
💬 QueryDsl을 사용하는 이유는 무엇일까?
QueryDsl을 사용하지 않을 경우
1. SQL로 작성하기
SELECT * FROM user WHERE name = 'Jhon'➡️ sql을 사용하면 JAVA 코드에서 사용하기 어렵다.
⚠️ SQL 의존하는 것은 좋지 않다. github JPA 정리본 - Chpater1 참고하기
2. JPQL로 작성하기
@Query("SELECT t FROM Todo t " +
"WHERE (:weather IS NULL OR t.weather = :weather) " +
"AND (:startAt IS NULL OR t.modifiedAt >= :startAt) " +
"AND (:endAt IS NULL OR t.modifiedAt <= :endAt) " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByOrderByModifiedAtDesc(
@Param("weather") String weather,
@Param("startAt") LocalDateTime startAt,
@Param("endAt") LocalDateTime endAt,
Pageable pageable); ➡️ 문자열로 쿼리를 작성하기 때문에 오타 발생 가능성이 있고 컴파일 시점에 오류를 잡을 수 없다는 치명적인 단점이 존재한다.
💬만약 위의 예시보다 더 복잡한 조건이 주어진다면?
➡️ 오류 발생 가능성도 증가하고 구현하기 어려워질 것이다.
위와 같은 JPQL의 한계를 보완하고 복잡한 동적 쿼리를 손쉽게 작성하기 위해 QueryDsl을 사용한다.
QueryDsl 설정 및 구현 과정
의존성 추가
//Querydsl 추가
implementation 'com.querydsl:querydsl-jpa:5.0.0:jakarta'
annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jakarta"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"빌드 해보기 (Q클래스 생성)
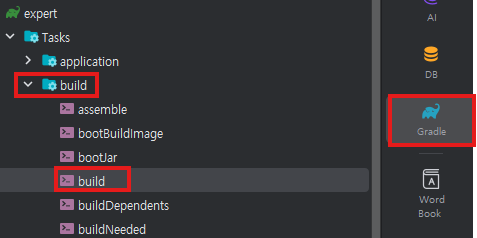
위와 같은 과정을 거치면 (gradle -> build -> build) 아래 사진과 같이 모든 Entity에 Q클래스가 생성된 것을 확인할 수 있다.
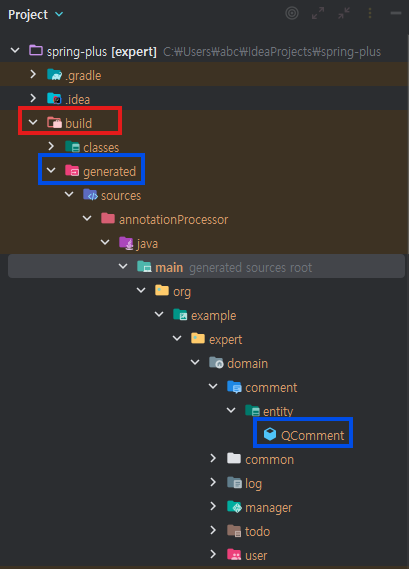
💡 Q클래스란?
엔티티 클래스의 메타 데이터를 가지고 있는 클래스이다.
이러한 Q클래스는
컴파일 단계에서 엔티티 기반으로 생성되며, QueryDsl은 이를 통해타입 안전성을 보장하며 쿼리를 작성할 수 있게된다.💬 타입 안전성?
➡️ 엔티티를 직접 사용하는 것이 아니라 엔티티
클래스 정보 활용을 위해 QClass를 만들어 사용함으로서 타입 안전한 쿼리작성을 할 수 있다.
Config
프로젝트에서 QueryDsl을 사용하기 위한 설정으로 JPAQueryFactory를 Bean으로 등록한다.
@Configuration
public class JPAConfiguration {
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}Repository를 통해 QueryDSL 사용
🟢 기존의 레포지토리
JpaRepository를 상속받고 있다.

JpaRepository는 기본적인 CRUD 기능을 제공해주기 때문에 복잡한 쿼리를 작성하기 위해서는 RepositoryCustom(인터페이스)로 관리해야한다.
🟢 RepositoryCustom
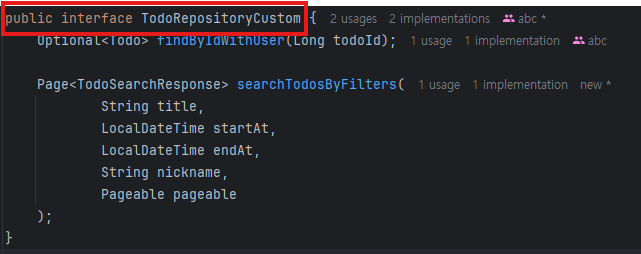
🤔 RepositoryCustom을 인터페이스로 관리하는 이유가 궁금해서 gpt한테 물어보니 아래와 같은 답변을 해주었다.
JpaRepository를 그대로 유지하면서 QueryDSL을 추가하면, Spring Data JPA가 제공하는 기능(@Query 같은 것들)과 QueryDSL을 함께 사용할 수 있어.
➡️ 간단한 조회는 JpaRepository에서 처리하고, 복잡한 동적 쿼리는 Custom Repository에서 처리할 수 있어.
✅ QueryDSL 기반의 동적 쿼리는 변경될 가능성이 높아서 따로 인터페이스로 관리
✅ JPA 기본 기능과 QueryDSL 기반의 커스텀 기능을 분리하여 유지보수성 향상
✅ Spring Data JPA 기능을 유지하면서 확장성을 확보
🟢 RepositoryCustomImpl
QueryDsl을 통한 복잡한 쿼리 작업을 담당한다.
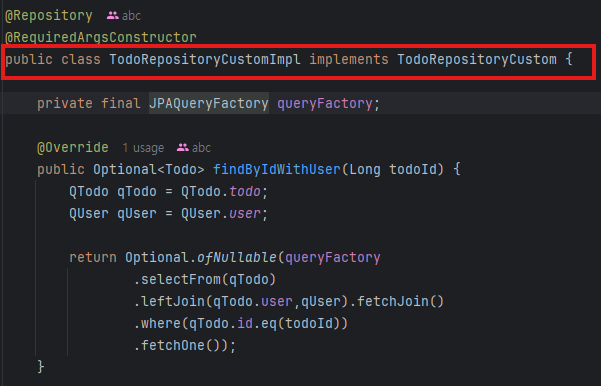
🔵 기존의 레포지토리를 아래와 같이 수정한다.

전체 코드
🟢 기존의 레포지토리
public interface TodoRepository extends JpaRepository<Todo, Long>, TodoRepositoryCustom {
@EntityGraph(attributePaths = {"user"})
@Query("SELECT t FROM Todo t " +
"WHERE (:weather IS NULL OR t.weather = :weather) " +
"AND (:startAt IS NULL OR t.modifiedAt >= :startAt) " +
"AND (:endAt IS NULL OR t.modifiedAt <= :endAt) " +
"ORDER BY t.modifiedAt DESC")
Page<Todo> findAllByOrderByModifiedAtDesc(
@Param("weather") String weather,
@Param("startAt") LocalDateTime startAt,
@Param("endAt") LocalDateTime endAt,
Pageable pageable);
}
🟢 RepositoryCustom
public interface TodoRepositoryCustom {
Optional<Todo> findByIdWithUser(Long todoId);
}🟢 RepositoryCustomImpl
@Repository
@RequiredArgsConstructor
public class TodoRepositoryCustomImpl implements TodoRepositoryCustom {
private final JPAQueryFactory queryFactory; //빈으로 등록했던 Factory
@Override
public Optional<Todo> findByIdWithUser(Long todoId) {
QTodo qTodo = QTodo.todo; //Q클래스 사용 (static을 뺄 수도 있다.)
QUser qUser = QUser.user;
return Optional.ofNullable(queryFactory
.selectFrom(qTodo)
.leftJoin(qTodo.user,qUser).fetchJoin()
.where(qTodo.id.eq(todoId))
.fetchOne());
}
}QueryDSL 을 사용하여 검색 기능 만들기 (심화 과정)
조건
👉 일정을 검색하는 기능을 만들고 싶어요!
검색 기능의 성능 및 사용성을 높이기 위해 QueryDSL을 활용한 쿼리 최적화를 해보세요.
❗Projections를 활용해서 필요한 필드만 반환할 수 있도록 해주세요❗
- 검색 조건은 다음과 같아요.
- 검색 키워드로 일정의 제목을 검색할 수 있어요.
- 제목은 부분적으로 일치해도 검색이 가능해요.
- 일정의 생성일 범위로 검색할 수 있어요.
- 일정을 생성일 최신순으로 정렬해주세요.
- 담당자의 닉네임으로도 검색이 가능해요.
- 닉네임은 부분적으로 일치해도 검색이 가능해요.
- 검색 키워드로 일정의 제목을 검색할 수 있어요.
- 다음의 내용을 포함해서 검색 결과를 반환해주세요.
- 일정에 대한 모든 정보가 아닌, 제목만 넣어주세요.
- 해당 일정의 담당자 수를 넣어주세요.
- 해당 일정의 총 댓글 개수를 넣어주세요.
- 검색 결과는 페이징 처리되어 반환되도록 합니다.
문제 풀이 과정
🟢 request 및 response
@Getter
@AllArgsConstructor
public class TodoSearchRequest {
private String title;
private LocalDate startAt;
private LocalDate endAt;
private String nickname;
}@Getter
@AllArgsConstructor
public class TodoSearchResponse {
private final String title;
private final long countManager;
private final long countComment;
}🟢 controller
//QueryDsl을 사용한 일정 검색 기능
@GetMapping("/todos/search")
public ResponseEntity<Page<TodoSearchResponse>> searchTodos(
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "10") int size,
@ModelAttribute TodoSearchRequest todoSearchRequest //@RequestParam도 가능하다.
) {
return ResponseEntity.ok(todoService.searchTodos(page, size, todoSearchRequest));
}💡 @ModelAttribute를 사용한 이유
[과제 과정] 1️⃣다른 서버의 API 데이터 가져오기2️⃣ @RequestParam vs @ModelAttribute
🟢 service
/**
* 검색 기능을 통한 일정의 제목, 담당자 수, 댓글 수를 조회하는 로직 수행
*
* @param page (현재 페이지)
* @param size (페이지 사이즈)
* @param todoSearchRequest (title,startAt, endAt, nickname)
* @return Page<TodoSearchResponse> (title, countManager, countComment)
*/
@Transactional(readOnly = true)
public Page<TodoSearchResponse> searchTodos(int page, int size, TodoSearchRequest todoSearchRequest) {
Pageable pageable = PageRequest.of(page - 1, size);
LocalDate startAt = todoSearchRequest.getStartAt();
LocalDate endAt = todoSearchRequest.getEndAt();
//시작 기간이 입력되지 않은 경우
if (ObjectUtils.isEmpty(startAt) ) {
startAt = LocalDate.MIN;
}
//끝 기간이 입력되지 않은 경우
if (ObjectUtils.isEmpty(endAt)) {
endAt = LocalDate.now(); //현재 시간
}
LocalDateTime formatStartAt = startAt.atStartOfDay();
LocalDateTime formatEndAt = endAt.atTime(LocalTime.MAX);
return todoRepository.searchTodosByFilters(
todoSearchRequest.getTitle(),
formatStartAt,
formatEndAt,
todoSearchRequest.getNickname(),
pageable
);
}💡
LocalDate.MIN

🟢 Repository
public interface TodoCustomRepository {
Optional<Todo> findByIdWithUser(Long todoId);
Page<TodoSearchResponse> searchTodosByFilters(String title, LocalDateTime startAt, LocalDateTime endAt, String nickname, Pageable pageable);
}
🟢 RepositoryCustom
public interface TodoRepositoryCustom {
Optional<Todo> findByIdWithUser(Long todoId);
Page<TodoSearchResponse> searchTodosByFilters(
String title,
LocalDateTime startAt,
LocalDateTime endAt,
String nickname,
Pageable pageable
);
}🟢 RepositoryCustomImpl 1️⃣ [group by 사용]
@Repository
@RequiredArgsConstructor
public class TodoCustomRepositoryImpl implements TodoCustomRepository{
... 생략
@Override
public Page<TodoSearchResponse> searchTodosByFilters(String title, LocalDateTime startAt, LocalDateTime endAt, String nickname, Pageable pageable) {
QTodo qTodo = QTodo.todo;
QManager qManager = QManager.manager;
QComment qComment = QComment.comment;
List<TodoSearchResponse> findTodos = jpaQueryFactory
.select(Projections.constructor(TodoSearchResponse.class,
qTodo.title,
qManager.count(),
qComment.count())
)
.from(qTodo)
.leftJoin(qTodo.managers, qManager)
.leftJoin(qTodo.comments, qComment)
.groupBy(qTodo)
.where(
searchTitle(title),
searchNickname(nickname),
qTodo.createdAt.between(startAt, endAt) //service 부분에서 null을 처리하였다.
)
.orderBy(qTodo.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 전체 데이터의 수 구하기
JPAQuery<Todo> countQuery = jpaQueryFactory
.selectFrom(qTodo)
.leftJoin(qTodo.managers, qManager)
.leftJoin(qTodo.comments, qComment)
.where(
searchTitle(title),
searchNickname(nickname),
qTodo.createdAt.between(startAt, endAt)
);
return PageableExecutionUtils.getPage(findTodos, pageable, countQuery::fetchOne);
}
private BooleanExpression searchTitle(String title) {
return StringUtils.hasText(title) ? QTodo.todo.title.likeIgnoreCase("%" + title + "%") : null; //입력된 tilte에 값이 있다면 like 조건 걸기
}
private BooleanExpression searchNickname(String nickname) {
return StringUtils.hasText(nickname) ? QTodo.todo.user.nickname.likeIgnoreCase("%" + nickname + "%") : null; //입력된 nickname에 값이 있다면 like 조건 걸기
}
}💡 Projections
select절에서 사용되며
쿼리 결과를 원하는 개체나 값으로 변환해주는 기능을 제공
Projections.constructor():생성자를 통해 접근하는 방법➡️ 명시적으로 DTO 클래스의 생성자를 지정할 수 있기 때문에 유연성을 높지만 생성자가 변경될 때마다 쿼리도 변경해야한다.
Querydsl - Querydsl 프로젝션으로 DTO 조회
💡BooleanExpression
QueryDsl은 where 조건에 null을 무시하는 특성을 이용하여,
조건이 null일 경우해당 조건을 쿼리에서 제외하는 방법을 이용할 수 있다.
QueryDsl 동적쿼리 작성 방법
[QueryDSL] 동적쿼리를 해결해보자
🤔 현재 코드에서는 기간 부분을 service에서 처리하였으나
QueryDsl은 where 조건에 null을 무시하는 특성이 있기 때문에 Repository에서 BooleanExpression를 사용하여 처리하는 것이 좋을 것 같다..where( searchTitle(title), searchNickname(nickname), qTodo.createdAt.between(startAt, endAt) // 기간 부분 );
💡 페이징 처리
// 전체 데이터의 수 구하기 JPAQuery<Todo> countQuery = jpaQueryFactory .selectFrom(qTodo) .leftJoin(qTodo.managers, qManager) .leftJoin(qTodo.comments, qComment) .where( searchTitle(title), searchNickname(nickname), qTodo.createdAt.between(startAt, endAt) ); return PageableExecutionUtils.getPage(findTodos, pageable, countQuery::fetchOne);
PageableExecutionUtils.getPage()에서countQuery::fetchOne부분은 람다를 사용하기 때문에 count 쿼리 호출이 지연되고, getPage가 내부에서 람다를 호출할지 말지 결정하기 때문에 최적화 메커니즘이 작동할 수 있다.
countQuery 최적화 부분- 인프런 질문
위와 같이 Group by를 이용해 검색 기능을 구현한 후 튜터님께 피드백을 받았을 때 아래와 같은 말씀을 해주셨다.
튜터님 조언
-
group by,case - when- then의 경우 내부에서 binary로 돌아가기 때문에 연산과정에서 좋은 성능을 내지 못한다. -
group by를 한다는 것 자체가 어떤 작업을 한다는 것을 의미한다. ➡️ 부하를 일으킬 수 있는 요소가 된다.
-
따라서, QueryDsl로 데이터를 뽑아오고 서비스단에서 처리하도록 하는 것이 더 좋다.
🟢 RepositoryCustomImpl 2️⃣ [subquery 사용]
JPAExpressions를 이용해 서브쿼리를 작성할 수 있다.
@Repository
@RequiredArgsConstructor
public class TodoRepositoryCustomImpl implements TodoRepositoryCustom {
private final JPAQueryFactory queryFactory;
@Override
public Optional<Todo> findByIdWithUser(Long todoId) {
QTodo qTodo = QTodo.todo;
QUser qUser = QUser.user;
return Optional.ofNullable(queryFactory
.selectFrom(qTodo)
.leftJoin(qTodo.user,qUser).fetchJoin()
.where(qTodo.id.eq(todoId))
.fetchOne());
}
@Override
public Page<TodoSearchResponse> searchTodosByFilters(String title, LocalDateTime startAt, LocalDateTime endAt, String nickname, Pageable pageable) {
QTodo qTodo = QTodo.todo;
QManager qManager = QManager.manager;
QComment qComment = QComment.comment;
JPQLQuery<Long> manageCount = JPAExpressions
.select(qManager.count())
.from(qManager)
.where(qTodo.id.eq(qManager.todo.id));
JPQLQuery<Long> commentCount = JPAExpressions
.select(qComment.count())
.from(qComment)
.where(qTodo.id.eq(qComment.todo.id));
List<TodoSearchResponse> findTodos = queryFactory
.select(Projections.constructor(
TodoSearchResponse.class,
qTodo.title,
manageCount,
commentCount
))
.from(qTodo)
.where(
titleContains(title),
searchNickname(nickname),
qTodo.createdAt.between(startAt, endAt)
)
.orderBy(qTodo.createdAt.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 전체 데이터의 수 구하기
JPAQuery<Long> countQuery = queryFactory
.select(qTodo.count())
.from(qTodo)
.where(
titleContains(title),
searchNickname(nickname),
qTodo.createdAt.between(startAt, endAt)
);
return PageableExecutionUtils.getPage(findTodos, pageable, countQuery::fetchOne);
}
private BooleanExpression titleContains(String title) {
return StringUtils.hasText(title) ? QTodo.todo.title.containsIgnoreCase(title) : null;
}
private BooleanExpression searchNickname(String nickname) {
return StringUtils.hasText(nickname) ? QTodo.todo.user.nickname.containsIgnoreCase(nickname) : null;
}
}서브쿼리를 사용할 경우 아래와 같은 단점이 존재한다.
-
추가적인 연산 비용 발생
➡️ 가상의 테이블을 만드는 것이라고 생각하면 된다.
-
최적화를 받은 수 없다.
➡️ 메타 정보가 담겨있지 않다.
-
복잡한 쿼리
➡️ 서브쿼리의 내용이 복잡해지면 메인 쿼리의 가독성도 떨어질 수 있다.
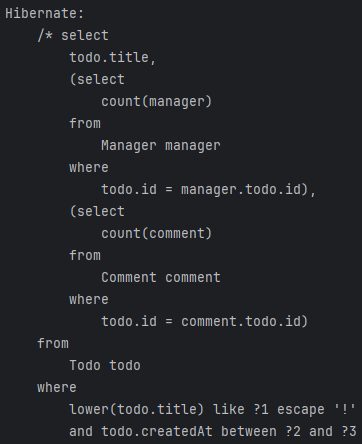
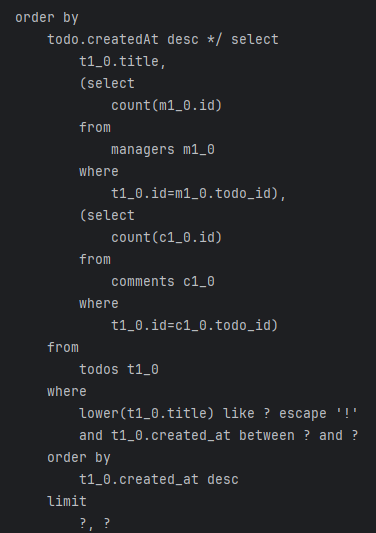
결론
QueryDsl을 group by, subquery를 사용하며 비교해본 결과 둘다 모두 공통적으로 추가적인 비용이 발생하는 단점이 존재했다.
개인적으로 생각하기에 둘의 성능 차이는 크게 나지 않을 것이라고 판단되었고 추후 더 복잡한 쿼리 로직을 구현해야한다면 튜터님의 조언대로 QueryDsl로 필요한 정보만 빼낸 뒤 Service에서 구현하는 것이 더 좋을 것 같다는 생각을 하게 되었다.
추후 프로젝트에서 다시 QueryDsl을 사용한다면 여러 방법을 구현한 뒤 성능 비교를 해보고 싶다.
