
데이터를 분석하기 위해서 가장 먼저 해야할 일은 데이터를 불러오는 것이다.
Python으로 분석을 하게 된다면 Pandas와 Numpy 라이브러리를 많이 사용하게 된다.
pandas 라이브러리를 이용하면 .csv .xlsx과 같은 파일을 쉽게 불러올 수 있다.
목차
- 파일 불러오기
- pd.read_csv - parameter
- 파일 내보내기(저장)
1. 파일 불러오기 : pd.read_csv()
url 링크를 통해 불러오기
import pandas as pd
url = 'https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/kt%26g/kt%26g_0.csv'
df = pd.read_csv(url)
df.head()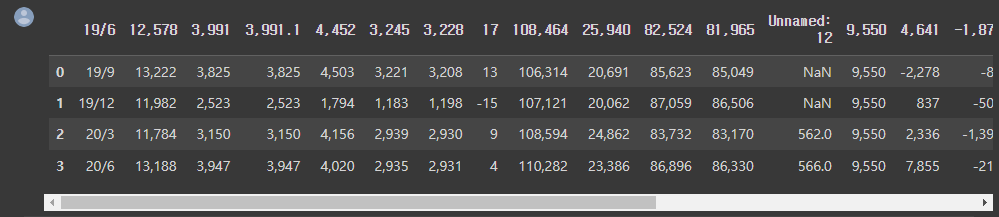
URL link를 url 변수에 저장 후 'pd.read_csv(url)'와 같은 형식으로 df 변수에 저장한다.
'df.head()'를 통해 가지고온 데이터의 head부분을 확인할 수 있다.
Google Drive에 저장된 파일 불러오기
from google.colab import drive
drive.mount('/content/drive')위 코드를 통해 Colab과 Google Drive를 연결한다.
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/project2/smoking.csv')
df.head()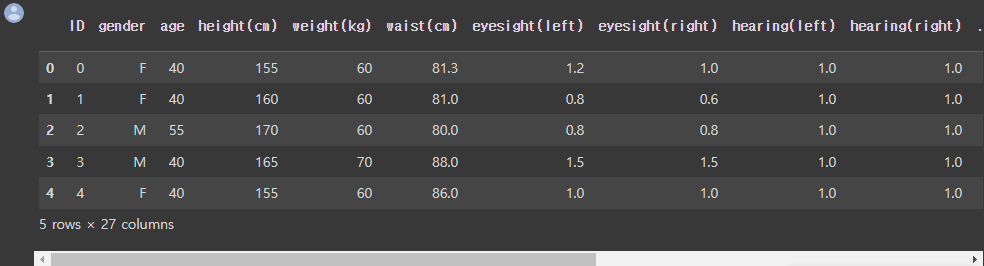
Google Drive와 연결 후 마찬가지로 pandas 라이브러리를 이용하여 저장된 파일을 불러올 수 있다.
2. pd.read_csv - parameter
pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default, delimiter=None, header='infer', names=NoDefault.no_default, index_col=None, usecols=None, squeeze=None, prefix=NoDefault.no_default, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)

n번째 행까지 불러오기 : nrows
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', nrows=5)nrows = 5를 사용했기 때문에 첫 행부터 5번째 행까지의 데이터를 불러온다.

Column명으로 사용할 행 지정 : header
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', header=5)header로 지정한 번호의 row가 column이 되고 그 아래 row들의 값들을 불러온다.
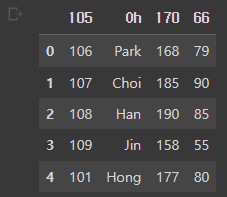
index 지정 : index_col
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', index_col=0)첫번째 column을 index로 사용하여 ID 열이 index가 되었다.
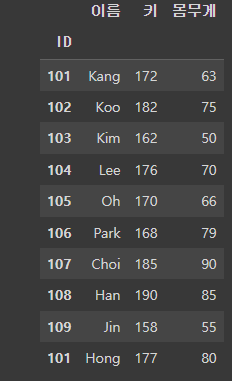
column명 지정 : names
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', names = ['아이디','name','Height','Weight'])names를 통해 column명을 직접 지정해줄 수 있다.
column명을 직접 지정해주면 불러온 데이터의 첫번째 행이 Column이 되지 않는다.
결측값을 불러올지 여부 : na_filter
- 결측치 불러오기 na_filter = True
- 결측치 제외하기 na_filter = False
불러올 행 개수 정하기 : nrow, skiprows, skipfooter
- nrow : n개의 행 불러오기 (처음 ~ n번째 행까지 불러오기)
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', nrows=5)nrows = 5를 사용했기 때문에 첫 행부터 5번째 행까지의 데이터를 불러온다.
- skiprows : 특정 줄 제외하고 불러오기
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', skiprows=5)5개의 행을 제외하고 불러와서 Column명으로 사용하려 했던 첫번째행도 삭제 되었다.
names 파라미터를 이용하여 Column명을 지정하여 해결할 수 있을 것이다.
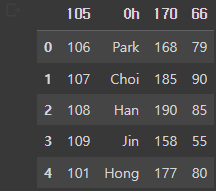
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', skiprows=[1,3,5])skiprows=[1,3,5] 다음과 같이 이용한다면 선택한 행을 제외한 후 불러올 수 있다.
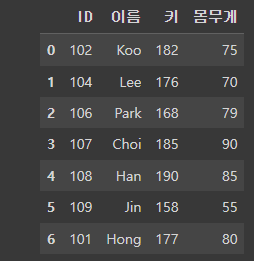
- skipfooter : 뒤에서 n개 제외하고 불러오기
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', skipfooter=5)뒤에서 5개의 행을 제외하고 데이터를 불러온다.
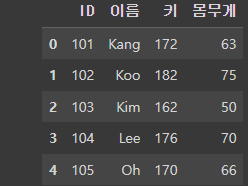
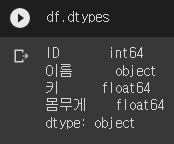
data type 설정 : dtype
df = pd.read_csv('/content/drive/MyDrive/basic1.csv', dtype = {"ID":int,"이름":str,"키":float,"몸무게":float})dtype을 이용하여 각 Column의 데이터 타입을 지정해 줄 수 있다.
유니코드 디코드 에러 (UnicodeDecodeError: 'utf-8' codec can't decode byte)
df = pd.read_csv('파일명.csv', encoding='CP949')불러온 csv파일과 python의 encoding 설정이 다르면 UnicodeDecodeError가 발생한다.
한글은 'utf-8'코덱을 주로 사용하여 Decoding 오류가 발생한다.
Encoding을 하여 불러온다면 오류를 해결할 수 있다.
3. 파일 내보내기(저장) : to_csv()
df.to_csv('파일명.csv')데이터 불러오는 것과 반대로 만든 데이터프레임을 csv파일로 출력한다.
df -> '파일명'.csv
[참조링크] https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
