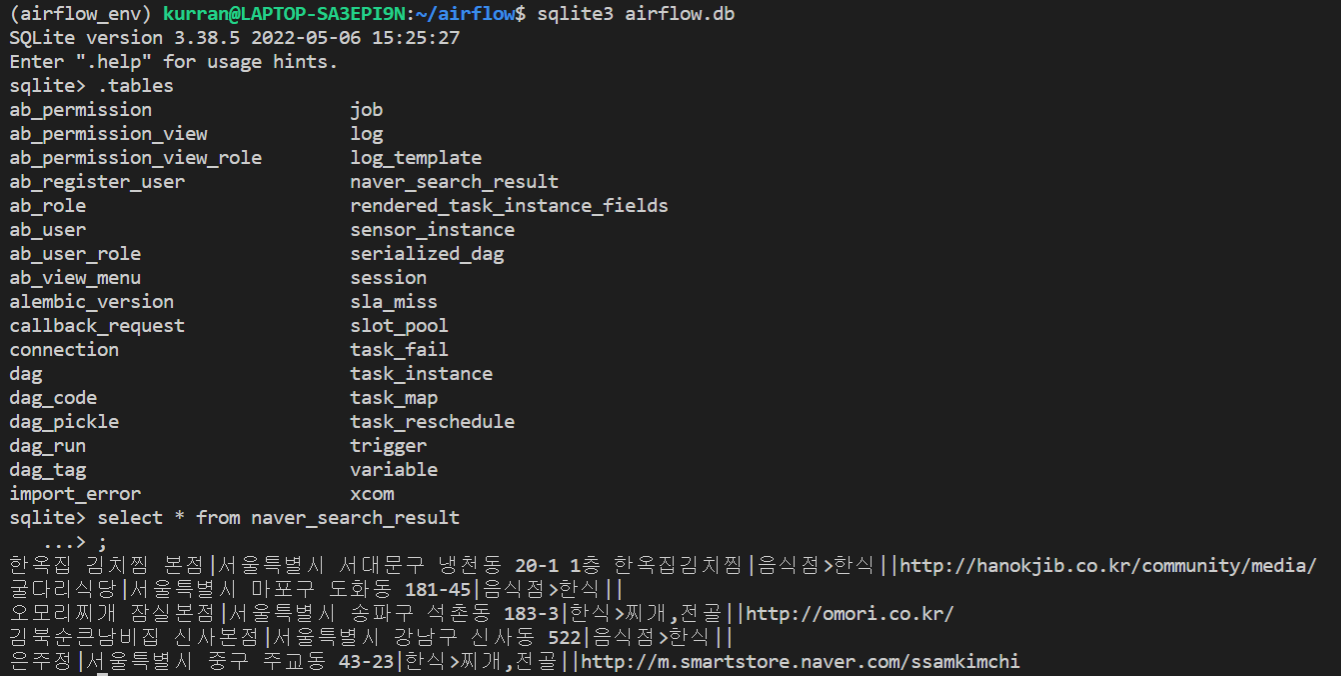
여기까지 아주 기초적인 에어플로우 실습을 해봤다. 여기서 등장한 오퍼레이터들만 사용하더라도 충분히 복잡한 작업을 수행하는 코드를 만들 수 있다.







안녕하세요! 대그 프로그래밍 전까지는 따라했는데.. ubuntu에서 ~airflow/dags에서 어떻게 naver_search_pipeline.py를 파일을 만들어 줄까요..? ubuntu에서 만든거라 제 실제 window에서는 airflow/dags폴더가 없는데!