[Beautiful Soup 기초]
- install
- conda install -c anaconda beatifulsoup4
- pip install beautifulsoup4
- beautiful soup 불러오기 & html 파일 열기
from bs4 import BeautifulSoup
page = open('../data/03. zerobase.html', 'r').read()
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify()) # prettify는 들여쓰기 기능! 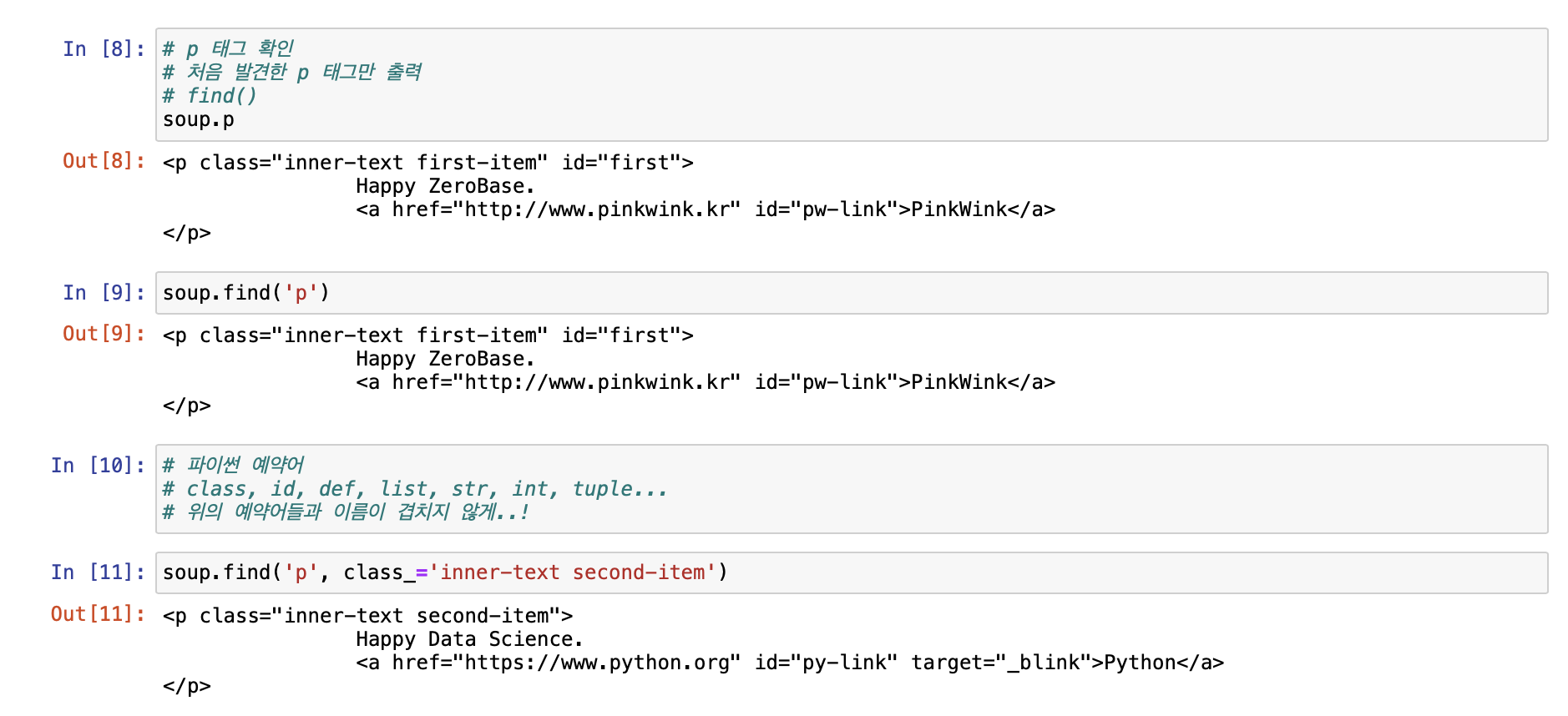
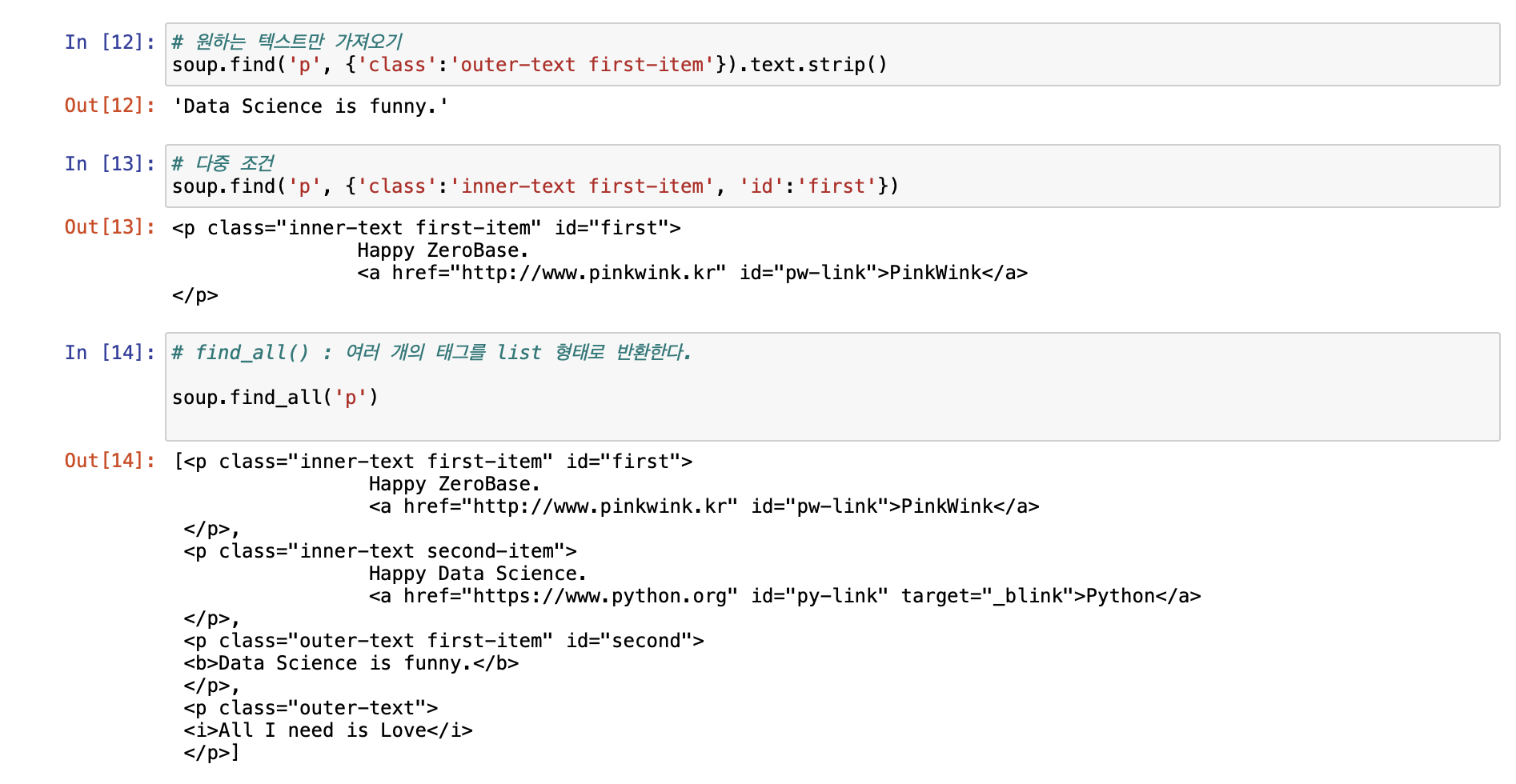
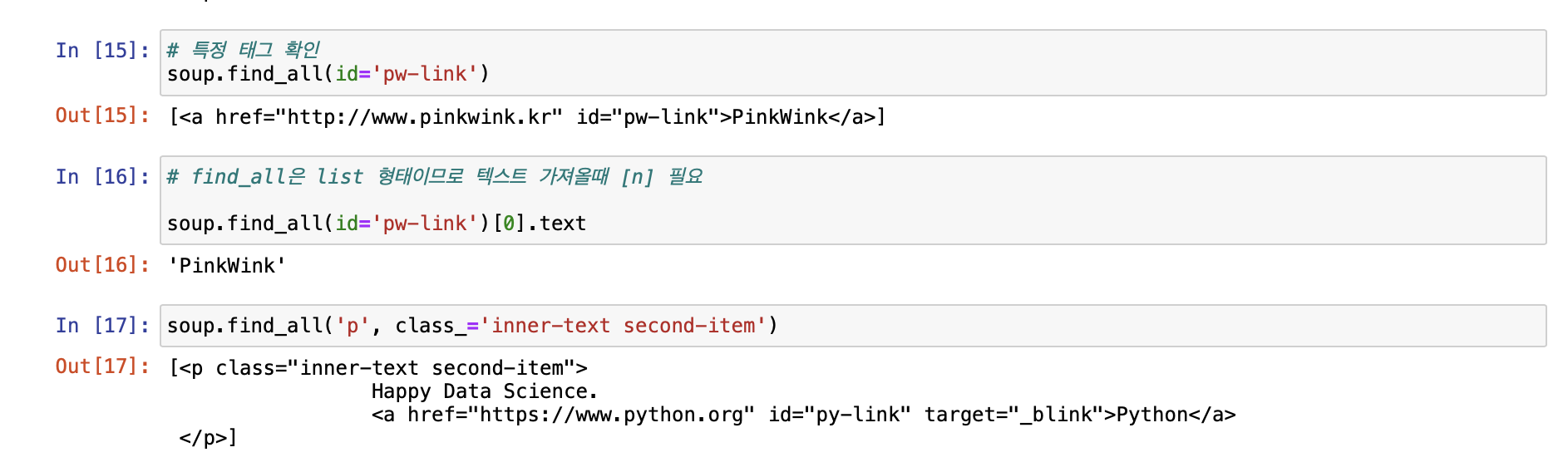
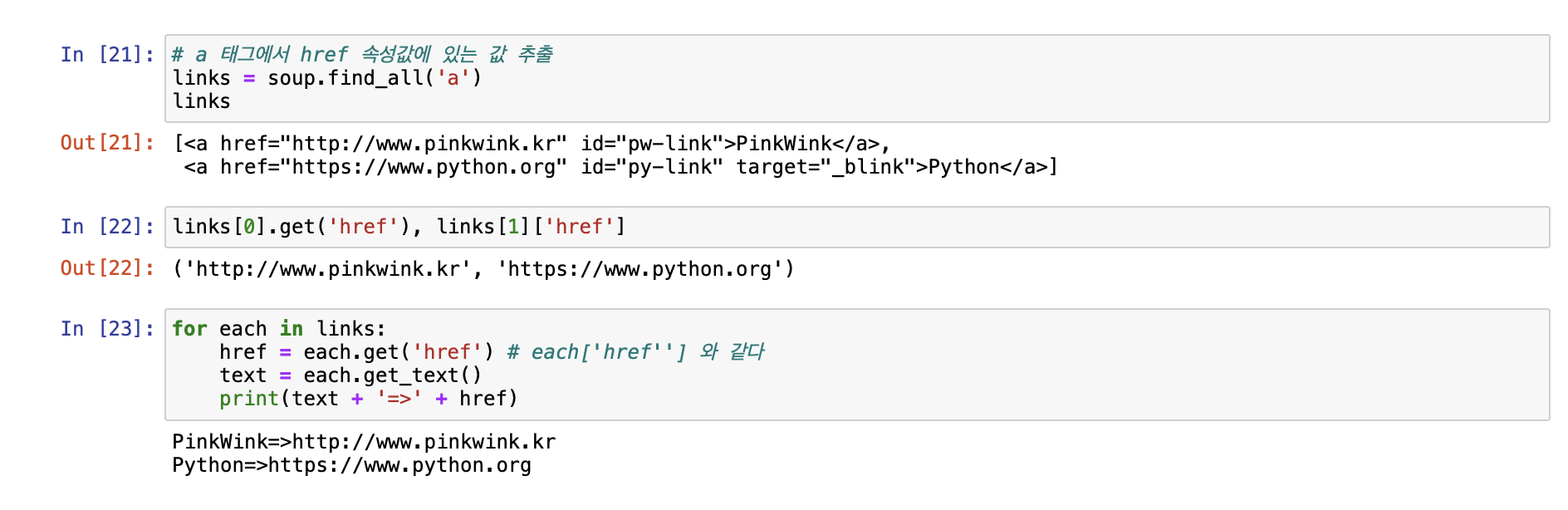
[ 크롬 개발자 도구 이용하기 ]
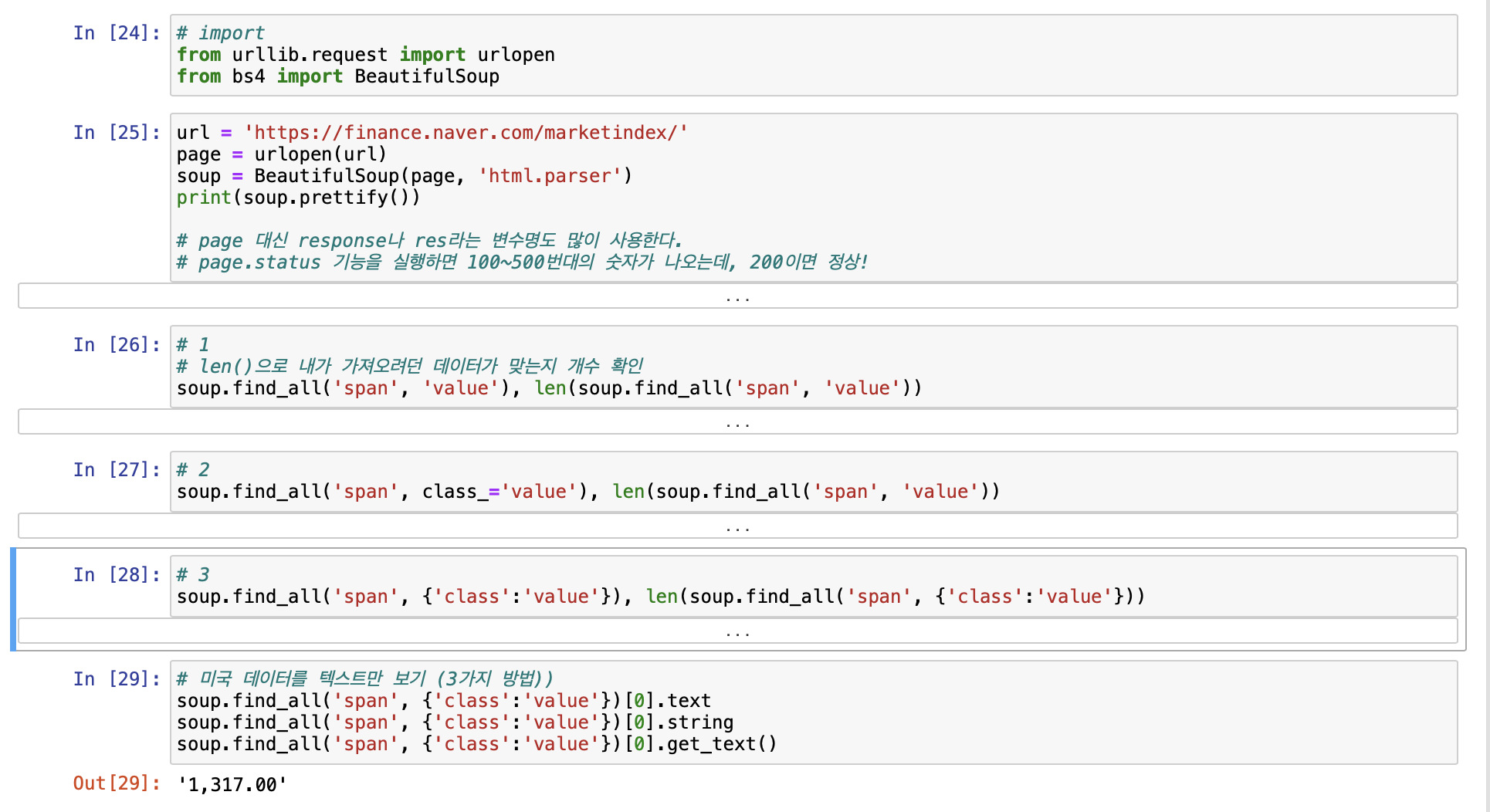
- BeautifulSoup 예제 1-1) 네이버 금융
- 크롬으로 네이버 금융을 검색하고 들어가서 <개발자 도구>를 활용해 원하는 데이터를 가져오기 위한 태그를 확인한다.
- BeautifulSoup 예제 1-2) 네이버 금융
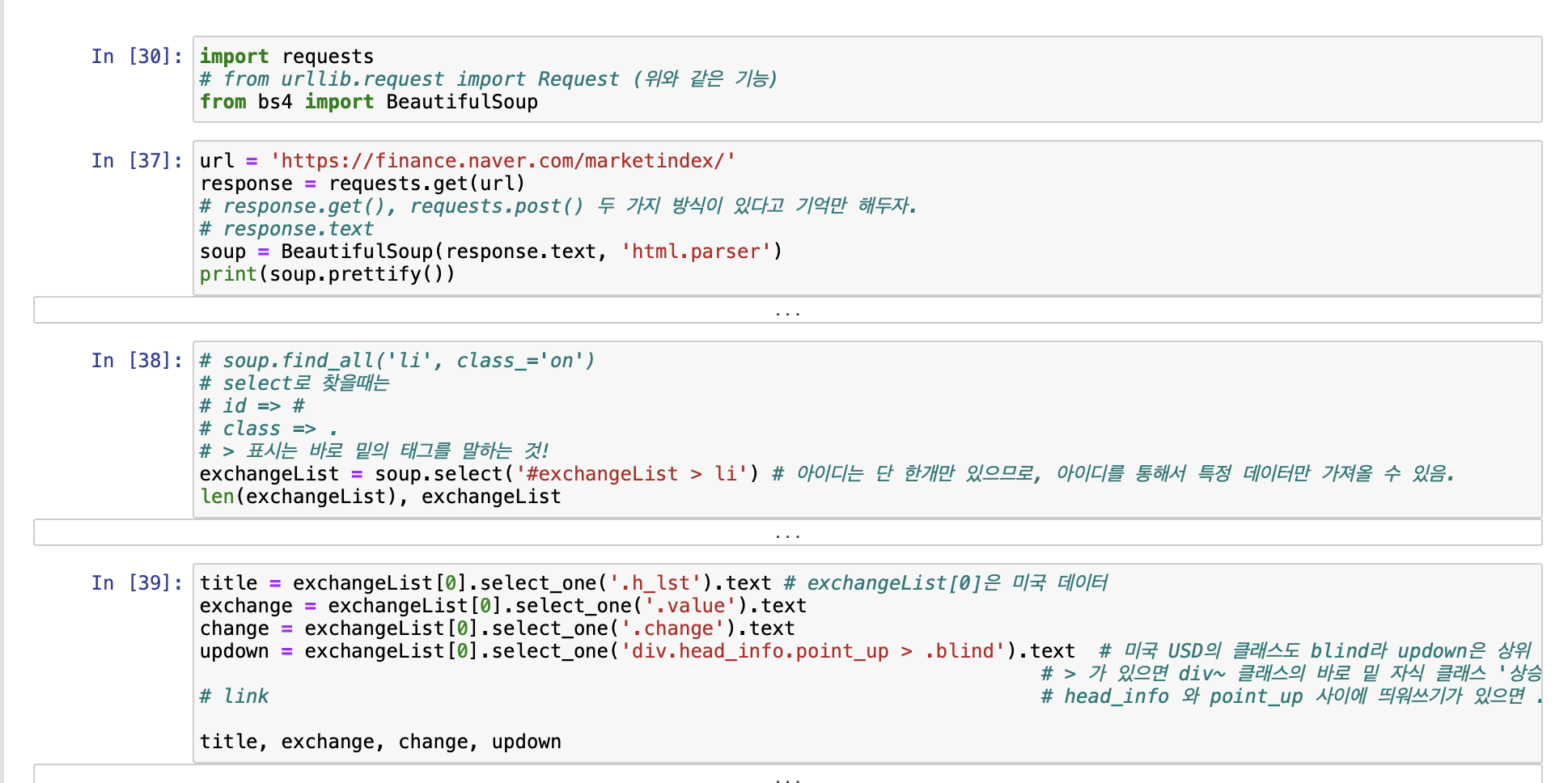
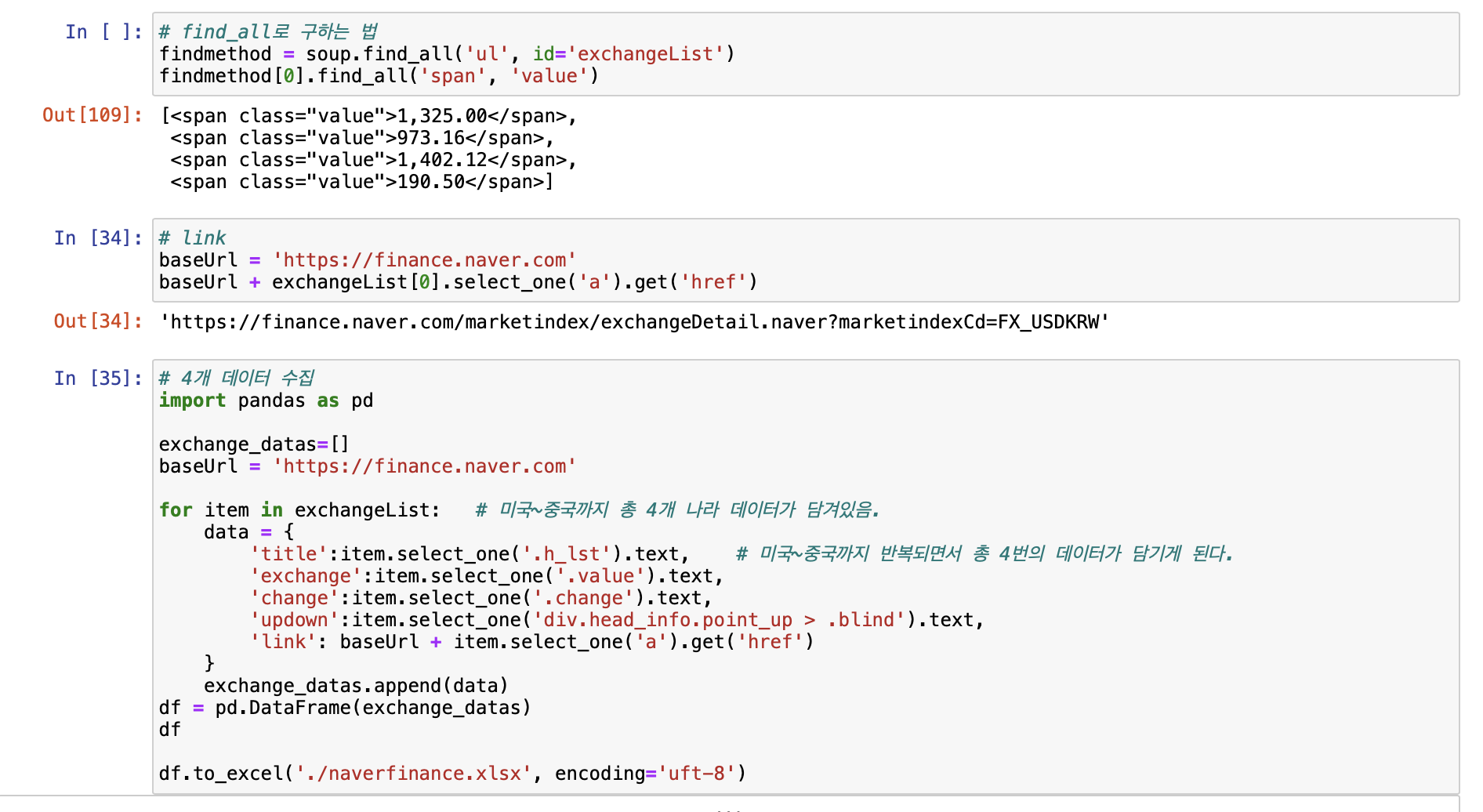
[위키백과 문서 정보 가져오기]
- BeautifulSoup 예제 2) 위키백과 문서 가져오기
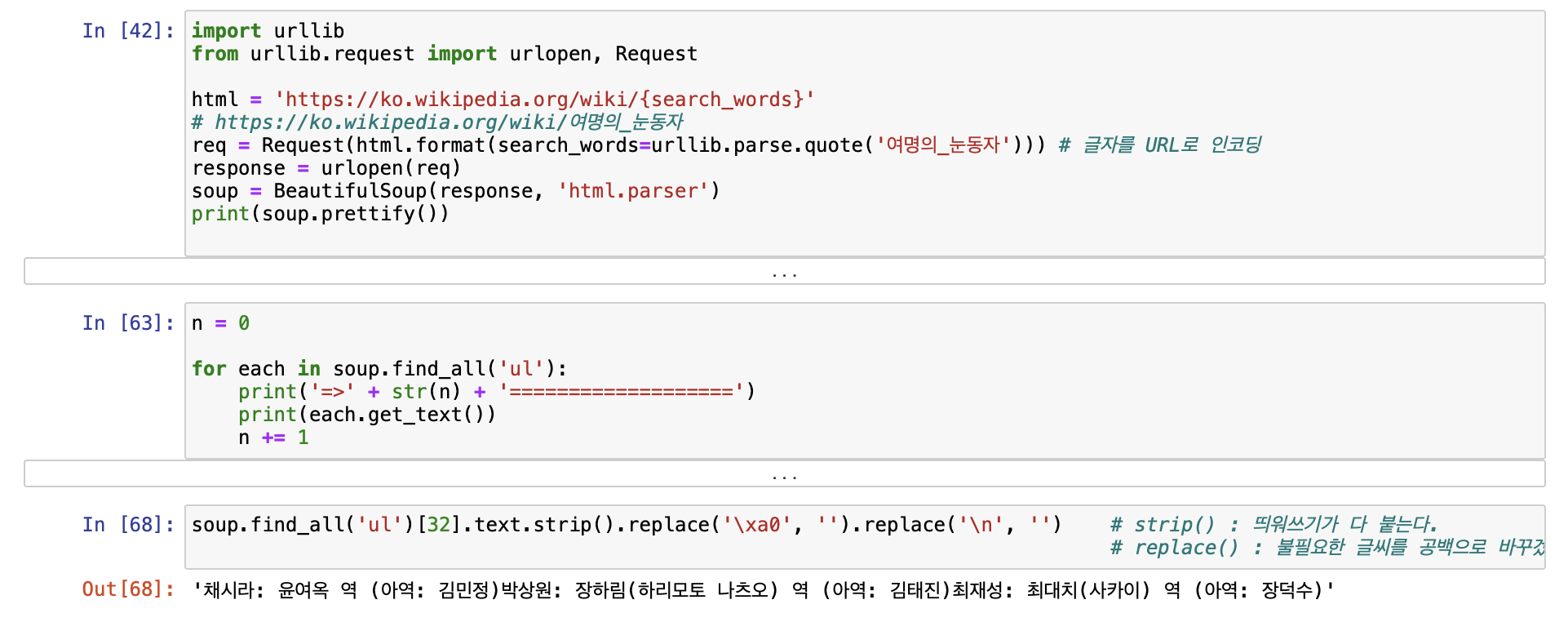
- 추가 개념! : isinstance
- 자료형의 True/False를 판단
- ex. favorite_movies = ['위대한쇼맨', 9.6, 인셉션', ['레오나르도 디카프리오', '조용하']]
- isinstance(favorite_movies, tuple) = False
- isinstance(favorite_movies, list) = True
for each_item in favorite_movies: if isinstance(each_item, list): for nexted_item in each_item: print('nested_item', nested_item) else: print('each_item', each_item)
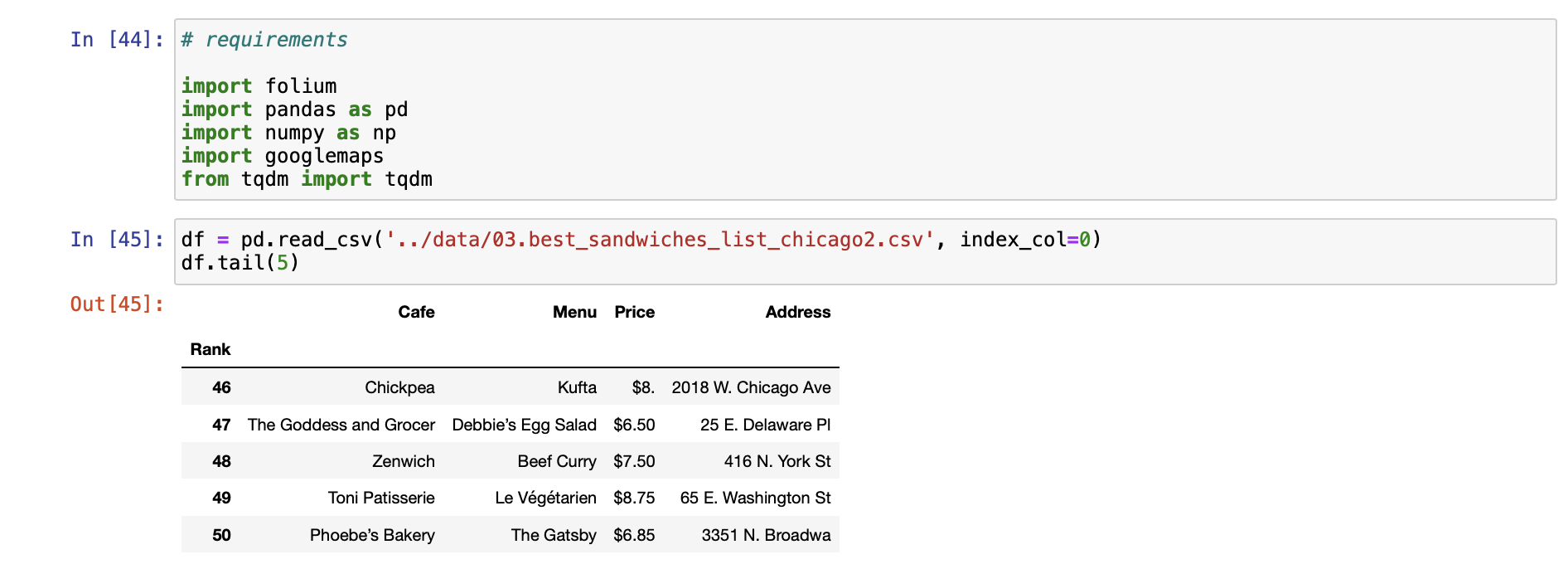
[시카고 샌드위치 맛집 분석 프로젝트]
[시카고 맛집 메인페이지 분석]
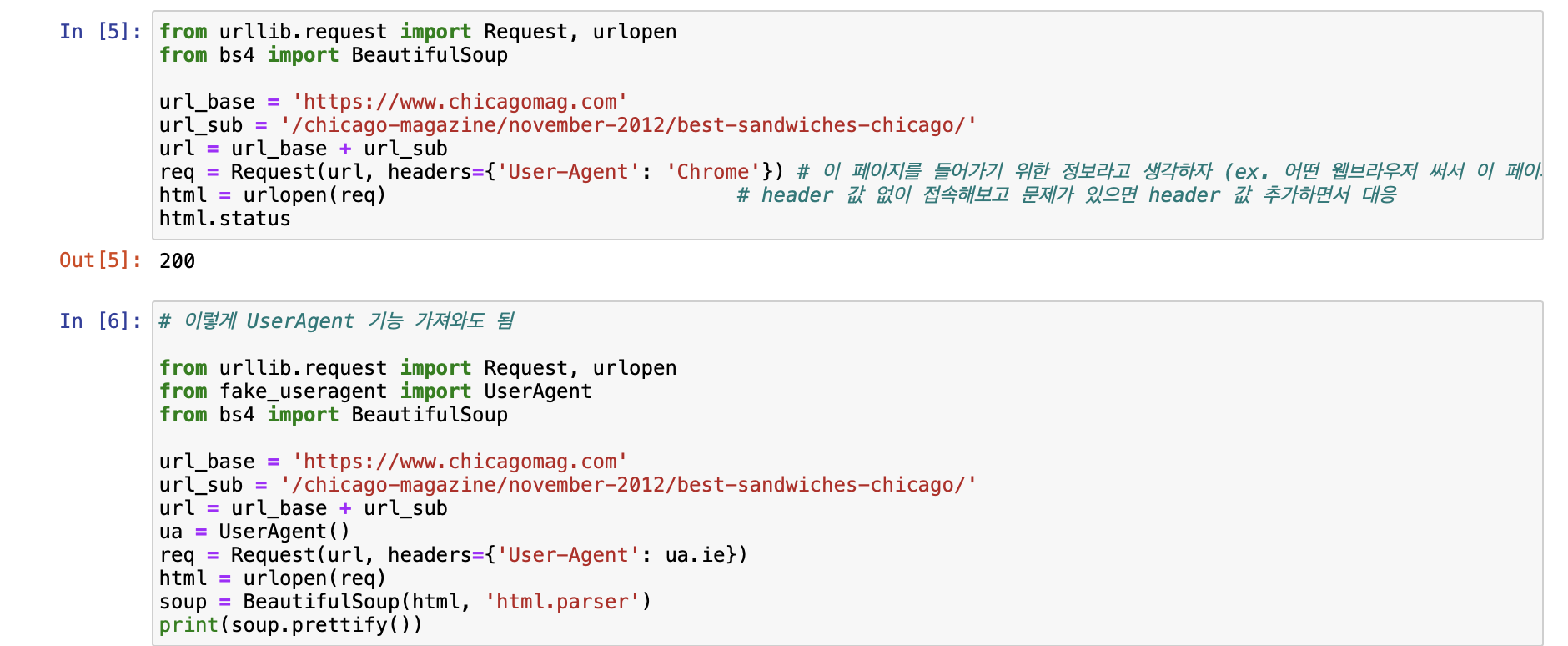
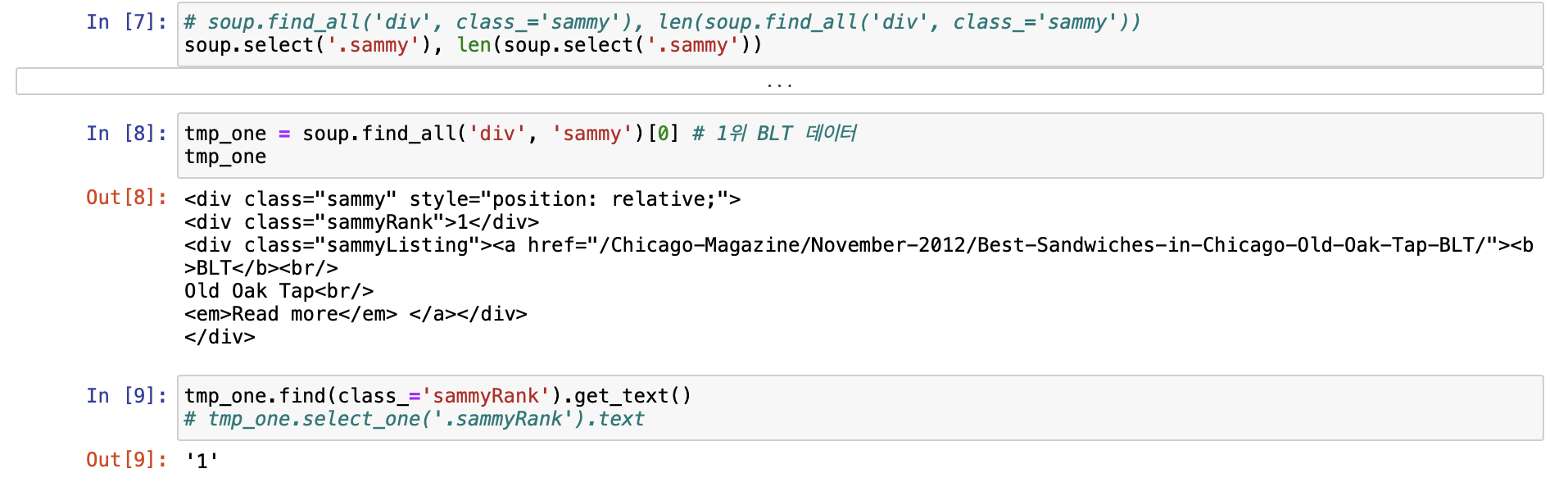
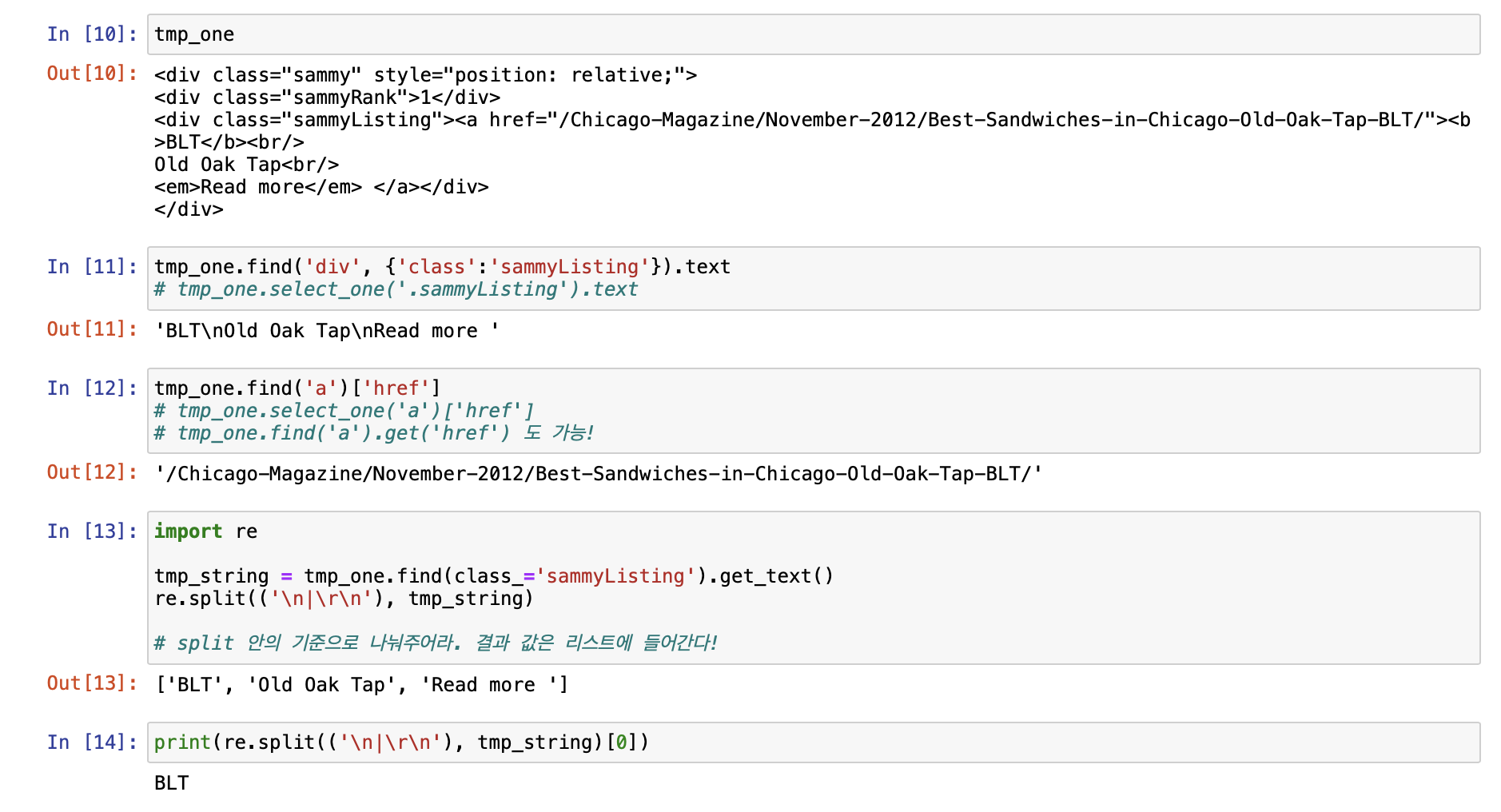
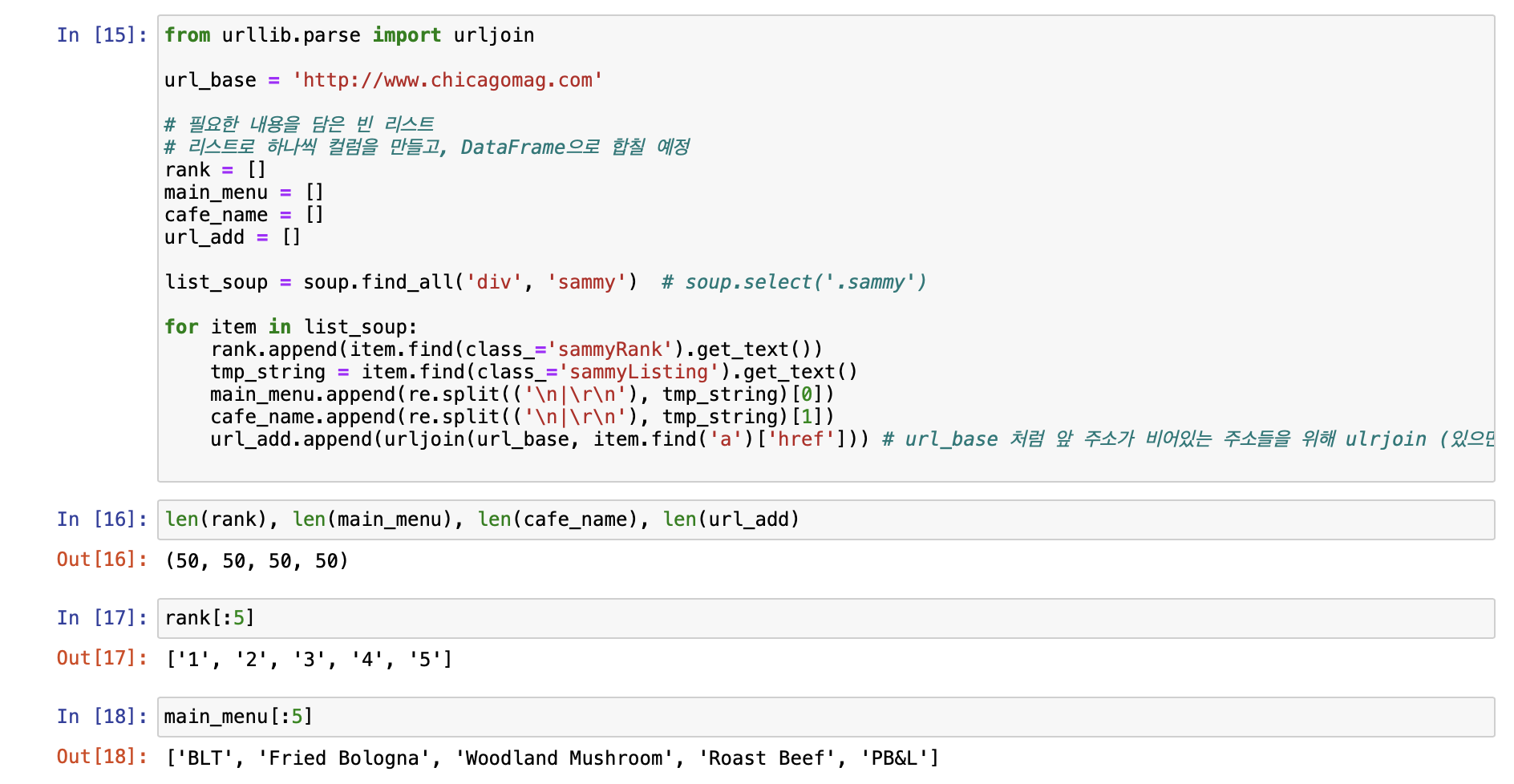
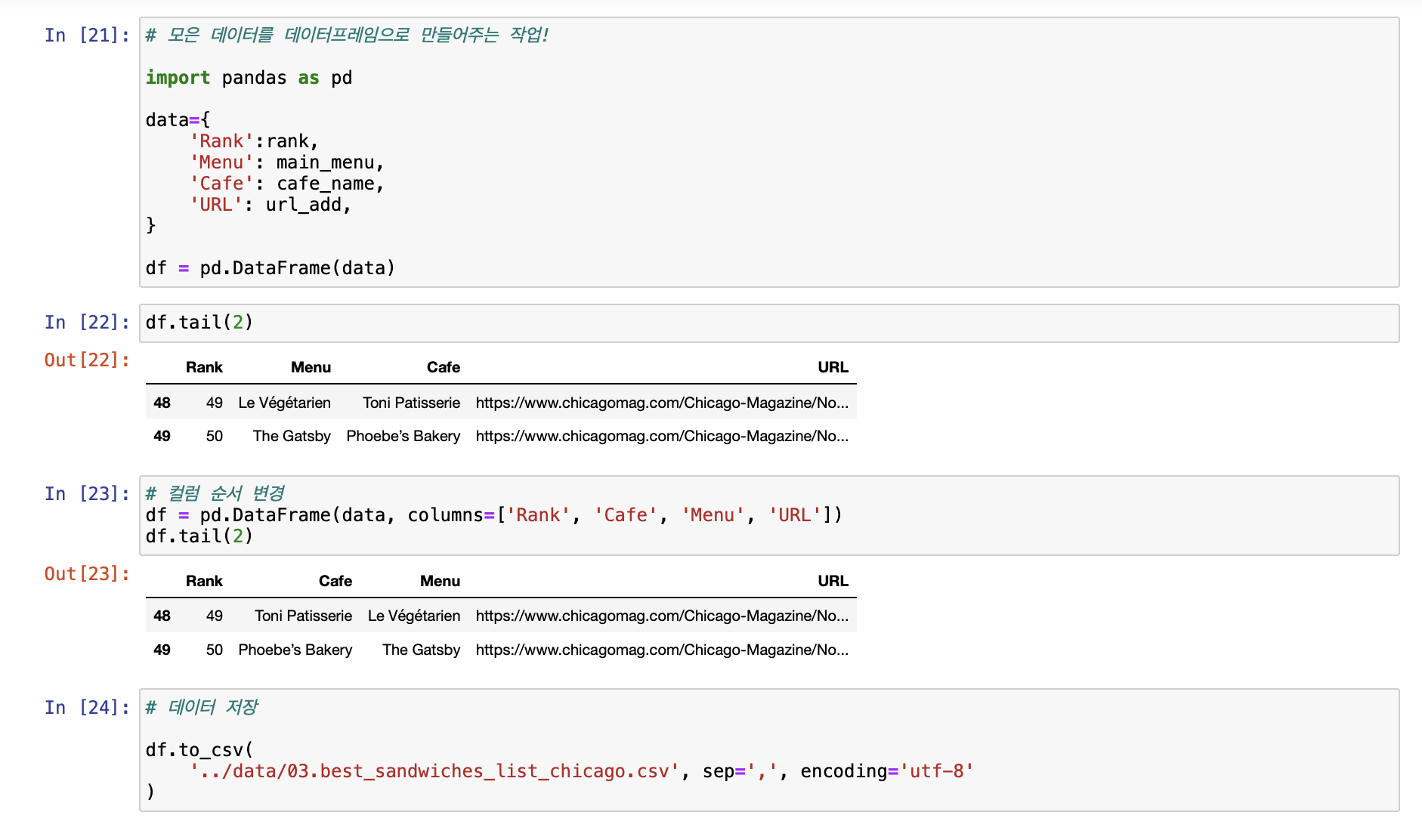
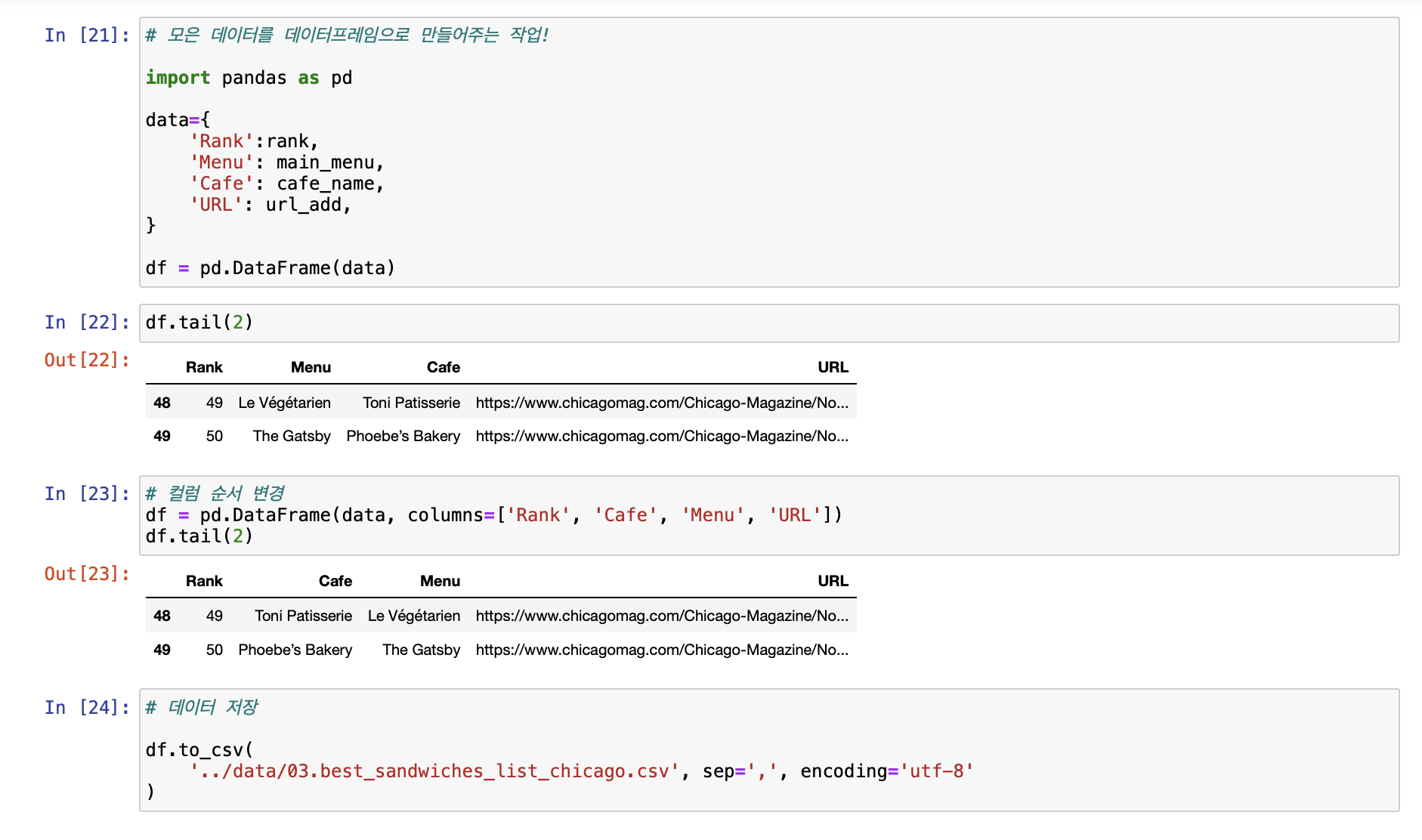
- 모은 데이터를 데이터프레임으로 만들어주는 작업!
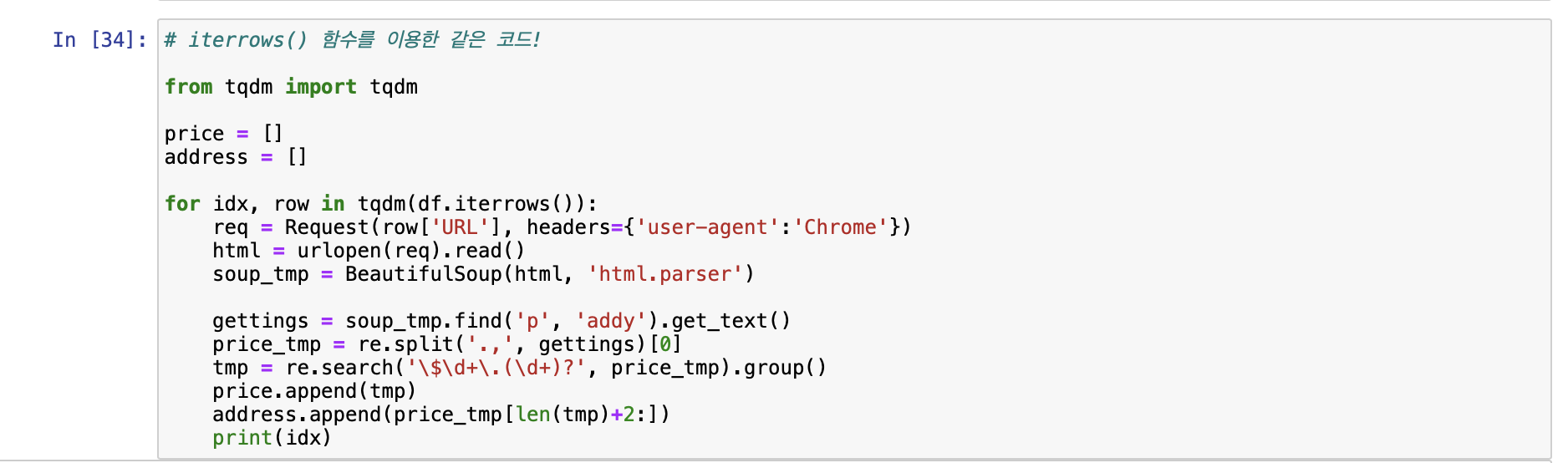
[시카고 맛집 데이터 하위페이지 분석]

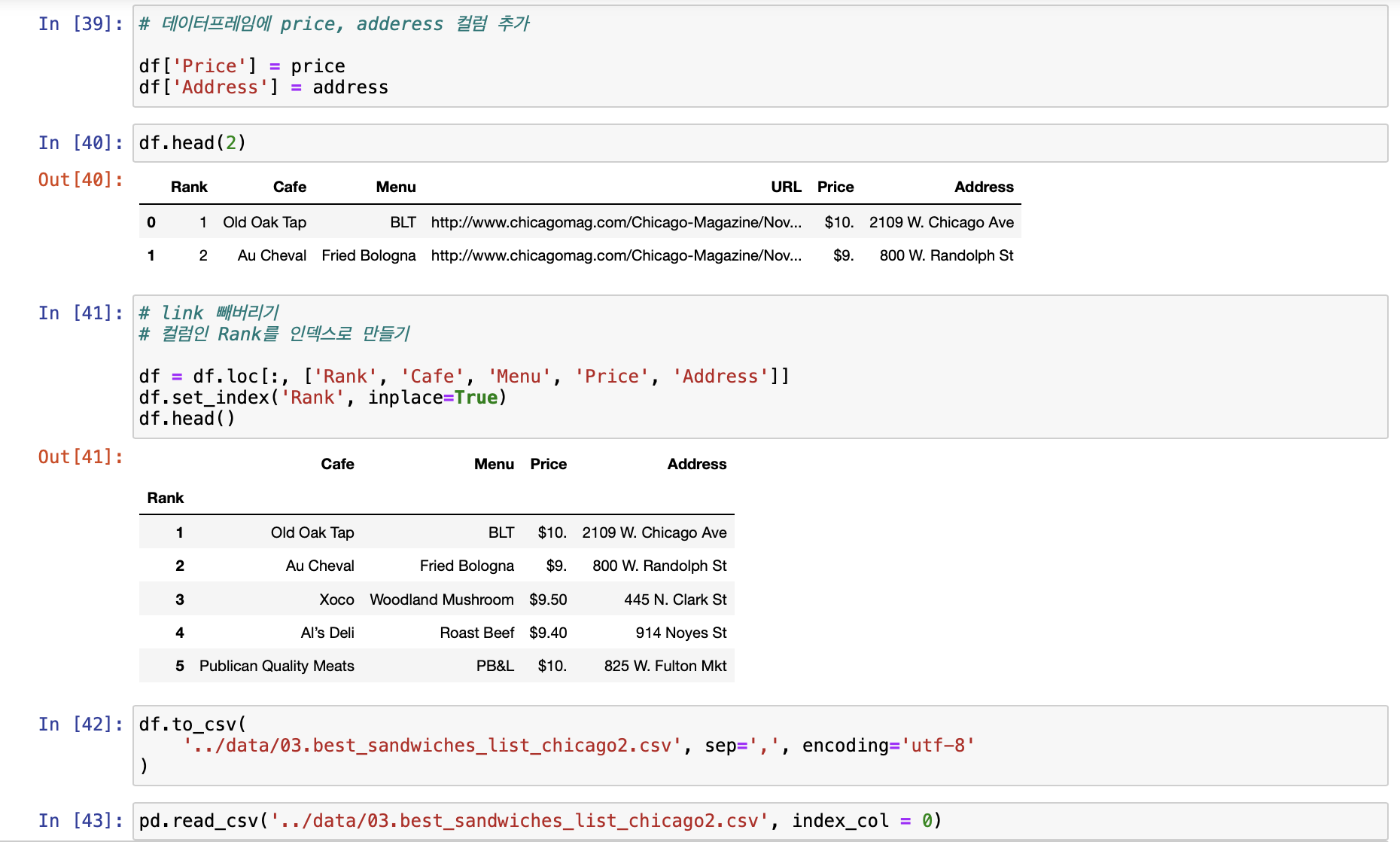
[시카고 맛집 데이터 지도 시각화]
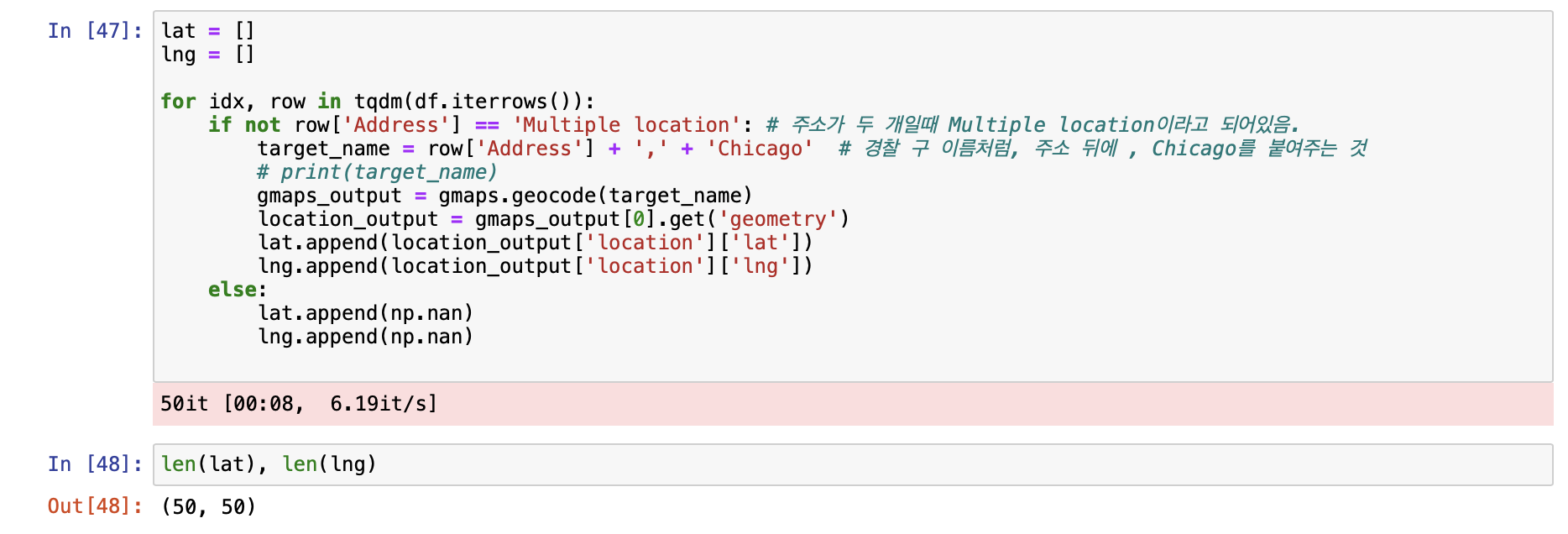
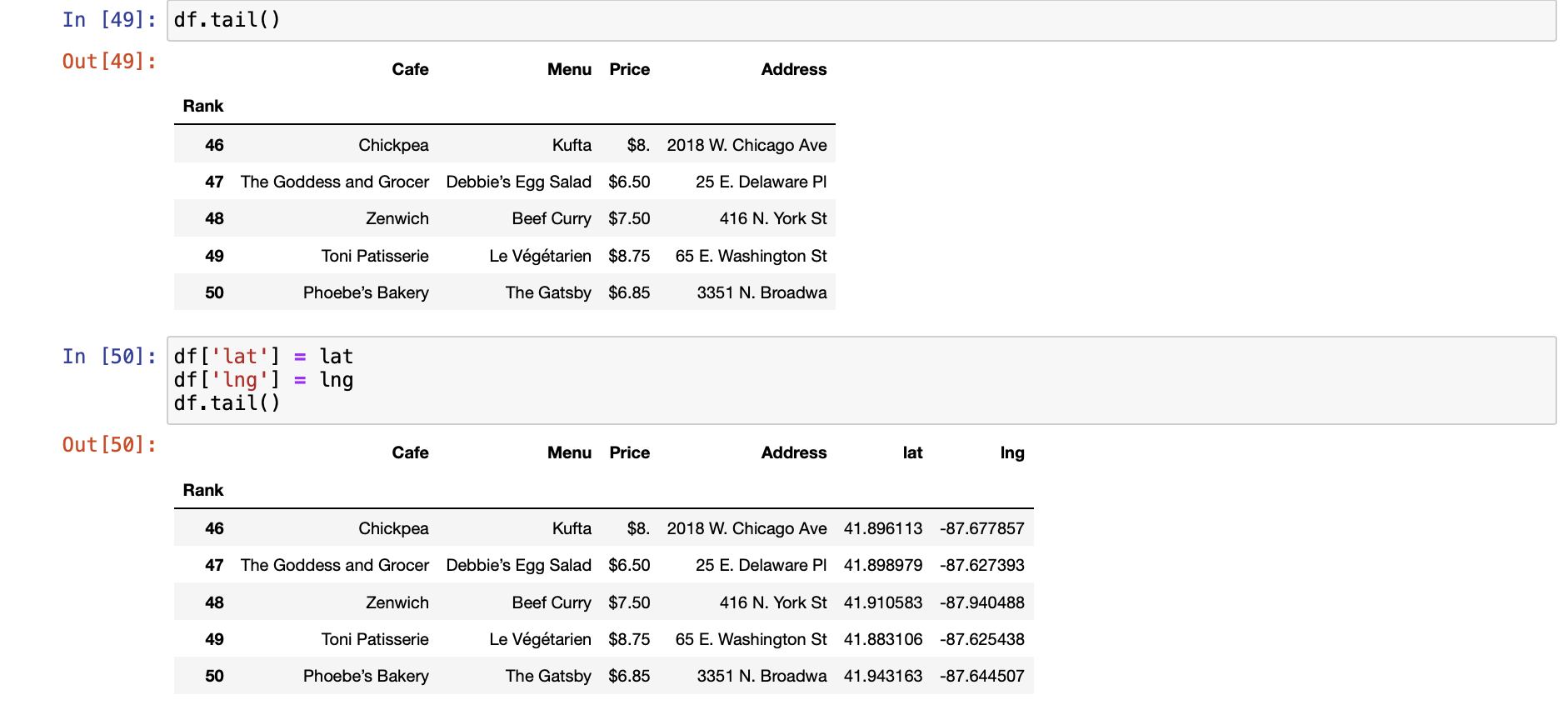
- 최종 지도

-> 지도 사진 추가 필요!
[네이버 영화 랭킹 프로젝트]
[네이버 영화 평점 사이트 분석]

- 영화 제목 태그
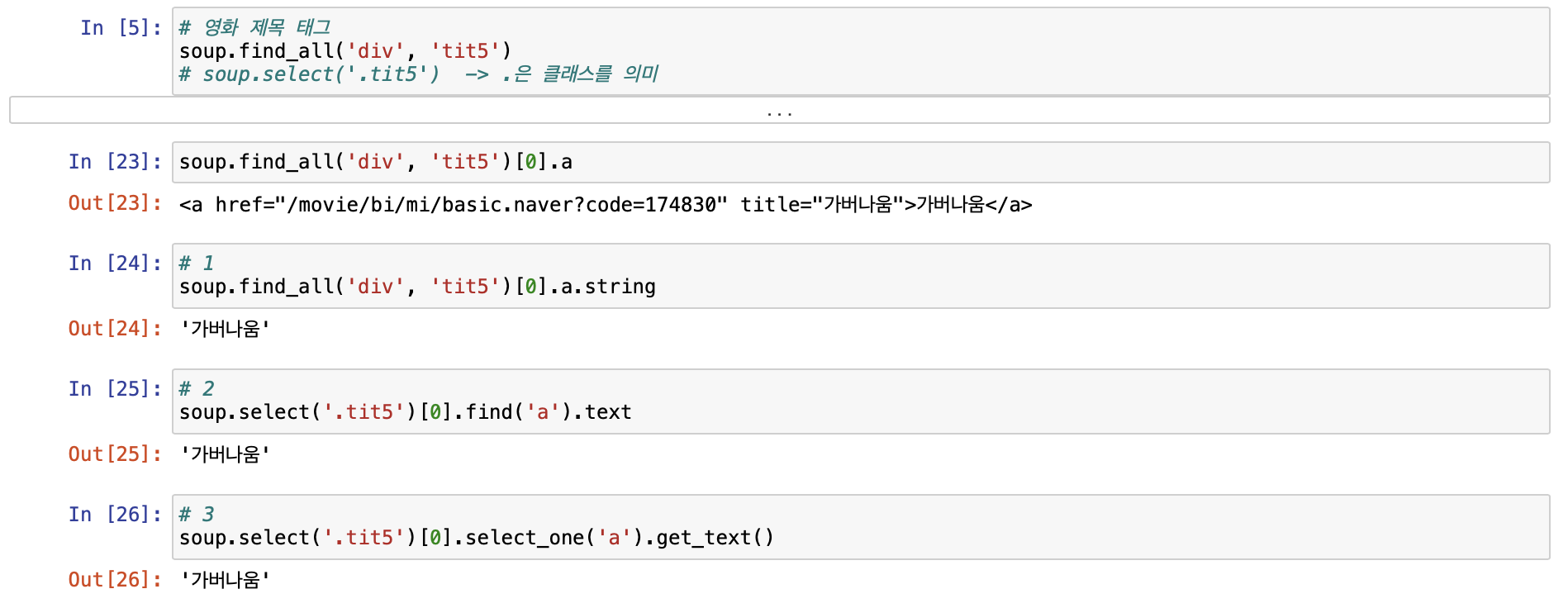
- 영화 평점 태그
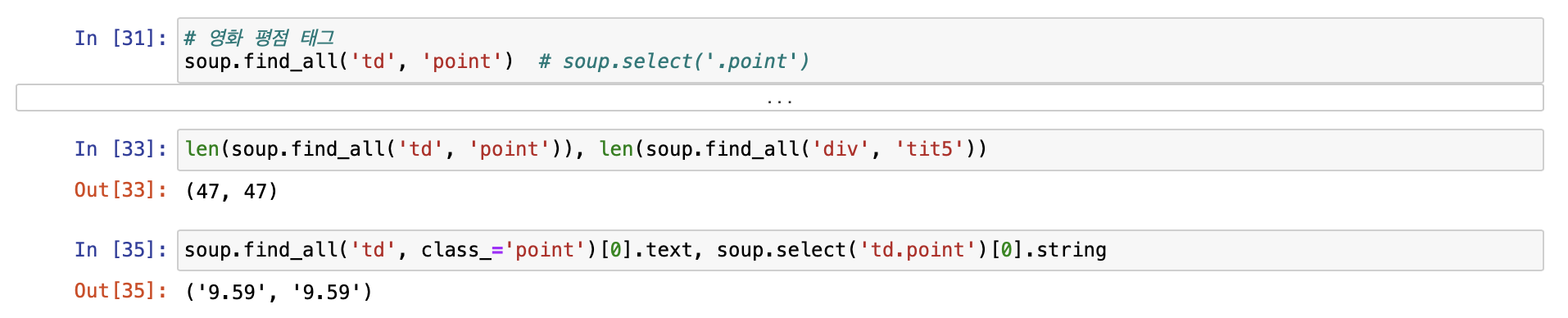
- 영화 제목 리스트 !

- 영화 평점 리스트

- 전체 데이터 수 확인

[네이버 영화 평점 데이터 확보]
- 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20210904'
- 마지막 날짜만 변경하면 우리가 원하는 기간 만큼 데이터를 얻을 수 있다.
- 2021년 1월 1일부터 100일간 기간 선정
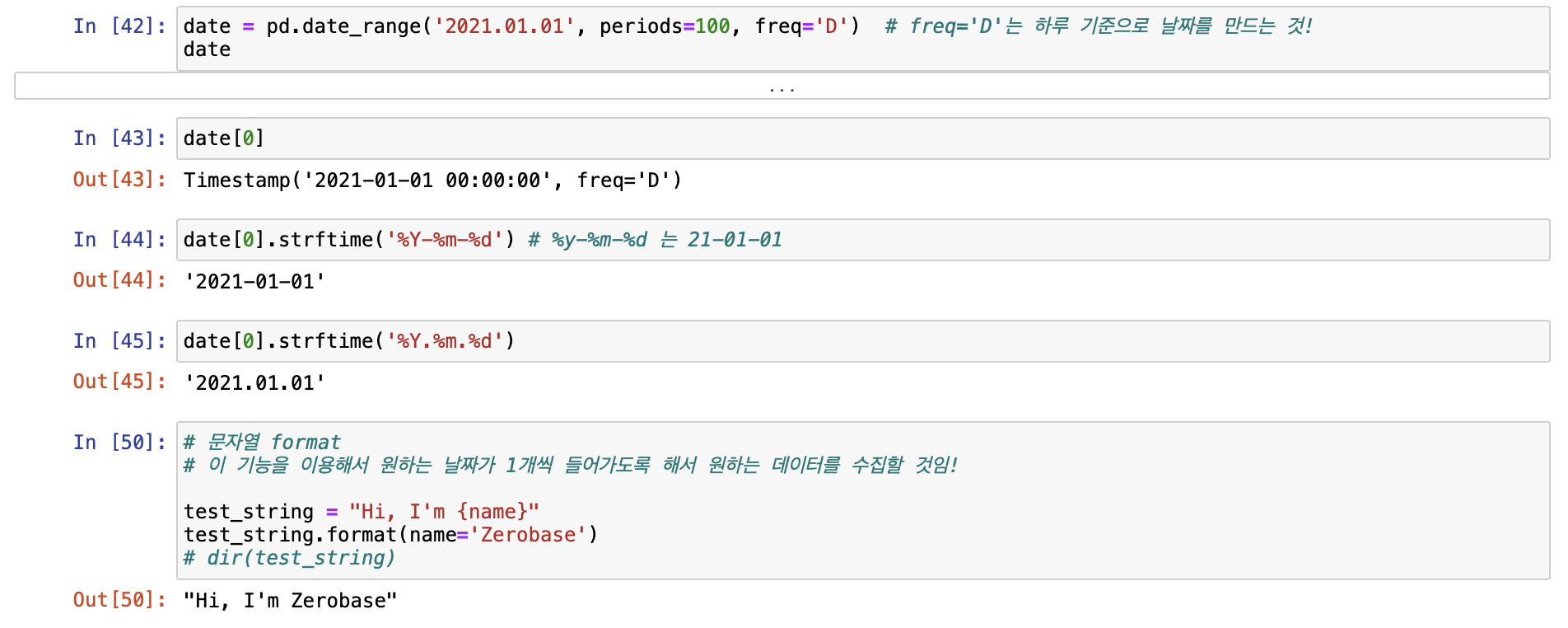
- 100일의 영화 평점 데이터를 가져오는 코드
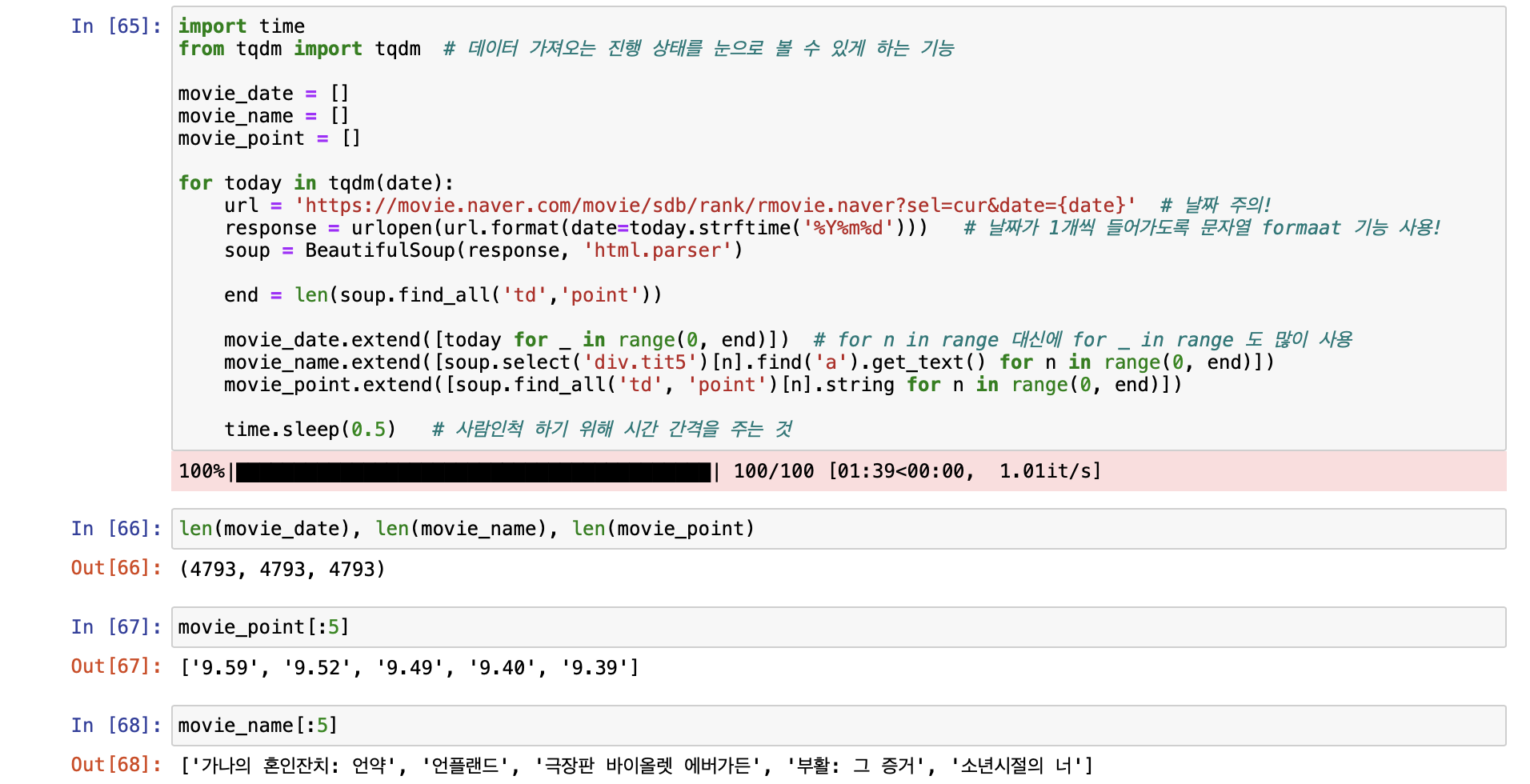
- 데이터 프레임 제작
- 평점 문자열 -> 실수형 변경
- 데이터 저장

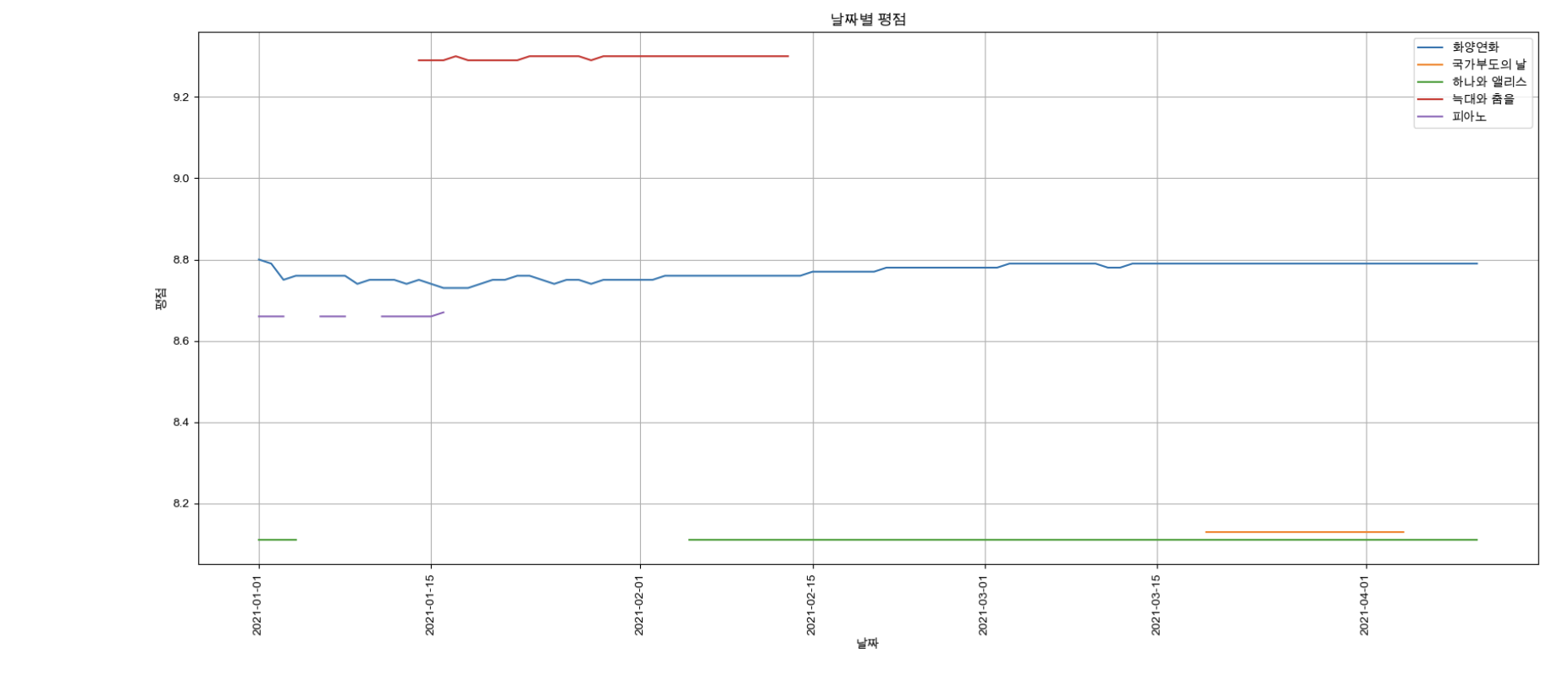
[네이버 영화 평점 데이터 정리 & 시각화]
- 영화 평점 데이터 정리
- 시각화

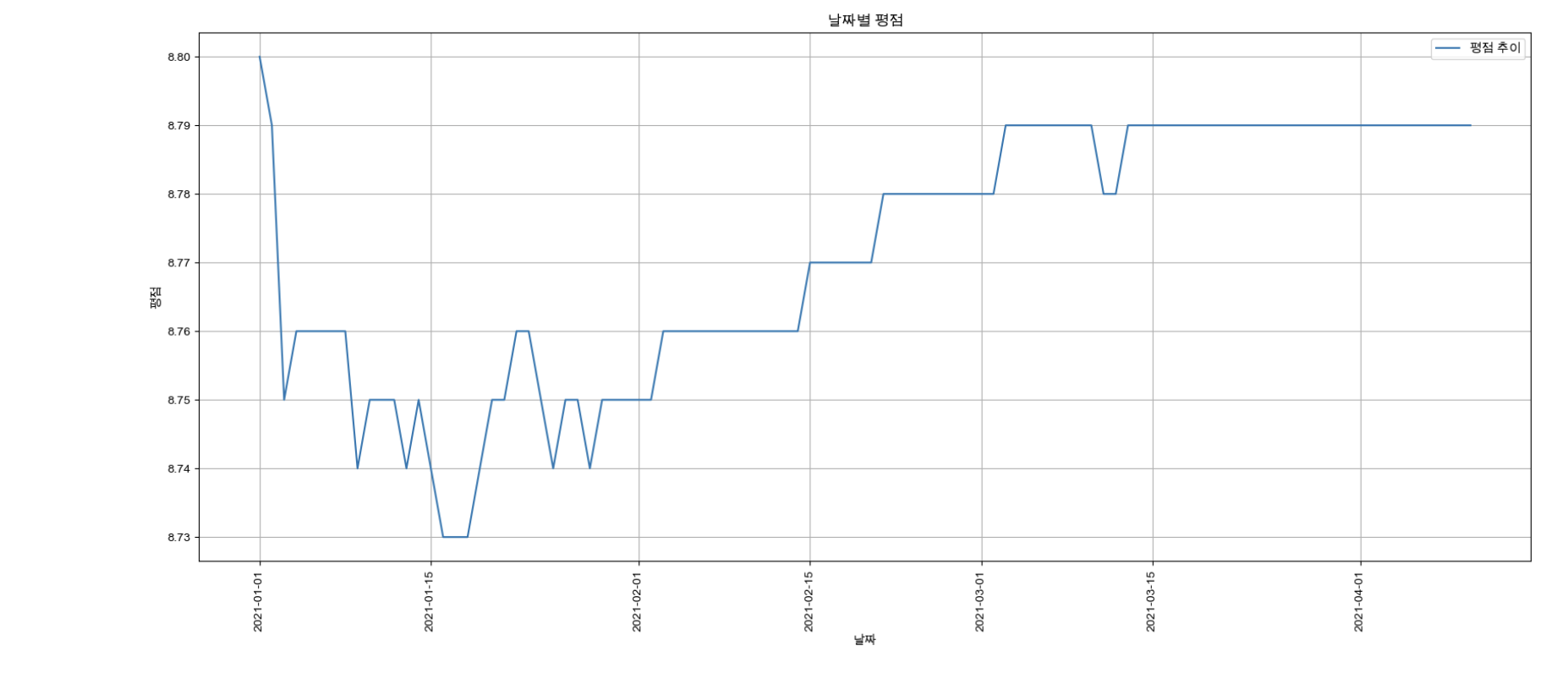
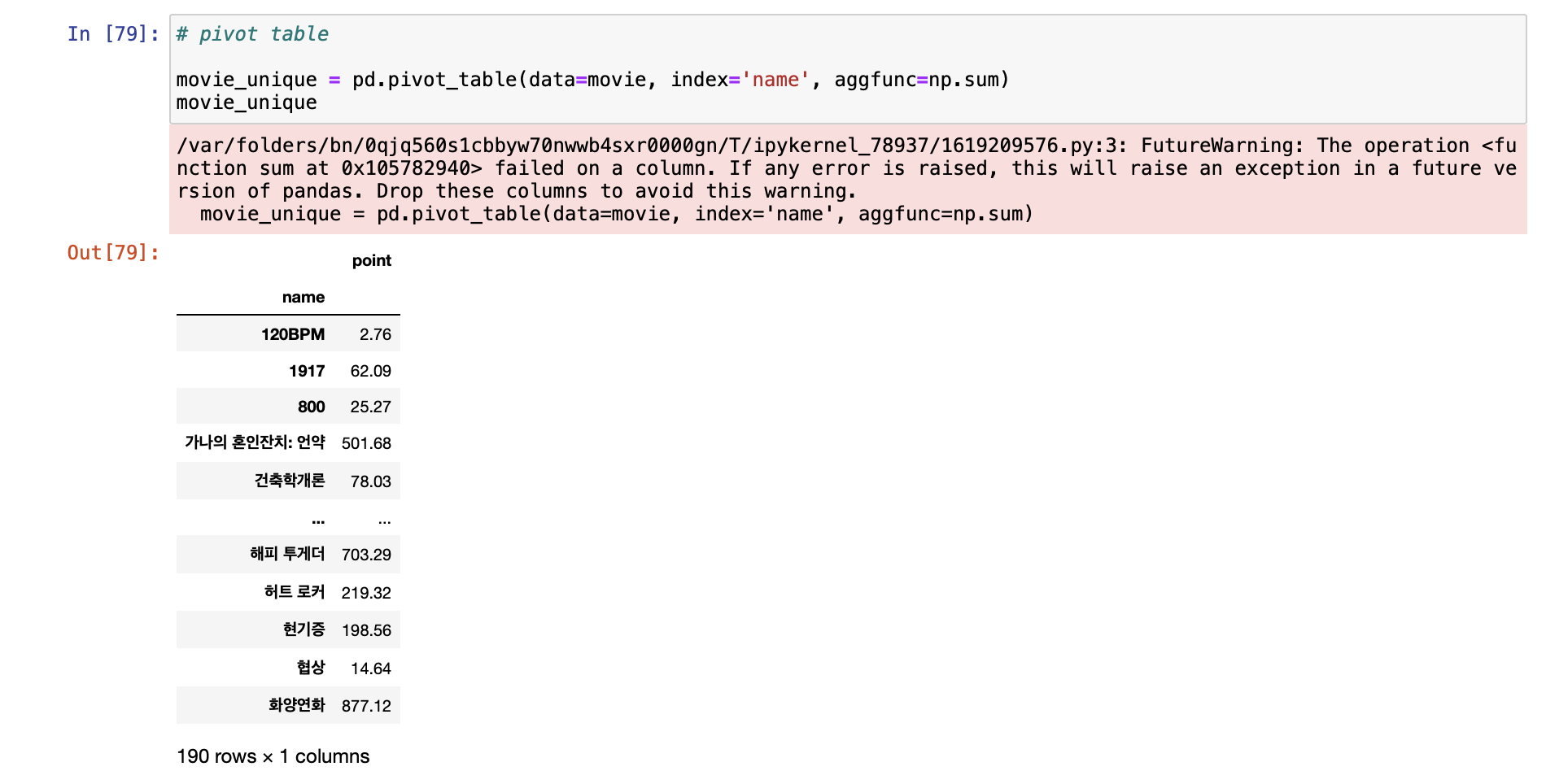
- pivot_table & 저장
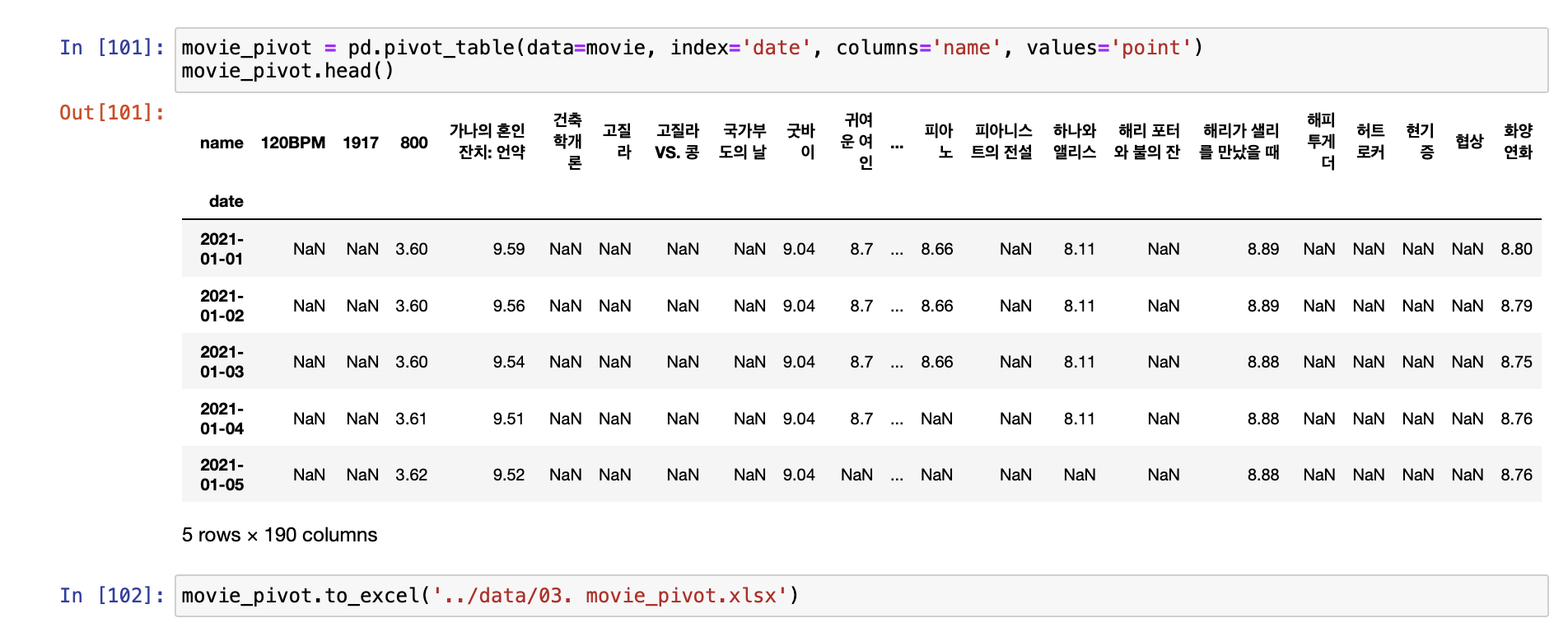
- 최종 데이터 & 시각화

늘 온 마음을 다해 :)