
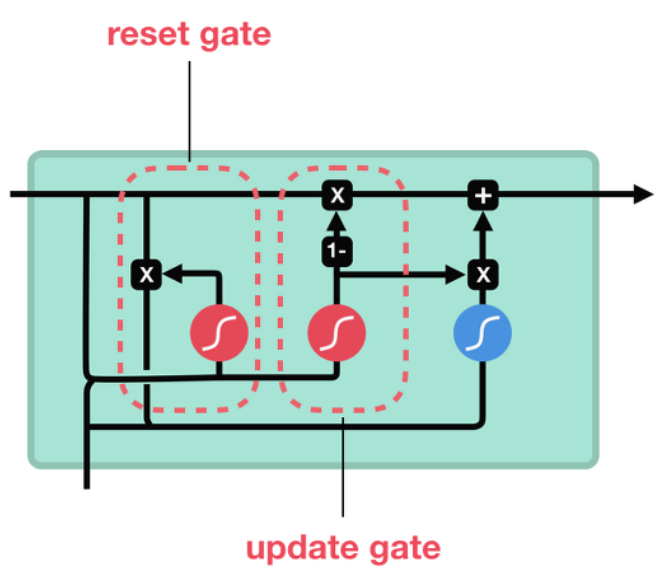
GRU는 LSTM과 비슷한 성능을 보이지만, 차이점은 LSTM은 3개의 Gate를 가지는 반면 Reset Gate(r)과 Update Gate(z)로 이루어져있다.
Reset Gate : 이전 상태를 얼마나 반영할지
Update Gate : 이전상태와 현재상태를 얼마만큼의 비율로 반영할지
Reset Gate
- 이전 상태의 hidden state와 현재 상태의 x를 받아 sigmoid 처리
- 이전 hidden state의 값을 얼마나 활용할 것인지에 대한 정보
Update Gate
- 이전 상태의 hidden state와 현재 상태의 x를 받아 sigmoid 처리
- LSTM의 forget gate, input gate와 비슷한 역할을 하며,
- 이전 정보와 현재 정보를 각각 얼마나 반영할 것인지에 대한 비율을 구하는 것이 핵심이다.
- 즉, update gate의 계산 한 번으로 LSTM의 forget gate + input gate의 역할을 대신할 수 있다.
- 따라서, 최종 결과는 다음 상태의 hidden state로 보내지게 된다.
LSTM vs GRU
GRU와 LSTM 중 어떤 것이 모델의 성능면에서 더 낫다라고 단정지어 말할 수 없으며, 기존에 LSTM을 사용하면서 최적의 하이퍼파라미터를 찾아낸 상황이라면 굳이 GRU로 바꿔서 사용할 필요는 없다.
경험적으로 데이터 양이 적을 때는 매개 변수의 양이 적은 GRU가 조금 더 낫고,
데이터 양이 더 많으면 LSTM이 더 낫다고도 한다.
GRU보다 LSTM에 대한 연구나 사용량이 더 많은데, 이는 LSTM이 더 먼저 나온 구조이기 때문이다.
참고자료

회사와 “함께” 성장하는 개발자