데이터베이스별 디스크 저장 방식 및 압축방식
서론
데이터베이스의 디스크 저장 방식은 비즈니스 모델의 요구 사항을 충족할 수 있는지를 검토하는 중요한 요소가 된다. 각 데이터베이스가 제공하는 저장 방식은 성능, 확장성, 데이터 압축 방식, 그리고 인코딩 방식에 따라 달라지며, 이러한 차이점은 비즈니스 모델에 맞는 최적의 데이터베이스 선택을 위한 중요한 기준이 된다. 본 글에서는 데이터베이스의 Row 기반과 Column 기반 저장 방식에 대해 살펴보고, 각 저장 방식에서 제공하는 압축 모델과 인코딩 방식의 차이점을 비교한다. 또한, 데이터베이스가 제공하는 압축 모델과 인코딩 방식이 비즈니스 요구 사항을 어떻게 충족시킬 수 있는지를 분석한다.
본 글에서 언급되는 페이지 크기와 1 Disk I/O는 Oracle Database 기준으로 설명한다. 데이터베이스에서 페이지(Page)의 기본 크기는 8KB로 설정되며, 이 크기는 데이터베이스가 데이터를 저장하는 기본 단위이다. 8KB는 일반적으로 사용되는 크기지만, 필요에 따라 변경이 가능하다. 또한, Disk I/O에서 한 번의 읽기 작업으로 기본적으로 8개의 페이지를 읽을 수 있다. 따라서, 한 번의 I/O 작업으로 읽는 데이터 양은 페이지 크기 × 8, 즉 64KB가 된다.
옵티마이저와 DB관리
RDBMS를 사용하는 기업에서는 데이터셋의 크기에 따라 관리 전략이 달라진다. 예를 들어, 작은 데이터셋, 보통 크기의 데이터셋, 큰 데이터셋을 사용하는 경우 각기 다른 방식으로 관리한다. 테이블에 Row Migration과 Row Chaining이 많이 발생하는 경우, 테이블을 주기적으로 재생성하여 데이터가 인접한 디스크에 위치하도록 설정하는 경우도 흔하다. SSD NVMe 디스크 사양을 사용할 경우, 물리적인 성능 차이는 별로 없을 수 있지만, 관리 측면에서 성능 최적화를 위해 이러한 재구성 작업이 필요하다.
개인적으로 SQL은 단순한 명령문이 아니라 옵티마이저에게 요청하는 방식(개떡같이 짜도 찰떡같이 바꿔주는…)이라고 생각한다. 대부분의 옵티마이저는 비용기반 옵티마이저(CBO)로 설계되어 있으며, 이는 ms단위 시간 동안 처리 비용이 가장 적은 실행 계획을 선택한다. 또한, 쿼리 실행 과정에서 불필요한 단계를 효율적으로 변경하여 최적의 성능을 낸다. 옵티마이저는 ms 단위 시간 동안 통계를 정확히 측정할 수 없기에, 테이블별 메타 정보를 저장하고 쿼리 시 해당 메타 정보를 불러와 최적의 실행 계획을 도출한다. 그러나 옵티마이저는 통계를 완벽하게 검증하지 않으며, 쿼리 성능을 높이기 위해 휴리스틱(Heuristic) 기반의 방식으로 쿼리를 결정한다. 이로 인해, Hint를 남발하는 유저가 있을 경우, 옵티마이저가 해당 Hint에 명시된 쿼리 플랜을 따라갈 확률이 높아지므로, Hint는 자주 사용하지 않도록 하고, 인덱스를 명확하게 설정하는 것이 중요하다.
MongoDB
MongoDB는 논리적으로 BSON(바이너리로 변환된 JSON) 형식으로 데이터를 저장하며, 2014년부터 WireTiger를 기본 스토리지 엔진으로 사용하고 있다. MongoDB는 레코드 스토어(또는 도큐먼트 스토어) 방식으로 데이터를 디스크에 저장하며, 하나의 도큐먼트가 물리적으로 함께 저장되는 구조를 따른다. 기본적인 Isolation level은 낮지만, Write-Ahead Logging(WAL)과 공유 캐시를 통해 다중 버전 동시성 제어(MVCC)를 지원한다.
MongoDB는 Collection 데이터를 압축하는 다양한 방식으로 데이터를 최적화할 수 있으며, 기본적으로는 None, Snappy, Zlib, Zstandard(ZSTB) 네 가지 압축 방식을 지원한다. 별도의 설정을 변경하지 않는 경우, Snappy가 기본 압축 방식으로 사용된다. 또한, MongoDB는 Collection 자체를 저장하므로, 데이터 인코딩에 따른 성능 차이는 크게 나타나지 않는다.
PostgreSQL
PostgreSQL은 행(row) 기반 저장소를 사용하는 전통적인 관계형 데이터베이스 관리 시스템(RDBMS)이다. 데이터는 각 행마다 디스크에 저장되며, 각 행은 페이지(Page) 단위로 디스크에 기록된다.
PostgreSQL의 저장 영역은 크게 Heap(메모리 아님), Index, Toast 3개로 구분된다. Heap은 데이터가 실제로 저장되는 기본적인 영역으로, 각 테이블의 데이터는 힙 영역에 저장된다. Index는 빠른 검색을 위해 사용되는 인덱스 구조로, 데이터의 순차적 검색을 효율적으로 처리할 수 있게 돕는다. 마지막으로, Toast는 주로 큰 데이터(예: 큰 텍스트나 바이너리 데이터)가 저장되는 영역으로, 데이터가 너무 커서 하나의 페이지에 맞지 않을 때 사용된다. 이러한 방식으로 PostgreSQL은 데이터의 저장 방식을 효율적으로 관리하며, 비즈니스 모델 요구 사항에 맞춰 성능을 최적화할 수 있다.
Heap (메모리 아님)
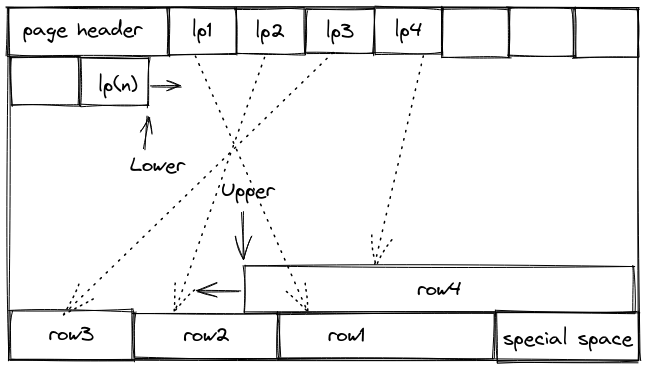
테이블의 대부분의 데이터를 Heap 영역에 저장한다. 한 페이지에는 데이터 행, 힙 헤더, 일부 시스템 관리 정보를 포함한다. 데이터는 Tuple 형식으로 저장되는데 (포인터, 값) 형태일 것이다.
Toast
PostgreSQL는 큰 데이터의 경우 Toast 영역에 저장한다. 예를들어 TEXT, BYTEA와 같은 경우에는 기본적인 페이지 크기를 넘어가므로 Toast를 사용하여 데이터를 다른 저장소에 분리하고 압축, 조각화하여 효율적으로 저장한다.
여기서 Toast의 설명을 읽다보면 Oracle의 로우 체이닝과 로우 마이그레이션 현상이 떠오른다. 별도 테이블 저장시에는 불필요한 Disk IO를 안하므로 효율적인 READ 성능이라고만 알아두자
TOAST와 Oracle의 Row Chaining/Row Migration 차이점
| 특성 | TOAST (PostgreSQL) | Row Chaining (Oracle) | Row Migration (Oracle) |
|---|---|---|---|
| 주 목적 | 크기가 큰 데이터를 효율적으로 저장 | 행 크기가 페이지 크기를 초과할 때 발생 | 행 크기가 업데이트로 증가하여 원래 페이지에서 저장할 수 없을 때 발생 |
| 대상 데이터 | TEXT, BYTEA 등 큰 데이터 | 행이 크기가 커서 하나의 페이지에 저장할 수 없는 경우 | 행이 크기가 업데이트로 늘어나서 기존 페이지에 저장할 수 없는 경우 |
| 저장 방식 | 데이터를 압축하거나 조각화하여 TOAST 테이블에 저장 | 행을 여러 페이지에 나누어 저장 | 행을 다른 페이지로 이동하여 저장 |
| 성능 문제 | 페이지 크기 제한을 넘은 큰 데이터에 대해 성능 최적화 | 여러 페이지에서 행을 읽어야 하므로 디스크 I/O 증가 | 한 페이지에 있는 원래 데이터와 이동된 데이터가 혼합되어 성능 저하 |
| 장점 | 큰 데이터의 압축과 조각화로 디스크 공간 절약 | 행이 커서 하나의 페이지에 맞지 않을 때 발생, 효율적으로 처리 | 행 크기가 커졌을 때 데이터가 이동되어 저장되므로 적절한 공간 활용 |
| 단점 | 압축, 조각화로 인해 읽기 성능 저하 가능 | 디스크 I/O 증가 및 성능 저하 | 디스크 I/O 증가 및 성능 저하 |
압축 알고리즘 & Encoding
Heap의 경우 고정길이 튜플 형태로 저장되기 때문에 별다른 압축 알고리즘이 적용되지 않는다. Toast의 경우 가변길이의 데이터가 저장되는 테이블이므로 압축 알고리즘이 적용되는데 PGLZ 압축 알고리즘과 LZ4 압축 알고리즘이 적용된다. 기본값은 자체 개발한 PGLZ이며 LZ4의 경우 13버전 이후 지원한다.
만약 Toast에 저장된 단일 필드에 대해서 특정 시나리오에 대해 속도를 조절하고 싶다면 아래 글을 읽어보는 것을 추천한다.
https://www.postgresql.fastware.com/blog/what-is-the-new-lz4-toast-compression-in-postgresql-14
이 글에서는 LZ4가 읽기 속도는 비슷하고, 쓰기 속도가 비약적으로 상승했다고 서술한다. 따라서 DB를 설계할 때, 필드에 대한 압축 알고리즘이 어떤 것들을 지원하는지, 그리고 어떤 필드를 어떤 알고리즘으로 압축해야 하는지도 중요한 고려사항이 된다.
CREATE TABLE tbl (id int, col1 text COMPRESSION pglz, col2 text COMPRESSION lz4, col3 text);Elastic Search
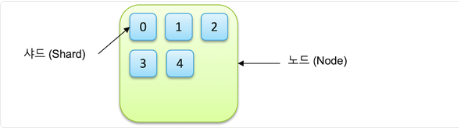
Elastic은 검색 및 분석 엔진이다. 기본적으로 RDBMS와 동일하게 문서 기반(or 레코드 기반)의 데이터를 처리한다. elastic의 인덱스는 RDBMS의 데이터베이스와 비슷하다. 데이터를 저장하고 인덱싱 하는 곳이다. 각 인덱스는 여러 샤드로 분할되어 저장되고 샤드는 물리적으로 데이터를 저장하는 단위이다. 즉 인덱스는 하나 이상의 샤드를 가르키는 논리적 네임스페이스다. 아래는 하나의 인덱스가 5개의 샤드로 저장되도록 설정한 예
개인적으로 Elastic의 가장 중요한 알고리즘을 뽑자면 역방향 인덱스(Inverted index)이다. 역방향 인덱스는 검색을 위해 고안되었고 동작방식은 아래와 같다.
Insert Below Document
{
_id: 1,
test: "I Love Xan"
},
{
_id: 2,
test: "I Love Jun"
}| text | id |
|---|---|
| I | 1, 2 |
| Love | 1, 2 |
| Xan | 1 |
| Jun | 2 |
문자열에 따른 ID 값을 매핑시켜 검색을 빠르게 수행할 수 있도록 한다. Elastic의 경우 일반적인 DB처럼 인덱스를 추가하지 않아도 필드가 Text 형태로 되어있다면 역방향 인덱스에 추가된다. 이는 원본 데이터보다 역방향 인덱스가 훨씬 큰 Disk 용량을 차지하고 있음을 말한다.
역방향 인덱스의 경우 Segment라는 형태로 저장된다. 샤드에서 검색은 각 세그먼트를 차례로 검색한 다음 (역방향 인덱스를 검색한 다음) 그 결과를 결합하여 샤드의 최종 결과를 만든다.
Elastic의 데이터 타입이 무조건 역방향 인덱스에 들어가는 것은 아니고 숫자 타입은 PintValues로 색인하는데 KD-Tree 자료구조를 사용해서 저장이 되어있다. (다차원 공간에서 search 등에 사용하는 기법)
따라서 숫자타입으로 되어있는 필드에 Search를 하게 된다면 검색성능이 크게 저하될 수 있다. 아래 블로그도 한번 참고해보도록 한다.
https://techblog.woowahan.com/20161/
Elastic이 사용하는 기본 압축 알고리즘은 LZ4를 사용하고 있다. Snappy도 아니고 LZ4를 사용하는것은 대용량 데이터를 저장하는게 아니라 검색을 위해서 빨라야 하니까 압축 해제 속도 & 압축 속도를 더 중요하게 생각함을 알 수 있다.
Kudu
Kudu는 열(column) 기반 스토리지 시스템이다. 열 기반 스토리지 시스템은 데이터를 열 단위로 저장하여 읽기 성능을 최적화 한다. 행 기반 스토리지와 비교를 하자면 행 기반은 온라인 트랜잭션 처리 (OLTP) 어플리케이션일 때는 대부분 트랜잭션에서 전체 레코드의 모든 값을 읽고 쓰는 작업이 일어난다. 따라서 OLTP 어플리케이션은 행 방향 스토리지를 쓰는것이 효율적이나, 특정 컬럼에만 접근해야 하는 분석 쿼리에 대해서 높은 성능을 보이고 싶을때는 열 기반 스토리지를 사용해야 한다. 각 열은 동일한 형식의 데이터를 보유하므로 열 데이터 형식에 맞게 선택된 압축 스키마를 사용하여 디스크 공간 및 I/O를 줄일 수 있다. 예를 들어 일반적인 OLTP를 위한 데이터 베이스에 1억개의 데이터가 있다고 한다면 이를 순회하기 위한 DiskIO는 얼마나 많을지 상상도 할 수 없다. 열 기반 스토리지 시스템에서는 분석을 위한 열만 query를 하면 되므로 훨씬 빠른 속도를 보장할 수 있다.
예를 들어 순차적으로 1부터 올라가는 필드값 ID라는 값이 있다고 한다면 열 기반 스토리지에서 Bitshuffle Encoding(아래에서 설명)로 압축하여 더 높은 쿼리 속도를 보장할 수 있다. 또는 Run Length Encoding을 적용하여 디스크 압축과 더 높은 쿼리 속도를 보장한다.
Kudu는 일반적인 분산 스토리지 시스템과 동일한 형상으로 짜여져 있다. 합의 알고리즘은 무난한 Raft 알고리즘을 사용한다. 각 cell은 64KB크기의 제한을 가진다. 여기서 각 셀에 64KB의 제한을 가진건 OLAP에 대한 방향성을 보여주는 듯 하다.
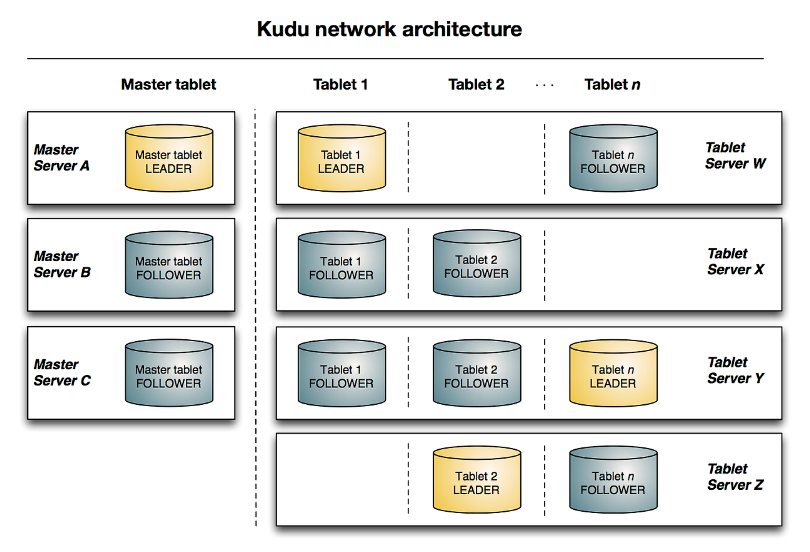
마스터는 홀수 구조로 되어있고 tablet은 스토리지 서버(elastic을 기준으로 하면 데이터 노드)라고 이해하면 된다.
Kudu에 파티션을 설정했다면 파티션 키에 할당된 tablet 서버에 데이터가 저장되고
Write요청은 각 tablet 서버에 분산이 되므로 write 부하 분산이 된다고 이해하면된다.
Read 요청도 동일하게 실제 데이터가 들어있는 tablet서버에서 I/O가 일어나므로 부하 분산이 일어난다.
즉, master에 저장된 데이터가 tablet에 저장되고 그 정보를 master의 메타 정보가 가지고 있다. 기본값으로 Replicas는 3으로 설정되어 있기 때문에 follower tablet에게 데이터를 sync하는데 디스크 저장공간을 줄이고 싶다면 replicas를 1로 설정해야한다
TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');- DB의 옵티마이저 처럼 쿼리를 전송했을 때 데이터가 있는 tablet에 I/O
Kudu는 Tablet 내부에 Rowset이라는 형태로 저장되는데 Rowset는 Metadata, PrimaryKey, column data, delta storage(로그) 의 정보가 있다. 또한 RowSet의 경우 압축을 통해 더 큰 Rowset을 생성해서 저장한다.
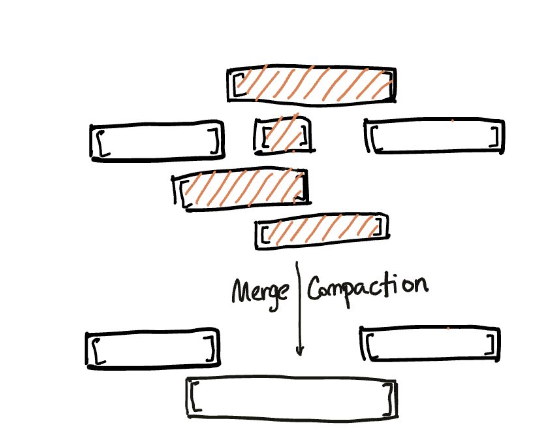
Kudu의 경우 각 필드에 대해 많은 압축 알고리즘을 제공하고 있다.
블로그 포스팅을 하는 테이블을 예시로 살펴보면 post_id는 순차적으로 증가하는 값이므로 BIT_SHUFFLE 인코딩 방식을 취했고 String의 대한 값은 LZ4 압축 알고리즘을 사용했으며 좀 더 압축률을 높이고자 번역본은 SNAPPY를 사용했다.
-- query with impala
CREATE TABLE blog_posts
(
user_id STRING ENCODING DICT_ENCODING,
post_id BIGINT ENCODING BIT_SHUFFLE,
subject STRING ENCODING PLAIN_ENCODING,
body STRING COMPRESSION LZ4,
spanish_translation STRING COMPRESSION SNAPPY,
china_translation STRING COMPRESSION ZLIB,
PRIMARY KEY (user_id, post_id)
) PARTITION BY HASH(user_id, post_id) PARTITIONS 2 STORED AS KUDU;PK는 B-Tree 구조로 별도로 저장되며, PK에 BIT_SHUFFLE 인코딩을 적용하는 것이 효율적인지는 확실하지 않다. 연속되는 값이 처리되는 경우 B-Tree 구조에서 효율적이지 않을 가능성이 크다. 그러나 이러한 인코딩 및 압축 기법을 통해 쿼리 속도가 비약적으로 향상될 수 있다는 점은 분명하다.
압축 알고리즘
GZIP
Snappy보다 더 많은 CPU 리소스를 사용하지만 더 높은 압축을 할 수 있다. 그러나 압축률이 높기 떄문에 자주 사용하지 않는 콜드 데이터에 적합하다.
Deflate 알고리즘에서 헤더 몇개와 체크섬을 더한것이므로 상세한 설명은 Deflate를 참고한다.
허프만 코딩
허프만 코딩은 허프만 코딩 그 자체로 쓰이지 않는다. 예를 들어 허프만 코딩 + LZ77 압축 = Deflate를 쓴다.
예시로 들 수 있는 가장 적합한 예시는 Nvidia의 GPU를 위한 고속 압축 라이브러리이다.
(https://developer.nvidia.com/nvcomp 참조)
Nvidia는 압축 알고리즘을 Deflate를 변형한 Gdeflate로 GPU 전용 압축 알고리즘을 따로 만들었다.
허프만 코딩은 빈도수가 높은 데이터는 짧은 코드로, 빈도수가 낮은 데이터는 긴 코드로 변환하여 전체 데이터를 더 효율적으로 저장하는 방식이다.
- 빈도 분석 (분석해야 하므로 실시간에는 효율적이지 않음)
- 우선선위 큐 (빈도수가 높다면 우선순위 높음)
- 이진 트리 생성 (우선순위 큐에서 가장 빈도수가 낮은 두 문자를 결합해서 새로운 트리 생성 → 반복)
- 트리 루트에서 각 문자를 향해 이동할때마다 왼쪽으로 가면 0 오른쪽으로 가면 1로 할당 → 이진코드 생성
LZ77
중복된 데이터를 찾고 압축하는 방식이다. 윈도우 방식(생각하는 SQL의 윈도우 함수가 맞다)으로 처리하여 현재 처리중인 문자열에서 이전에 등장한 문자열을 참조하여 압축을 수행한다.
- 중복되는 문자열을 찾아서 버퍼 등등 ~~ 작업을 수행하면서 효율적이게 만듬
예를들어서 “ABABABAB” 라는 데이터가 있다면 <offset, length, character> 의 형태로
<0, 0, A> <0, 0, B> <1, 1, > <1, 2, > <1, 1, > <1, 2, > 라는 데이터로 변형된다.
근데 8바이트 문자열이 14바이트가 되었으므로 이 예시에는 효과적이지 못한데 중복된 데이터가 많을 경우 효과적일 것으로 예상된다.
Deflate
LZ77과 Huffman 코딩을 결합하여 효율적으로 데이터를 압축하는 방식이다. GZIP에서 사용하는 압축 방식으로 잘 알려져 있다.
- 데이터 블록 분할
- 입력 데이터를 여러 블록으로 나누어 처리하고 이 블록은 독립적으로 압축
- LZ77에서 반복되는 패턴을 찾고 (offset, length)형태로 기록하여 압축한다
- Huffman코딩을 사용하여 빈도가 높은 문자는 짧은 코드로, 빈도가 낮은 문자는 긴 코드로 표현한다.
Snappy
구글에서 2011년 자체 개발한 압축 라이브러리이다. 압축률을 적당한 수준으로 제공하면서 빠르게 압축하고 해제하는 것을 목표로 한다. 범용적으로 Database에서는 기본값으로 사용하고 있다 (혹은 LZ4)
Lz4
LZ77 계열 알고리즘을 이용하여 데이터를 압축한다.
Snappy와 압축률은 비슷하거나 조금 낮지만 훨씬 빠르게 압축하며 압축해제한다. (Snappy의 2배)
Zstd
GZIP과 비슷한 압축률을 제공하지만 압축 해제할 때는 더 빠르다.
마치며
각 데이터베이스의 특징을 살펴보며 MongoDB는 Document 형태로 데이터를 저장해 Join 연산에 불리하다는 특징을 알 수 있었다. PostgreSQL은 Toast 저장공간을 통해 Oracle에서 발생하는 Row Chaining과 Row Migration 문제를 방지한다는 점을 알 수 있었다. ElasticSearch는 역방향 인덱스를 사용해 문서 검색에 효율적이지만, Join 연산이 불가능하다는 특징을 알 수 있었다. Kudu는 열 기반 스토리지 시스템으로 설계되어 데이터 분석에서 높은 성능을 제공한다는 점을 알 수 있었다. 또한 대용량 데이터를 위해서 파일포맷도 더 빠르고 더 효율적인 것들이 많이 나오는것 같다. 예를 들어, Parquet는 열 기반 저장 포맷으로 데이터 분석 및 처리 성능에서 표준으로 자리 잡았다. Parquet는 효율적인 데이터 압축과 인코딩 방식을 통해 저장 공간을 절약하며, 동시에 대규모 데이터 세트에 대해 뛰어난 쿼리 성능을 제공한다. 최근에는 Vortex(https://github.com/spiraldb/vortex) 같은 새로운 파일 포맷도 주목받고 있다. Vortex는 대용량 데이터 처리에서 더 나은 성능과 유연성을 목표로 설계된 파일 포맷으로, 복잡한 데이터 워크플로우를 간소화하고, 효율적인 저장 및 분석을 가능하게 한다. 이러한 파일 포맷의 발전은 데이터 처리 기술이 데이터 집약적인 환경의 요구를 충족하기 위해 끊임없이 진화하고 있음을 보여준다. 익숙한 것들을 사용하는 것보다 비즈니스에 맞게 올바른 데이터베이스를 사용하는 것을 다시금 느끼게 된다.
