먼저 논문에 있는 TimesNet의 처리 과정에 대한 그림을 통해 이해하는 활동을 진행했다.
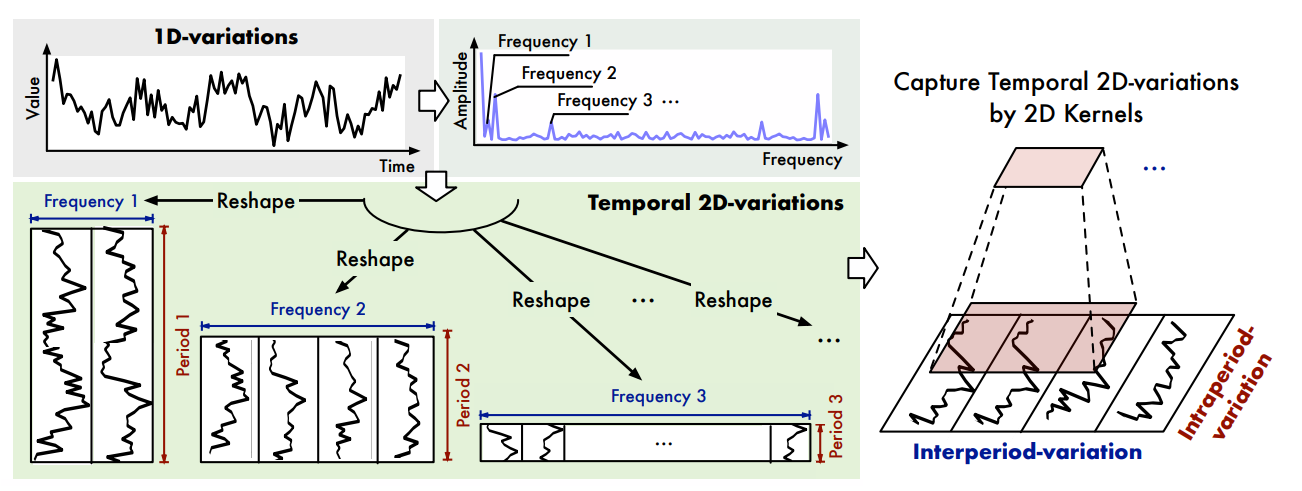
다음은 TimesNet이 2차원으로 표현되는 과정에 대한 그림이다.
- 1차원 단일 변수(시간에 대한 값)에서 푸리에 변환(FFT)을 통해 가장 강한 진폭을 가진(뚜렷한 주기성을 갖는)를 주파수 k개 찾는다.
- 찾은 k개를 2차원으로 분리(inter-period, intra-period)해 CNN에 입력한다.
- 2DConv(2차원 합성곱)을 이용하여 시계열 2차원 패턴을 확인한다.
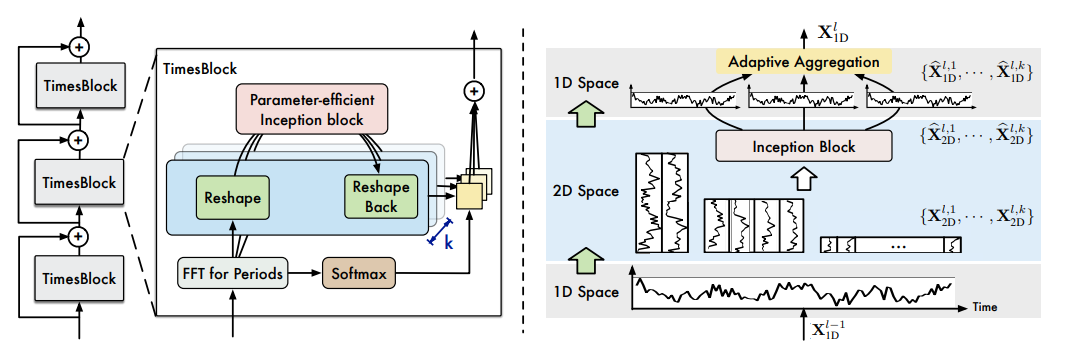
우선 전체적인 TimesNet의 architecture는 다음과 같다.
- 앞의 과정을 TimesBlock에서 반복 수행하게 된다.
- 1차원인 시계열 데이터를 2차원의 k개의 주파수로 표현한다. 이후 다시 1차원인 제각각의 주기 패턴을 가진 시계열 표현으로 분리한다.
- 분리된 서로 다른 주기의 1차원 시계열 표현에서 softmax 가중합으로 주기성에 대한 두드러진 표현을 담은 최종 시계열 표현을 출력해 다음 TimesBlock 입력값에 전달한다.
다음은 TimesNet github의 TimesNet.py 코드를 통해 알고리즘을 확인해보는 활동을 해보았다.
1. 라이브러리 호출
import torch # 딥러닝 사용 위한 라이브러리 호출
import torch.nn as nn # 신경망 구성용 클래스
import torch.nn.functional as F # 활성화 레이어 및 함수 라이브러리
import torch.fft # 푸리에 변환(FFT) 기능 제공
from layers.Embed import DataEmbedding # 수치 데이터 및 시간 정보를 고차원 임베팅 벡터로 변환
from layers.Conv_Blocks import Inception_Block_V1 # 다양한 커널 사이즈로 차원에 대한 합성곱을 수행하는 인셉션 스타일 블록 라이브러리2. 푸리에 변환(FFT) 함수
def FFT_for_Period(x, k=2):
# [B, T, C]
xf = torch.fft.rfft(x, dim=1) #T를 기준으로 푸리에 변환 수행
# find period by amplitudes
frequency_list = abs(xf).mean(0).mean(-1) #진폭값 계산, B값, C값의 평균)
frequency_list[0] = 0
_, top_list = torch.topk(frequency_list, k) # 진폭이 가장 큰 상위 2개의 주파수 인덱스 추출
top_list = top_list.detach().cpu().numpy()
period = x.shape[1] // top_list # 주기 계산
return period, abs(xf).mean(-1)[:, top_list]
다음은 입력 시계열 데이터에서 주기를 추출하는 함수 부분이다.
TimesNet에서는 시계열 데이터를 강한 주파수 k개를 2차원(inter-period, intra-period)으로 확장해 표현하고 있다.
입력값 x: 시계열 입력 텐서, shape
B: 배치 크기, T: 시계열 크기, C(N): 특성 차원(변수)
입력값 k: 추출할 주기의 개수
반환값: 상위 k(2)개의 주기, 각 주기의 진폭 평균값
3. Timeblock 클래스
class TimesBlock(nn.Module): def __init__(self, configs):
super(TimesBlock, self).__init__()
self.seq_len = configs.seq_len
self.pred_len = configs.pred_len
self.k = configs.top_k
# parameter-efficient design
self.conv = nn.Sequential(
Inception_Block_V1(configs.d_model, configs.d_ff,
num_kernels=configs.num_kernels),
nn.GELU(),
Inception_Block_V1(configs.d_ff, configs.d_model,
num_kernels=configs.num_kernels)
)-
시계열 길이, 예측 길이, 주기 개수 저장
-
Inception_Block_V1 두 개를 이어 붙인다.
(첫 번째 블록은 d_model을 d_ff로 확장한다.
두 번째 블록은 d_ff에서 d_model로 축소한다.)
GELU() 활성화함수를 통해 비선형성을 부여한다.
def forward(self, x):
B, T, N = x.size()
period_list, period_weight = FFT_for_Period(x, self.k)
res = []
for i in range(self.k):
period = period_list[i]
# padding
if (self.seq_len + self.pred_len) % period != 0:
length = (
((self.seq_len + self.pred_len) // period) + 1) * period
padding = torch.zeros([x.shape[0], (length - (self.seq_len + self.pred_len)), x.shape[2]]).to(x.device)
out = torch.cat([x, padding], dim=1)
else:
length = (self.seq_len + self.pred_len)
out = x
# reshape
out = out.reshape(B, length // period, period,
N).permute(0, 3, 1, 2).contiguous()
# 2D conv: from 1d Variation to 2d Variation
out = self.conv(out)
# reshape back
out = out.permute(0, 2, 3, 1).reshape(B, -1, N)
res.append(out[:, :(self.seq_len + self.pred_len), :])-
앞의 FFT_for_Period 함수를 통해 입력받은 B,T,C에 대한 푸리에 변환을 진행한다.
-
주기별로 2D로 변형하며, 합성곱을 진행한다.
(CNN 처리를 위한 구조를 위해 변형) -
2D Convolution 진행 이후, 복원한 다음 다시 1차원으로 변경
res = torch.stack(res, dim=-1)
# adaptive aggregation
period_weight = F.softmax(period_weight, dim=1)
period_weight = period_weight.unsqueeze(
1).unsqueeze(1).repeat(1, T, N, 1)
res = torch.sum(res * period_weight, -1)
# residual connection
res = res + x
return res-
2개 주기에 대한 결과를 softmax를 통해 가중치 기반으로 통합한다.
-
원본 값 x와 출력 값 res를 더해 최종 residual connection을 적용한다.(기울기 소실 문제 해결)
4. 모델 클래스(forecast)
해당 논문에서는 총 5개 부문
(단기, 장기 예측 / 결측치 보간 / 분류 / 이상치 탐지)
에 대한 분석을 진행해 5가지 모델에 대한 알고리즘을 표현했다.
class Model(nn.Module):
"""
Paper link: https://openreview.net/pdf?id=ju_Uqw384Oq
"""
def __init__(self, configs):
super(Model, self).__init__()
self.configs = configs
self.task_name = configs.task_name
self.seq_len = configs.seq_len
self.label_len = configs.label_len
self.pred_len = configs.pred_len태스크 이름, 입력 길이, 예측 길이를 저장한다.
앞의 forward() 함수에 필요한 정보를 받는 코드.
self.model = nn.ModuleList([TimesBlock(configs)
for _ in range(configs.e_layers)])
self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
self.layer = configs.e_layers
self.layer_norm = nn.LayerNorm(configs.d_model)-
TimesBlock을 여러(configs.e_layers)개 쌓는 구조이다.
-
입력 시계열과 시간정보를 d_model 차원으로 임베딩한다.
-
각 TimesBlock 출력에 적용할 정규화 레이어 형성
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
self.predict_linear = nn.Linear(
self.seq_len, self.pred_len + self.seq_len)
self.projection = nn.Linear(
configs.d_model, configs.c_out, bias=True)
if self.task_name == 'imputation' or self.task_name == 'anomaly_detection':
self.projection = nn.Linear(
configs.d_model, configs.c_out, bias=True)
if self.task_name == 'classification':
self.act = F.gelu
self.dropout = nn.Dropout(configs.dropout)
self.projection = nn.Linear(
configs.d_model * configs.seq_len, configs.num_class)각 test_name에 따라서 projection layer를 설정해준다.
분석 방법별로 원하는 출력형태가 다르기 때문에 다르게 설정된다.
forecasting을 중점적으로 보겠다.
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
self.predict_linear = nn.Linear(
self.seq_len, self.pred_len + self.seq_len)
self.projection = nn.Linear(
configs.d_model, configs.c_out, bias=True)시계열의 시간 축을 늘리는 역할을 하는 layer이다.
(self.pred_len + self.seq_len)
decoder input 없이 예측 구간까지 포함된 시계열을 출력하게 한다.
- 내부 차원(d_model)을 다시 사용자가 원하는 차원으로 줄인다.
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# Normalization from Non-stationary Transformer
means = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc.sub(means)
stdev = torch.sqrt(
torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5)
x_enc = x_enc.div(stdev)평균 제거 및 표준편차로 나누는 기능(Normalization)
# embedding
enc_out = self.enc_embedding(x_enc, x_mark_enc) # [B,T,C]
enc_out = self.predict_linear(enc_out.permute(0, 2, 1)).permute(
0, 2, 1) # align temporal dimension
# TimesNet
for i in range(self.layer):
enc_out = self.layer_norm(self.model[i](enc_out))
# project back
dec_out = self.projection(enc_out)-
x_enc(시계열 값)와 x_mark_enc(시간 인코딩 정보)를 임베딩해 새로운 d_model 차원의 고차원 표현으로 변환해준다.
또한 시간 축 확장을 진행한다.(앞 코드 참고) -
TimesBlock함수를 반복 적용하며 시계열 패턴을 추출한다.
여기서 각 block별로 정규화 layer을 진행하여 안전성을 확보한다. -
d_model을 우리가 원하는 차원으로 변환하여 출력 후 저장한다.
# De-Normalization from Non-stationary Transformer
dec_out = dec_out.mul(
(stdev[:, 0, :].unsqueeze(1).repeat(
1, self.pred_len + self.seq_len, 1)))
dec_out = dec_out.add(
(means[:, 0, :].unsqueeze(1).repeat(
1, self.pred_len + self.seq_len, 1)))
return dec_out정규화 복원 작업을 진행한다.(Normalization 이전 값)
정리
다음과 같은 단계로 TimesNet 모델이 작동하고 있음을 알 수 있었다.
- 입력값 (B,T,C)정규화 진행(B: 배치 크기, T: 시계열 크기, C(N): 특성 차원(변수))
- 임베딩 진행(B, T, d_model)
- 시간 확장(예측 시계열까지)
- TimesBlock 반복 호출(2D conv)
- 출력 차원을 최종 출력 차원으로 변환
- 역정규화
