DFS(Depth First Search)
의미 그대로 깊이 우선 탐색하는 알고리즘이다.
DFS에서는 그래프에서 깊이를 우선적으로 하여 가장 깊은 곳까지 확인하고 다른 루트를 확인한다. 하나의 루트를 정해 막다른 길을 만나면 다른 루트를 찾는 미로찾기라고 생각하면 쉽다.
recursion 기반의 DFS pseudo code
Algorithm dfs(G, v)
visited[v] = true
traverse.append(v)
for (w adjacent to v)
if (!visited[w])
dfs(g, w)- 현재 노드에 인접한 노드 중에서 방문하지 않은 노드를 방문한다.
stack 기반의 DFS pseudo code
Algorithm dfs(graph, v)
stack.push(v)
while (stack)
v = stack.pop()
traverse.append(v)
if (!visited[v])
visited[v] = true
stack.push(unvisited adjacent nodes)- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 대해 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 위의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
특징
- 노드가 n개, 간선이 m개일 경우 O(n+m) time이 소요된다.
- 현 경로상의 노드만 저장하기 때문에 메모리 소모가 적다.
- 해를 찾으면 탐색을 끝내버리므로, 찾아닌 해가 최적의 경우가 아닐 수 있다.
BFS(Breadth First Search)
의미 그대로 너비 우선 탐색하는 알고리즘이다.
BFS는 그래프에서 가까운 노드부터 탐색하며, 모든 노드들을 한 번만 방문한다.
queue 기반의 BFS pseudo code
Algorithm bfs(G, v)
visited[v] = true
Q.enqueue(v)
while (Q)
v = Q.dequeue()
for (w adjacent to v)
if (!visited[w])
visited[w] = true
Q.enqueue(w)- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드와 인접한 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 위의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
특징
- 노드가 n개, 간선이 m개일 경우 O(n+m) time이 소요된다.
- 출발노드에서 목표노드까지의 최적의 해를 보장한다.
- 경로가 매우 길 경우에는 많은 메모리 공간을 필요로 한다.
DFS, BFS 과정
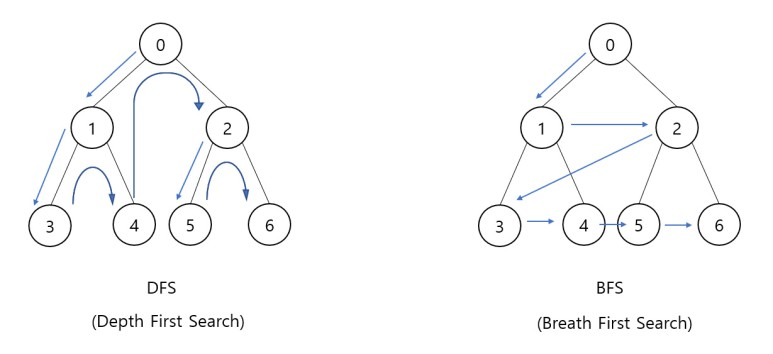
위의 그림을 통해 DFS, BFS의 차이를 살펴보자.
DFS
- 시작노드인 0을 스택에 넣는다.
- 스택의 top에 존재하는 0의 인접 노드 중 1을 스택에 넣고 방문처리한다.
- 스택의 top에 존재하는 1의 인접 노드 중 3을 스택에 넣고 방문처리한다.
- 스택의 top에 존재하는 3의 인접 노드 중 방문하지 않은 노드가 없으므로 스택에서 3을 빼낸다.
- 스택의 top에 존재하는 1의 인접 노드 중 4(방문하지 않은 노드)을 스택에 넣고 방문처리한다.
- 스택의 top에 존재하는 4의 인접 노드 중 방문하지 않은 노드가 없으므로 스택에서 4을 빼낸다.
- 스택의 top에 존재하는 1의 인접 노드 중 방문하지 않은 노드가 없으므로 스택에서 1을 빼낸다.
위의 방법을 나머지 노드들에 대해 적용하면, 0 > 1 > 3 > 4 > 2 > 5 > 6의 순서로 탐색하는 것을 알 수 있다.
BFS
- 시작노드인 0을 큐에 넣는다.
- 큐의 top에 존재하는 0의 인접 노드 1, 2를 큐에 넣고, 큐의 top에 존재하는 0을 방문처리 한 후 빼낸다.
- 큐의 top에 존재하는 1의 인접 노드 3, 4를 큐에 넣고, 큐의 top에 존재하는 1을 방문처리 한 후 빼낸다.
- 큐의 top에 존재하는 2의 인접 노드 5, 6을 큐에 넣고, 큐의 top에 존재하는 2를 방문처리 한 후 빼낸다.
- 큐의 top에 존재하는 3의 인접 노드 중 방문하지 않은 노드가 없으므로, 3을 방문처리 한 후 큐에서 빼낸다.
- 큐의 top에 존재하는 4의 인접 노드 중 방문하지 않은 노드가 없으므로, 4를 방문처리 한 후 큐에서 빼낸다.
위의 방법을 나머지 노드들에 대해 적용하면, 0 > 1 > 2 > 3 > 4 > 5 > 6의 순서로 탐색하는 것을 알 수 있다.
