
Search Process
색인
- 문서에서 키워드를 찾아 보기 쉽도록 정렬 및 나열한 목록입니다.
- 비유하자면 책의 맨 앞에 있는 목차를 떠올리시면 됩니다.
- 데이터베이스 관점으로 보면 '마치며','들어가며' 같은 목차의 제목은 PK와 같은 레코두를 대표하는 값을 의미하고, 몇번 페이지를 나타내는 것은 실제 데이터 레코드가 존재하는 물리적 주소로 이해하면 될 것 같습니다.
역색인
-
주어진 문장에 키워드를 통해 문서를 찾아내는 방식입니다.
-
비유하자면 책에서 맨 뒤에 나와 있는 찾아 보기와 비슷합니다.
-
역색인 같은 경우는 색인의 비해 검색 성능이 매우 빠릅니다.

데이터베이스에서 fox로 검색을 하고자 한다면 테이블의 row를 하나씩 살피면서 fox가 포함된다면 데이터를 가져오고 아니라면 그다음으로 넘어갑니다.
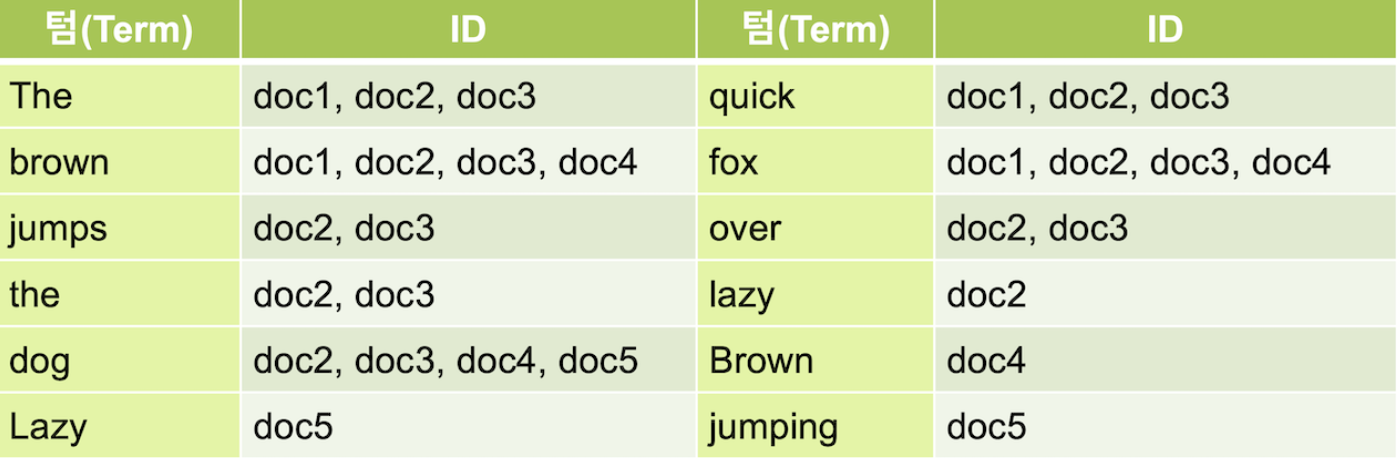
역색인을 사용하는 검색 엔진에서는 추출된 각 키워드를 term이라고 부릅니다.
역색인은 Term이라는 키워드를 추출하고, Term컬럼에 해당하는 데이터를 저장하는 방식입니다. 역색인을 사용하면 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역색인이 가리키는 id의 배열값이 추가되는 것이므로 큰 속도의 저하 없이 여전히 빠른 속도로 검색이 가능합니다.
마치며,,,
검색은 대량의 문서 집합에서 '특정'키워드가 포함된 문서를 찾아내는 행위입니다. 하나하나 살피면서 시간이 지체되는 것보다는 역색인을 이용하여 키워드로 인한 검색으로 문서를 찾는 방법이 찾을때도 편하고, 좀 더 선호하지 않을까 싶습니다. 아직 자세하게는 잘 모르지만 좀 더 알아보면 좋을꺼 같습니다.

개발자가 되기 위한 1인