
Notify 프로젝트의 크롤링 기능을 완성했다. 그런데 문제가 생겼다.
Notify 프로젝트의 문제점
1. 크롤링에 오랜 시간(3분)이 걸리고, 크롤링을 하는 동안 클라이언트의 요청을 처리할 수 없는 문제가 발생했다.
2. 크롤링 작업에서 오류가 발생하면 시스템 자체가 다운되는 오류가 발생했다.
크롤링으로 로그인을 거치고 여러 페이지에 있는 각 학과의 공지사항과 공통 공지사항을 가져와야했기 때문에 3분이나 소요되었다.
다시 말해 클라이언트는 3분동안 기다려야하는 상황이 발생한 것이다. 그런데 크롤링은 30분마다 실행되기 때문에 클라이언트의 지연은 빈번하게 발생했다.
또한 크롤링 작업으로 인해 오류가 발생하면서 시스템 자체가 빈번하게 다운되었고, 그 때마다 시스템을 재실행해야했다.
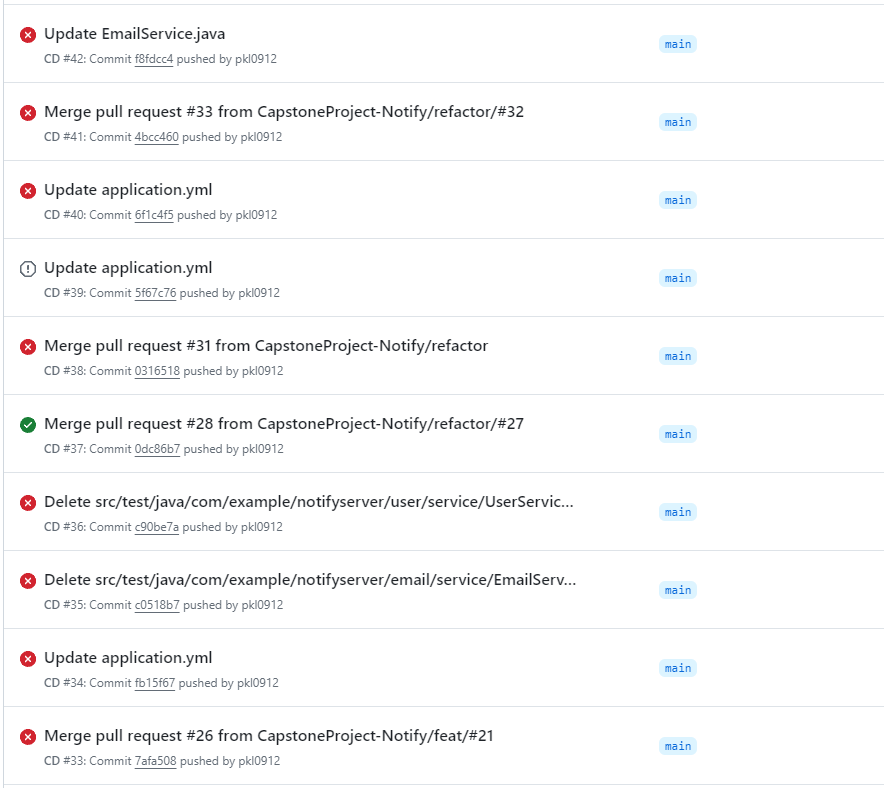
그러다보니 CI/CD가 정상적으로 작동하지 않았다.
해결 방안
이를 해결하기 위해 아래와 같은 해결방안을 고안하였다.
- 크롤링서버와 일반 서버를 분리한다.
- 크롤링 서버에서 크롤링 작업이 끝나면 카프카를 통해 일반 서버에 메시지를 보낸다.
여기서 크롤링 서버에서 일반서버에 메시지를 보내는 이유는 크롤링한 게시물에 사용자가 설정한 키워드가 있는 경우 이메일을 보내야하기 때문이다.
크롤링이 완료되면 아래의 메서드를 호출하도록 작성이 되어있었다.
public void sendNotificationEmail(String to, String nickname, String keyword, String postLink) {
String subject = "키워드 " + keyword + "에 대한 새로운 알림";
String content = String.format(
"%s님이 설정하신 키워드 %s와 관련된 새 게시물이 등록되었습니다. " +
"아래 링크에서 게시물을 확인하세요.<br><a href=\"%s\">%s</a>",
nickname, keyword, postLink, postLink
);
sendEmail(to, subject, content);
}따라서 이 작업을 메서드 내에서 메서드를 호출하는 것이 아니라 크롤링 메서드가 완료되면 Producer로서 Kafka에 메시지를 보내서 Consumer인 Notify-server가 해당 메시지를 소비하게 만들 예정이다.
왜 Kafka인가?
메시지 큐를 이용해야겠다고 생각을 하고 가장 고민했던 것은 RabbitMQ와 Kafka 중에 어떤 것을 사용할지였다. 그래서 둘을 비교해 보았다.
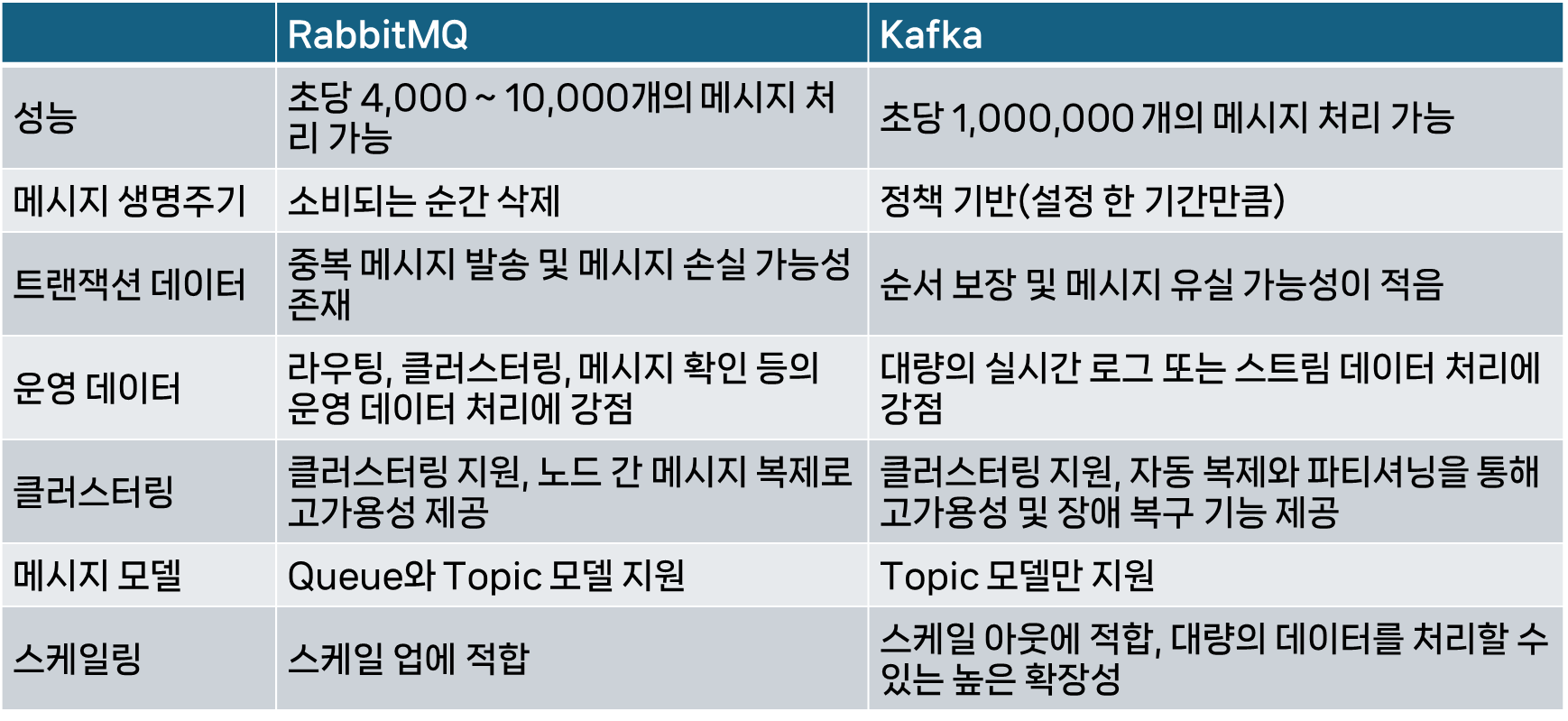
사실 내가 사용할 기능은 정말 메시지를 주고 받는 것이어서 둘 다 크게 상관은 없었지만 아래의 이유로 Kafka를 선택하였다.
- 프로젝트가 발전한다면 스케일 업보다는 스케일 아웃 방향으로 발전할 것이다.
- 추후에 더 많은 학과의 공지사항을 제공하려면 각 학과 페이지의 크롤링을 해야하고 이 때 각 학과의 크롤링 완료 메시지를 보내면서 메시지가 중복되거나 손실될 경우 이메일 서비스를 제대로 제공할 수 없다.
따라서 위의 이유로 카프카를 사용하기로 했다. 그리고 카프카를 사용하기 위해 아래 포스트들을 작성하며 공부해보았다.
도커를 사용한 카프카 적용 과정
Notify프로젝트는 도커를 사용하여 리눅스 서버에서 스프링 어플리케이션을 구동 중이었다. 따라서 카프카를 적용할 때에도 도커를 사용하여 리눅스 서버에 카프카를 설치하고 실행한 뒤 크롤러 서버와 기존 서버를 작동시킬 계획이었다. 그런데 카프카를 도커로 매번 설치하면 크롤러를 새로 빌드할 때 이미 존재하는 Notify 서버에서 카프카에 접속할 수 없으므로 카프카는 서버 자체에 설치하여 실행하였다.
1. 크롤러 스프링 프로젝트를 생성
Notify 크롤러 깃허브 레포
위 레포지토리에 스프링 프로젝트를 생성하였다.
2. 크롤링 어플리케이션 카프카 관련 설정 추가
build.gradle에 추가
// 카프카
implementation 'org.springframework.kafka:spring-kafka'appliation.yml에 추가
spring:
server:
port: 8082크롤링 서버 포트는 8082로 설정한다.
3. Git Actions를 통한 CI/CD 구축
[ci.yml]
name: CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-22.04
env:
working-directory: notify-crawler
steps:
- name: 체크아웃
uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
distribution: 'corretto'
java-version: '17'
- name: application.yml 생성
run: |
mkdir ./src/main/resources # resources 폴더 생성
cd src/main/resources
echo "${{ secrets.APPLICATION }}" > ./application.yml
- name: 빌드
run: |
chmod +x gradlew
./gradlew build -x test
shell: bash 여기서 주의할 점은 나는 .gitignore를 통해 application.yml을 깃허브에 올리지 않았기 때문에 mkdir ./src/main/resources 을 통해서 resources 폴더를 생성했다는 것이다. 만약 이미 이 폴더가 있다면 저 명령어는 빼도 된다.
[deploy.yml]
name: Deploy to Docker Hub and NOTIFY Server
# 워크플로우 트리거 설정
on:
push:
branches:
- main # main 브랜치에 푸시될 때 워크플로우 실행
jobs:
deploy-ci:
runs-on: ubuntu-22.04
env:
working-directory: notify-crawler
steps:
- uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
distribution: 'corretto'
java-version: '17'
- name: application.yaml 생성
run: |
mkdir ./src/main/resources # resources 폴더 생성
cd src/main/resources
echo "${{ secrets.APPLICATION }}" > ./application.yml
- name: 빌드
run: |
chmod +x gradlew
./gradlew build -x test
shell: bash
- name: Set up Docker Buildx # Docker Buildx 설정
uses: docker/setup-buildx-action@v2
- name: Login to Docker Hub # Docker Hub에 로그인
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKER_HUB_USERNAME }} # Docker Hub 사용자 이름
password: ${{ secrets.DOCKER_HUB_ACCESS_TOKEN }} # Docker Hub 접근 토큰
- name: Build and Push Docker Image # Docker 이미지 빌드 및 푸시
uses: docker/build-push-action@v4
with:
context: . # 현재 디렉토리를 컨텍스트로 사용
file: ./Dockerfile # Dockerfile 위치
push: true # 이미지를 Docker Hub에 푸시
tags: ${{ secrets.DOCKER_HUB_USERNAME }}/notify-crawler:latest # 이미지 태그 설정
deploy:
runs-on: ubuntu-latest # 워크플로우가 실행될 환경 설정
needs: deploy-ci # deploy-ci 작업 완료 후 실행
steps:
- name: Deploy to NOTIFY Server # 원격 서버에 배포
uses: appleboy/ssh-action@v0.1.4
with:
host: ${{ secrets.NOTIFY_SERVER_HOST }} # 원격 서버 주소
username: ${{ secrets.NOTIFY_SERVER_USER }} # 원격 서버 사용자 이름
key: ${{ secrets.NOTIFY_SERVER_SSH_KEY }} # 원격 서버 SSH 키
script: | # 원격 서버에서 실행할 스크립트
sudo docker pull ${{ secrets.DOCKER_HUB_USERNAME }}/notify-crawler:latest # 최신 Docker 이미지 풀링
sudo docker stop notify-crawler || true # 기존 컨테이너 중지 (실패해도 무시)
sudo docker rm notify-crawler || true # 기존 컨테이너 삭제 (실패해도 무시)
sudo docker run -d -p 8082:8082 --name notify-crawler ${{ secrets.DOCKER_HUB_USERNAME }}/notify-crawler:latest # 새 컨테이너 실행위 코드를 살펴보면 도커허브로부터 이미지를 pull 받아서 기존 서버에 컨테이너를 제거하고 그 자리에 8082 포트로 배포한다.
4. KafkaProducer 클래스 생성 및 호출
[KafkaProducer.java]
package com.example.notify_crawler.producer;
import com.example.notify_crawler.notice.domain.Notice;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Properties;
@Service
public class KafkaProducer {
private static final String TOPIC = "notify-crawler-topic";
public static void produce(List<Notice> newNotices) {
// Kafka Producer 설정
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, NoticeSerializer.class.getName());
// Kafka Producer 생성
org.apache.kafka.clients.producer.KafkaProducer<String, List<Notice>> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props);
// Kafka에 메시지 보내기
ProducerRecord<String, List<Notice>> record = new ProducerRecord<>(TOPIC, newNotices);
producer.send(record);
// Producer 종료
producer.flush();
producer.close();
}
}아래 코드처럼 크롤링 컨트롤러의 마지막에 카프카 프로듀서를 이용하여 메시지를 카프카로 보낸다.
[CrawlerController.java의 일부]
log.info("==== 모든 공지사항 크롤링 작업 완료 시각: "+ String.valueOf(LocalDateTime.now())+"====");
KafkaProducer.produce(kafkaNotices);여기까지 마치면 크롤링 서버는 완성되었다. 이제 크롤링 서버와 소통할 수 있도록 기존 서버를 수정해야한다.
5. 기존 서버에 카프카 관련 설정 추가
build.gradle에 추가
// 카프카
implementation 'org.springframework.kafka:spring-kafka'
// 직렬화 라이브러리 추가
implementation 'com.fasterxml.jackson.core:jackson-databind'appliation.yml에 추가
kafka:
bootstrap-servers: 15.164.34.15:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: com.example.notify_crawler.producer.NoticeSerializer여기서 직렬화관련된 내용을 추가한 것을 볼 수 있다.
6. 기존 서버의 크롤링 기능 제거
당연히 기존 서버에는 크롤링 기능이 있을 필요가 없다. 따라서 크롤링 기능을 제거했다.
7. 기존 서버에 KafkaConsumer 클래스 생성
package com.example.notifyserver.kafka;
import com.example.notifyserver.notice.domain.Notice;
import com.example.notifyserver.user.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
@Slf4j
public class KafkaConsumer {
@Autowired
UserService userService;
@KafkaListener(topics = "notify-crawler-topic", groupId = "notify")
public void consume(List<Notice> notices) {
if (notices == null || notices.isEmpty()) {
// 비어있는 noticeList가 오는 경우에 대한 처리
log.info("================ 새롭게 크롤링 된 게시물이 없습니다. ================");
return;
}
// Kafka 메시지를 역직렬화한 List<Notice> 객체를 사용하여 원하는 작업을 수행
for (Notice notice : notices) {
log.info("================ 새롭게 크롤링 된 게시물 제목: ================" + notice.getNoticeTitle());
}
}
}이 때 토픽과 그룹 아이디를 크롤링 서버의 설정과 같게 설정해야한다. 그렇지 않으면 크롤링 서버의 메시지를 가져올 수 없다.
또한 여기서는 일단 메시지를 로깅하는 부분까지만 구현하였다. 하지만 실제 코드는 저 메시지를 받으면 키워드에 해당하는 공지사항을 확인하는 메서드를 호출하게 만들었다.
추가적으로 직렬화와 역직렬화를 통해 자바 객체를 전달하였는데 전반적인 과정은 Kafka로-Java-객체-전송하기에 정리해두었다.
참고:
