Apache Kafka란?
- 여러 대의 분산 서버에서 대량의 데이터를 처리하는 분산 메시징 시스템
- 메시지를 받고, 받은 메시지를 다른 시스템이나 장치에 보내기 위해 사용됨
- 대표적인 기능
| 기능 | 역할 |
|---|---|
| 데이터 허브 | 여러 시스템 사이에서 데이터를 상호 교환한다. |
| 로그 수집 | BI 도구를 이용한 리포팅과 인공지능 분석을 위해 여러 서버에서 생성된 로그를 수집하고 축적할 곳에 연결한다. |
| 웹 활동 분석 | 실시간 대시보드와 이상 탐지/부정 검출 등 웹에서의 사용자 활동을 실시간으로 파악한다. |
| 사물인터넷 | 센서 등 다양한 디바이스에서 보낸 데이터를 수신해서 처리한 후 디바이스에 송신한다. |
| 이벤트 소싱 | 데이터에 대한 일련의 이벤트를 순차적으로 기록하고 CQRS 방식으로 대량의 이벤트를 유연하게 처리한다. |
현재 우리 팀 상항
- 채팅 서비스를 구현하면서 모든 채팅 서버 인스턴스의 데이터를 하나로 흐르게 하는 데이터 파이프라인을 구축할 필요가 있다.
- 채팅서버에서 푸시서버에서로 푸시를 보낼 때 푸시 요청이 순차적으로 쌓여야 한다.
-> Kafaka를데이터 허브와이벤스 소싱을 목적으로 사용하기로 함
Kafaka vs RabbitMQ
공통점
- 도착한 메시지를 큐에 저장하고 순차적으로 메시지를 소비
- Pub/Sub 패턴을 가지는 메시지 브로커
차이점
- Kafaka는 이벤트 브로커고 RabbitMQ는 메시지 브로커다
메시지 브로커
- pub/sub 구조
publisher가 생산한 메시지를 메시지 큐에 저장하고
저장된 데이터를 consumer가 가져갈 수 있도록 중간 다리 역할을 해주는 브로커 - 서로 다른 시스템 사이에서 데이터를 비동기 형태로 처리하기 위해 사용
- consumer가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터가 삭제됨
이벤트 브로커
- 기본적으로 메시지 브로커의 큐 기능들을 가지고 있음
-> 즉 이벤트 브로커는 메시지 브로커 역할이 가능 - publisher가 생산한 이벤트를 데이터베이스에 저장하듯이 계속 저장
- topic이 event streamer에 저장
- consumer가 이벤트를 다시 읽어갈 수 잇음
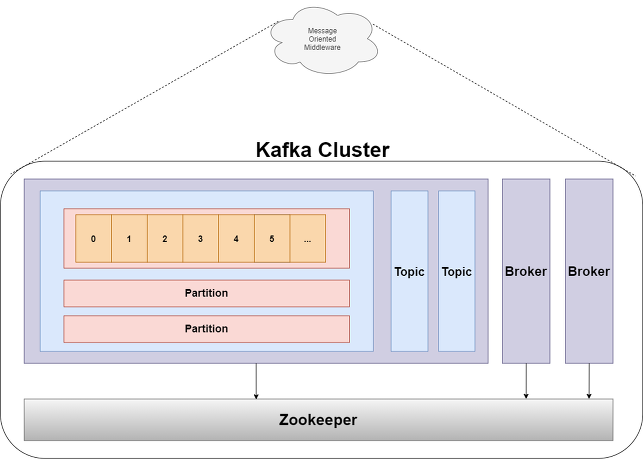
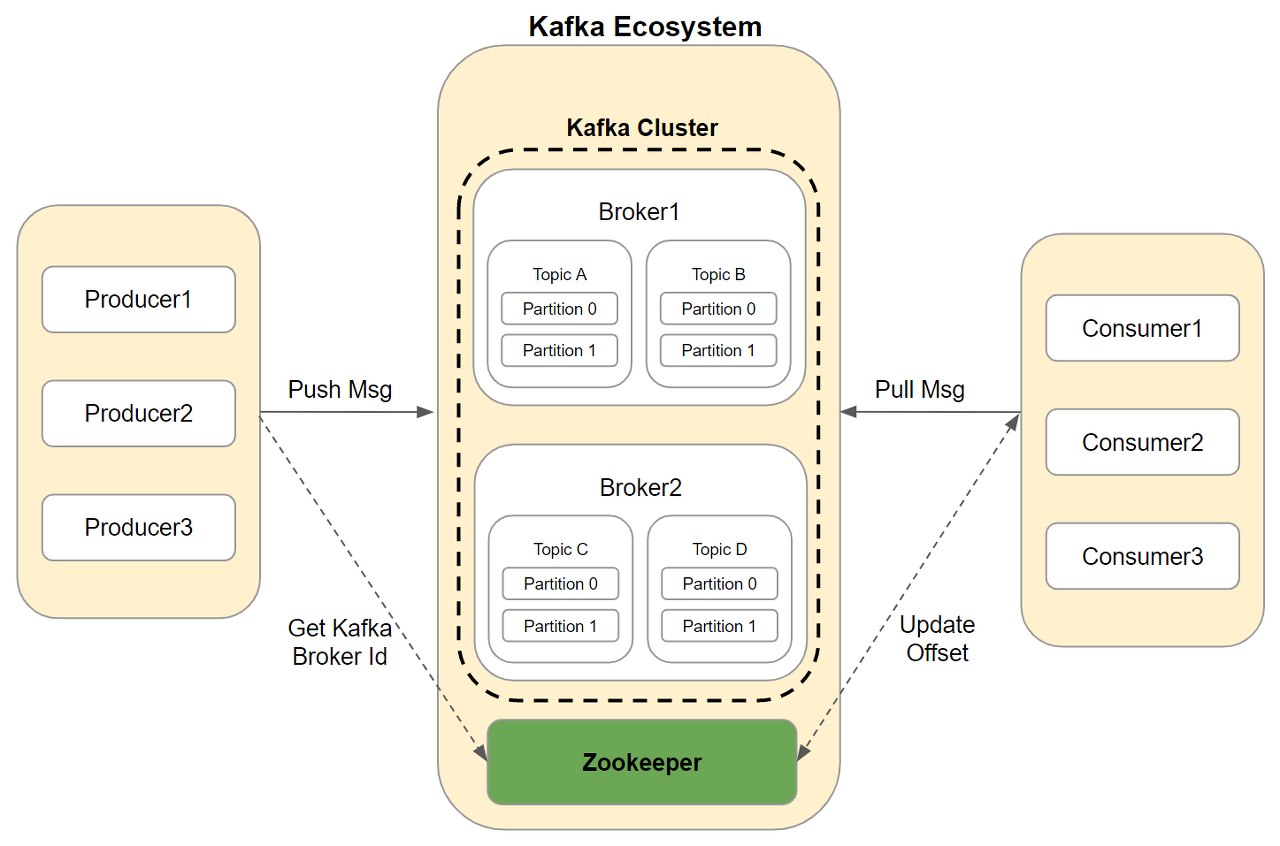
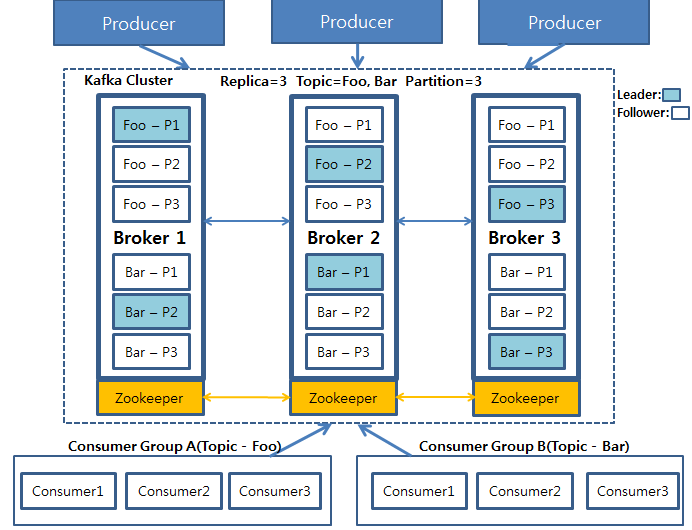
Kafka 아키텍처
Zookeeper
- Broker에 분산 처리된 메시지 큐의 정보들을 관리
- Kafka 서버를 가동하려면 Zookeeper를 먼저 가동해줘야 함
Broker
- Kafka Server를 의미
- 한 클러스터 내에서 Kafka server를 여러 대 띄울수 있음
Topic
- 메시지가 생산되고 소비되는 주제
- ex) 1번방 topic, 날씨 topic
- A 토픽에서 생산된 메시지는 A 토픽을 구독한 사람에게만 보여짐
Partition
- Topic 내에서 메시지가 분산되어 저장되는 단위
- 한 Topic에 Partition이 여러개 있다면, 여러개의 Partition에 대해서 메시지가 분산되어 저장됨
- Partition 내에서는 Queue 방식으로 저장되므로 순서를 보장해 줌
- 단 Partition끼리는 메시지 순서를 보장해주지 않음
Log
- Partition의 한 칸을 Log라 함
- key, value, timestamp로 구성됨
Offset
- Partition의 각 메시지를 식별할 수 있는 유니크한 값
- 메시지를 소비하는 Consumer가 읽을 차례를 의미하므로 Partition마다 별도로 관리됨
- 0부터 시작하여 1씩 증가
참고 주소
Apache Kafka 도입기-KimYeonghun
🙈[Kafka] 기본 개념잡기🐵-✌ victolee
아파치 카프카(Apache Kafka) 아키텍처 및 동작방식, 파티션 읽기 쓰기
