좋은 추상화와 나쁜 추상화
이미지 출처: viktor-kukurba.medium.com
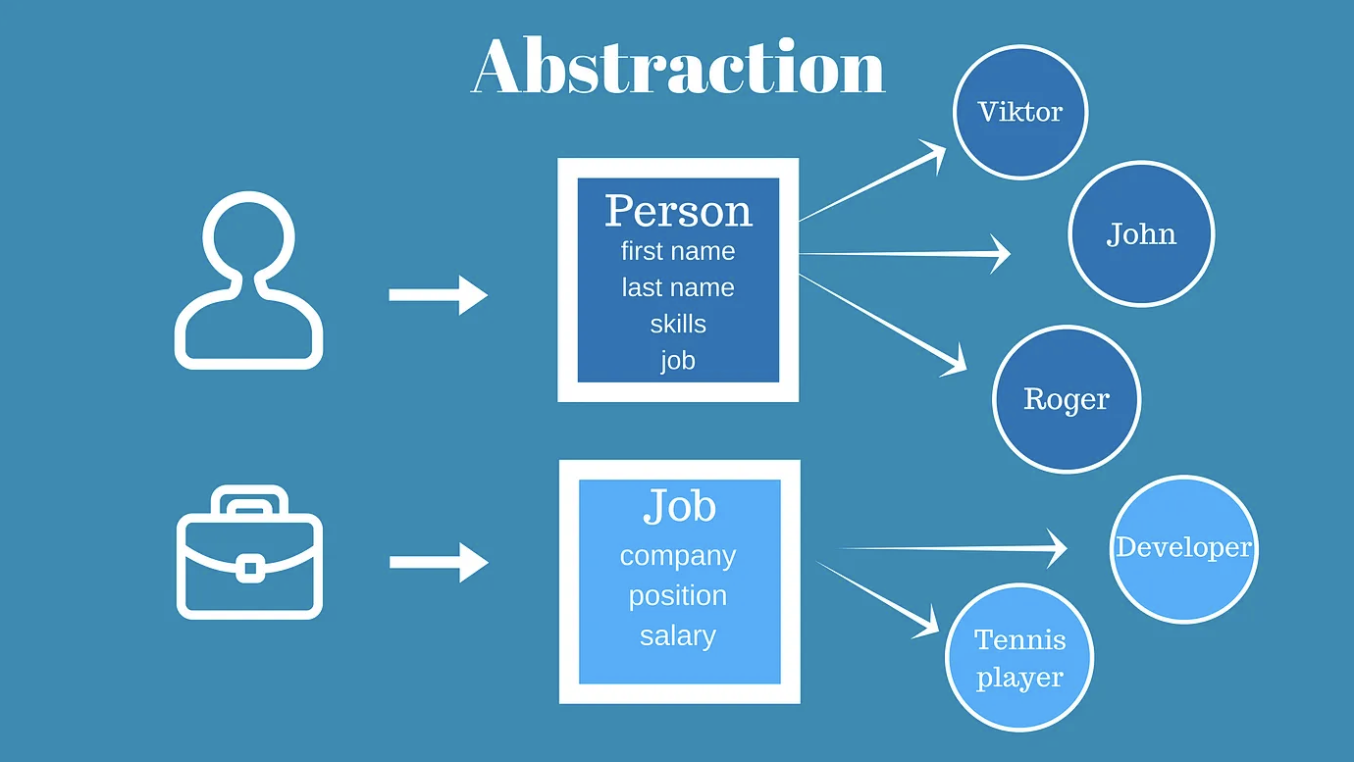
📌 추상화
추상화는 소프트웨어 개발의 핵심 원리 중 하나이다. 잘된 추상화는 복잡성을 줄이고 코드의 유지보수를 쉽게 만들어준다. 반면, 잘못된 추상화는 시스템을 복잡하게 만들고, 시간과 비용을 증가시킬 수 있다. 이 글에서는 추상화가 어떻게 발전하고, 때로는 잘못된 방향으로 갈 수 있는지, 그리고 이를 방지하는 방법에 대해 이야기한다.
좋은 추상화
📌 좋은 추상화의 특성
💡 깊은 모듈로 구성된 추상화
좋은 추상화는 깊은 모듈을 제공해야 한다. 깊은 모듈이란 단순한 사용법으로 복잡한 일을 처리할 수 있는 모듈을 말한다. 예를 들어, 함수를 하나 호출하면 그 안에서 복잡한 로직이 처리되는 코드는 좋은 추상화이다. 반면, 여러 매개변수를 요구하거나 복잡한 로직을 사용자에게 노출시키는 코드는 얕은 추상화이다. 추상화는 사용자가 쉽게 이해하고, 더 많은 가치를 얻을 수 있도록 도와야 한다.
💡 불필요한 세부 사항을 숨기는 추상화
추상화는 필요하지 않은 세부 사항을 감추고, 중요한 부분만 보여주어야 한다. 예를 들어, 네트워크 요청을 보내는 함수를 만들 때 axios나 fetch 같은 라이브러리를 사용하는지 굳이 드러낼 필요는 없다. 그저 "네트워크 요청을 보낸다"라는 기능만 표현되면 된다.
- 잘못된 예시
function fetchData(config) {
if (user.isLoggedIn) {
return axios(config);
} else {
return fetch(config.url);
}
}이 코드는 너무 많은 내부 동작을 드러내고 있어서 유지보수가 어렵다.
- 개선된 예시
async function fetchData(url) {
const config = { method: 'GET', url };
const response = await axios(config);
return response.data;
}이렇게 하면 함수의 동작이 일관되고, 네트워크 요청을 처리하는 방법이 바뀌더라도 함수 자체는 수정할 필요가 없다.
💡 단일 책임을 가진 추상화
좋은 추상화는 하나의 책임만을 가져야 한다. 서로 다른 기능을 한 함수에 섞어버리면 코드가 복잡해지고 유지보수가 어려워진다. 예를 들어, 데이터베이스를 업데이트하는 함수가 동시에 UI도 업데이트하는 건 좋지 않다. 이런 기능은 각각 별도로 분리해서 관리해야 한다.
📌 추상화의 이점과 비용
추상화에는 분명한 이점이 있다. Redux 창시자이자 React 핵심 개발자 Dan Abramov은 이를 세 가지로 요약한다.
💡 의도에 집중할 수 있다
추상화를 통해 개발자는 특정 기능에만 집중할 수 있다. 예를 들어, "send email" 함수를 호출하면 이메일이 어떻게 전송되는지 신경 쓰지 않아도 된다.
💡 코드 재사용
여러 곳에서 동일한 코드를 사용할 수 있어 유지보수 비용이 줄어든다.
💡 버그 방지
중복된 코드에서 발생할 수 있는 버그를 한 번에 수정할 수 있다.
나쁜 추상화
📌 나쁜 추상화가 만들어지는 일반적인 상황
프로그래머 A가 코드에서 반복되는 부분을 발견한다. "이걸 하나로 묶어서 함수로 만들고, 여러 곳에서 재사용하면 좋겠다"라고 생각한다. 그렇게 중복된 코드를 추출해서 하나의 함수로 만들고, 그 함수를 여러 곳에서 사용하도록 정리한다. 이 과정에서 프로그래머 A는 코드가 더 깔끔해지고, 유지보수도 쉬워질 거라고 기대한다.
하지만 시간이 지나 새로운 요구 사항이 생긴다. 이 새로운 요구 사항은 기존에 만든 추상화와 완벽히 맞지 않는다. 예를 들어, 기존 함수는 비동기 처리만 했는데, 새 기능은 동기 처리가 필요하다든지, 추가적인 조건을 처리해야 하는 경우가 생긴다.
프로그래머 B는 기존 추상화를 포기하지 않고 고수하려고 한다. 그래서 파라미터를 추가하거나 조건문을 넣어, 새로운 기능도 기존 함수 안에서 처리하게 한다. 이런 방식이 계속 반복되면 함수는 점점 복잡해지고, 추상화는 본래의 간결함을 잃게 된다.
결국, 이 함수는 단순한 공통 기능을 처리하는 것이 아니라, 다양한 특수한 경우를 처리하는 무거운 코드 덩어리가 된다. 코드가 복잡해질수록 이를 유지하려는 부담감이 커지며, 이는 "매몰 비용 오류"로 이어진다. 이미 많은 시간을 들여 작성한 코드를 버리기 어려워서, 계속해서 복잡한 조건을 추가하며 유지하려고 하게 되는 것이다.
📌 DRY와 나쁜 추상화의 탄생
많은 개발자들이 DRY(Don't Repeat Yourself) 원칙을 지키기 위해 추상화를 시도한다. 코드 중복을 피하기 위해 두 개의 유사한 코드 블록을 발견하면, 이들을 하나의 함수로 통합하는 것이 일반적인 접근이다. 그러나 이러한 추상화가 처음에는 효과적으로 보일 수 있지만, 시간이 지남에 따라 새로운 요구 사항이 등장하면서 점차 문제가 발생한다.
💡 나쁜 추상화의 진행 과정
- 초기 추상화: 두 개의 유사한 코드 블록이 발견되면, 개발자는 이를 통합하여 중복을 줄이려 한다.
- 새로운 요구 사항: 이후 비슷하지만 약간 다른 요구 사항이 등장할 때, 기존 추상화를 그대로 유지하려는 압박감 때문에 파라미터나 조건문을 추가하게 된다.
- 복잡성 증가: 이러한 과정이 반복되면 코드가 점점 더 복잡해지고, 추상화는 본래의 목적을 잃어버린다. 이로 인해 새로운 기능을 추가하거나 버그를 수정할 때 큰 어려움을 겪는다.
결국 이러한 추상화는 이해하기 어려운 코드가 되고, 기존 추상화를 유지하려는 부담감이 커진다. 이는 코드베이스가 점점 복잡해지면서 팀이 더 이상 문제를 해결하기 어려워지는 상황을 초래한다.
📌 나쁜 추상화의 문제점
Dan Abramov는 추상화가 지나치게 DRY하게 만들어지면 나쁜 결과를 초래할 수 있다고 경고한다. DRY 원칙을 맹목적으로 따르는 대신, 추상화의 비용과 이점을 고려해야 한다. 추상화의 비용에는 의도치 않은 결합, 추가적인 간접 참조, 팀의 개발 관성 등이 포함된다.
나쁜 추상화는 다음과 같은 문제들을 일으킬 수 있다.
💡 의도치 않은 결합
한 모듈의 변경이 다른 모듈에도 영향을 미쳐 의도하지 않은 버그가 발생할 수 있다.
💡 추가적인 복잡성
지나치게 추상화된 코드는 오히려 이해하기 어려워지고 유지보수가 복잡해진다.
💡 팀의 관성
복잡한 추상화를 유지하려는 심리적 부담감이 발생해, 코드 변경이 꺼려지게 된다.
📌 잘못된 추상화를 방지하는 방법 (좋은 추상화를 위한 지침)
Dan Abramov는 잘못된 추상화를 방지하기 위해 생각해 봐야하는 몇 가지 방법을 제시한다.
💡 구체적인 코드를 테스트하라
추상화된 코드 대신, 구체적인 비즈니스 로직을 테스트하라. 이를 통해 추상화가 변경되더라도, 테스트는 여전히 코드의 핵심 기능이 잘 작동하는지 확인할 수 있다.
💡 추상화를 미루라
두 코드 블록이 유사해 보일 때, 성급하게 추상화를 하지 말고 먼저 그 코드가 실제로 같은 문제를 해결하고 있는지 충분히 검토하라. 추상화는 필요할 때만 도입하는 것이 좋다.
💡 추상화 삭제를 허용하라
잘못된 추상화가 발견되면, 이를 과감하게 제거하고 각 코드 블록을 인라인화하는 것도 좋은 방법이다. 추상화를 추가하는 것만큼, 제거하는 것도 개발 과정의 중요한 부분이다.
