[3주차 목표]
1. 데이터프레임 사용법을 익힌다.
2. 파이썬을 이용해서 데이터를 각종 차트로 시각화해본다.
👉3. 상관 관계 분석에 대해서 이해한다.👈
[목차]
- 상관 계수
- 히트맵
- 산점도
#사용하는 데이터테이블
import pandas as pd
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/drinks.csv'
drink_df = pd.read_csv(url, ',')○ 상관 계수
상관 분석이란 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것이다.
상관 계수란 2개의 변수 중 하나의 값이 상승하면 다른 값도 상승하는 경향을 수치로 표현하며 이를 1과 -1 사이 값으로 변환한다. 상관 계수가 1과 가깝다면 서로 강한 양의 상관 관계가 있는 것이고, -1에 가깝다면 음의 상관 관계가 있는 것이다.
✋데이터 시각화에 사용되는 패키지
Matplotlib: 파이썬의 자료를 차트나 플롯으로 시각화하는 패키지import matplotlib.pyplot as plt
seaborn: Matplotlib을 기반으로 다양한 테마와 기능을 추가한 시각화 패키지import seaborn as sns
👉상관계수 구하기
corr = df.corr(method = 'pearson')
pearson은 상관계수를 구하는 계산 방법 중 하나이며, 가장 널리 쓰인다.
cols = ['beer_servings', 'spirit_servings', 'wine_servings', 'total_litres_of_pure_alcohol']
corr = drink_df[cols].corr(method = 'pearson')
corr
○ 히트맵
일반적으로 상관계수 차트를 그릴 때는 seaborn에서 제공하는 heatmap()을 주로 이용한다.
히트맵을 그리기 위해서는 상관계수 데이터프레임을 리스트 형태로 변환한 값이 필요하며, 차트에 이름을 입력하기 위한 리스트가 필요하다.
#상관계수 데이터프레임 리스트
corr.values
#컬럼명
column_names = ['beer', 'spirit', 'wine', 'alcohol']👉히트맵 만들기
sns.heatmap(데이터프레임의 상관계수 데이터)
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=1.5)
hm = sns.heatmap(corr.values, # 상관계수 데이터
cbar=True, # 오른쪽 컬러 막대 출력 여부
annot=True, # 차트에 숫자를 보여줄 것인지 여부
square=True, # 차트를 정사각형으로 할 것인지
fmt='.2f', # 숫자의 출력 소수점자리 개수 조절
annot_kws={'size': 15}, # 숫자 출력시 숫자 크기 조절
yticklabels=column_names, # y축에 컬럼명 출력
xticklabels=column_names) # x축에 컬럼명 출력
plt.tight_layout() # 그래프 간격 유지 설정
plt.show() # 그래프 표시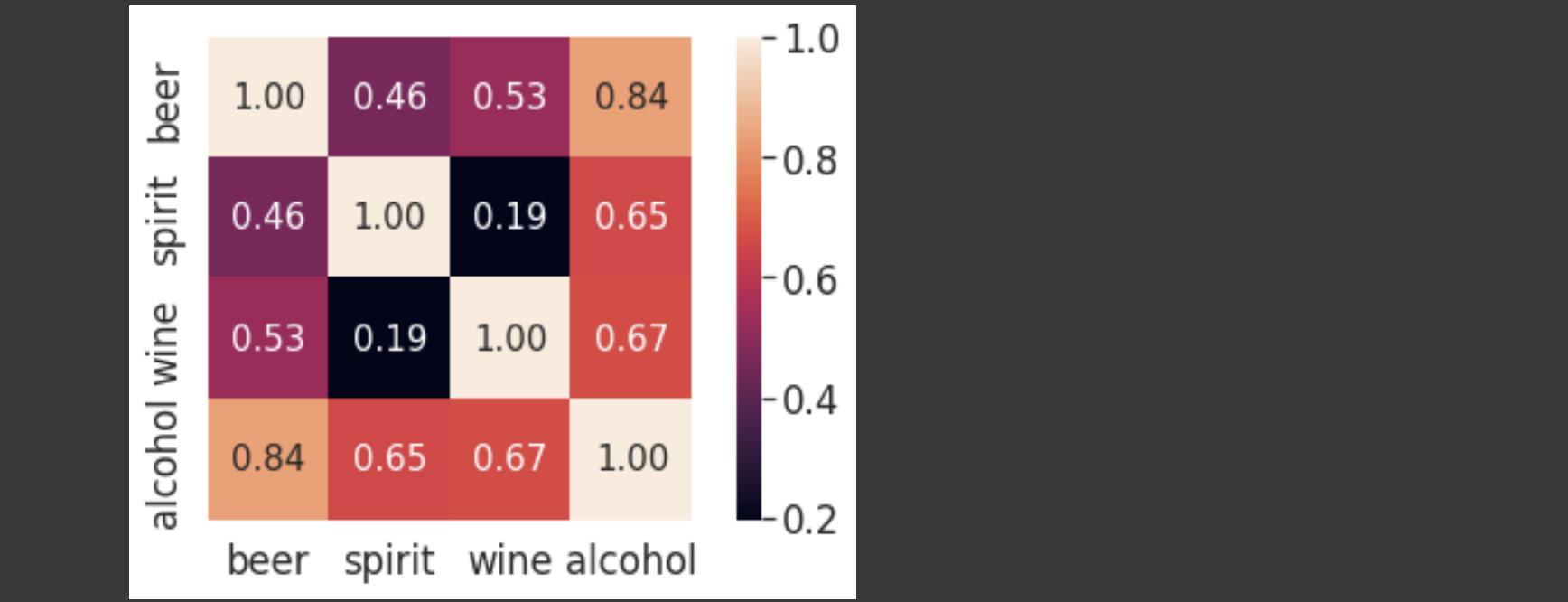
○ 산점도
산점도 (scatter plot)은 좌표상에 점들을 표시하는 방법으로 두 개 변수 간의 관계를 나타내는 그래프이다. pairplot은 각 열의 조합에 대해서 산점도를 그리고, 같은 데이터가 만나는 대각선 영역에는 해당 데이터의 히스토그램 (범위 별 데이터의 빈도를 그래프로 나타낸 것)을 그린다.
👉산점도 그리기
sns.pairplot(데이터프레임)
# 시각화 라이브러리를 이용한 피처간의 scatter plot을 출력합니다.
sns.set(style='whitegrid') # 배경을 하얗게 한다
sns.pairplot(drink_df[['beer_servings', 'spirit_servings',
'wine_servings', 'total_litres_of_pure_alcohol']])
plt.show()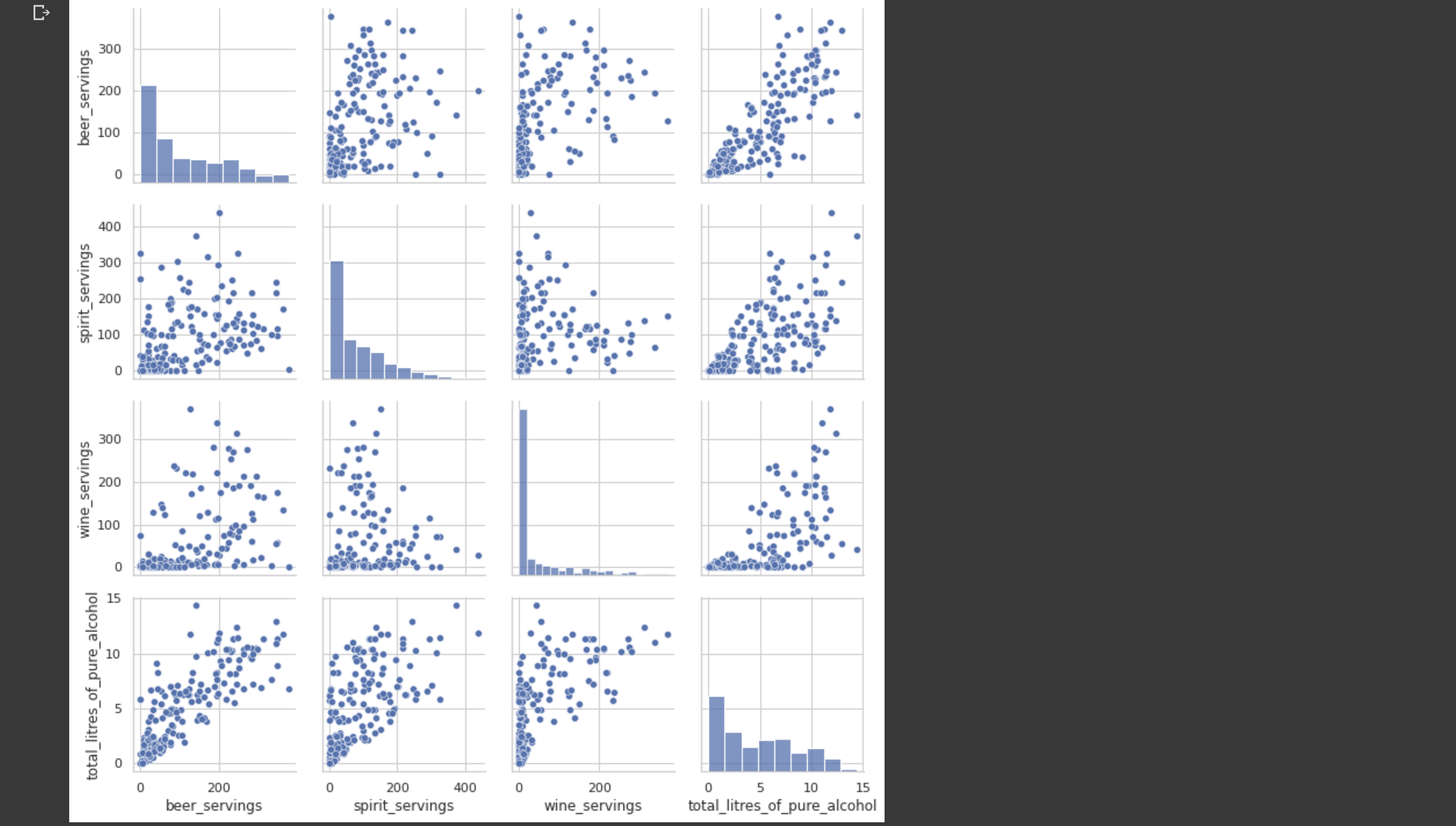

훈이야 화이팅