본 포스팅의 내용은 Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani, Jonathan Taylor (2023), 「An Introduction to Statistical Learning with Applications in Python」, Springer 를 참고하였습니다.
재표집법(resampling method)은 훈련 세트에서 반복적으로 표본을 추출한다.
추출한 표본에 대해 적합을 반복하면서 적합된 모형에 대한 추가 정보를 구한다.
예를 들어 선형회귀 적합에 대한 변동을 추정해보기 위해, 여러 부류의 표본을 추출하고, 추출한 부류에 대해 선형회귀를 각각 적합한 후, 이러한 적합들이 얼마나 다른지 확인한다.
이러한 접근법은 한 번의 적합으로는 이용할 수 없는 정보를 구하는데 도움이 된다.
같은 방식을 여러 번 적합하는 과정에서 계산량이 많다는 단점도 있지만, 현대 컴퓨터 성능에서는 크게 문제가 될 정도는 아니다.
이번 장에서는 가장 일반적으로 사용되는 두 가지 방법을 알아볼 것이다.
- 교차검증(cross-validation)
- 부트스트랩(bootstrap)
교차검증은 통계적 학습 방법에 관한 테스트 오류를 추정해 성능 평가(모형평가, model assessment) 및 적절한 유연성 수준 선택(모형선택 model selection) 등이 가능하다.
부트스트랩은 여러 상황 중 모수 추정값의 정확도나 통계적 학습 방법의 정확도를 제공하는데 사용된다.
5.1. 교차검증
먼저 테스트 오류율(test error rate)과 훈련 오류율(training error rate)를 구분할 필요가 있다.
테스트 오류는 통계적 방법을 사용해 새로운 관측에 대한 반응을 예측한 결과에 대한 오류의 평균이라고 할 수 있다. 새로운 관측이란 훈련에 사용되지 않은 관측값을 말한다.
테스트 오류를 줄이는 것이 좋은 통계적 학습 방법 선택의 정당성을 가질 수 있다.
실제로는 테스트 세트가 확보되기 어렵고, 훈련 오류율과 테스트 오류율이 매우 차이가 나는 경우가 있다. 테스트 오류율을 과소추정할 경우 그렇다.
5.1.1. 검증 세트 접근법
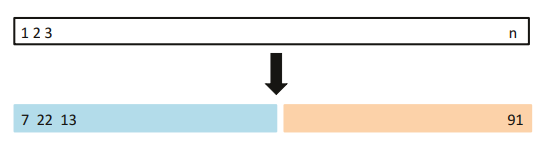
[그림 5.1] 검증 세트 접근법의 개요도
훈련 데이터를 통해 테스트 오류율을 추정하는 방법 중 하나는 검증 세트 접근법(Validation set approach)이다.
이는 관측값을 훈련 세트(training set)와 검증 세트(validation set) 또는 보류 세트(hold-out set)로 나눈다.
훈련 세트에서는 모형을 접근하고 적합된 모형은 검증 세트에 있는 관측의 반응을 예측하는데 사용된다.
검증세트 오류율은 테스트 오류율의 추정값을 제공한다.
(양적 반응일 때는 MSE를 사용한다.)
Auto 데이터 세트로 예를 들었을 때,
연비(mpg)와 마력(horsepower)사이에 비선형 관계가 있고, 를 사용해 mpg를 사용할 때, 선형 항만 사용하는 경우보다 더 좋은 결과인 데이터 세트이다.
여기서 차항을 높일수록 정확도가 높을까?
3장에서는 직접 고차항으로 갈 때의 p-value값을 확인했다.
이 방법 이외에도 검증하는 방법이 사용될 수 있다.
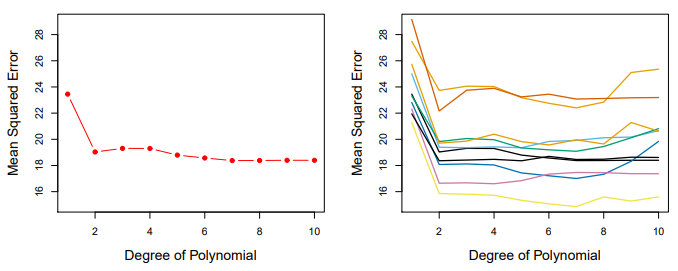
[그림 5.2] 검증 세트 접근법을 사용한 테스트 오류 추정
392개의 관측값을 반으로 나누어 훈련 세트, 검증 세트로 나눈다.
훈련 모형에 회귀모형을 적합하고 검증 표본에서 그 성능을 평가한 결과로 검증 세트 오류율이 나온다.
이 경우에는 MSE를 검증 세트 오차의 측도로 이용했다.
왼쪽 그림을 통해 선형 모형에서 이차항의 적합으로 갈 때는 MSE가 상당히 줄어들지만 삼차 적합으로 가면 살짝 크다.
이는 회귀에 삼차항은 좋은 예측이 나오지 않음을 의미한다.
오른쪽 그림은 앞의 검증 방법을 다시 무작위로 데이터 세트를 두 부류로 나누었을 때의 검증 세트의 MSE 변동을 나타낸 것이다.
10개의 곡선 모두 값은 다르지만 선형에서 이차 적합으로 갈 때 큰 폭으로 MSE가 작아진다는 점, 차항이 증가하더라고 MSE가 크게 달라지지 않는다는 점은 같다.
따라서 이 접근법은 곡선이 제각각이라서 어떠한 모형이 가장 작은 지 알 수 없고, 경향성을 파악하는데 도움이 된다.
-
어느 관측이 훈련 세트에 포함되고, 검증 세트에 포함되는지에 따라 테스트 오류율의 검증 추정값은 매우 큰 폭으로 변동될 수 있다.
-
모형을 적합할 때 훈련 세트에만 적합을 하기 때문에 관측개수가 적어지는 단점이 있다.
즉, 검증 세트 오류율이 전체 데이터 세트에 대해 적합한 모형의 테스트 오류율을 과대추정할 수 있다.5.1.2. LOOCV
하나 빼고 교차검증(LOOCV, leave-one-out cross validation)은 검증 세트 접근법의 단점을 해결하기 위한 접근법이다.
먼저 검증 세트 접근법과 마찬가지로 관측값을 두 부류로 나눈다.
여기서 차이점은 훈련세트와 마찬가지로, 검증 세트 또한 훈련에 사용할 것이다.
단, 한 개의 관측치 을 제외하고 말이다.
을 사용해 을 예측한다.
이는 테스트 오차에 대해 근사적으로 비편향 추정값을 제공한다.
하지만 하나만 할 경우 변동이 심하기 때문에 여러 번 반복한다.
이러한 접근법을 n번 반복하면 n개의 제곱오차 가 만들어지고, 이에 대한 평균이 테스트 MSE에 대한 LOOCV 추정값이다.
다음은 이 방법의 개요도이다.
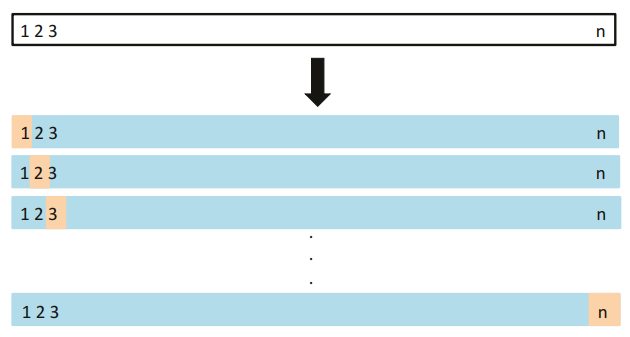
[그림 5.3] LOOCV 접근법의 개요도
LOOCV는 검증 세트 접근법에 비해 장점이 있다.
첫째로는 편향이 훨씬 적다.
LOOCV는 관측치 n개중 n-1개의 관측을 포함해 통계적학습을 반복한다.
검증세트는 위의 절반 정도이므로 과대추정의 문제가 훨씬 적어진다.
둘째로는 테스트 MSE의 변동성이 매우 적다.
검증 세트 접근법은 무작위로 추출된 표본으로 인해 테스트 MSE의 변동성이 매우 컸다.
하지만 LOOCV는 훈련 세트가 전체 데이터셋과 동일하기 때문에 여러 번 수행하더라도 테스트 세트의 MSE는 거의 비슷할 것이다.
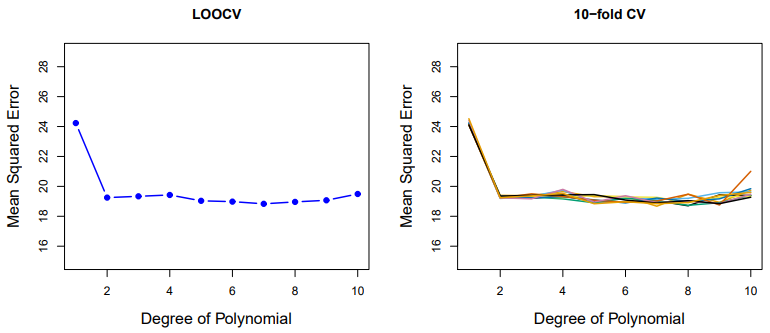
[그림 5.2] LOOCV를 사용한 테스트 오류 추정
LOOCV의 단점은 모형을 n번 적합해야하므로 구현에 비용이 많이 들 수 있다.
최소제곱 선형 회귀 또는 다항회귀의 경우에는 LOOCV의 비용을 단일 모형 적합 비용과 동일하게 만드는 방법이 있다.
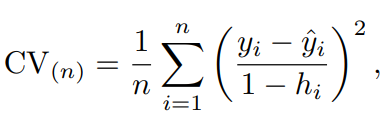
는 i번 째 최소제곱 적합에서의 적합값이고, 는 지렛값이다.
MSE와는 i번째의 잔차를 만큼 나눈 것으로 다르다.
이므로 지렛점이 높아야 해당 등식을 성립시키기에 적합할 정도로 팽창한다.
(다시 공부하기)
LOOCV는 매우 일반적인 방법으로 어떤 종류의 모형에서도 사용가능하다.
하지만 해당 공식은 일반적으로 성립하지 않을 수 있다.
이럴 경우는 모형을 n번 적합해야한다.
5.1.3. 겹 교차검증
겹 교차검증(k-fold cross-validation)은 LOOCV의 대안의 방법이다.
LOOCV의 단점인 많은 계산으로 인한 비용을 개선한 것이다.
다음은 겹 교차검증의 개요도이다.
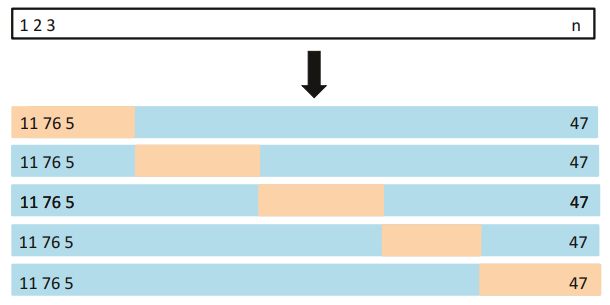
[그림 5.5] 겹 교차검증의 개요도
LOOCV와 마찬가지로 훈련세트와 검증 세트를 나눈 후 검증세트 중 일부분을 빼고 다시 훈련세트에 넣는다.
여기서 큰 차이점은 관측치를 여러 부류로 뺀다. 그 중 첫 번째 부류만 검증 세트로 하고, k-1개의 나머지 부류는 다시 훈련세트에 포함시켜 적합한다.
이를 k번 반복하면 모든 부류에 대한 검증세트를 마련한 가 나올 것이다.
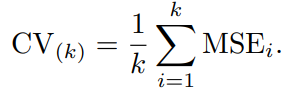
LOOCV는 으로 설정한 겹 교차 검증이라고 할 수 있다.
일반적으로 5 또는 10을 사용한다.
이렇게 했을 때 가장 큰 장점은 계산상의 장점이라고 할 수 있다.
모형 적합 횟수를 n번에서 5, 10번으로 획기적으로 줄이기 때문이다.
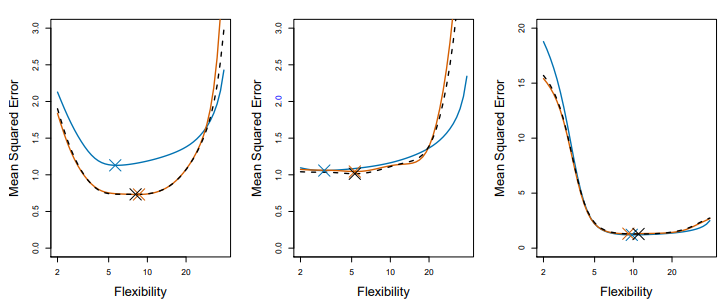
[그림 5.6] 여러 데이터의 관측치의 형태의 따른 시뮬레이션 데이터 세트의 테스트 MSE 참값과 추정값.
현실 데이터를 검토할 때는 테스트 MSE의 참값을 모르기 때문에 교차검증 추정값이 얼마나 참값에 가까운지 확인하기 힘들다.
그러나 시뮬레이션 데이터를 검토한다면 테스트 MSE의 참값을 계산할 수 있어 교차검증 결과의 정확도를 평가할 수 있다.
위 그림의 파란색 실선이 참값이고, 검은색 파선과 주황색 실선이 각각 LOOCV 추정값과 10-겹 교차검증 추정값이다.
세 개의 그래프 모두 비슷한 곡선을 가진다고 할 수 있다.
오른쪽 그림은 참값과 테스트 MSE가 어느 유연성에서든 비슷하다.
가운데 그림에서는 유연성이 낮을 때는 비슷하지만, 유연성이 커짐에 따라 차이가 나는데, 테스트 MSE를 과대추정한다.
왼쪽 그림은 유연성이 높을 때는 비슷하지만 유연성이 낮아짐에 따라 테스트 MSE를 과소추정한다.
교차검증의 목표는 훈련 데이터셋을 통해 적합한 회귀모형이 학습에 사용되지 않는 데이터에서 얼마나 잘 수행되는지에 대한 것이다.
이 경우에는 MSE의 최솟값을 확인하는 것이 목표이기 때문에 어느 지점의 유연성을 가질 때
즉, (어떠한 통계적 모형 방법을 썼을 때 / 한 통계적 방법에서 여러 유연성을 가질 때)가장 MSE가 낮은지 확인하면 된다.
5.1.4. 겹 교차검증의 편향-분산 트레이드 오프
앞에서 언급했듯이, 겹 교차검증은 LOOCV 접근법보다 계산상의 축소에서 큰 장점을 가지고 있다.
하지만 이 장점 이외에도 LOOCV보다 더 정확한 추정값을 내는 경우도 많다는 것이 있다.
앞의 검증 세트 접근법은 전체 데이터셋의 절반만을 학습에 사용하기 때문에 테스트 오류율을 과대추정할 수 있다.
이 논리를 이용해 LOOCV가 근사적으로 테스트 오차의 비편향추정값을 제공할 수 있음을 알 수 있다.
(거의 전체 데이터 세트에 대해 적합을 진행하기 때문에)
겹 교차검증은 이 둘의 중간 정도 될 것이다.
결론적으로는 훈련 세트가 전체 데이터 세트에 가까울수록 편향이 줄어든다는 것이다.
하지만 편향의 감소 이외에도 분산이라는 문제를 확인해볼 필요가 있다.
분산은 편향과는 반대로 LOOCV가 겹 교차검증보다 분산이 더 크다.
왜그럴까? 상관관계에 대한 관점으로 보자.
LOOCV같은 경우에는 n회 훈련 데이터 세트에 대해 거의 동일하다. 동일하다면 훈련 세트가 서로 비슷해 높은 상관관계를 보인다. 따라서 과적합될 가능성이 커 테스트 데이터를 예측할 때 분산이 클 수 있다.
- 편향(Bias): 모델이 정답에서 얼마나 벗어나 있는가?
- 분산(Variance): 모델이 관측치에 대해 얼마나 민감한가?
따라서 분산과 편향의 균형을 맞춘 알맞은 모델을 선택하는 것이 중요하다.
5.1.5. 분류 문제에서의 교차검증
지금까지는 반응변수 가 양적 변수인 회귀분석 상황에서의 교차검증을 다루었다.
(MSE를 사용한 테스트 오류 추정)
반응 변수가 질적인 경우는 어떨까?
분류상황에서도 마찬가지로 적용하지만, MSE가 아닌 다른 척도를 사용해서 오류율을 추정해야한다.
LOOCV 오류율은 다음과 같은 형태이다.

이고, 교차검증 오류율과 검증 세트 오류율도 다음과 같은 식이다.
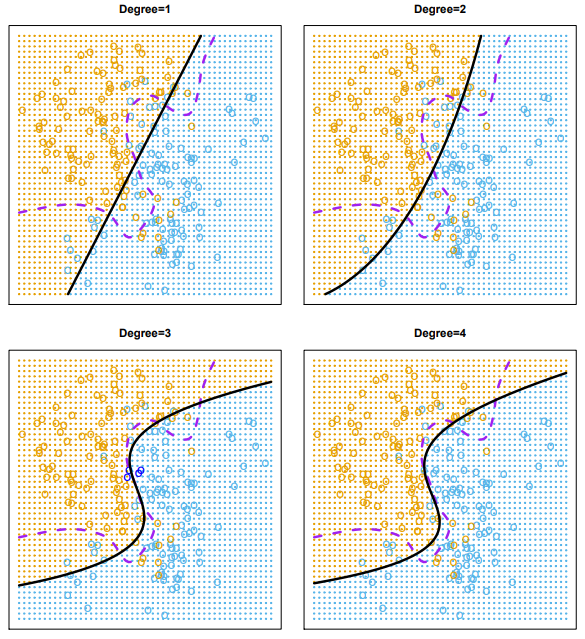
[그림 5.7] 2차원 분류 데이터의 로지스틱 회귀 적합 결과. 1차,2차,3차,4차 로지스틱 회귀에서 추정된 결정경계.
보라색 파선은 오류율이 가장 낮은 것으로 알려진 베이즈 결정경계이다.
위 데이터는 시뮬레이션 데이터이므로 참 테스트 오류율을 계산할 수 있다.
베이즈 오류율은 0.133이고, 4개의 그림의 테스트 오류율은 각각 0.201, 0.197, 0.160, 0.162으로 큰 차이가 난다.
선형 로지스틱 회귀가 이 상황에서는 베이즈 결정 경계를 모형화하기에 유연성이 충분하지 않다.
따라서 이 경우는 예측변수의 차항을 높여 다항 로지스틱함수를 활용한다.
차항을 높였더니, 0.197로 줄어들었고, 3차 로지스틱 회귀모형 적합 결과 0.160으로 줄어들었다.
실제 현실 데이터에서는 베이즈 결정경계와 테스트 오류율은 알 수 없다.
그렇다면 어떠한 모형을 선택을 해아할까?
교차검증으로 가능하다.
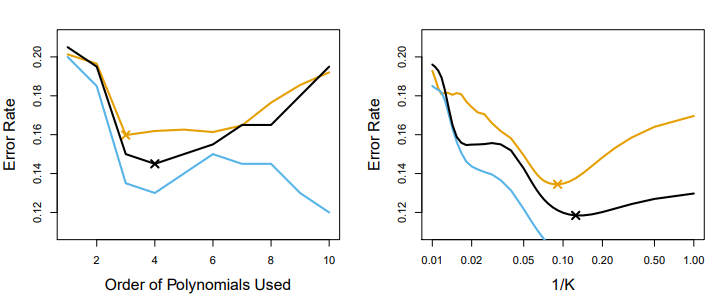
[그림 5.8] 테스트 오류(갈색), 훈련 오류(파란색), 10-겹 교차검증 오류(검정색)
왼쪽 데이터에서 훈련 데이터(파란색 실선)은 예상대로 유연성이 증가함에 따라 오류율이 감소하는 경향을 보인다.
테스트 오류율(갈색 실선)은 특징적인 U-자형을 그리며 유연성이 올라갈수록 오류율이 커진다.
교차검증 방법인 10-겹 교차검증은 약간 과소추정하는 느낌은 있지만 테스트 오류율을 근사적으로 잘 설명한다.
여기서는 4차항일 때 가장 최소인 오류율을 갖는다.(실제로는 3차)
오른쪽 그림에서는 KNN 접근법으로 분류해 얻은 세 개의 곡선을 K 값의 함수로 제시했다.
위의 경우에도 세 개의 곡선 모두 왼쪽 그림과 비슷한 경향을 가진다.
5.2. 부트스트랩
부트스트랩(bootstrap)은 주어진 추정량 또는 통계적 학습 방법의 불확실성을 수량화 해주는 통계적 도구이다.
예를 들어 선형회귀 적합에서 계수()의 표준오차를 추정하는데 사용할 수 있다.
(R 같은 통계 소프트웨어에서 자동으로 출력해주기도 한다.)
학습을 위해 단순한 모형인 가장 좋은 투자 배분을 결정하는 토이 예제로 부트스트랩을 설명한다.
금융자산인 X,Y 금융자산에 고정된 총금액을 분배해서 투자한다고 하자.
X에 , Y에 비율만큼 투자하고 투자의 총위험, 분산을 최소화하는 를 선택하려고 한다.
(
위험을 최소화하는 값은 다음과 같다.
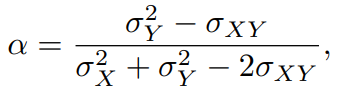
현실에서는 위의 값(X의 분산, Y의 분산, XY의 공분산)의 수량을 알 수 없으므로 추정값을 계산해야한다.
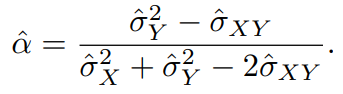
다음은 이 접근법으로 시뮬레이션 데이터 세트에서 를 추정하는 과정을 보여준다.
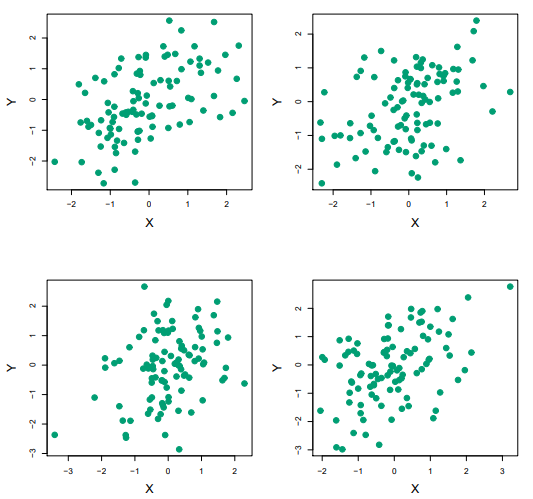
[그림 5.9] 투자 수익 X,Y에 대해 100번의 시뮬레이션 결과.
투자 X,Y에 대한 100쌍의 수익을 시뮬레이션 한 결과이다.
의 추정값은 각각 0.576, 0.532, 0.657, 0.651이 나왔다.
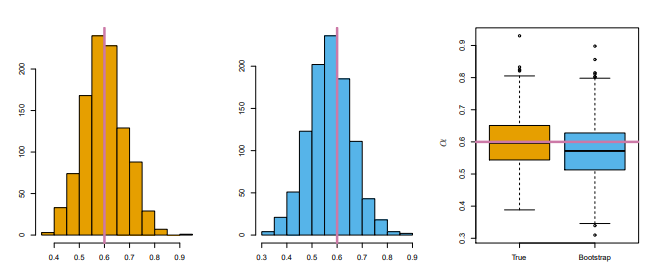
[그림 5.10] 추정값에 관련한 시뮬레이션
왼쪽 그림은 참 모집단에서 1,000개의 시뮬레이션 데이터 세트를 생성해 구한 것이다.
가운데 그림은 단일 데이터 세트에서 1,000개의 부트스트랩 표본을 생성해 구했다.
오른쪽은 다음 두 세뮬레이션의 추정값을 상자그림으로 나타냈다.
(분홍색 실선은 의 참 값이다.)
를 구하는 식을 사용해 를 추정하는 과정을 1,000번 반복하였다.
여기서 모수를 로 설정하였고, 인 것을 알고 있다.
에 대한 전체 1,000개의 추정값의 평균은 다음과 같다.
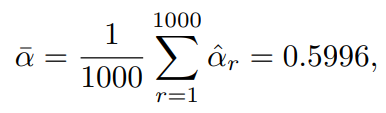
이를 이용한 추정값들의 표준편차는 다음과 같다.
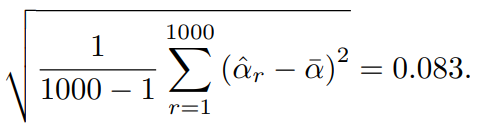
의 정확도로 이라는 것은 와 추정값의 평균이 근사적으로 0.083정도 차이가 난다는 것이므로 좋은 성능이다.
하지만 현실 데이터는 모집단에서 새로운 표본을 생성할 수 없으므로 를 앞에서처럼 추정할 수 없다.
부트스트랩 접근법은 새로운 표본 세트를 얻는 과정을 컴퓨터를 사용해 모방하게 해줌으로써 의 변동성을 추정할 수 있다.
(모집단에서 반복적으로 독립적인 데이터셋을 얻는 것이 아닌, 원래 데이터 세트에서 관측값을 반복적으로 표집해 서로 다른 데이터 세트를 얻는다.)
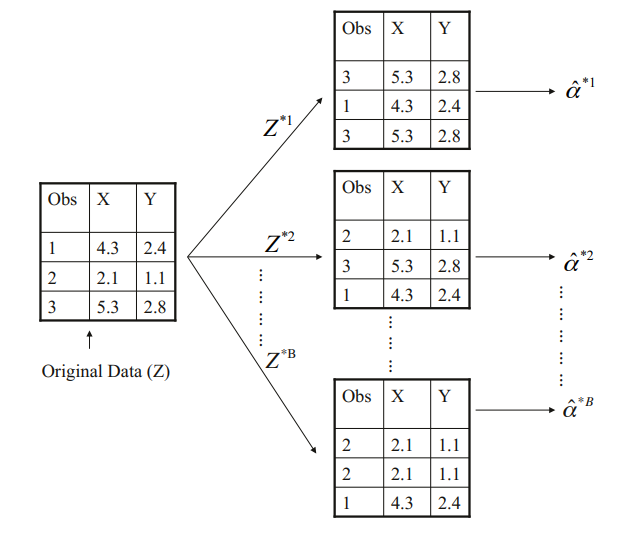
[그림 5.11] n=3개의 관측값을 포함하는 소규모 표본에서 부트스트랩 접근법을 도표로 설명한 그림.
에서 새로운 데이터인 부트스트랩 데이터를 생성한다.
표집은 복원추출로 진행한다.
를 통해 를 추정하는 을 만들 수 있다.
해당 절차는 B번 반복하여 에 대한 , , 를 생성할 수 있다.
다음 공식으로 부트스트랩 추정값의 표준오차를 계산 가능하다.
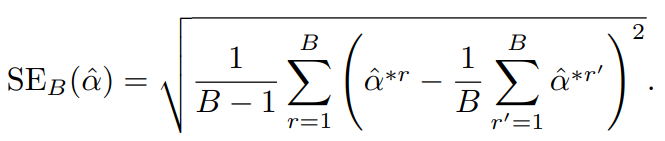
이 값을 통해 원본 데이터 세트에서 추정된 의 표준오차 추정값을 쓸 수 있다.
그림 [5.10]을 통해 부트스트랩 접근법의 예시를 확인 가능하다.
이 히스토그램은 왼쪽의 이상적인 히스토그램과 근접하다는 것을 확인할 수 있다.
(부트스트랩 접근법으로 구한 으로 앞선 표준오차와 상당히 비슷하다.)
또한 오른쪽 그림에서 볼 수 있듯이, 두 상자그림의 산포(spread)가 유사해 부트스트랩 접근법을 사용해 에 연관된 변동을 효과적으로 추정할 수 있다는 것을 알 수 있다.
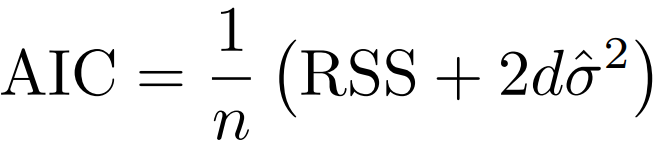
간단하게 하기 위해 상수 값은 생략한 결과이다.
BIC는 베이지안 관점에서 유도되었지만 AIC와 유사하다.

횐님^^ 좋은 글입니다..^^ 조만간 쐬주한잔 하시죠~^^