Ch14. The Block I/O Layer
Block device는 고정된 크기의 데이터 청크에 대한 랜덤 접근으로 구별되는 하드웨어 기기들이다. 고정된 크기의 청크 데이터가 block이라고 불린다. 가장 흔한 블록 디바이스는 하드 디스크이다.
다른 기본 기기 타입으로는 character device가 있다. 캐릭터 기기는 연속데이터의 흐름으로 접근된다. 예시로는 시리얼 포트 및 키보드가 있다. 하드웨어 기기가 데이터 스트림에 접근되었다면 character device이고, 랜덤하게 접근되었다면 block device이다.
커널이 블록 기기를 관리하는데에 더 많은 노력과 준비가 필요하다. 블록 기기는 미디어의 앞뒤로 위치를 계속 옮길 수 있어야하고, 성능에 민감하기 때문에 커널이 더 신경써서 관리해야 하는 것이다.
1. Anatomy of a Block Device
블록 기기에서 다룰 수 있는 가장 작은 단위는 sector라고 부른다. 섹터는 2의 거듭제곱의 크기를 가질 수 있지만, 512바이트가 가장 흔한 크기이다. 섹터 크기는 기기의 물리적 자원이며 섹터는 모든 블록 기기의 기본 단위이다. 따라서 기기는 섹터보다 작은 단위를 다루거나 연산할 수 없다.
소프트웨어는 다룰 수 있는 가장 작은 논리적 단위를 블록으로 정의한다. 블록은 파일시스템의 추상화이다. 파일시스템은 여러 블록에 거쳐 접근될 수 있다. 물리적 기기가 섹터 레벨에서 다룰 수 있다면, 커널은 모든 디스크 연산을 블록단위로 수행한다. 따라서 블록 크기는 섹터보다 작을 수 없고 반드시 섹터 크기의 배수여야한다. 게다가 커널의 블록은 2의 거듭제곱이여야 하고, 페이지 크기보다 클 수 없다. 보통 블록 크기는 512B, 1KB, 4KB로 많이 이용한다.
몇가지 혼동되는 용어들이 있다. 섹터는 hard sector, device block으로도 불린다. 블록은 filesystem block, I/O block으로도 불린다.
2. Buffers and Buffer Heads
블록이 메모리에 저장될 때 이는 버퍼에 저장된다. 각각의 버퍼는 하나의 블록과 연관되어있다. 즉, 버퍼는 메모리의 디스크 블록을 표현하는 것이다. 커널이 데이터를 수반하기 위해 관련된 제어 정보가 필요로 하기 때문에 각가의 버퍼는 descriptor와 연관된다. Descriptor는 buffer head로 불리고 buffer_head구조체를 갖는다. 해당 구조체는 <linux/buffer_head.h>에 정의되어있다. 이중 b_state 필드는 특정 버퍼의 상태를 나타내는데, 관련된 플래그는 bh_state_bits 열거형(enum)으로 저장되어 있다. b_count 필드는 버퍼의 사용횟수를 나타낸다. <linux/buffer_head.h>에 정의된 get_bh(), put_bh()함수에 의해 증가 및 감소한다.
버퍼 헤드를 조작하기 전에 get_bh()를 통해 값을 증가시켜주고, 버퍼 헤드의 이용이 끝났다면 put_bh()를 이용해 값을 감소시켜주어야한다.
2.6 커널 이전에는 버퍼 헤드가 굉장히 중요한 데이터 구조였다. I/O의 단위였기 때문이다. 버퍼헤드는 디크스 블록에서 물리적 페이지 매핑을 묘사할 뿐 아니라 모든 블록 I/O의 컨테이너 역할도 했다. 하지만 두 문제가 존재했는데, 첫번째는 버퍼헤드가 크고 다루기 어려운 데이터 구조체이며, 데이터를 다루는데 있어서도 깔끔하거나 간편한 편이 아니였다는 것이다. 대신 커널은 페이지 단위로 작업하는 것을 더 선호하며, 이 편이 더 간편하고 좋은 성능을 보인다. 큰 버퍼헤드가 각각의 버퍼를 비효율적으로 묘사한다. 두번째 문제는 단일 버퍼만 나타낸다는 것이다. 모든 I/O 연산의 컨테이너로서 사용될 때, 버퍼 헤드는 하나의 블록 연산을 여러 버퍼헤드 구조체로 쪼갠다. 따라서 필요없는 오버헤드와 공간 낭비가 발생한다. 이런 문제점을 보완하기 위해 bio 구조체를 리눅스 커널 2.5 버전에 도입했다.
3. The bio Structure
커널에서 블록 I/O의 기본 컨테이너로, <linux/bio.h>에 정의되어 있다. 구조체는 활성화된 부분들의 목록의 블록 I/O 작업을 표현한다. Segment는 메모리에서 연속적인 버퍼의 청크이다. 그러므로 개별적인 버퍼는 메모리에 연속적일 필요가 없다. 버퍼를 청크로 표현할 수 있게 되면서 bio 구조체는 커널이 메모리의 여러 위치에서 온 단일 버퍼에서조차 블록 I/O를 가능하게 한다. 이와 같은 Vecter I/O를 scatter-gather I/O라고 한다.
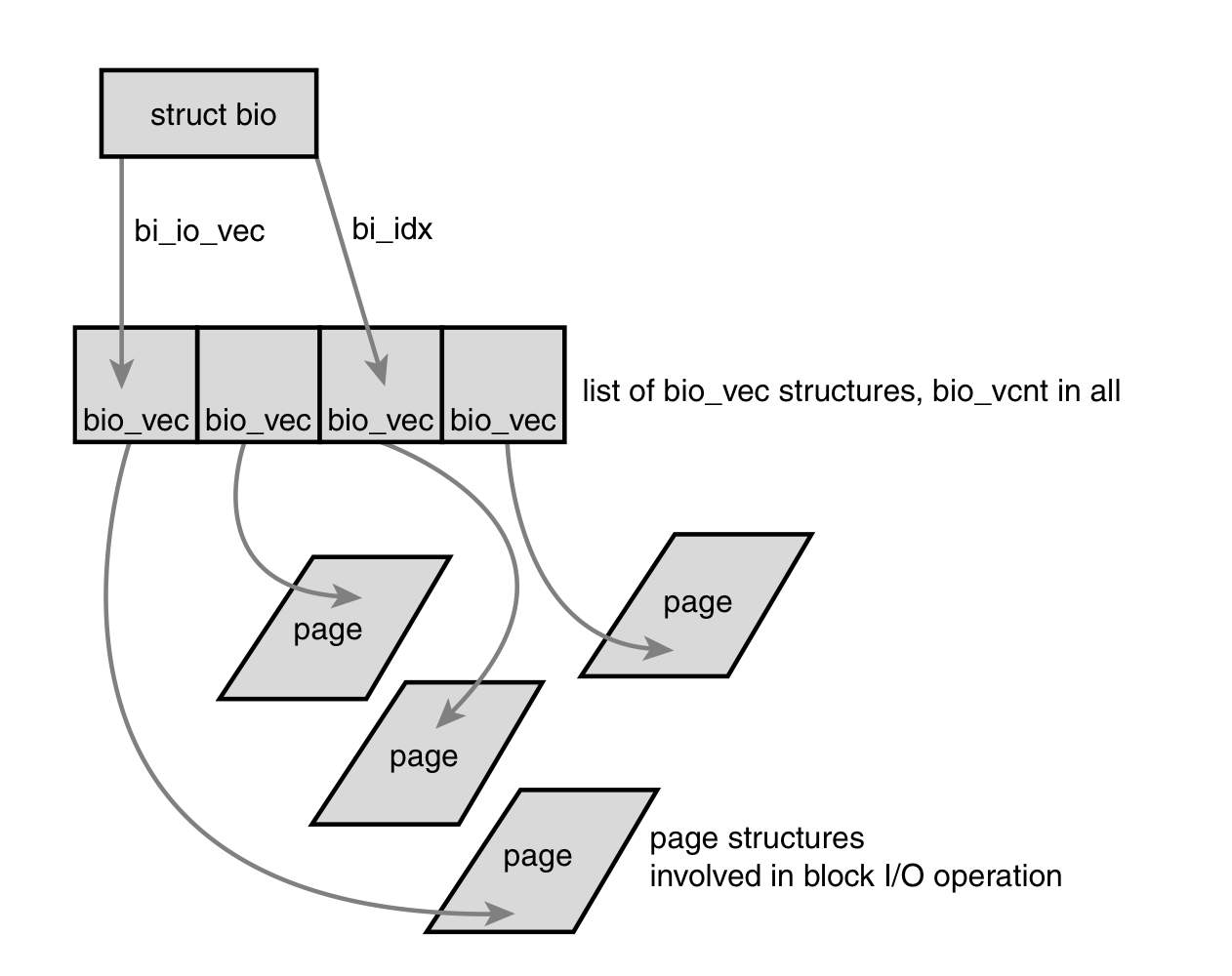
bio 구조체에서 가장 중요한 필드는 bi_io_vec, bi_vcnt, bi_idx이다. bi_io_vec은 bio_vec의 목록을 나타내고, bi_vcnt는 bio_vec의 오프셋 번호, bi_idx는 bi_io_vec에서 현재 인덱스를 나타낸다. bio구조체를 도식화하면 다음과 같다.
3.1. I/O vectors
bi_io_vec필드는 bio_vec구조체 배열을 가리킨다. 이 구조체는 이 특정 블록 I/O 동작에서 개별 세그먼트의 목록으로 사용된다. 각각의 bio_vec은 <page, offset, len>의 벡터형태로 다뤄진다. page는 물리적 페이지, offset은 블록에서의 위치, len은 블록의 시작부터 offset까지의 길이를 나타낸다.
각각의 블록 I/O 연산에서 bio_vec 배열에 bi_vcnt 벡터가 존재하며 이는 bi_io_vec부터 시작한다.
bi_vcnt
본문에는 number of bio_vecs off라고 되어있는데 그림을 보고 offset이라 유추하였다. 탐색이 완료된 것을 off라고 두고 완료된 벡터의 수를 나타내는 것일 수도 있겠다는 생각을 해본다. I/O 벡터 챕터에서는 반대로 수가 아닌 벡터로 취급하고 있는데 이 역시 혼동된다. bi_vcnt와 bi_idx는 unsigned short이다.
요약하자면 각각의 블록 I/O 요청은 bio 구조체로 표현된다. 각각의 요청은 하나 이상의 블록으로 구성되어 있고, 이는 bio_vec구조체의 배열로 저장되어있다.
이런 구조는 벡터처럼 동작하고 각각의 세그먼트의 메모리에서의 물리적 페이지의 위치를 표시한다. I/O 연산에서의 첫번째 세그먼트는 bi_io_vec에 의해 표시된다. 각각의 추가적인 세그먼트는 처음의 뒤를 이루며 목록의 모든 bi_vcnt 세그먼트에 닿을 때 까지 반복된다. 블록 I/O 레이어가 세그먼트를 제출하면 bi_idx 필드가 업데이트되어 최신 세그먼트를 가리킨다.
bi_idx필드는 목록상 현재 bio_vec을 가리키고, 이를 통해 블록 I/O 레이어가 부분적으로 완료된 I/O 연산을 추적할 수 있도록 한다. 하지만 이보다 더 중요한 목적은 bio 구조체를 쪼갠다는 것이다. 이 특징 덕분에 RAID를 구현하는 드라이버는 단일 bio 구조체를 가질 수 있다. RAID 드라이버가 해야할 것은 bio 구조체를 복사해 bi_idx 필드를 업데이트하여 개별적인 드라이브가 어디서부터 동작해야할 지 나타내는 것이다.
RAID (Redundant Array of Inexpensive Disks)
성능과 신뢰성의 목적으로 여러 디스크를 하나의 볼륨으로 묶는 하드디스크 설정방법
이외에도 bi_cnt필드는 bio_get()함수와 bio_put()함수를 이용해 그 값을 증가 / 감소할 수 있다. 이 필드값이 0이 되면 해당 bio구조체는 붕괴된다.
마지막으로 bi_private 필드는 해당 구조체의 소유자만의 사적 필드이다.
3.2. The Old Versus the New
버퍼 헤드와 bio 구조체의 차이를 아는 것이 중요하다. bio 구조체는 I/O 연산을 나타내며, 메모리상에 하나 이상의 페이지를 포함할 수 있다. 반면 buffer_head 구조체는 단일 버퍼를 표현하며 이는 디스크의 단일 블록을 의미한다. 버퍼헤드가 단일 디스크 블록에 단일 페이지에 묶여있기 때문에 버퍼헤드는 불필요하게 요청을 블록 사이즈단위의 청크로 나누고, 나중에 합친다. bio 구조체가 이러한 부분에서 더 가볍기 때문에 불연속적인 블록을 표현하고 불필요하게 쪼개지 않는다. 이외에도 bio 구조체가 갖는 이점은 아래와 같다.
bio구조체는 high 메모리를 쉽게 표현할 수 있다.bio구조체가 포인터가 아닌 물리적 페이지만 다루기 때문이다.bio구조체는 일반 페이지 I/O와 direct I/O(페이지 캐시를 경유하지 않는 I/O 연산)을 표현할 수 있다.bio구조체는 scatter-gather(벡터화된) 블록 I/O연산을 쉽게 수행할 수 있다.bio구조체는 버퍼 헤드보다 더 가볍다.bio구조체는 블록 I/O연산을 표현하기 위한 최소한의 필요한 정보만 포함하고 퍼버 스스로와 연관된 불필요한 정보는 불포함하기 때문이다.
버퍼 헤드는 디스크 블록을 페이지로 매핑하는 지시자로서의 기능을 한다. bio 구조체는 버퍼의 상태와 같은 정보는 가지고 있지 않다.
4. Request Queues
블록 기기들은 request queue를 통해 대기중인 I/O 요청을 저장한다. Request queue는 request_queue구조체로 표현되며, <linux/blkdev.h>에 정의되어있다. Request queue는 요청과 관련된 제어정보에 대한 양방향 연결 리스트를 포함한다. 요청은 파일시스템과 같은 커널 상 더 높은 차원의 코드에서 추가된다. Request queue가 비어있지 않으면 블록 기기 드라이버는 큐의 앞에서 요청을 받아와 연관된 블록 디바이스에 전달한다.
큐 안의 요청들은 각각 request 구조체로 표현되며 이 역시 <linux/blkdev.h>에 정의되어있다. 각각의 요청은 하나 이상의 bio 구조체로 구성될 수 있는데, 이는 개별적인 요청이 여러 연속된 디스크 블록에서 연산할 수 있기 때문이다. 디스크의 블록은 인접해 있어야 하지만, 메모리의 블록은 그럴 필요가 없다. 각각의 bio 구조체가 여러 세그먼트를 표현할 수 있고, 요청은 여러 bio 구조체로 구성되어있다. (세그먼트는 메모리 블록의 연속된 청크들이다.)
5. I/O Schedulers
커널이 발생시킨 순서대로 단순하게 요청을 블록 기기로 전달하는 것은 낮은 성능을 보일 수 있다. 현대 컴퓨터에서 가장 느린 연산이 디스크를 탐색하는 것이다. 각각의 탐색마다 하드 디스크의 헤드를 특정 블록의 위치로 이동시키는 것은 수 밀리초를 소요한다. 따라서 탐색 시간을 줄이는 것이 시스템 성능의 가장 중요한 목표이다.
그러므로 커널은 요청을 받은 순서대로, 혹은 받는대로 디스크에 블록 I/O 요청을 보내지 않는다. 대신, merging and sorting을 통해 시스템 전반의 성능을 매우 크게 향상시킨다. 이 연산을 수행하는 커널의 하위시스템을 I/O 스케줄러라고 한다.
I/O 스케줄러는 디스크 I/O의 자원을 대기중인 블록 I/O 요청들에게 나눈다. 이를 request queue에서 대기중인 요청들을 합치고 정렬하여 자원을 할당 분배한다. 프로세스 스케줄러가 프로세서의 자원을 시스템의 프로세스에 나누는 것과 유사하지만, 다르다. 프로세스 스케줄러와 I/O 스케줄러는 자원을 여러 객체에 가상화한다. 프로세스 스케줄러의 경우 프로세서가 가상화 되고 프로세스에 공유된다. 이는 멀티태스킹과 Unix와 같이 멀티태스킹을 지원하며 시간을 공유하는 운영체제에 가상화의 환상을 제공한다. 반면 I/O 스케줄러는 블록 기기를 여러 블록 요청으로 가상화한다. 이는 디스크 탐색을 최소화 하고 적절한 디스크 성능을 보장하기 위함이다.
5.1. The Job of an I/O Scheduler
I/O 스케줄러는 블록 기기의 요청 큐를 관리함으로써 동작한다. 스케줄러는 큐에서의 요청의 순서를 결정하고 각각의 요청이 언제 블록 기기에 전송될 지 결정한다. 스케줄러는 요청 큐가 탐색을 줄이는 목표를 달성하도록 관리한다. 시스템 전체의 성능을 높이는 방향으로 동작하기 때문에 몇몇 요청들을 불공평하게 다루기도 한다.
I/O 스케줄러는 두가지 주요 행동(병합과 정렬)을 한다. 병합은 두개 이상의 요청을 하나로 합치는 것이다. 예를 들어 파일시스템에서 파일에서 데이터 청크를 읽으라는 요청이 들어왔다고 한다면, 큐에 있는 요청 중 디스크의 인접한 섹터에서 읽어오는 요청이 있는지 확인한다. 그렇다면 두 요청은 하나의 요청으로 병합될 수 있다. 이를 통해 I/O 스케줄러는 여러 요청에 의한 오버헤드를 감소시킨다.
만약 요청중 인접한 섹터에서 읽어오는 것이 큐에 없다면 현재 요청을 큐의 마지막으로 보내버린다. 반대로 요청중 인접한 섹터에서 읽어오는 것이 큐에 있다면 현재 요청을 큐의 해당 요청의 옆에 집어넣는다. 따라서 전체적인 대키 큐는 정렬된 채로 존재하고 탐색 활동이 큐를 따라 진행된다. 목표는 각각의 탐색을 최소화 하는 것이 아닌 전체적인 탐색을 디스크 헤드가 곧게 이동하도록 하여 최소화 시키는 것이다. 이는 엘리베이터에 적용된 알고리즘과 유사하다. 엘리베이터는 층과 층 사이를 왔다갔다 하지 않고, 한 방향으로 이동하면서 처리하는 방향으로 동작한다. 해당 방향으로의 마지막 층에 도착하면 엘리베이터는 방향을 전환해 반대 방향으로 이동한다. 이런 유사성 때문에 I/O 스케줄러는 엘리베이터로 불리기도 한다.
5.2. The Linus Elevator
첫 I/O 스케줄러는 Linus Elevator라고 불렸다. 이는 리눅스 커널 2.4 버전의 기본 I/O 스케줄러였다. Linus Elevator는 병합과 정렬 모두를 수행한다. 요청이 큐에 추가되면 다른 대기중인 요청들과 병합될만한 후보가 있는지 확인한다. Linus Elevator 스케줄러는 front 병합과 back 병합을 모두 수행한다. 병합의 종류는 인접한 요청의 위치에 따라 다르다. 새로운 요청이 남아있는 요청을 즉시 진행한다면 이는 front 병합이다. 반대로 새로운 요청이 남아있는 요청을 즉시 선행한다면 이는 back 병합이다. 파일이 배열되는 방법과 I/O 연산의 수행이 일반적인 작업량을 가지기 때문에(파일은 섹터 번호를 증가시킴으로써 배열, 데이터는 앞에서부터 끝으로 읽힌다 등), back 병합이 더 자주 발생한다.
만약 병합이 실패하면 큐에서 집어넣을 곳을 찾는다. 만약 적절한 위치가 없다면 요청은 큐의 끝에 추가된다. 그리고 만약 존재하는 요청이 사전에 정의된 임계치보다 오래되었다면 새 요청은 다른 곳에 추가되어도 되지만 큐의 끝에 추가된다. 이는 디스크에 있는 많은 요청이 무한히 굶는 것을 막는다. 허나 나이를 확인하는 것은 효율적이지 못하다. 주어진 시간동안 요청을 서비스할 수 있는 어떠한 실질적인 시도도 제공하지 않는다. 그저 요청의 삽입-정렬을 적절한 지연 후 중단한다. 이는 응답속도를 향상시키긴 하나 여전히 요청을 굶주릴 수 있다. 최종적으로 Linus Elevator 스케줄러를 요약하자면 다음과 같다.
- 큐에 on-disk 섹터와 인접한 요청이 있다면 존재하는 요청과 새로운 요청을 하나의 요청으로 병합한다.
- 큐의 요청이 충분히 오래되었다면 새로운 요청은 큐의 마지막에 추가되어 오래된 요청이 처리되지 않고 굶주리는 것을 막는다.
- 큐에 적절한 위치가 있다면 새로운 요청을 그곳에 삽입함으로써 큐가 디스크의 물리적 위치를 기준으로 정렬된 상태를 유지하도록 한다.
- 적절한 삽입 위치가 없다면 요청은 큐의 마지막에 삽입된다.
5.3. The Deadline I/O Scheduler
Deadline I/O 스케줄러는 Linus Elevator에 의해 발생하는 굶음을 예방하기 위해 탄생하였다. 탐색을 최소화하기 위해 한 영역에 대한 무거운 I/O 연산은 무한히 요청을 굶주릴 수 있다. 게다가 같은 영역에서의 요청의 흐름은 멀리 떨어진 다른 요청이 절대 처리될 수 없도록 한다. 더 안좋게는, 쓰기 작업이 읽기 작업을 굶주리게 하는 문제도 있다. 쓰기 작업은 보통 커널이 쓰기작업을 할 때가 되면 디스크에 전념한다. 읽기 작업은 꽤나 다른데, 보통 어플리케이션이 읽기 요청을 전달하면 어플리케이션은 요청이 마무리될 때 까지 멈춘다. 그 말은 읽기 작업은 동기적으로 이루어진다. 시스템의 반응이 쓰기 지연시간에 크게 영향을 받지 않을지라도, 읽기 지연시간은 중요하다. 쓰기 지연시간은 어플리케이션 성능에 적은 영향을 미치지만, 어플리케이션은 각각의 읽기 요청이 완료될 때 까지 기다려야한다. 결론적으로 읽기 지연시간이 시스템 성능에 더 중요하다.
많은 파일을 읽는다고 가정해보자. 각각ㄱ의 읽기는 작은 버퍼화된 청크에서 발생한다. 어플리케이션은 이전의 청크(디스크에서 읽기)가 완료되어 어플리케이션에 돌아올 때 동안 다음 청크를 읽기 시작할 수 없다. 설상가상으로 읽기와 쓰기 작업은 inode와 같은 여러 메타데이터를 읽어야한다. 디스크에서 이 블록들을 읽는 것은 I/O를 직렬화 한다. 결과적으로 각각의 읽기 요청이 굶주렸다면, 그런 어플리케이션에 대한 전체적인 지연은 거대하게 커질 수 있다. 읽기 요청의 비동기성과 상호 의존성은 읽기 시스템 성능에 대한 읽기 지연시간을 훨씬 더 강력하게 견뎌낸다. Deadline I/O 스케줄러는 요청의 굶주림과 읽기 굶주림이 최소화 되도록 보장하는 몇가지 특징을 구현한다.
요청의 굶주림을 감소시키려면 전반적인 처리량을 대가로 해야한다. Linus Elevator에서도 이런 타협이 존재했다. 탐색을 최소화 시키는 것이 중요하지만, 무한히 굶어있는 것 역시 좋지않다. Deadline I/O 스케줄러는 전반적인 처리량이 아직 좋다면 굶주림을 제한하기 위해 더 노력을 기울인다.
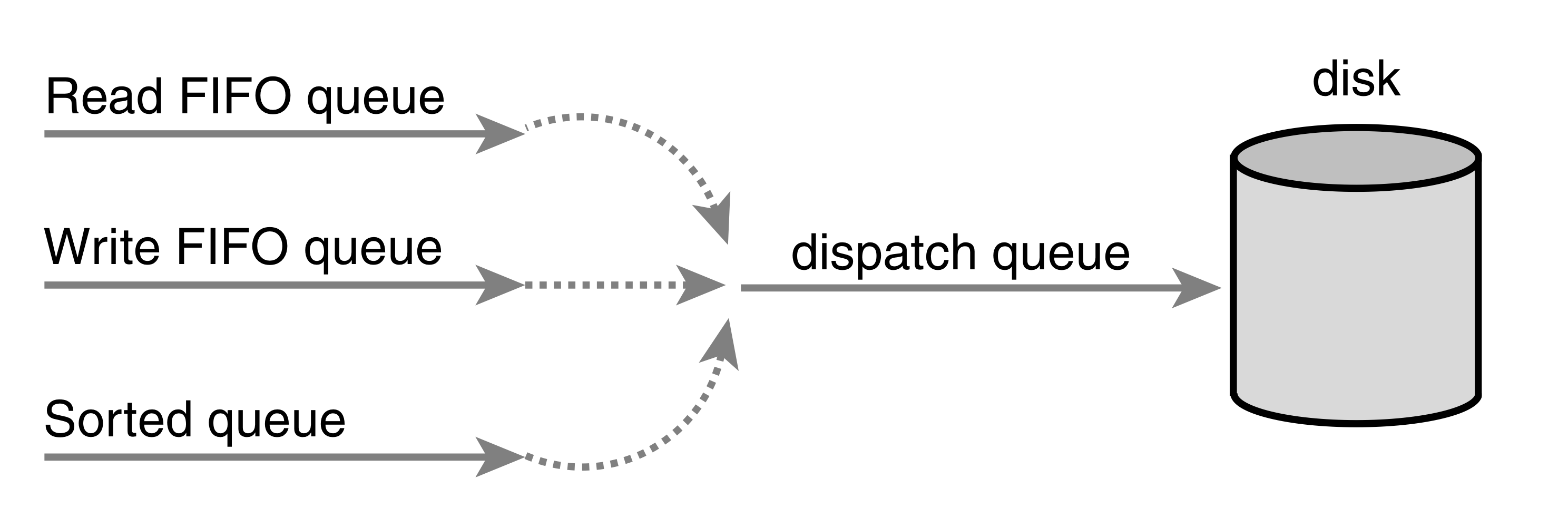
Deadline I/O 스케줄러에서는 각각의 요청이 만료시간과 연관된다. 기본값으로, 읽기 요청의 만료시간은 500밀리초이고, 쓰기 요청의 만료시간은 5초이다.Deadline I/O 스케줄러는 Linus Elevator와 같이 디스크에서의 물리적 위치를 기준으로 대기큐를 정렬한다. 이 큐를 Deadline I/O 스케줄러에서는 sorted queue라고 한다. 새로운 요청이 제출되었을 때, Deadline I/O 스케줄러는 Linus Elevator처럼 병합 및 삽입을 진행한다. Deadline I/O 스케줄러는 요청을 요청의 유형에 따라 읽기 요청은 read FIFO 큐에 정렬되고, 쓰기 요청은 write FIFO 큐에 삽입된다. 결과적으로 새로운 요청은 큐의 마지막에 추가된다. 일반 작업에서 Deadline I/O 스케줄러는 요청을 정렬 큐의 앞에서 뽑아내어 dispatch 큐에 넣는다. Dispatch 큐는 디스크 드라이브로 먹여지고, 이 결과로 최소 탐색이 가능하다.
만약 맨 앞의 요청이 만료되면, Deadline I/O 스케줄러는 FIFO 큐에서의 요청을 처리하기 시작한다. 이런 방법으로 Deadline I/O 스케줄러는 정해진 만료시간 이상으로 남아있도록 하지 않는다.
5.4. The Anticipatory I/O Scheduler
Deadline I/O 스케줄러가 읽기 지연시간을 최소화 하는데 큰 기여를 했지만, 전체적인 처리량(throughput)을 소모함으로써 그 역할을 한다. Anticipatory I/O 스케줄러는 훌륭한 읽기 지연시간 뿐만 아닌 훌륭한 전역 처리량을 목표로 한다.
첫째로 Anticipatory I/O 스케줄러는 Deadline I/O 스케줄러를 기반으로 출발한다. 따라서 전체적으로 다르지는 않다. Anticipatory I/O 스케줄러는 세개의 큐를 구현하고 각각의 요청의 유효기간을 정한다. 주요한 차이점은 anticipation heuristic의 추가이다.
Anticipatory I/O 스케줄러는 다른 디스크 I/O가 진행되는 동안 발생하는 읽기 요청과 관련된 탐색을 최소화하고자한다. 읽기 요청이 발생하면 평소와 같이 유효기간을 설정하고 다루어진다. 그러나 요청이 제출된 후에는 Anticipatory I/O 스케줄러는 즉각적으로 다시 탐색하지 않고 다른 요청을 처리하러 간다. 대신 몇 밀리초간 아무것도 하지 않는다. 그 몇 밀리초간, 어플리케이션이 다른 읽기 요청을 제출할 수 있는 기회가 생긴다. 디스크의 인접한 구역으로 발생된 요청은 즉시 처리된다. 기다리는 기간이 지난 후, Anticipatory I/O 스케줄러는 그만 둔 곳 부터 다시 탐색하며 이전의 요청을 처리한다.
다른 많은 요청이 있음에도 읽기 요청을 처리하면서 앞뒤로 탐색하는 비율을 조금이라도 줄인다면 anticipation에서 소비한 몇 밀리초는 그만한 가치가 있다는 사실을 염두에 두어야한다. 만약 인접한 I/O 요청이 기다리는 기간에 발생한다면, I/O 스케줄러는 탐색의 쌍을 저장할 뿐이다. 더 많은 읽기 요청이 디스크의 같은 구역에서 발생한다면, 여러 탐색들이 예방될 것이다.
물론 기다리는 기간에 아무것도 일어나지 않는다면 그 몇 밀리초는 낭비되는 것이므로, Anticipatory I/O 스케줄러의 이점을 최대한 끌어올리기 위해 어플리케이션과 파일시스템의 행동을 정확하게 예측하는 것이 관건이다. 이는 통계와 연관된 휴리스틱으로 해결할 수 있다. Anticipatory I/O 스케줄러는 프로세스별로 블록 I/O의 습관을 추적한다. 충분히 높은 예측 성공률을 토대로, Anticipatory I/O 스케줄러는 시스템 응답이 필요로 하는 주의는 유지한 채로 읽기 요청의 처리를 위한 탐색의 패널티 크게 줄일 수 있었다. 이로써 읽기 지연시간을 최소화 할 수 있을 뿐더러, 탐색의 수와 기간도 최소화할 수 있었다. 결론적으로 낮은 시스템 지연시간, 높은 시스템 처리량을 달성하였다.
Anticipatory I/O 스케줄러는 서버에는 이상적이였으나, 탐색을 선호하는 데이터베이스를 포함하는 평범하지 않은 특정한 경우에는 느리게 동작하였다.
5.5. The Complete Fair Queuing I/O Scheduler
Complete Fair Queuing(CFQ) I/O 스케줄러는 특정한 작업부하를 위해 디자인된 스케줄러이나, 실제로는 여러 작업부하 환경에서 좋은 성능을 보여준다. 이는 이전에 다루어진 스케줄러와 기본적으로 다르다.
CFQ I/O 스케줄러는 들어오는 I/O 요청을 프로세스를 바탕으로 특정한 큐에 할당한다. 예를 들어 프로세스 foo에서의 I/O 요청은 foo의 큐에 할당되고, 프로세스 bar에서의 I/O 요청은 bar의 큐에 할당된다. 각각의 큐에서 요청은 인접한 요청과 합쳐지고 삽입 정렬된다. 큐는 섹터별로 정렬된 채로 유지된다. CFQ I/O 스케줄러의 다른 점은 각각의 프로세스가 I/O를 제출할 하나의 큐가 있다는 것이다.
CFQ I/O 스케줄러는 그러고 나서 큐를 라운드 로빈으로 처리하고, 각각의 큐에서 요청을 뽑아낸다. 이는 프로세스별 단계에서 각각의 프로세스가 균등한 디스크의 대역폭 슬라이스를 받게 함으로써 공정함을 제공한다. 의도한 작업은 멀티미디어였지만, 실제로는 CFQ I/O 스케줄러는 다양한 경우에도 잘 동작한다.
CFQ I/O 스케줄러는 데스크탑 작업에 권장된다. CFQ I/O 스케줄러는 현재 리눅스의 기본 I/O 스케줄러이다.
5.6. The Noop I/O Scheduler
Noop I/O 스케줄러는 정렬을 하지도 않고, 탐색을 막는 어떠한 것도 하지 않는다. 따라서 이전의 여러 스케줄러가 요청 지연시간을 줄이기 위해 이용한 알고리즘을 구현할 필요도 없다.
Noop I/O 스케줄러는 병합을 수행한다. 새로운 요청이 큐에 들어오면, 인접한 요청과 합친다. 이것 말고는 Noop I/O 스케줄러는 진짜 아무것도 안하고 큐를 FIFO에 가까운 순서로 유지한다.
Noop I/O 스케줄러는 truly random-access인 블록 기기(플래시 메모리 카드)를 의도하였다. 만약 블록 기기가 탐색과 연관된 오버헤드가 없다면 새로운 요청에 대한 삽입 정렬이 필요하지 않다.
5.7. I/O Scheduler Selection
부트타임 옵션으로 elevator=foo를 커널 커맨드 라인에 작성함으로써 I/O 스케줄러를 변경할 수 있다. 기본값은 CFQ이다. foo에 들어갈 수 있는 것은 다음과 같다.
| Parameter | I/O Scheduler |
|---|---|
| as | Anticipatory |
| cfq | Complete Fair Queuing |
| deadline | Deadline |
| noop | Noop |
References
- Linux Kernel Development (3rd Edition) by Robert Love
