이 글에 대해서
- 이전 글 no offset query로 Paging 성능 개선하기와 이어지는 내용입니다.
- DB Index에 대한 간단한 설명과 Spring Data Jpa에서의 활용, Ngrinder를 통한 성능 확인에 대한 내용이 담겨있습니다.
1. DB Index
- MySQL InnoDB 기준으로 설명합니다.
- DB Index 자료구조에 대해서 참고하고, 공부할 수 있는 좋은 글들이 많이 있어서 간략하게만 설명합니다.
B+Tree
- 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조입니다.
- 기존 B-Tree와 다르게 leaf node에만 데이터를 저장하는 구조입니다.
- 리프 노드간에는 Doubly Linked List형태로 previous, next node에 대한 정보를 가지고 있습니다.
- 이러한 점이 B+Tree가 DB의 Index의 자료구조로 활용되는 것이며, 해쉬테이블과 다르게 순차적인 탐색에 좋은 성능을 보입니다.
- B+Tree에 데이터들이 삽입되고, 수정될 때마다 index의 key(column)으로 데이터를 정렬하게 됩니다.
2. Index 적용해보기
JPA에서 Index 생성하기
- Entity 클래스에
@Table어노테이션을 통해서 설정할 수 있습니다.

- 지도의 name(cloumn)에
map_name_idx라는 index를 생성합니다.
쿼리를 통해서 Index 확인하기
show index from map;
- map_name_index를 확인할 수 있습니다.
쿼리가 인덱스를 타는지 확인하기
- Spring Data Jpa를 활용한 기존 NamedQuery입니다.
Slice<Map> findMapsByFullDisclosureAndIdGreaterThanAndNameContaining(Pageable pageable, Boolean fullDisclosure, Long id, String name)
mapRepository.findMapsByFullDisclosureAndIdGreaterThanAndNameContaining(PageRequest.ofSize(10), true, 300, "ron");- 실제 작동하는 쿼리라면?
ron이라는 단어가 포함되는 데이터를 찾습니다.
select * from map where full_disclosure = true and id > 300 and name like '%ron%' limit 10;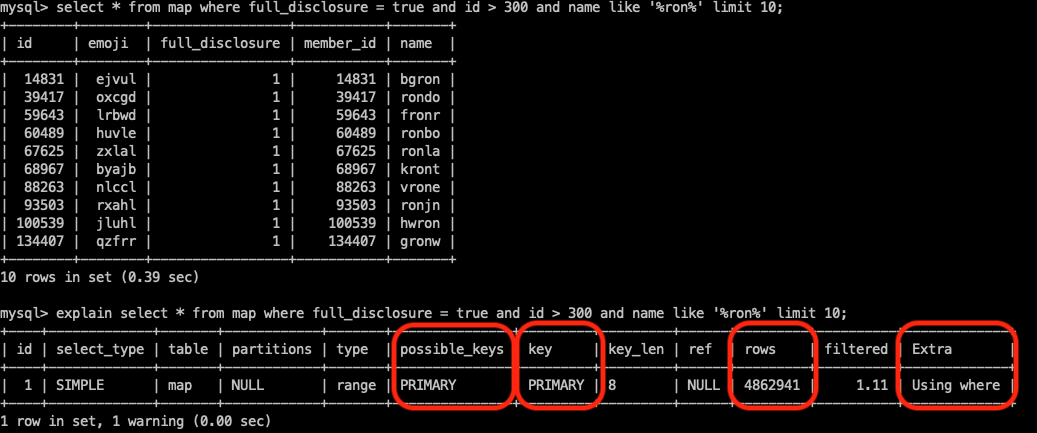
- explains 명령어를 통해서 쿼리 실행 계획에 대해서 확인해봅니다. (예상치)
map_name_idx인덱스를 타지 않고서 Primary key로 생성된(Clustered Index)를 통해서 데이터를 찾을 것으로 예상합니다.- 또한, rows 필드를 확인해보면, 4862941개의 행을 조사할 것으로 예측합니다.
왜 Index를 타지 못할까?
- 위에서 B+Tree에 대해서 설명했던 것처럼 인덱스에는 key가 되는 컬럼을 정렬합니다.
- 현재 들어가있는 더미 데이터들은 무작위 알파벳 5글자로 구성되어있습니다.
- 그렇기 때문에 알파벳순으로 data들이 정렬되어있습니다.
- 하지만 앞선 like 쿼리에서 '%'가 앞과 뒤에 붙어있다면, index의 순차탐색이 불가능합니다.
- 물론 앞에만 붙어있더라도(검색조건으로 끝나는 데이터) 순차탐색이 불가능합니다.
- ron이라는 단어가 어느 지점에 포함되어있을지 전혀 알 수 없기 때문입니다.
- 그래서 id가 300이상인 데이터에 대해서 조건에 맞는 데이터를 10개까지 탐색하게 됩니다.
- 전혀 포함되지 않은 숫자나 한글로 like 쿼리를 보낸다면 id가 300 이상인 지도의 모든 데이터를 조회해야할 것입니다.
- 아래와 같이 데이터를 조회하는데 27.35초가 걸리는 것을 확인할 수 있습니다.

like 쿼리에서 인덱스를 타게하는 방법은?
- 정렬된 데이터를 순차적으로 읽을 수 있도록 쿼리를 작성하는 것입니다.
Slice<Map> findMapsByFullDisclosureAndIdGreaterThanAndNameStartingWith(Pageable pageable, Boolean fullDisclosure, Long id, String name)
mapRepository.findMapsByFullDisclosureAndIdGreaterThanAndNameStartingWith(PageRequest.ofSize(10), true, 300, "ron");ron과 같은 찾고자하는 단어로 시작하는지로 조건을 걸어둡니다.
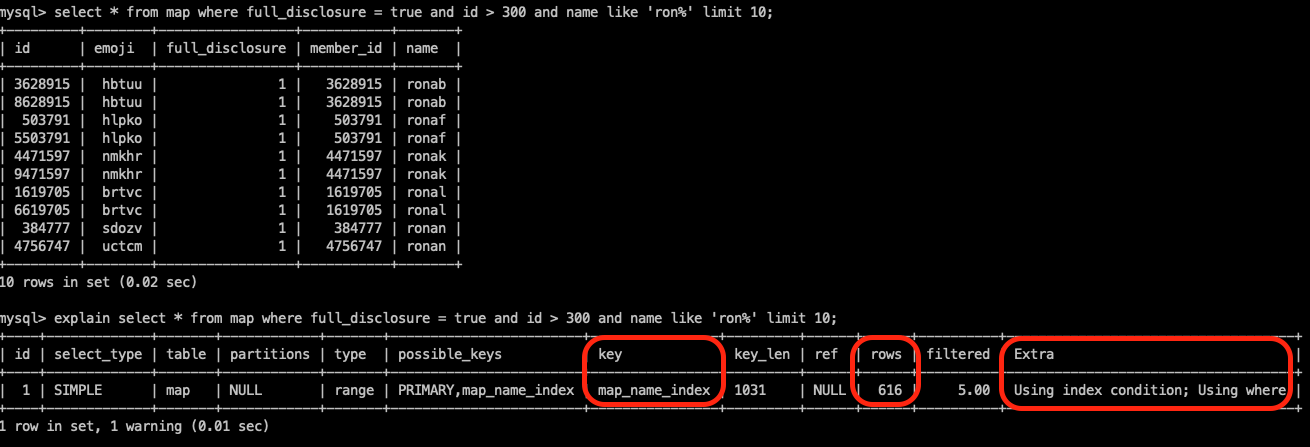
select * from map where full_disclosure = true and id > 300 and name like 'ron%' limit 10;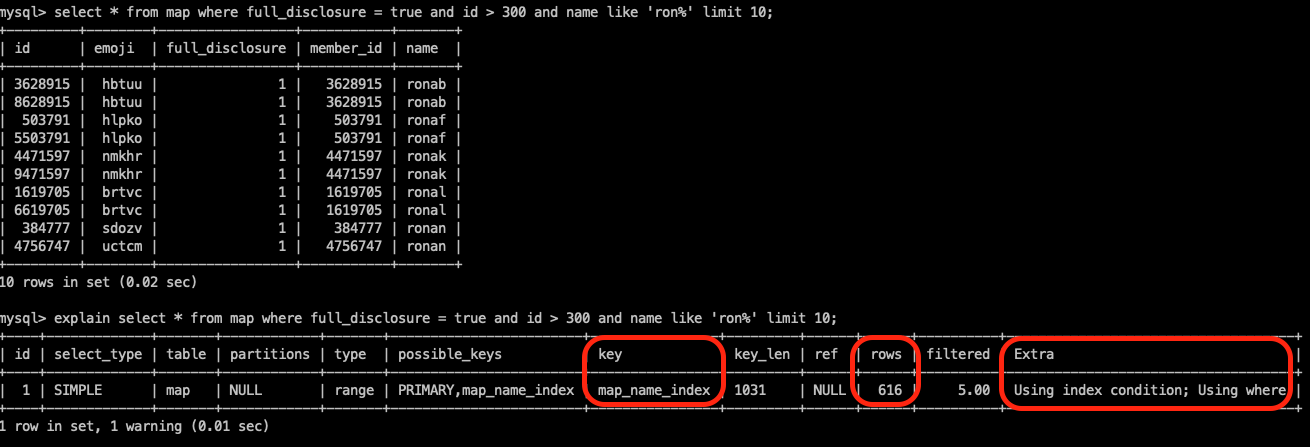
-
explain을 통해서 확인해보면 key로
map_name_idx를 활용하고, 616개의 데이터 행을 읽을 것으로 예상합니다. -
또한, Index condtion을 활용하는 것을 볼 수 있습니다.
-
또한 아까와 같이 존재하지않는 조건을 검색했을 때도, 아주 빠른 속도로 응답하는 것을 확인할 수 있습니다.

3. NGrinder로 성능 확인해보기
- 이전 글과 같은 조건으로 name 검색조건을 알파벳 소문자 3글자의 단어로 요청하도록 script를 작성했습니다.
- Agent 1 / Vuser 102 / test 5분
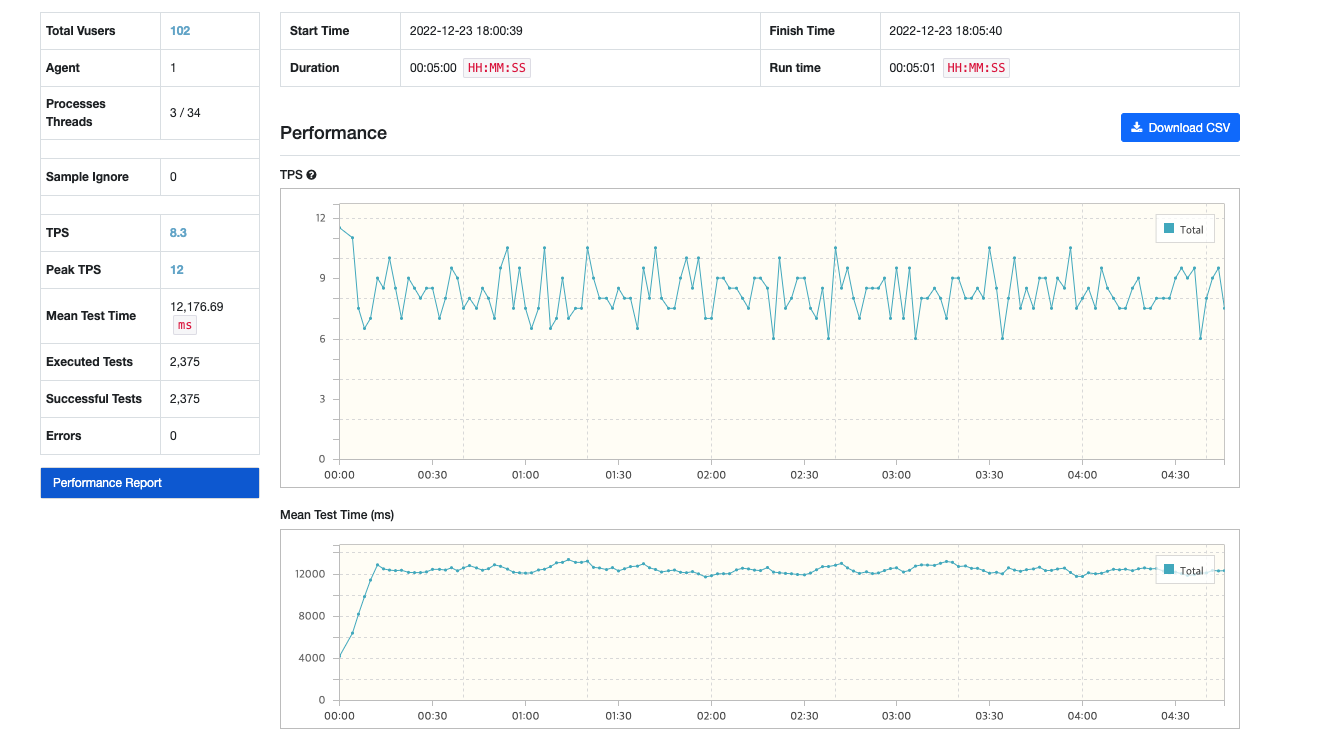
NameContaining (%{name}%)
-
TPS가 8이며, MTT가 12초입니다.
-
지도를 검색할 때, 평균적으로 12초정도의 응답속도가 나오게 되는 것입니다.
- 아마 실제 사용자라면 서버 오류인줄 알고 지속적으로 새로고침 혹은 재요청을 시도할 것입니다.
- 또한, 테스트시 요청하는 검색조건이 영어 알파벳으로만 했지만, 숫자와 한글이 포함된다면 Connection timeout과 같은 에러가 지속적으로 발생했을 확률이 높습니다.
NameStartingWith ({name}%)
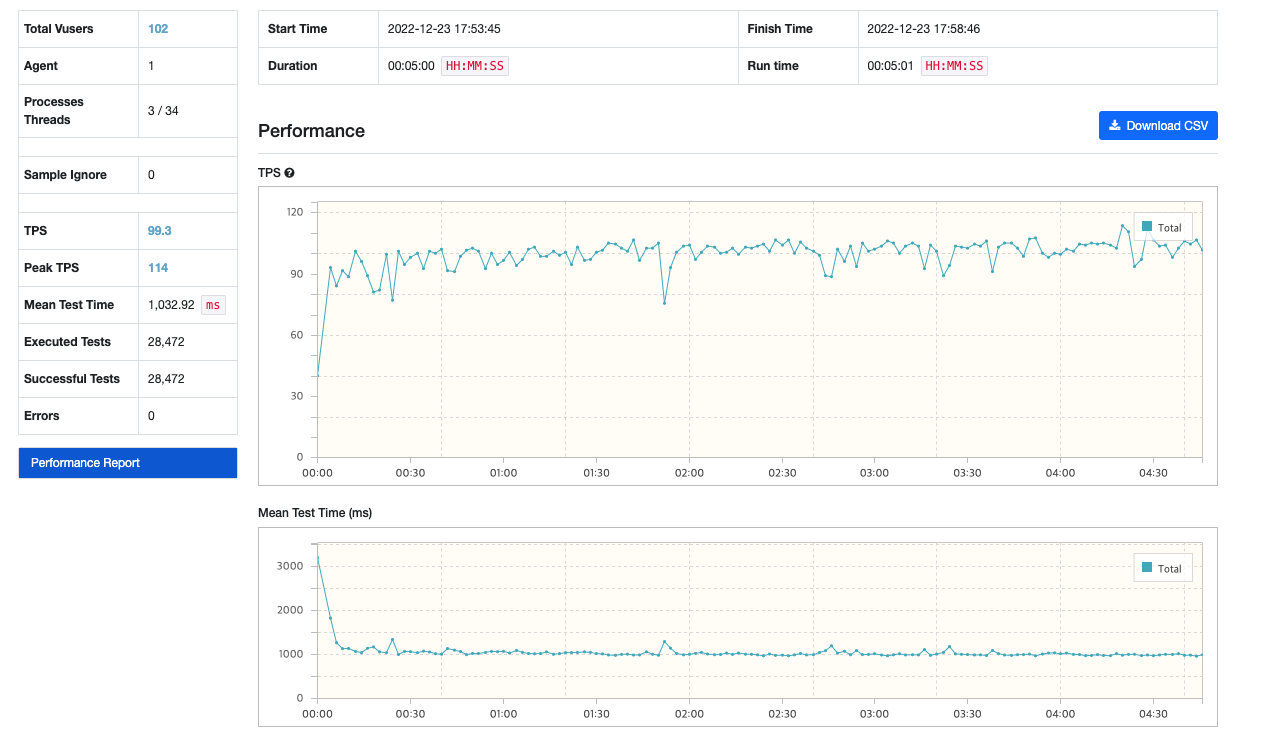
- TPS가 99 / MTT가 1초대로 10배 가까운 성능의 개선을 확인할 수 있었습니다.
결론
- 지도 이름 검색 기능에 대해서 index를 적용하고, 성능 개선을 적용했습니다.
- 추후 다른 기능에 대한 성능 리팩토링과 DB index, 쿼리 성능에 대해서 더 학습하고 핵심적인 내용을 정리해보겠습니다.
Index 사용
- DB Index의 경우 조회보다 추가/수정이 잦은 테이블의 경우에는 데이터를 계속 정렬해야하기 때문에 그 효율이 좋지않을 수 있습니다.
- 그렇기 때문에 index 사용을 선택할 때, 고려해야하는 부분들이 있다는 것을 참고하셨으면 좋겠습니다.
- 지속적으로 DB와 쿼리에 대해서 공부해야겠습니다.
시작되는 단어가 아닌 포함하는 단어로 검색을 하고 싶어요!
- 엘라스틱서치 검색 엔진을 적용해보자. 언젠가 공부해볼 키워드!
References
- https://jojoldu.tistory.com/243
- https://devonce.tistory.com/52
- 산토리의
인덱스를 탈까?퀴즈

차곡차곡