[2주차 목표]
1. 판다스와 데이터프레임 사용법에 대해 복습한다.
2. 형태소 분석과 워드 클라우드를 실습해본다.
3. 머신러닝 기법을 이용해 분류하기를 실습해본다.
👉 텍스트 마이닝을 위한 기본 세팅
○ 사용하는 패키지
- KoNLPy : 한국어 텍스트 처리에서 문자열을 토큰화 하기 위해서 사용하는 형태소 분석기
- Counter : 단어들을 카운트할 때 사용
- WordCloud : 위드 클라우드 패키지
- np.hstack, np.concatenate : Numpy 함수
○ Colab에서 한글 사용을 위한 세팅
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()- 코드 실행 후 런타임 다시 시작
○ csv 파일 업로드와 데이터 로드
- Colab에는 파일이 없으므로 기존의 csv 파일을 드래그/드롭으로 업로드 해준다. :
news_data.csv - Pandas를 이용하여 데이터프레임으로 저장
import pandas as pd
# news_data.csv 파일을 읽어드림
df = df.read_table('news_data.csv', sep=',')
df
👉 텍스트 마이닝
○ 불필요한 데이터 (결측값, 중복)제거
- 결측값 확인하기
데이터프레임이름.isnull().sum() Null 값 카운트(결측값, 존재하지 않는 값으로 결측값이라고 부르며, 실제 있는 값이 아님에도 특정행으로서 존재하는 경우). 항상 데이터를 분석하기 전에 데이터에 결측값이 존재하는 지 확인해야 한다.
# 각 열마다 존재하는 결측값 개수 카운트
print(df.isnull().sum())
# Result
news 0
code 0
dtype: int64
# sum()은 true인 값이 몇개인지 보는 함수# Null 값이 있는 경우 제거하기
데이터프레임이름.dropna(inplace=True)- 중복 확인하기
데이터프레임이름['열의이름'].nunique()는 특정 열에서 중복을 제외하고 데이터를 카운트 했을 때 총 데이터 수를 알려준다. (실제로 제거해주는 것은 아님)
# 유니크한 샘플의 수 또는 중복을 제거한 샘플의 수
print(df['news'].nunique())
# Result
553원래 데이터가 600개 였으므로 중복이 47개 존재한다는 말이다. 실제로 제거하면 553개가 남는다.
- 중복 데이터 제거
데이터프레임이름.drop_duplicates(subset=['중복을체크할열'], inplace=True) 중복이 있다면 해당 행 전체를 제거한다.
inplace=True는 데이터 원본값에서 제거가 된다는 의미이며, 이 코드가 빠지면 원본데이터는 그대로 남고 결과를 다른 변수에 할당할 수는 있다.
df.drop_duplicates(subset=['news'], inplace=True)
len(df)
# Result
553- 데이터의 분포 확인하기
데이터프레임이름['열의이름'].value_counts() 특정 열에 존재하는 각 종류의 값을 카운트하여 숫자로 출력.
df['code'].value_counts()
# Result
code
IT/과학 180
사회 192
생활/문화 181- 데이터분포 시각화하기
데이터프레임이름['열의이름'].value_counts().plot(kind='bar') 해당 열에 존재하는 각 종류의 값들을 카운트하여 바 차트 (bar chart)로 시각화해준다.
df['code'].value_counts().plot(kind = 'bar')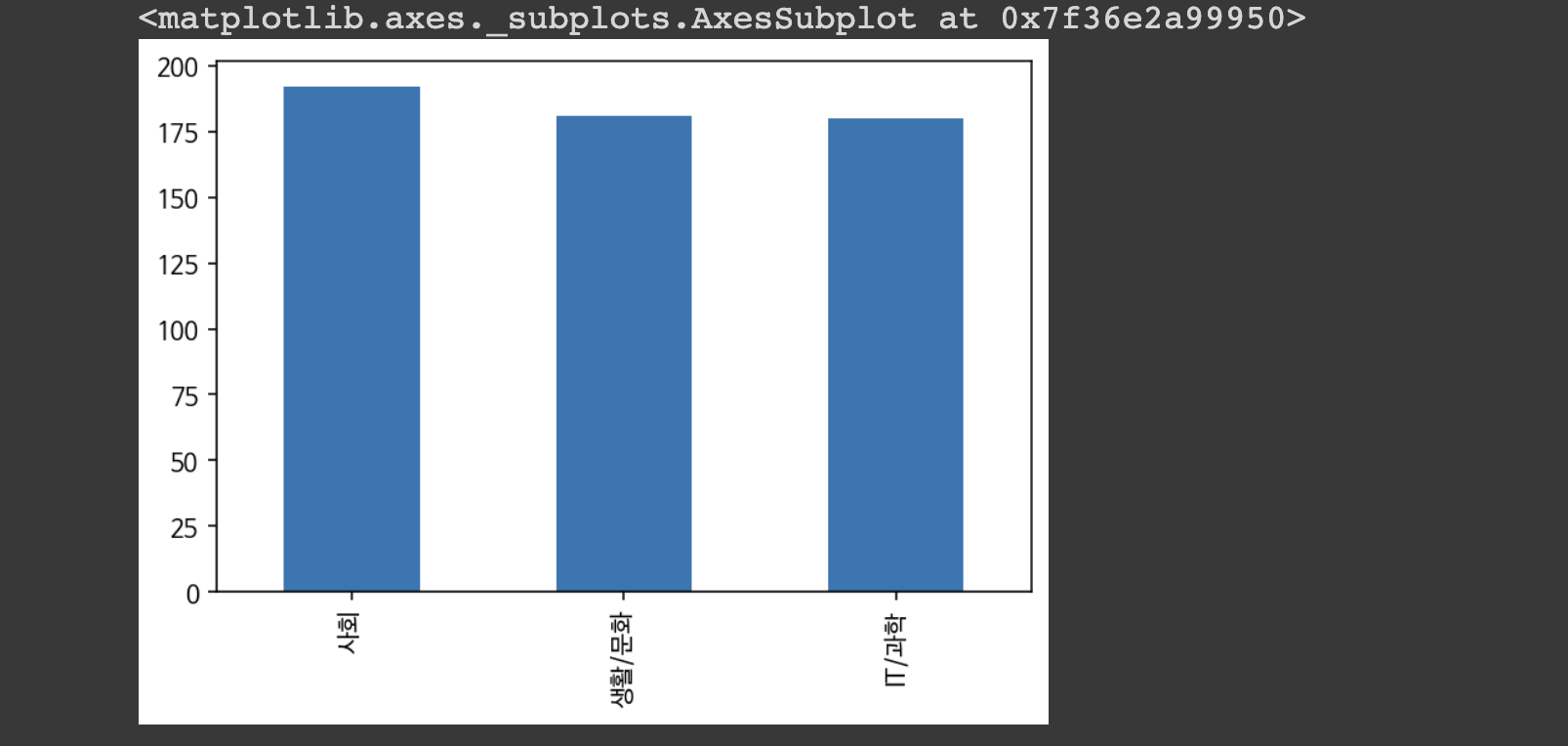
○ 형태소 분석
한국어 텍스트를 처리할 때 주로 형태소 분석기를 사용하여 자연어 처리를 한다. 이를 사용하여 형태소 단위 또는 명사 단위를 뽑아낼 수 있다. 이를 문장보다 작은 단위인 토큰 단위로 뽑아냈다고 하여 토큰화라고 한다.
- 형태소 분석기
KoNLPy설치
!pip install konlpyKoNLPy에는 다양한 형태소 분석기가 존재하며 그 중 하나인 Okt를 사용하여 명사만 추출한다.
# 아래 코드는 konlpy라는 패키지 안에 tag 모듈 안에 있는 Okt라는 모듈을 임포트 합니다.
# konlpy 안에 tag 안에 Okt가 있는 이런 상하 관계는 누가 정했냐구요? konlpy 개발자가 그렇게 정했고,
# 저는 지금 konlpy 홈페이지에 적혀져 있는 사용법대로 사용하고 있는 겁니다.
# konlpy 홈페이지 : https://konlpy-ko.readthedocs.io/ko/v0.4.3/
# from 패키지.모듈 import 하위모듈
# 이것은 패키지를 임포트하는 전형적인 방식입니다.
from konlpy.tag import Okt- 형태소 분석
# 형태소 분석 예시
# 명사 분석기에 이름을 준다.
tokenizer = Okt()
kor_text = '...'
# 결과 찍어보기
print(tokenizer.nouns(kor_text))데이터프레임이름['열의이름'].apply(동작코드)를 이용하면 해당 열에 있는 각 행에 '동작코드'를 전부 적용할 수 있다.
# 'news'열에 있는 기사를 토큰화 함수를 적용하여 'tokenized'열에 저장한다.
df['tokenized'] = df['news'].apply(tokenizer.nouns)- 불용어 제거
불용어 (stopwords)란, 데이터 전체에서 꽤 많이 등장하지만 실제로는 별로 중요하지 않은 단여이다. 한국어에서 ~는, ~가 같은 조사나 접사 또는 데이터 특성상 자주 등장할 수 밖에 없는 단어 (뉴스에서 '최근', '기자' 등)이다.
# 불용어 리스트 만들기
stop_words = ['기자', '최근', '무단', '배포'...]리스트 컴프리헨션
python에서 리스트를 사용할 때 많이 사용되는 문법이다. 조건에 맞는 item만을 남기는 것을 목표로 사용한다.
#리스트 컴프리헨션 예시 test_list = ['경찰서', '상해', '혐의', '씨', '구속', '수사', '일'] remove_word_list = ['경찰서', '구속'] test_list = [item for item in test_list if item not in remove_word_list and len(item) > 1] print(test_list) # Result ['상해', '혐의', '수사']
# 불용어 제거 코드
df['tokenized'] = df['tokenized'].apply(lambda x: [item for item in x if item not in stop_words and len(item) > 1])
✋ lamda x : 동작 코드
현재 입력을 x라고 하고 x에 대해서 동작 코드를 수행하라는 의미
○ 분야별 단어 리스트로 묶기
목표 : 각 카테고리에 등장하는 단어들을 하나의 리스트로 묶는다.
- 뉴스 카테고리별로 묶기
# code 열이 '사회'인 데이터만 필터링
df[df['code']=='사회']- 특정 열을 하나의 리스트로 만들기
df['열의이름'].values를 이용하면 특정 데이터프레임의 열을 리스트 형태로 만들 수 있다.
# 특정 카테고리의 tokenized 열에 있는 값을 리스트로 묶어주기
df[df['code']=='특정 카테고리']['tokenized'].values
# Result : 이중 리스트 형태가 됨
[['첫번째 뉴스에 대한 데이터'], ['두번째 뉴스에 대한 데이터'], ... 중략 ...]np.hstack()은 여러 데이터를 하나의 데이터로 묶어준다. 그래서 이중 리스트를 입력하면 하나의 리스트로 바꿔준다.
# numpy 패키지 임포트
import numpy as np
# code 열의 값이 '사회'인 경우만 필터링한 데이터프레임의 'tokenized'열의 모든 리스트를 전부 연결하여 하나의 리스트로 변환.
social_news = np.hstack(df[df['code']=='사회']['tokenized'].values)
# code 열의 값이 '생활/문화'인 경우만 필터링한 데이터프레임의 'tokenized'열의 모든 리스트를 전부 연결하여 하나의 리스트로 변환.
life_news = np.hstack(df[df['code']=='생활/문화']['tokenized'].values)
# code 열의 값이 'IT/과학'인 경우만 필터링한 데이터프레임의 'tokenized'열의 모든 리스트를 전부 연결하여 하나의 리스트로 변환.
it_news = np.hstack(df[df['code']=='IT/과학']['tokenized'].values)
# 너무 길어서 ...가 나오면서 중간이 중략되고 출력됩니다.
print(social_news)
# Result
['파주' '시청' '사진' ... '온라인' '제보' '저작권']○ 카테고리별 단어 빈도 수 파악하기
collections라는 패키지의 Counter라는 함수로 단어의 등장 빈도를 카운트할 수 있다. Counter(리스트의이름)의 입력으로 사용하면 각 단어의 등장 빈도를 카운트해준다.
from collections import CounterCounter(리스트의이름).most_common(숫자)를 사용하면 숫자만큼의 높은 순서만 출력한다. 3을 입력하면 빈도 높은 단어 3개만 출력한다.
social_news_word_count = Counter(social_news)
print(social_news_word_count.most_common(20))
# Result
[('코로나', 180), ('혐의', 142), ('학교', 133), ('경찰', 130), ('거리', 127), ('방역', 118), ('학생', 115), ('서울', 113), ('두기', 107), ('생활', 101), ('시설', 92), ('수사', 89), ('지역', 87), ('마스크', 86), ('등교', 77), ('수업', 73), ('지침', 69), ('시작', 66), ('사회', 65), ('현장', 64)]👉 워드 클라우드
워드 클라우드는 중요한 단어나 키워드를 추출하여 직관적으로 보여주는 시각화 도구이다. 각 카테고리의 뉴스 기사에 주로 어떤 단어들이 키워드로 등장하는 지 확인한다.
from wordcloud import WordCloud워드 클라우드는 리스트 형태가 아니라 띄어쓰기를 기준으로 단어들이 구분되는 문자열을 인식한다.
' '.join()을 사용하면 각 리스트의 원소들을 띄어쓰기를 기준으로 재결합하여 문자열로 만들어준다.
' '.join(social_news)사회 카테고리의 명사 토큰들을 하나의 문자열로 연결하고 이를 temp_data라는 변수에 저장한다.
# '사회' 뉴스란에 있는 모든 명사 토큰들을 다시 하나의 문자열로 연결
temp_data = ' '.join(social_news)✋ 워드 클라우드 뼈대 코드
fontpath 는 한글 폰트의 경로를 변수형태로 저장한 것이다.
plt는 만들어진 워드클라우드를 출력하기 위한 코드라고 보면 된다.
# 사용하고자 하는 폰트의 경로. Colab에서는 이 경로를 사용하시면 됩니다.
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 사용할 단어의 수 , width = 가로, height = 세로, font_path = fontpath).generate('입력 문자열')
plt.imshow(wc, interpolation = 'bilinear')만들 단어 리스트,사용할 단어의 수, 가로, 세로만 필요에 따라 입력하면 된다.
# 사회 뉴스 기사의 워드클라우드
plt.figure(figsize = (15,15))
temp_data = ' '.join(단어 리스트)
wc = WordCloud(max_words = 2000 , width = 1600 , height = 800, font_path = fontpath).generate(temp_data)
plt.imshow(wc, interpolation = 'bilinear')
